






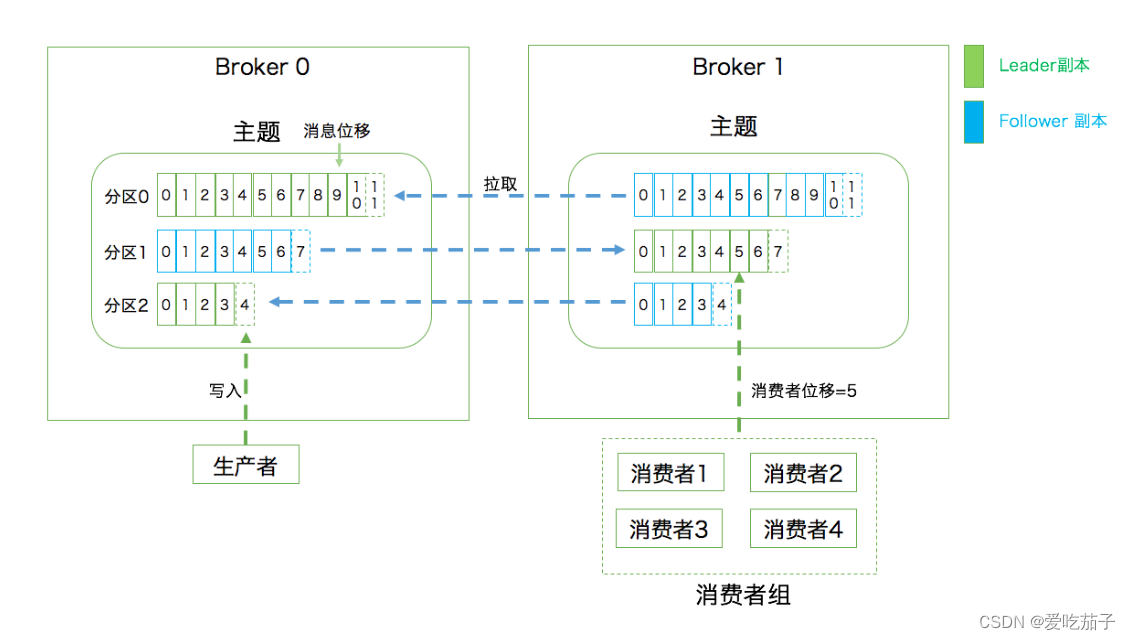
kafka 重要术语
- 消息:Record。kafka处理的主要对象
- 主题:Topic,逻辑容器,可以区分不同的业务
- 分区:Partition。一个有序不变的消息队列,每个主题可以有多个分区
- 消息位移:Offset。表示分区中消息的位置,是单调递增的值
- 副本:Replica。实现数据冗余(follower 不向外提供读服务),把一条消息拷贝到多个地方。副本分为 leader 和 follower。副本是在分区维度下,即每个分区可以存在多个副本
- 生产者:Producer。向主题发送消息的应用程序
- 消费者:Consumer。从主题中订阅新消息的应用程序
- 消费者位移:Consumer Offset。表示消费者进度,每个消费者都有自己的消费者位移,存放在位移主题中。
- 消费者组:Consumer Group。多个消费者实例共同组成一组。
- 重平衡:Rebalance。消费者组内某个实力挂掉后,其它消费者实例自动重新分配订阅主题分区的过程。是实现高可用的重要手段
kafka分区的好处
- 提供负载均衡的能力,提高可伸缩性,可以添加更多的消费者和生产者,增加系统的吞吐量
- 每个分区内的消息都是有序的
分区策略
- 轮询策略
- 随机策略
- 粘性分区策略
- 按消息键保序策略
自定义分区策略:
编写一个具体的类实现org.apache.kafka.clients.producer.Partitioner接口中的partition方法即可
kafka 实现无消息丢失配置
- 设置 ack 应答级别为 -1(all):生产者发送数据过来,leader + isr(能够和 leader 保持同步的 follower + leader本身 组成的集合) 中所有的节点收到数据后应答
- 使用 producer.send(msg, callback) 带有回调的发送方法。若发送失败可以有针对性处理
- 设置 retries 为一个较大的值,是 Producer 的参数
- 分区副本数 >= 2,且 ISR 中最小副本数量 >= 2
- 确保消息消费完再提交。Consumer 端有个参数 enable.auto.commit,最好把它设置成 false,并手动提交位移
kafka 的 offset
作用:记录 consumer 位移消息
从 0.9 版本开始,默认将offset保存在Kafka
一个内置的topic中,该 topic 为 __consumer_offset。
使用 K-V 结构存储:
- key : group.id + topic + 分区号
- value : 当前 offset的值(其它等等)
当 kafka 中的 consumer 程序启动,就会自动创建该位移主题!
关于 offset 的提交问题
当 consumer 消费完消息后,需要记录新的 offset,有两种选择,一是自动提交,二是手动提交。
自动提交位移可能会出现重复消费问题!
手动提交:
- 同步提交:必须等 offset 提交成功,再去消费下一批数据
- 异步提交:发送完提交 offset 请求后,开始消费下一批数据
** 异步提交之细粒度化:**
private Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
int count = 0;
……
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record: records) {
process(record); // 处理消息
offsets.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1);
if(count % 100 == 0)
consumer.commitAsync(offsets, null); // 回调处理逻辑是 null
count++;
}
}
这样不受 poll 方法返回消息总数的限制。可以把大量消息,分成 100 一段进行 offset 提交,若中途出现问题,可以避免大量消息的重新消费。(牛牛牛)
CommitFailedException异常怎么处理?
出现这个问题的原因?
消费者实例花费太多的时间进行消息处理,耽误了调用 poll 方法
解决方案
- 缩短单条消息处理时间:优化代码吧
- 增加 Consumer 端允许下游系统消费一批消息的最大时长。 max.poll.interval.ms 参数变大
- 减少下游系统一次性消费的消息总数。consumer 少拿一些消息,参数 max.poll.records 变小
- 下游系统使用多线程来加速消费。使用线程池,榨干 cpu !
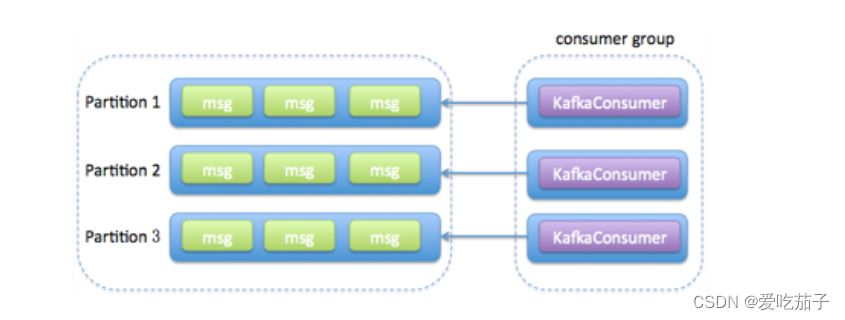
多线程消费方案?
-
消费者程序启动多个线程,每个线程维护专属的 KafkaConsumer 实例,负责完整的消息获取、消息处理流程
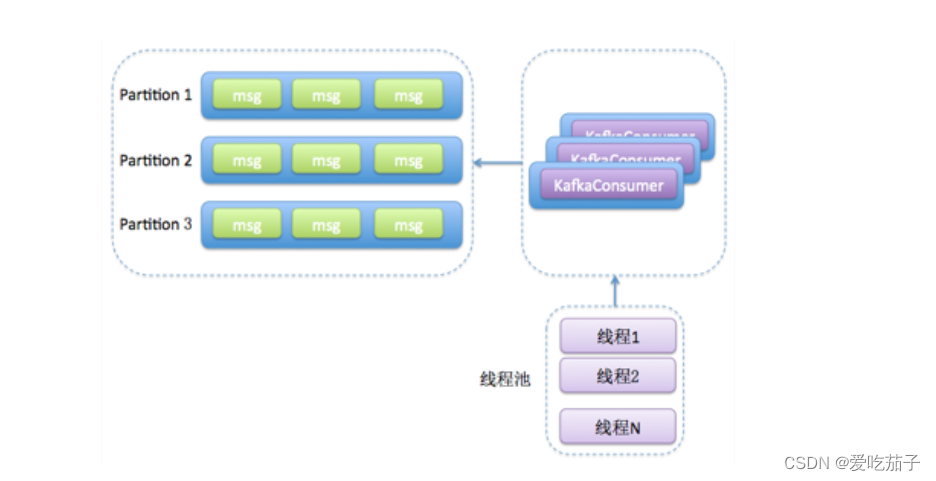
-
消费者程序使用单或多线程获取消息,同时创建多个消费线程执行消息处理逻辑。获取消息的线程可以是一个,也可以是多个,每个线程维护专属的 KafkaConsumer 实例,处理消息则交由特定的线程池来做,从而实现消息获取与消息处理的真正解耦。
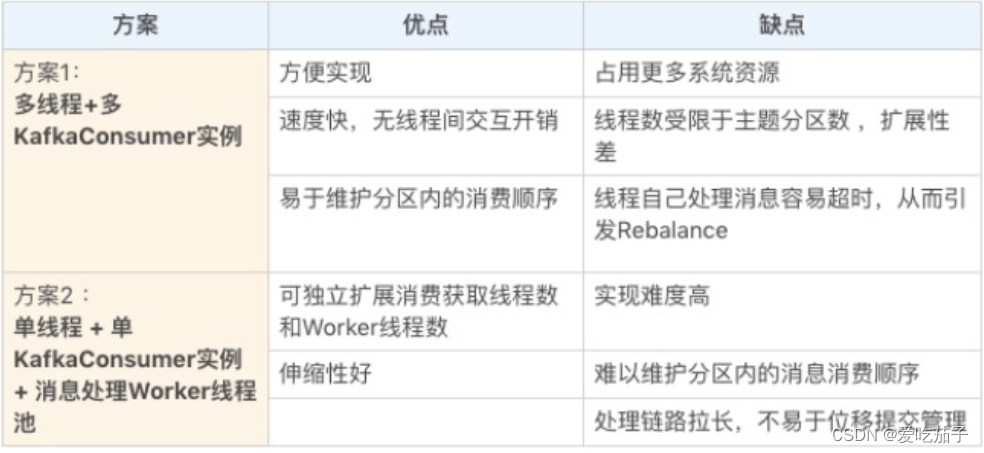
方案比较
kafka 副本机制详解
- 提供数据冗余。即使系统部分组件失效,系统依然能够继续运转,因而增加了整体可用性以及数据持久性。
- 提供高伸缩性。支持横向扩展,能够通过增加机器的方式来提升读性能,进而提高读操作吞吐量。
- 改善数据局部性。允许将数据放入与用户地理位置相近的地方,从而降低系统延时。
** kafka 副本中的 follower 为什么不对外提供读服务?**
- 方便实现 “Read-your-writes”。即当你写完消息后,能够及时读取到刚才的消息。副本同步是异步的,如何副本对外提供服务,可能会出现消息不一致问题
- 方便实现单调读。什么是单调读?就是对于一个消费者用户而言,在多次消费消息时,它不会看到某条消息一会儿存在一会儿不存在。
对于 ISR 队列的定义:leader + 与 leader 同步的 follower
leader 同步的 follower 的条件 : 只要 follower 落后 leader 最长时间间隔不超过 Broker 端参数** replica.lag.time.max.ms 参数值,并且同步速度不小于** leader 拉取消息的速度。
最好禁止 Unclean 领导者选举 : 因为 follower 与 leader 之间总会存在消息差,若 follower 替换原来的 leader ,会出现消息丢失的情况!
kafka的幂等性和事务
- 幂等性:保证单分区内消息去重( 根据 <PID, Partition, SeqNumber> 判断消息是否重复)
- 事务:前提必须开启幂等性,能够保证跨分区,跨会话的幂等性。但影响性能。
事务应该是基于 XA 协议实现的
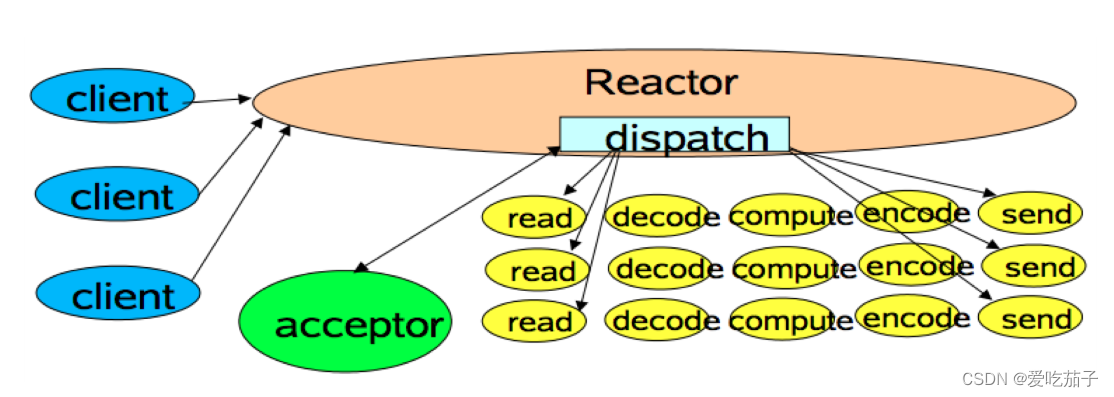
kafka 请求如何被处理
所有的请求都是通过 TCP 网络以 Socket 的方式进行通讯的。
kafka 采用 ** Reactor 模式 **
kafka 压缩
为什么需要压缩?时间换空间,可以减少磁盘空间和网络带宽的传输量
一般在 producer 端压缩,broker 校验,消费者端解压读取。设置 broker 要尊重 producer 的压缩方式
# server.properties
compression.type=producer [或指定算法]
- 注意消息的版本号,不论哪个版本,Kafka 的消息层次都分为两层:消息集合(message set)以及消息(message)。一个消息集合中包含若干条日志项(record item),而日志项才是真正封装消息的地方。
- 选择合适的压缩算法(考虑 cpu 资源、带宽资源等因素)
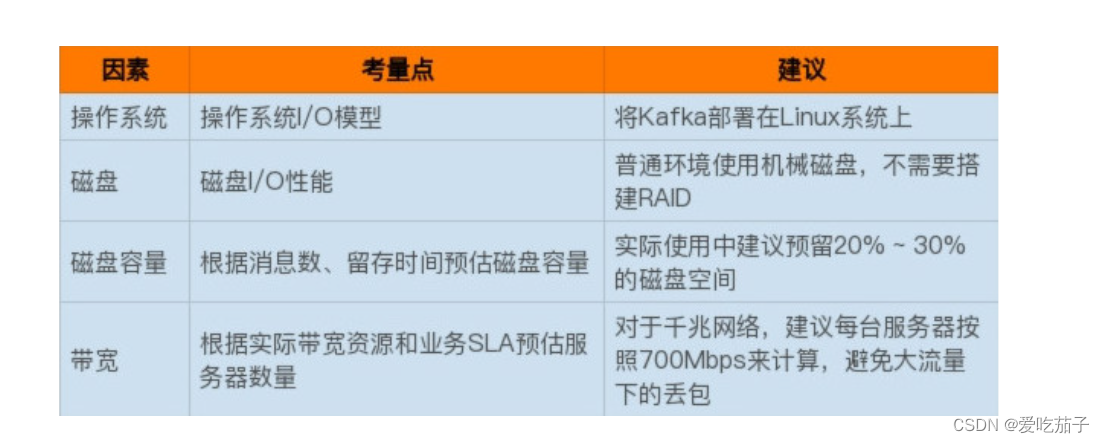
线上集群方案:















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









