






python编程学习入门:
1、python特点
- 1.易于学习:Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。
- 2.易于阅读:Python代码定义的更清晰。
- 3.易于维护:Python的成功在于它的源代码是相当容易维护的。
- 4.一个广泛的标准库:Python的最大的优势之一是丰富的库,跨平台的,在UNIX,Windows和Macintosh兼容很好。
- 5.互动模式:互动模式的支持,您可以从终端输入执行代码并获得结果的语言,互动的测试和调试代码片断。
- 6.可移植:基于其开放源代码的特性,Python已经被移植(也就是使其工作)到许多平台。
- 7.可扩展:如果你需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用C或C++完成那部分程序,然后从你的Python程序中调用。
- 8.数据库:Python提供所有主要的商业数据库的接口。
- 9.GUI编程:Python支持GUI可以创建和移植到许多系统调用。
- 10.可嵌入 :你可以将Python嵌入到C/C++程序,让你的程序的用户获得”脚本化”的能力。
2、python安装过程
3、第一个程序
print("hello,这是第一个python程序")
运行:hello,这是第一个python程序
4、Python标识符
标识符是允许作为变量(函数、类等)名称的有效字符串。其中,有一部分是关键字(语言本身保留的标识符),它是不能做它用的标识符的,否则会引起语法错误(SyntaxError 异常)。Python 还有称为 built-in 标识符集合,虽然它们不是保留字,但是不推荐使用这些特别的名字。

Python 是动态类型语言, 也就是说不需要预先声明变量的类型。 变量的类型和值在赋值那一刻被初始化。变量赋值通过等号来执行。
Python的有效标识符由大小写字母、下划线和数字组成。数字不能作为第一个字符,标识符的长度不限,Python标识符是大小写敏感的。
在编程语言中,常见的变量命名方式有两种:
-
驼峰体:
- DateOfBirth
- AgeOfBoy
- ShowMeAI
-
下划线:
- date_of_birth
- age_of_boy
- show_me_ai
5、python保留字:
下面的图片显示了在Python中的保留字。这些保留字不能用作常数或变数,或任何其他标识符名称。所有 Python 的关键字只包含小写字母。

5、行的缩进
Python 的代码块不使用大括号 {} 来控制类,函数以及其他逻辑判断。python 最具特色的就是用缩进来写模块。缩进可使用tab或空格等,空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量。


6、多行语句
Python语句中一般以新行作为语句的结束符。但是我们可以使用斜杠( \)将一行的语句分为多行显示,如下所示:
total = 2 + \
3 + \
4
print(total)
输出:9
语句中包含 [], {} 或 () 括号就不需要使用多行连接符。如下实例:
days = ['Monday', 'Tuesday', 'Wednesday',
'Thursday', 'Friday']
print(days)
输出:['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday']
7、Python字符串与引号
Python 可以使用引号( ‘ )、双引号( “ )、三引号( ‘’’ 或 “”” ) 来表示字符串,引号的开始与结束必须是相同类型的。(更详细的python字符串知识参见python字符串及操作)
其中三引号可以由多行组成,编写多行文本的快捷语法,常用于文档字符串,在文件的特定地点,被当做注释。

#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 文件名:test.py
# 第一个注释
print("这是第二个注释") # 第二个注释
输出:这是第二个注释
注释可以在语句或表达式行末:
name = "ShowMeAI" # 这是一个注释
python 中多行注释使用三个单引号(‘’’)或三个双引号(“””)。
#!/usr/bin/python # -*- coding: UTF-8 -*- # 文件名:test.py ''' 这是多行注释,使用单引号。 这是多行注释,使用单引号。 这是多行注释,使用单引号。 ''' """ 这是多行注释,使用双引号。 这是多行注释,使用双引号。 这是多行注释,使用双引号。 """
8、python空行
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
空行与代码缩进不同,空行并不是Python语法的一部分。书写时不插入空行,Python解释器运行也不会出错。但是空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
9、同一行显示多条语句
Python可以在同一行中使用多条语句,语句之间使用分号(;)分割,以下是一个简单的实例:
import sys; x = 'ShowMeAI'; sys.stdout.write(x + '\ ')
输出:ShowMeAI
10、print输出
python3中print默认输出都是换行的,如果要实现不换行需要在变量末尾加上 (, end="')
x="a"
y="b"
# 换行输出
print(x)
print(y)
print('这里是分割线---------')
# 不换行输出
print(x, end='')
print(y, end='')
输出:
a
b
这里是分割线---------
ab
Process finished with exit code 0
11、代码组
缩进相同的一组语句构成一个代码块,我们称之代码组。
像if、while、def和class这样的复合语句,首行以关键字开始,以冒号( : )结束,该行之后的一行或多行代码构成代码组。
12、python的变量类型
Python基本数据类型一般分为6种:数值(Numbers)、字符串(String)、列表(List)、元组(Tuple)、字典(Dictionary)、集合(Set)。本文详细讲解Python中变量赋值、数据类型以及数据类型的转换。
变量存储在内存中的值,这就意味着在创建变量时会在内存中开辟一个空间。基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中。因此,变量可以指定不同的数据类型,这些变量可以存储整数,小数或字符。
13、变量赋值
-
Python 中的变量赋值不需要类型声明。
-
每个变量在内存中创建,都包括变量的标识,名称和数据这些信息。
-
每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
-
等号 = 用来给变量赋值。
多变量赋值
Python允许你同时为多个变量赋值。例如:
a = b = c = d = 3
print(a, b, c, d)
输出:
3 3 3 3
以上实例,创建一个整型对象,值为3,三个变量被分配到相同的内存空间上。
14、标准数据类型
在内存中存储的数据可以有多种类型。
例如,一个人的年龄可以用数字来存储,他的名字可以用字符来存储。
Python有最常用的5个标准数据类型:
- Numbers(数值)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
其中数值类型,在Python支持四种不同的数字类型:
- int(有符号整型)
- float(浮点型)
- bool(布尔型)
- complex(复数)
a=3.14 print(type(a)) b=3 print(type(b)) c=True print(type(c)) str="hello" print(type(str))
输出:
<class 'float'>
<class 'int'>
<class 'bool'>
<class 'str'>

15、python字符串
可以使用加号(+)对字符串进行连接,使用星号(*)对字符串进行重复操作。如下
str = 'Hello ShowMeAI!' print(str) # 输出完整字符串 print(str[0]) # 输出字符串中的第一个字符 print(str[2:5]) # 输出字符串中第三个至第六个之间的字符串 print(str[2:]) # 输出从第三个字符开始的字符串 print(str * 2) # 输出字符串两次 print(str + " Awesome") # 输出连接的字符串
输出:
Hello ShowMeAI!
H
llo
llo ShowMeAI!
Hello ShowMeAI!Hello ShowMeAI!
Hello ShowMeAI! Awesome
16、Python列表
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。
列表用 [ ] 标识,是 python 最通用的复合数据类型。
列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,下标可以为空表示取到头或尾。
list = [ 'ShowMeAI', 233 , 234, 'show', 23.5 ] tinylist = [123, 'show'] print(list) # 输出完整列表 print(list[0]) # 输出列表的第一个元素 print(list[1:3]) # 输出第二个至第三个元素 print(list[2:]) # 输出从第三个开始至列表末尾的所有元素 print(tinylist * 2) # 输出列表两次 print(list + tinylist) # 打印组合的列表
输出:
['ShowMeAI', 233, 234, 'show', 23.5]
ShowMeAI
[233, 234]
[234, 'show', 23.5]
[123, 'show', 123, 'show']
['ShowMeAI', 233, 234, 'show', 23.5, 123, 'show']
16、Python元组
元组是另一个数据类型,类似于 List(列表)。
元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
tuple = ( 'ShowMeAI', 233 , 23.4, 'show', 2.35 ) tinytuple = (123, 'show') print(tuple) # 输出完整元组 print(tuple[0]) # 输出元组的第一个元素 print(tuple[1:3]) # 输出第二个至第四个(不包含)的元素 print(tuple[2:]) # 输出从第三个开始至列表末尾的所有元素 print(tinytuple * 2) # 输出元组两次 print(tuple + tinytuple) # 打印组合的元组
输出:
('ShowMeAI', 233, 23.4, 'show', 2.35)
ShowMeAI
(233, 23.4)
(23.4, 'show', 2.35)
(123, 'show', 123, 'show')
('ShowMeAI', 233, 23.4, 'show', 2.35, 123, 'show')
以下是元组无效的,因为元组是不允许更新的。而列表是允许更新的:
tuple = ( 'ShowMeAI', 233 , 23.4, 'show', 2.35 ) list=['ShowMeAI', 233 , 23.4, 'show', 2.35] tuple[2] = 100 # 元组中是非法应用 list[2] = 100 # 列表中是合法应用 print(tuple) print(list)
输出:Traceback (most recent call last):
File "C:/Users/Apple/PycharmProjects/pythonProject2/sTudy.py", line 45, in <module>
tuple[2] = 100 # 元组中是非法应用
TypeError: 'tuple' object does not support item assignment
元组中不允许修改,所以我们注释掉它
tuple = ( 'ShowMeAI', 233 , 23.4, 'show', 2.35 ) list=['ShowMeAI', 233 , 23.4, 'show', 2.35] # tuple[2] = 100 # 元组中是非法应用 list[2] = 100 # 列表中是合法应用 print(tuple) print(list)
输出:
('ShowMeAI', 233, 23.4, 'show', 2.35)
['ShowMeAI', 233, 100, 'show', 2.35]
17、Python字典
字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典用”{ }”标识。字典由索引(key)和它对应的值value组成。
dict = {}
dict['one'] = "This is one"
dict[2] = "This is two"
tinydict = {'name': 'ShowMeAI','code':3456, 'dept': 'AI'}
print(dict['one']) # 输出键为'one' 的值
print(dict[2]) # 输出键为 2 的值
print("我在测试",dict)
print(tinydict) # 输出完整的字典
print(tinydict.keys()) # 输出所有键
print(tinydict.values()) # 输出所有值
输出:
This is one
This is two
我在测试 {'one': 'This is one', 2: 'This is two'}
{'name': 'ShowMeAI', 'code': 3456, 'dept': 'AI'}
dict_keys(['name', 'code', 'dept'])
dict_values(['ShowMeAI', 3456, 'AI'])
18、Python数据类型转换
有时候,需要对数据内置的类型进行转换,数据类型的转换,只需要将数据类型作为函数名即可。
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。

19、Python比较运算符
a=3 b=3 print(a!=b) print(type(a!=b))
输出:
False
<class 'bool'>
20、Python赋值运算符

21、Python位运算符
a 为 60,b 为 13
a=0011 1100
b=0000 1101
a&b = 0000 1100
a|b = 0011 1101
a^b = 0011 0001
~a = 1100 0011

a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = 0
c = a & b; # 12 = 0000 1100
print("第1次运算后,c的值为:", c)
c = a | b; # 61 = 0011 1101
print("第2次运算后,c的值为:", c)
c = a ^ b; # 49 = 0011 0001
print("第3次运算后,c的值为:", c)
c = ~a; # -61 = 1100 0011
print("第4次运算后,c的值为:", c)
c = a << 2; # 240 = 1111 0000
print("第5次运算后,c的值为:", c)
c = a >> 2; # 15 = 0000 1111
print("第6次运算后,c的值为:", c)
输出:
第1次运算后,c的值为: 12
第2次运算后,c的值为: 61
第3次运算后,c的值为: 49
第4次运算后,c的值为: -61
第5次运算后,c的值为: 240
第6次运算后,c的值为: 15
22、Python逻辑运算符
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:

a = 10
b = 20
if a and b :
print("1.变量 a 和 b 都为 true")
else:
print("1.变量 a 和 b 有一个不为 true")
if a or b :
print("2.变量 a 和 b 都为 true,或其中一个变量为 true")
else:
print("2.变量 a 和 b 都不为 true")
# 修改变量 a 的值
a = 0
if a and b :
print("3.变量 a 和 b 都为 true")
else:
print("3.变量 a 和 b 有一个不为 true")
if a or b :
print("4.变量 a 和 b 都为 true,或其中一个变量为 true")
else:
print("4.变量 a 和 b 都不为 true")
if not( a and b ):
print("5.变量 a 和 b 都为 false,或其中一个变量为 false")
else:
print("5.变量 a 和 b 都为 true")
输出:
1.变量 a 和 b 都为 true
2.变量 a 和 b 都为 true,或其中一个变量为 true
3.变量 a 和 b 有一个不为 true
4.变量 a 和 b 都为 true,或其中一个变量为 true
5.变量 a 和 b 都为 false,或其中一个变量为 false
23、Python成员运算符
Python 还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。

a = 10
b = 20
list = [1, 2, 3, 4, 5 ];
if ( a in list ):
print("1.变量 a 在给定的列表中 list 中")
else:
print("1.变量 a 不在给定的列表中 list 中")
if ( b not in list ):
print("2.变量 b 不在给定的列表中 list 中")
else:
print("2.变量 b 在给定的列表中 list 中")
# 修改变量 a 的值
a = 2
if ( a in list ):
print("3.变量 a 在给定的列表中 list 中")
else:
print("3.变量 a 不在给定的列表中 list 中")
输出:
1.变量 a 不在给定的列表中 list 中
2.变量 b 不在给定的列表中 list 中
3.变量 a 在给定的列表中 list 中
24、Python身份运算符
身份运算符用于比较两个对象的存储单元

注: id() 函数用于获取对象内存地址。
is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个(同一块内存空间), == 用于判断引用变量的值是否相等。
a = [1, 2, 3] b = a print(b is a) print(b == a) b = a[:] print(b) print(b is a) print(b==a)
输出:
True
True
[1, 2, 3]
False
True
25、Python运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:

a = 20
b = 10
c = 15
d = 5
e = 0
e = (a + b) * c / d #( 30 * 15 ) / 5
print("(a + b) * c / d 运算结果为:", e)
e = ((a + b) * c) / d # (30 * 15 ) / 5
print("((a + b) * c) / d 运算结果为:", e)
e = (a + b) * (c / d); # (30) * (15/5)
print("(a + b) * (c / d) 运算结果为:", e)
e = a + (b * c) / d; # 20 + (150/5)
print("a + (b * c) / d 运算结果为:", e)
输出:
(a + b) * c / d 运算结果为: 90.0
((a + b) * c) / d 运算结果为: 90.0
(a + b) * (c / d) 运算结果为: 90.0
a + (b * c) / d 运算结果为: 50.0
26、Python条件语句
在 Python 中,可以使用 if 语句对条件进行判断,然后根据不同的结果(True或者False)执行不同的代码。Python 中的 if 语句可以细分为三种形式: if 语句、if else 语句和 if elif else 语句。
Python程序语言指定任何非0和非空(null)值为true,0 或者 null为false。
Python 编程中 if 语句用于控制程序的执行,基本形式为:
if 判断条件:
执行语句……
else:
执行语句……
if 语句的判断条件可以用>(大于)、<(小于)、==(等于)、>=(大于等于)、<=(小于等于)来表示其关系。
当判断条件为多个值时,可以使用以下形式:
if 判断条件1:
执行语句1……
elif 判断条件2:
执行语句2……
elif 判断条件3:
执行语句3……
else:
执行语句4……
其中”判断条件”成立时(非零),则执行后面的语句,而执行内容可以多行,以缩进来区分表示同一范围。else 为可选语句,当需要在条件不成立时执行内容则可以执行相关语句。
flag = False
name = 'ShowMeAI'
if name == 'python': # 判断变量是否为 python
flag = True # 条件成立时设置标志为真
print('welcome boss') # 并输出欢迎信息
else:
print('welcome '+name) # 条件不成立时输出变量名称
输出:welcome ShowMeAI
num = 6
if num == 3: # 判断num的值
print('boss')
elif num == 2:
print('user')
elif num == 1:
print('worker')
elif num < 0: # 值小于零时输出
print('error')
else:
print('random') # 条件均不成立时输出
输出:random
由于 python 并不支持 switch 语句,所以多个条件判断,只能用 elif 来实现,如果判断需要多个条件需同时判断时,可以使用 or (或),表示两个条件有一个成立时判断条件成功;使用 and (与)时,表示只有两个条件同时成立的情况下,判断条件才成功。
# if语句多个条件
num = 9
if num >= 0 and num <= 10: # 判断值是否在0~10之间
print('hello')
# 输出结果: hello
num = 10
if num < 0 or num > 10: # 判断值是否在小于0或大于10
print('hello')
else:
print('undefine')
# 输出结果: undefine
num = 8
# 判断值是否在0~5或者10~15之间
if (num >= 0 and num <= 5) or (num >= 10 and num <= 15):
print('hello')
else:
print('undefine')
# 输出结果: undefine
简单的语句组,也可以在同一行的位置上使用if条件判断语句,如下示例
show = 100
if ( show == 100 ) : print("变量 show 的值为100")
print("Good bye!")
输出:
变量 show 的值为100
Good bye!
27、Python循环语句
程序在一般情况下是按顺序执行的,Python提供了各种控制结构,允许更复杂的执行路径。
循环语句允许我们执行一个语句或语句组多次,下面是在大多数编程语言中的循环语句的一般形式:

| while 循环 | 在给定的判断条件为 true 时执行循环体,否则退出循环体。 |
| for 循环 | 重复执行语句 |
| 嵌套循环 | 你可以在while循环体中嵌套for循环 |
28、循环控制语句
循环控制语句可以更改语句执行的顺序。Python支持以下循环控制语句:

| 控制语句 | 描述 |
|---|---|
| break 语句 | 在语句块执行过程中终止循环,并且跳出整个循环 |
| continue 语句 | 在语句块执行过程中终止当前循环,跳出该次循环,执行下一次循环。 |
| pass 语句 | pass是空语句,是为了保持程序结构的完整性。 |
29、Python-While循环语句
Python 编程中 while 语句用于循环执行程序,即满足某条件的情况下,循环执行某段程序。其基本形式为:
while 判断条件(condition):
执行语句(statements)……

执行语句可以是单个语句或语句块。判断条件可以是任何表达式,任何非零、或非空(null)的值均为true。当判断条件假 false 时,循环结束。

以下代码演示了Python中的while循环:
count = 0
while (count < 9):
print('The count is:', count)
count = count + 1
print("Done!")
输出:
The count is: 0
The count is: 1
The count is: 2
The count is: 3
The count is: 4
The count is: 5
The count is: 6
The count is: 7
The count is: 8
Done!
while 语句时还有另外两个重要的命令 continue,break 来跳过循环:
- continue 用于跳过该次循环
- break 用于退出循环
有时候”判断条件”还可以是个常值,表示循环必定成立,具体用法如下
i = 1
while i < 10:
i += 1
if i%2 > 0: # 非双数时跳过输出
continue
print(i) # 输出双数2、4、6、8、10
i = 1
while 10: # 循环条件为1必定成立
i += 1
if i > 10 and i<20: # 当i大于10时跳出循环
print(i)
continue
elif i>20:
break
输出:
2
4
6
8
10
11
12
13
14
15
16
17
18
19
30、Python-for循环语句
for循环的语法格式如下:
for iterating_var in sequence: statements(s)


for x in 'GOOD': # 第一个实例
print("当前字母: %s" % x)
fruits = ['banana', 'apple', 'mango']
for y in fruits: # 第二个实例
print('当前水果: %s'% y)
print("完成")
输出:
当前字母: G
当前字母: O
当前字母: O
当前字母: D
当前水果: banana
当前水果: apple
当前水果: mango
完成
通过序列索引迭代;另外一种执行循环的遍历方式是通过索引,如下实例:
fruits = ['香蕉', '苹果', '葡萄']
for x in range(len(fruits)):
print('当前水果 : %s' % fruits[x])
print("完成!")
输出:
当前水果 : 香蕉
当前水果 : 苹果
当前水果 : 葡萄
完成!
以上实例我们使用了内置函数 len() 和 range(),函数 len() 返回列表的长度,即元素的个数。 range返回一个序列的数。
len()函数返回对象中元素的数量;len()是Python中一个非常有用的内置函数,它提供了一种简单的方式来获取对象的长度或元素的数量。
greeting = "Hello,Hello" print(len(greeting))
输出:12
range(5)得到的是:0,1,2,3,4 表示从0到4 start和stop表示的范围规则:“前闭后开”,也就是说取不到5
迭代range(1,5)得到的是1,2,3,4 表示从1到4
step 步长,默认为1,表示迭代时的增量(或减量),在使用step时必须要指定第一个参数start
31、循环使用else语句
在 python 中,for … else 表示这样的意思,for 中的语句和普通的没有区别,else 中的语句会在循环正常执行完(即 for 不是通过 break 跳出而中断的)的情况下执行,while … else 也是一样。
for num in range(20,30): # 迭代 10 到 20 之间的数字
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
print ('%d 等于 %d * %d' % (num,i,j))
break # 跳出当前循环
else: # 循环的 else 部分
print ('%d 是一个质数' % num)
输出:
20 等于 2 * 10
21 等于 3 * 7
22 等于 2 * 11
23 是一个质数
24 等于 2 * 12
25 等于 5 * 5
26 等于 2 * 13
27 等于 3 * 9
28 等于 2 * 14
29 是一个质数
32、经典案例-for循环绘图
我们来使用学习到的for循环,绘制不同的图案,帮助大家进一步熟悉for循环用法
空心等边三角形
rows = int(input('输入列数: '))
print("打印空心等边三角形,这里去掉if-else条件判断就是实心的")
for i in range(0, rows + 1):#变量i控制行数
for j in range(0, rows - i):#(1,rows-i)#row如果为4,则第一行输出3空格
print(" ", end='')#不换行输出,换行空格
j =j + 1
for k in range(0, 2 * i - 1):#(1,2*i-1),
if k == 0 or k == 2 * i - 2 or i == rows:
if i == rows:
if k % 2 == 0:#因为第一个数是从0开始的,所以要是偶数打印*,奇数打印空格
print("*1", end='')
else:
print(" 2", end='')#注意这里的", end='' ",一定不能省略,可以起到不换行的作用
else:
print("*3", end='')
else:
print(" 4", end='')
k += 1
print("\
")
i += 1
输出:
*3
*3 4*3
*3 4 4 4*3
*1 2*1 2*1 2*1
菱形
#菱形
print("打印空心等菱形,这里去掉if-else条件判断就是实心的")
rows = int(input('输入列数: '))
for i in range(rows):#变量i控制行数
for j in range(rows - i):#(1,rows-i)
print(" ", end='')
j += 1
for k in range(2 * i - 1):#(1,2*i)
if k == 0 or k == 2 * i - 2:
print("*", end='')
else:
print(" ", end='')
k += 1
print("\
")
i += 1
#菱形的下半部分
for i in range(rows):
for j in range(i):#(1,rows-i)
print(" ", end='')
j += 1
for k in range(2 * (rows - i) - 1):#(1,2*i)
if k == 0 or k == 2 * (rows - i) - 2:
print("*", end='')
else:
print(" ", end='')
k += 1
print("\
")
i += 1
输出:
打印空心等菱形,这里去掉if-else条件判断就是实心的
输入列数: 3
*
* *
* *
* *
*
33、Python-break语句
Python break语句,打破了最小封闭的for或while循环。
break语句用来终止循环语句,即循环条件没有False条件或者序列还没被完全递归完,也会停止执行循环语句。
使用 continue 语句,可以跳过执行本次循环体中剩余的代码,转而执行下一次的循环。
在嵌套循环中,break语句将停止执行最深层的循环,可以完全终止当前循环,并开始执行下一循环代码。
for letter in 'Hellohworld': # 第一个实例
if letter == 'h':
print('当前字母 :', letter+letter)
break
print('当前字母 :', letter+letter+letter)
print('当前字母 :', letter)
var = 10 # 第二个实例
while var > 0:
print('当前变量值 :', var)
var = var -1
if var == 5: # 当变量 var 等于 5 时退出循环
print("before break")
break
print("after break1")
print("after break2")
print("完成!")
输出:
当前字母 : H
当前字母 : e
当前字母 : l
当前字母 : l
当前字母 : o
当前字母 : hh
当前变量值 : 10
当前变量值 : 9
当前变量值 : 8
当前变量值 : 7
当前变量值 : 6
before break
after break2
完成!
34、Python-continue语句
Python continue 语句用来告诉Python跳过当前循环的剩余语句,然后继续进行下一轮循环(而break是跳出整个循环)。
continue语句用在while和for循环中。

for letter in 'helloworld': # 第一个实例
if letter == 'h':
continue
print('当前字母 :', letter)
var = 7 # 第二个实例
while var > 0:
var = var -1
if var == 5:
continue
print('当前变量值 :', var)
print("完成!")
输出:
当前字母 : e
当前字母 : l
当前字母 : l
当前字母 : o
当前字母 : w
当前字母 : o
当前字母 : r
当前字母 : l
当前字母 : d
当前变量值 : 6
当前变量值 : 4
当前变量值 : 3
当前变量值 : 2
当前变量值 : 1
当前变量值 : 0
完成!
35、Python-pass语句
Python pass 是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句。

for letter in 'Hellohworld':
if letter == 'h':
pass
print('这是 pass 块')
print('当前字母 :', letter)
print("完成!")
输出:
当前字母 : H
当前字母 : e
当前字母 : l
当前字母 : l
当前字母 : o
这是 pass 块
当前字母 : h
当前字母 : w
当前字母 : o
当前字母 : r
当前字母 : l
当前字母 : d
完成!
36、Python字符串
字符串是 Python 中最常用的数据类型。我们可以使用引号(‘或”)来创建字符串。
37、Python访问字符串中的值
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。Python 访问子字符串
,
可以使用方括号配合索引来进行字符串切片。


str1 = 'Hello World!'
str2 = "Python ShowMeAI"
print("str1[0]: ", str1[0]) #index为0的字符
print("str2[1:5]: ", str2[1:5]) #从index为1开始到5结束(不包含5)
输出:
str1[0]: H
str2[1:5]: ytho
38、Python字符串连接
可以对字符串进行截取并与其他字符串进行连接
str1 = 'Hello World!'
print("输出 :", str1[:6] + 'ShowMeAI!')
输出 : Hello ShowMeAI!
39、Python转义字符
在需要在字符中使用特殊字符时,python 用反斜杠 \ 转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| (在行尾时) | 续行符 |
| \ | 反斜杠符号,代码行换行 |
| \’ | 单引号 |
| \” | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | |
| 换行 | |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 |
| \xyy | 十六进制数,以 \x 开头,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |

40、Python字符串运算符
下表实例变量 a 值为字符串 “Hello”,b 变量值为 “Python”:
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | >>>a + b ‘HelloPython’ |
| * | 重复输出字符串 | >>>a * 2 ‘HelloHello’ |
| [] | 通过索引获取字符串中字符 | >>>a[1] ‘e’ |
| [ : ] | 截取字符串中的一部分 | >>>a[1:4] ‘ell’ |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | >>>”H” in a True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | >>>”M” not in a True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母”r”(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | >>>print r’\ |
a='hello'
b='world'
print(a+b)
print(a*2)
print(a[1])
print(a[1:4])
print('h' in a)
print('m' not in a)
print('m' in a)
print('\r')
输出:
helloworld
hellohello
e
ell
True
True
False
41、Python字符串格式化
Python 支持格式化字符串的输出。
(1)基础用法
最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
print("The website is %s and the author's age is %d!" % ('A1', 21) )
输出:The website is A1 and the author's age is 21!
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %F 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| 在正数前面显示空格 | |
| # | 在八进制数前面显示零(‘0’),在十六进制前面显示’0x’或者’0X’(取决于用的是’x’还是’X’) |
| 0 | 显示的数字前面填充’0’而不是默认的空格 |
| % | ‘%%’输出一个单一的’%’ |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
(2)format格式化字符串
Python还有一种格式化字符串的函数str.format(),它增强了字符串格式化的功能,基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序。
print("{} {}".format("hello", "ShowMeAI"))
print("{0} {1}".format("hello", "ShowMeAI"))
print("{1} {0} {1}".format("hello", "ShowMeAI"))
print("网站名:{name}, 地址 {url}".format(name="B站", url="www.bilibili.com"))
# 通过字典设置参数
site = {"name": "B站", "url": "www.bilibili.com"}
print("网站名:{name}, 地址 {url}".format(**site))
# 通过列表索引设置参数
my_list = ['B站', 'www.bilibili.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的
输出:
hello ShowMeAI
hello ShowMeAI
ShowMeAI hello ShowMeAI
网站名:B站, 地址 www.bilibili.com
网站名:B站, 地址 www.bilibili.com
网站名:B站, 地址 www.bilibili.com
format还可以对数字进行格式化,下表展示了 str.format() 格式化数字的多种方法:
print("{:.2f}".format(3.1415926))
输出:3.14
| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
| 3.1415926 | {:+.2f} | +3.14 | 带符号保留小数点后两位 |
| -1 | {:+.2f} | -1.00 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 不带小数 |
| 5 | {:0>2d} | 05 | 数字补零 (填充左边, 宽度为2) |
| 5 | {:x<4d} | 5xxx | 数字补x (填充右边, 宽度为4) |
| 10 | {:x<4d} | 10xx | 数字补x (填充右边, 宽度为4) |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00e+09 | 指数记法 |
| 13 | {:>10d} | 13 | 右对齐 (默认, 宽度为10) |
| 13 | {:<10d} | 13 | 左对齐 (宽度为10) |
| 13 | {:^10d} | 13 | 中间对齐 (宽度为10) |
| 11 | '{:b}'.format(11)'{:d}'.format(11)'{:o}'.format(11)'{:x}'.format(11)'{:#x}'.format(11)'{:#X}'.format(11) | 10111113b0xb0XB | 进制 |
^, <, > 分别是居中、左对齐、右对齐,后面带宽度, : 号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充。
+ 表示在正数前显示 +,负数前显示 -; (空格)表示在正数前加空格
b、d、o、x 分别是二进制、十进制、八进制、十六进制。
此外我们可以使用大括号 {} 来转义大括号
print("{} 对应的优先级是 {{0}}".format("ShowMeAI"))
输出:ShowMeAI 对应的优先级是 {0}
(3)Python三引号
Python 中三引号可以将复杂的字符串进行赋值。
Python 三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。
三引号的语法是一对连续的单引号或者双引号
hi = '''hi there''' print(hi)
输出:
hi
there
三引号让程序员从引号和特殊字符串的泥潭里面解脱出来,自始至终保持一小块字符串的格式是所谓的WYSIWYG(所见即所得)格式的。
一个典型的用例是,当你需要一块HTML或者SQL时,这时当用三引号标记,使用传统的转义字符体系将十分费神。
errHTML = '''
<HTML><HEAD><TITLE>
Friends CGI Demo</TITLE></HEAD>
<BODY><H3>ERROR</H3>
<B>%s</B><P>
<FORM><INPUT TYPE=button VALUE=Back
ONCLICK="window.history.back()"></FORM>
</BODY></HTML>
'''
cursor.execute('''
CREATE TABLE users (
login VARCHAR(8),
uid INTEGER,
prid INTEGER)
''')
42、Unicode字符串
Python 中定义一个 Unicode 字符串和定义一个普通字符串一样简单;若引号前小写的”u”表示这里创建的是一个 Unicode 字符串。如果你想加入一个特殊字符,可以使用 Python 的 Unicode-Escape 编码。如下例所示:
u1='Hello World !' u2='Hello\u0020World !' print(u1) print(u2)
输出:
Hello World !
Hello World !
被替换的 \u0020 标识表示在给定位置插入编码值为 0x0020 的 Unicode 字符(空格符)
43、python的字符串内建函数
字符串方法是从python1.6到2.0慢慢加进来的——它们也被加到了Jython中。
这些方法实现了string模块的大部分方法,如下表所示列出了目前字符串内建支持的方法,所有的方法都包含了对Unicode的支持,有一些甚至是专门用于Unicode的。
| 方法 | 描述 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
| string.count(str, beg=0, end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| string.decode(encoding=’UTF-8’, errors=’strict’) | 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 ‘ignore’ 或 者’replace’ |
| string.encode(encoding=’UTF-8’, errors=’strict’) | 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace’ |
| string.endswith(obj, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| string.expandtabs(tabsize=8) | 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
| string.find(str, beg=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.format() | 格式化字符串 |
| string.index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在 string中会报一个异常. |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False |
| string.isdecimal() | 如果 string 只包含十进制数字则返回 True 否则返回 False. |
| string.isdigit() | 如果 string 只包含数字则返回 True 否则返回 False. |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| string.isnumeric() | 如果 string 中只包含数字字符,则返回 True,否则返回 False |
| string.isspace() | 如果 string 中只包含空格,则返回 True,否则返回 False. |
| string.istitle() | 如果 string 是标题化的(见 title())则返回 True,否则返回 False |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| string.lower() | 转换 string 中所有大写字符为小写. |
| string.lstrip() | 截掉 string 左边的空格 |
| string.maketrans(intab, outtab]) | maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| max(str) | 返回字符串 str 中最大的字母。 |
| min(str) | 返回字符串 str 中最小的字母。 |
| string.partition(str) | 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
| string.replace(str1, str2, num=string.count(str1)) | 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
| string.rfind(str, beg=0,end=len(string) ) | 类似于 find() 函数,返回字符串最后一次出现的位置,如果没有匹配项则返回 -1。 |
| string.rindex( str, beg=0,end=len(string)) | 类似于 index(),不过是从右边开始. |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
| string.rpartition(str) | 类似于 partition()函数,不过是从右边开始查找 |
| string.rstrip() | 删除 string 字符串末尾的空格. |
| string.split(str=””, num=string.count(str)) | 以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+1 个子字符串 |
| string.splitlines([keepends]) | 按照行(‘\r’, ‘\r\‘, \‘)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
string.startswith(obj, beg=0,end=len(string))检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。
string.strip([obj])在 string 上执行 lstrip()和 rstrip()
string.swapcase()翻转 string 中的大小写
string.title()返回”标题化”的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle())
string.translate(str, del=””)根据 str 给出的表(包含 256 个字符)转换 string 的字符,要过滤掉的字符放到 del 参数中.
string.upper()转换 string 中的小写字母为大写
string.zfill(width)返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0
string = 'uUUPpp' print(string.upper()) print(string.capitalize())
输出:
UUUPPP
Uuuppp
44、Python列表(List)
序列是Python中最基本和常见的数据结构。序列中的每个元素都分配一个数字 - 【它的位置,或索引】,第一个索引是0,第二个索引是1,依此类推。
序列都可以进行的操作包括索引,切片,加,乘,检查成员。
此外,Python已经内置确定序列的长度以及确定最大和最小的元素的方法。
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型。
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
(1)访问列表中的值
使用下标索引来访问列表中的值,可以使用方括号的形式截取子列表。
list1 = ['python', 'ShowMeAI', 1997, 2022]
list2 = [1, 2, 3, 4, 5, 6, 7 ]
print("list1[0]: ", list1[0])
print("list2[1:5]: ", list2[1:5])
输出:
list1[0]: python
list2[1:5]: [2, 3, 4, 5]
list = ['red', 'green', 'blue', 'yellow', 'white', 'black'] print( list[-1] ) print( list[:-2] ) print( list[-3:] )
输出:
black
['red', 'green', 'blue', 'yellow']
['yellow', 'white', 'black']
(2)更新列表
可以对列表的数据项进行修改或更新,也可以使用append()方法来添加列表项,如下所示
list = [] # 空列表
list.append('Google') # 使用 append() 添加元素
list.append('ShowMeAI')
print(list)
输出:
['Google', 'ShowMeAI']
(3)删除列表元素
可以使用 del 语句来删除列表的元素,如下所示
list1 = ['python', 'ShowMeAI', 1997, 2022]
print(list1)
del list1[2]
print("删除索引为2的元素后 : ")
print(list1)
输出:
['python', 'ShowMeAI', 1997, 2022]
删除索引为2的元素后 :
['python', 'ShowMeAI', 2022]
(4)Python列表脚本操作符
列表对 + 和 的操作符与字符串相似。+ 号用于组合列表, 号用于重复列表。
如下所示:
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| [‘Hi!’] * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print x, | 1 2 3 | 迭代 |
(5)Python列表截取
Python 的列表截取实例如下:
L = ['Google', 'ShowMeAI', 'Baidu'] print(L[2]) print(L[-2]) print(L[1:])
输出:
Baidu
ShowMeAI
['ShowMeAI', 'Baidu']
(6)Python列表函数方法
Python包含以下函数:
| 序号 | 函数 | 作用 |
|---|---|---|
| 1 | len(list) | 列表元素个数 |
| 2 | max(list) | 返回列表元素中索引值最大的值 |
| 3 | min(list) | 返回列表元素中索引值最小的值 |
| 4 | list(seq) | 将元组转换为列表 |
# 示例1:长度
list1, list2 = [123, 'ShowMeAI', 'google'], [456, 'abc']
print("第1个列表长度 : ", len(list1))
print("第2个列表长度 : ", len(list2))
输出:
第1个列表长度 : 3
第2个列表长度 : 2
# 示例2:最大最小值
list1, list2 = ['Baidu', 'ShowMeAI', 'google'], [456, 789, 200]
print("第1个列表最大值 : ", max(list1))
print("第1个列表最小值 : ", min(list1))
print("第2个列表最大值 : ", max(list2))
print("第2个列表最小值 : ", min(list2))
输出:
第1个列表最大值 : n
第1个列表最小值 : Baidu
第2个列表最大值 : 789
第2个列表最小值 : 200
# 示例3:转列表
aTuple = (123, 'ShowMeAI', 'google', 'Baidu');
aList = list(aTuple)
print("列表元素 : ")
print(aTuple)
print(aList)
输出:
列表元素 :
(123, 'ShowMeAI', 'google', 'Baidu')
[123, 'ShowMeAI', 'google', 'Baidu']
Python包含以下方法:
| 序号 | 方法 | 作用 |
|---|---|---|
| 1 | list.append(obj) | 在列表末尾添加新的对象 |
| 2 | list.count(obj) | 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) | 将对象插入列表 |
| 6 | list.pop([index=-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) | 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() | 反向列表中元素 |
| 9 | list.sort(cmp=None, key=None, reverse=False) | 对原列表进行排序 |
aList = ['Baidu', 'ShowMeAI', 'google']
print("aList : ", aList)
aList.append( 'ByteDance' )
aList += ['ShowMeAI']
print("经过append和+计算后的aList : ", aList)
print("统计ShowMeAI个数 : ", aList.count('ShowMeAI'))
aList.extend(['Taobao', 'Tencent'])
print("经过extend后的aList : ", aList)
print("使用index查找Taobao的索引位置: ", aList.index('Taobao'))
aList.insert( 3, 'DiDi')
print("在index为3的位置insert元素后的aList : ", aList)
print("aList pop出的元素: ", aList.pop())
aList.remove('ShowMeAI')
print("aList用remove删除第1个匹配到的ShowMeAI后: ", aList)
aList.reverse()
print("aList使用reverse逆序后的结果: ", aList)
aList.sort()
print("aList使用sort排序后的结果: ", aList)
输出:
aList : ['Baidu', 'ShowMeAI', 'google']
经过append和+计算后的aList : ['Baidu', 'ShowMeAI', 'google', 'ByteDance', 'ShowMeAI']
统计ShowMeAI个数 : 2
经过extend后的aList : ['Baidu', 'ShowMeAI', 'google', 'ByteDance', 'ShowMeAI', 'Taobao', 'Tencent']
使用index查找Taobao的索引位置: 5
在index为3的位置insert元素后的aList : ['Baidu', 'ShowMeAI', 'google', 'DiDi', 'ByteDance', 'ShowMeAI', 'Taobao', 'Tencent']
aList pop出的元素: Tencent
aList用remove删除第1个匹配到的ShowMeAI后: ['Baidu', 'google', 'DiDi', 'ByteDance', 'ShowMeAI', 'Taobao']
aList使用reverse逆序后的结果: ['Taobao', 'ShowMeAI', 'ByteDance', 'DiDi', 'google', 'Baidu']
aList使用sort排序后的结果: ['Baidu', 'ByteDance', 'DiDi', 'ShowMeAI', 'Taobao', 'google']
45、Python元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
tup1 = ('ByteDance', 'ShowMeAI', 1997, 2022)
tup2 = (1, 2, 3, 4, 5 )
tup3 = "a", "b", "c", "d"
# 创建空元组
tup1 = ()
#元组中只包含一个元素时,需要在元素后面添加逗号
tup1 = (50,)
元组与字符串类似,下标索引从0开始,可以进行截取,组合等。
(1)访问元组
元组可以使用下标索引来访问元组中的值。
tup1 = ('python', 'ShowMeAI', 1997, 2022)
tup2 = (1, 2, 3, 4, 5, 6, 7)
print("tup1[0]: ", tup1[0])
print("tup2[1:5]: ", tup2[1:5])
输出:
tup1[0]: python
tup2[1:5]: (2, 3, 4, 5)
(2)修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合
tup1 = (12, 34.56)
tup2 = ('abc', 'xyz')
# 以下修改元组元素操作是非法的。
# tup1[0] = 100
# 创建一个新的元组
tup3 = tup1 + tup2
print(tup3)
输出:
(12, 34.56, 'abc', 'xyz')
(3)删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,
tup = ('python', 'ShowMeAI', 1997, 2022)
print(tup)
del tup
print("删除tup后 : ")
print(tup)
输出:
('python', 'ShowMeAI', 1997, 2022)
删除tup后 :
Traceback (most recent call last):
File "C:/Users/Apple/PycharmProjects/pythonProject2/sTudy.py", line 527, in <module>
print(tup)
NameError: name 'tup' is not defined
(4)元组运算符
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len((1, 2, 3)) | 3 | 计算元素个数 |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 |
| (‘Hi!’,) * 4 | (‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’) | 复制 |
| 3 in (1, 2, 3) | True | 元素是否存在 |
| for x in (1, 2, 3): print x, | 1 2 3 | 迭代 |
(5)元组索引,截取
因为元组也是一个序列,所以我们可以访问元组中的指定位置的元素,也可以截取索引中的一段元素。

(6)无关闭分隔符
任意无符号的对象,以逗号隔开,默认为元组,如下实例:
print('abc', -4.24e93, 18+6.6j, 'xyz')
x, y = 1, 2
print("Value of x , y : ", x,y)
输出:
abc -4.24e+93 (18+6.6j) xyz
Value of x , y : 1 2
(7)元组内置函数
Python元组包含了以下内置函数
| 序号 | 方法 | 作用 |
|---|---|---|
| 1 | cmp(tuple1, tuple2) | 比较两个元组元素。 |
| 2 | len(tuple) | 计算元组元素个数。 |
| 3 | max(tuple) | 返回元组中元素最大值。 |
| 4 | min(tuple) | 返回元组中元素最小值。 |
| 5 | tuple(seq) | 将列表转换为元组。 |
46、Python字典(Dictionary)
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }

dict = {'a': 1, 'b': 2, 'b': '3'}
print(dict['b'])
输出:3
键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
dict = {'a': 1, 'b': 2, 'b': '3'}
print(dict['b'])
print(dict)
输出:
3
{'a': 1, 'b': '3'}

值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
dict1 = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
dict2 = { 'abc': 123, 98.6: 37, (1,2):345 }
print(dict1['Alice'])
print(dict1['Beth'])
print(dict1['Cecil'])
print(dict2['abc'])
输出:
2341
9102
3258
123

(1)访问字典里的值
dict = {'Name': 'ShowMeAI', 'Color': 'Blue', 'Class': 'First'}
print("dict['Name']: ", dict['Name'])
print("dict['Color']: ", dict['Color'])
输出:
dict['Name']: ShowMeAI
dict['Color']: Blue
(2)修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值如下代码示例
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
dict['Age'] = 8 # 更新
dict['School'] = "ShowMeAI" # 添加
print("dict['Age']: ", dict['Age'])
print("dict['School']: ", dict['School'])
输出:
dict['Age']: 8
dict['School']: ShowMeAI
(3)删除字典元素
能删单一的元素也能清空字典,清空只需一项操作。
显示删除一个字典用del命令,如下实例:
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
del dict['Name'] # 删除键是'Name'的条目
dict.clear() # 清空字典所有条目
del dict # 删除字典
print("dict['Age']: ", dict['Age'])
print("dict['School']: ", dict['School'])
输出:
Traceback (most recent call last):
File "C:/Users/Apple/PycharmProjects/pythonProject2/sTudy.py", line 558, in <module>
print("dict['Age']: ", dict['Age'] )
TypeError: 'type' object is not subscriptable
(4)字典键的特性
字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会更新前一个,如下实例:
dict = {'Name': 'Zara', 'Age': 7, 'Name': 'ShowMeAI'}
print("dict['Name']: ", dict['Name'])
输出:
dict['Name']: ShowMeAI
2)键必须不可变,所以可以用数字,字符串或元组充当,所以用列表就不行,如下实例:
dict = {['Name']: 'Zara', 'Age': 7}
print("dict['Name']: ", dict['Name'])
输出:
Traceback (most recent call last):
File "C:/Users/Apple/PycharmProjects/pythonProject2/sTudy.py", line 564, in <module>
dict = {['Name']: 'Zara', 'Age': 7}
TypeError: unhashable type: 'list'
(5)字典内置函数与方法
Python字典包含了以下内置函数:
| 函数及描述 | 作用 |
|---|---|
| cmp(dict1, dict2) | 比较两个字典元素。 |
| len(dict) | 计算字典元素个数,即键的总数。 |
| str(dict) | 输出字典可打印的字符串表示。 |
| type(variable) | 返回输入的变量类型,如果变量是字典就返回字典类型。 |
Python字典包含了以下内置方法:
| 函数及描述 | 作用 |
|---|---|
| dict.clear() | 删除字典内所有元素 |
| dict.copy() | 返回一个字典的浅复制 |
| dict.fromkeys(seq[, val]) | 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| dict.get(key, default=None) | 返回指定键的值,如果值不在字典中返回default值 |
| dict.has_key(key) | 如果键在字典dict里返回true,否则返回false |
| dict.items() | 返回可遍历的(键, 值) 元组数组的视图对象 |
| dict.keys() | 返回一个字典所有的键的视图对象 |
| dict.setdefault(key, default=None) | 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| dict.update(dict2) | 把字典dict2的键/值对更新到dict里 |
| dict.values() | 返回字典中的所有值的视图对象 |
| pop(key[,default]) | 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| popitem() | 返回并删除字典中的最后一对键和值。 |
47、Python集合
集合(Set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。

(1)集合的基本操作


(1)添加元素
语法格式如下:
s.add( x )
将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
company = set(("Google", "ShowMeAI", "Taobao"))
company.add("Facebook")
print(company)
输出:{'Taobao', 'Facebook', 'Google', 'ShowMeAI'}
还有一个方法,也可以添加元素,且参数可以是列表,元组,字典等,语法格式如下:
s.update(x)
x 可以有多个,用逗号分开。
company = set(("Google", "ShowMeAI", "Taobao"))
company.update({"Facebook", "LinkedIn"})
print(company)
company.update([1,4],[5,6])
print(company)
输出:{'Facebook', 'Taobao', 'LinkedIn', 'Google', 'ShowMeAI'}
{1, 4, 'Taobao', 5, 'LinkedIn', 6, 'Google', 'ShowMeAI', 'Facebook'}
(2)移除元素
语法格式如下:
s.remove(x)
将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。
company = set(("Google", "ShowMeAI", "Taobao"))
company.remove("Taobao")
print(company)
输出:{'Google', 'ShowMeAI'}
company.remove("Facebook")
输出:
Traceback (most recent call last):
File "C:/Users/Apple/PycharmProjects/pythonProject2/sTudy.py", line 580, in <module>
company.remove("Facebook")
KeyError: 'Facebook'
此外还有一个方法也是移除集合中的元素,且如果元素不存在,不会发生错误。格式如下所示:
s.discard(x)
company = set(("Google", "ShowMeAI", "Taobao"))
company.discard("Facebook")
print(company)
输出:{'Google', 'ShowMeAI', 'Taobao'}
我们也可以设置随机删除集合中的一个元素,语法格式如下:
s.pop()
company = set(("Google", "ShowMeAI", "Taobao", "Facebook"))
x = company.pop()
print(x)
输出:ShowMeAI
多次执行测试结果都不一样。
set 集合的 pop 方法会对集合进行无序的排列,然后将这个无序排列集合的左面第一个元素进行删除。
(3)计算集合元素个数
语法格式如下:
len(s)
计算集合 s 元素个数。
company = set(("Google", "ShowMeAI", "Taobao", "Facebook"))
print(len(company))
输出:4
(4)清空集合
语法格式如下:
s.clear()
清空集合 s。
company = set(("Google", "ShowMeAI", "Taobao", "Facebook"))
company.clear()
print(company)
输出:set()
(5)判断元素是否在集合中存在
语法格式如下:
x in s
判断元素 x 是否在集合 s 中,存在返回 True,不存在返回 False。
company = set(("Google", "ShowMeAI", "Taobao", "Facebook"))
print("Facebook" in company)
输出:True
(6)集合内置方法完整列表
| 方法 | 描述 |
|---|---|
| add() | 为集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| discard() | 删除集合中指定的元素 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素 |
| symmetric_difference() | 返回两个集合中不重复的元素集合。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
| update() | 给集合添加元素 |
48、Python函数
(1)定义一个函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号 : 起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方,不带表达式的 return 相当于返回 None。
def AorB (a,b):
if a > b:
return a
else:
return b
print(AorB(6,3))
输出:6
计算面积函数,如下为示例代码
# 计算面积函数
def a_area(width, height):
return width * height
def a_welcome(name):
print("Welcome", name)
a_welcome("ShowMeAI")
w = 4
h = 5
print("width =", w, " height =", h, " area =", a_area(w, h))
输出:
Welcome ShowMeAI
width = 4 height = 5 area = 20
(2)函数调用
定义一个函数:给了函数一个名称,指定了函数里包含的参数,和代码块结构。
这个函数的基本结构完成以后,你可以通过另一个函数调用执行,也可以直接从 Python 命令提示符执行
# 定义函数
def print_myself(str):
# 打印任何传入的字符串
print (str)
return
# 调用函数
print_myself("调用用户自定义函数!")
print_myself("再次调用同一函数")
输出:
调用用户自定义函数!
再次调用同一函数
(3)参数传递
在 python 中,类型属于对象,变量是没有类型的:
a=[1,2,3] a="ShowMeAI"
[1,2,3] 是 List 类型,“ShowMeAI” 是 String 类型,而变量 a 是没有类型,它仅仅是一个对象的引用(一个指针),可以是指向 List 类型对象,也可以是指向 String 类型对象。
(4)可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
- 不可变类型:变量赋值 a=10 后再赋值 a=5,这里实际是新生成一个 int 值对象 5,再让 a 指向它,而 10 被丢弃,不是改变 a 的值,相当于新生成了 a。
- 可变类型:变量赋值 l=[1,2,3,4] 后再赋值 l[2]=5 则是将 list l 的第三个元素值更改,本身l没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
- 不可变类型:类似 C++ 的值传递,如整数、字符串、元组。如 func(a),传递的只是 a 的值,没有影响 a 对象本身。如果在 func(a) 内部修改 a 的值,则是新生成一个 a 的对象。
- 可变类型:类似 C++ 的引用传递,如 列表,字典。如 func(l),则是将 l 真正的传过去,修改后 func 外部的 l 也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
(5)python传不可变对象实例
通过 id() 函数来查看内存地址变化:
def my_change(a):
print(id(a)) # 指向的是同一个对象
a=10
print(id(a)) # 一个新对象
a=5
print(id(a))
my_change(a)
输出:
140730102650768
140730102650768
140730102650928
可以看见在调用函数前后,形参和实参指向的是同一个对象(对象 id 相同),在函数内部修改形参后,形参指向的是不同的 id。
(6)传可变对象实例
可变对象在函数里修改了参数,那么在调用这个函数的函数里,原始的参数也被改变了。如下为示例代码
def change_list(mylist):
# "修改传入的列表"
mylist.append([1,2,3,4])
print("函数内取值:",mylist)
return
# 调用changeme函数
mylist=[10,20,30]
change_list(mylist)
print("函数外取值:",mylist)
输出:
函数内取值: [10, 20, 30, [1, 2, 3, 4]]
函数外取值: [10, 20, 30, [1, 2, 3, 4]]
(7)参数
以下是调用函数时可使用的正式参数类型:
- 必需参数
- 关键字参数
- 默认参数
- 不定长参数
(8)必需参数
必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
调用 print_myself() 函数,你必须传入一个参数,不然会出现语法错误:
def print_myself( str ): # "打印任何传入的字符串" print(str) return # 调用 print_myself 函数,不加参数会报错 print_myself()
输出:Traceback (most recent call last):
File "C:/Users/Apple/PycharmProjects/pythonProject2/sTudy.py", line 650, in <module>
print_myself()
TypeError: print_myself() missing 1 required positional argument: 'str'
(9)关键字参数
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
以下实例在函数 print_myself() 调用时使用参数名:
def print_myself( str ): #"打印任何传入的字符串" print(str) return #调用print_myself函数 print_myself( str = "大家周五下午好!")
输出:大家周五下午好!
以下示例代码中演示了函数参数的使用不需要使用指定顺序:
def print_info(name,age):
#"打印任何传入的字符串"
print ("名字:",name)
print ("年龄:",age)
return
#调用print_info函数
print_info( age=30, name="ShowMeAI")
输出:
名字: ShowMeAI
年龄: 30
(10)默认参数
调用函数时,如果没有传递参数,则会使用默认参数。以下代码中如果没有传入 age 参数,则使用默认值:
def print_info(name,age = 35 ):
#"打印任何传入的字符串"
print ("名字: ",name)
print ("年龄: ",age)
return
#调用print_info函数
print_info(age=30,name="M1")
print("------------------------")
print_info(name="M2")
输出:
名字: M1
年龄: 30
------------------------
名字: M2
年龄: 35
(11)不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述 2 种参数不同,声明时不会命名。基本语法如下:
def function_name([formal_args,] *var_args_tuple ): "函数_文档字符串" function_suite return [expression]
加了星号 * 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数。
def print_info(arg1,*vartuple):
# "打印任何传入的参数"
print("输出:")
print(arg1)
print(vartuple)
# 调用print_info 函数
print_info(100,90,80)
输出:
100
(90, 80)
如果在函数调用时没有指定参数,它就是一个空元组。我们也可以不向函数传递未命名的变量。如下代码:
def print_info(arg1,*vartuple):
# "打印任何传入的参数"
print("输出:")
print(arg1)
for var in vartuple:
print (var)
print(vartuple)
return
# 调用printinfo 函数
print_info(100)
print_info(90,80,70)
输出:
100
输出:
90
80
(80, 70)
70
(80, 70)
还有一种就是参数带两个星号 **基本语法如下:
def function_name([formal_args,] **var_args_dict ): "函数_文档字符串" function_suite return [expression]
加了两个星号 ** 的参数会以字典的形式导入。
def print_info( arg1, **vardict ):
# "打印任何传入的参数"
print("输出: ")
print(arg1)
print(vardict)
# 调用print_info 函数
print_info(1, a=2,b=3)
输出:
1
{'a': 2, 'b': 3}
声明函数时,参数中星号 * 可以单独出现,例如:
def f(a, b, *, c): return a + b + c a=1 b=2 print(f(a,b,c=3))
输出:6
如果单独出现星号 * 后的参数必须用关键字传入。
def f(a,b,*,c): return a+b+c f(1,2,c=3) # 正常 # f(1,2,3) # 报错
(12)匿名函数
python 使用 lambda 来创建匿名函数。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。

语法:lambda 函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
实例:
my_sum = lambda arg1, arg2: arg1 + arg2
# 调用my_sum函数
print ("相加后的值为 : ", my_sum( 10, 20 ))
print ("相加后的值为 : ", my_sum( 20, 20 ))
输出:
相加后的值为 : 30
相加后的值为 : 40
(13)return语句
return [表达式] 语句用于退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。之前的例子都没有示范如何返回数值,以下实例演示了 return 语句的用法:
def my_sum( arg1, arg2 ):
# 返回2个参数的和."
total = arg1 + arg2
print("函数内 : ", total)
return total
# 调用sum函数
total = my_sum( 10, 20 )
print("函数外 : ", total)
输出:
函数内 : 30
函数外 : 30
(14)强制位置参数
Python3.8+ 新增了一个函数形参语法 / 用来指明函数形参必须使用指定位置参数,不能使用关键字参数的形式。
在以下的例子中,形参 a 和 b 必须使用指定位置参数,c 或 d 可以是位置形参或关键字形参,而 e 和 f 要求为关键字形参:
def f(a, b, /, c, d, *, e, f): print(a, b, c, d, e, f)
以下使用方法是正确的:
f(10, 20, 30, d=40, e=50, f=60)
以下使用方法会发生错误:
f(10, b=20, c=30, d=40, e=50, f=60) # b 不能使用关键字参数的形式 f(10, 20, 30, 40, 50, f=60) # e 必须使用关键字参数的形式
49、迭代器与生成器
(1)Python迭代器
迭代是Python最强大的功能之一,是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退

迭代器有两个基本的方法:iter() 和 next(),从Python3开始,要用__iter__和__next__。
字符串,列表或元组对象都可用于创建迭代器:
list=[1,2,3,4] it = iter(list) # 创建迭代器对象 print(next(it)) # 输出迭代器的下一个元素1 print(next(it)) # 输出迭代器的下一个元素2
输出:
1
2
迭代器对象可以使用常规for语句进行遍历
l=['Baidu', 'ShowMeAI', 'google', 'ByteDance'] it = iter(l) # 创建迭代器对象 for x in it: print(x)
执行以上程序,输出结果如下:
Baidu
ShowMeAI
google
ByteDance
也可以使用 next() 函数
list=['Baidu', 'ShowMeAI', 'google', 'ByteDance']
it = iter(list) # 创建迭代器对象
while True:
try:
print(next(it))
except StopIteration:
break
执行以上程序,输出结果如下:
Baidu
ShowMeAI
google
ByteDance
(2)创建一个迭代器
把一个类作为一个迭代器使用需要在类中实现两个方法 iter() 与 next() 。
如果你已经了解的面向对象编程,就知道类都有一个构造函数,Python 的构造函数为 init(), 它会在对象初始化的时候执行。
iter() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 next() 方法并通过 StopIteration 异常标识迭代的完成。
next() 方法(Python 2 里是 next())会返回下一个迭代器对象。
创建一个返回数字的迭代器,初始值为 1,逐步递增 1
class IterNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
x = self.a
self.a += 1
return x
num_class = IterNumbers()
iter_num = iter(num_class)
print(next(iter_num))
print(next(iter_num))
print(next(iter_num))
print(next(iter_num))
print(next(iter_num))
print(next(iter_num))
输出:
1
2
3
4
5
6
(3)StopIteration
StopIteration 异常用于标识迭代的完成,防止出现无限循环的情况,在 next() 方法中我们可以设置在完成指定循环次数后触发 StopIteration 异常来结束迭代。
在 4 次迭代后停止执行
class IterNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
if self.a <= 4:
x = self.a
self.a += 1
return x
else:
raise StopIteration
num_class = IterNumbers()
iter_num = iter(num_class)
for x in iter_num:
print(x)
输出:
1
2
3
4
(4)生成器
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作。

在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
以下实例使用 yield 实现斐波那契数列
def fibonacci(n): # 生成器函数 - 斐波那契
# a, b, counter = 0, 1, 0
a=0
b=1
counter=0
while True:
if(counter>n):
return
yield a
# a, b = b, a + b
a=b
b=a+b
counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True:
try:
print(next(f))
except StopIteration:
break
输出:
0
1
2
4
8
16
32
64
128
256
512
50、数据结构
(1)Python列表
Python中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能。

以下是 Python 中列表的方法:
| 方法 | 描述 |
|---|---|
| list.append(x) | 把一个元素添加到列表的结尾,相当于 a[len(a):] = [x]。 |
| list.extend(L) | 通过添加指定列表的所有元素来扩充列表,相当于 a[len(a):] = L。 |
| list.insert(i, x) | 在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引,例如 a.insert(0, x) 会插入到整个列表之前,而 a.insert(len(a), x) 相当于 a.append(x) 。 |
| list.remove(x) | 删除列表中值为 x 的第一个元素。如果没有这样的元素,就会返回一个错误。 |
| list.pop([i]) | 从列表的指定位置移除元素,并将其返回。如果没有指定索引,a.pop()返回最后一个元素。元素随即从列表中被移除。(方法中 i 两边的方括号表示这个参数是可选的,而不是要求你输入一对方括号,你会经常在 Python 库参考手册中遇到这样的标记。) |
| list.clear() | 移除列表中的所有项,等于del a[:]。 |
| list.index(x) | 返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误。 |
| list.count(x) | 返回 x 在列表中出现的次数。 |
| list.sort() | 对列表中的元素进行排序。 |
| list.reverse() | 倒排列表中的元素。 |
| list.copy() | 返回列表的浅复制,等于a[:]。 |
a = [2, 123, 123, 1, 1234.5]
print('''a.count(123), a.count(1), a.count('x'),a.count(2)''')
print(a.count(123), a.count(1), a.count('x'), "\
",a.count(2))
a.insert(2, -1)
print('''a.insert(2, -1)''')
print(a, "\
")
a.append(456)
print('''a.append(456)''')
print(a, "\
")
a.index(456)
print('''a.index(456)''')
print(a.index(456), "\
")
a.remove(456)
print('''a.remove(456)''')
print(a, "\
")
a.reverse()
print('''a.reverse()''')
print(a, "\
")
a.sort()
print('''a.sort()''')
print(a, "\
")
输出:
a.count(123), a.count(1), a.count('x'),a.count(2)
2 1 0 1
a.insert(2, -1)
[2, 123, -1, 123, 1, 1234.5]
a.append(456)
[2, 123, -1, 123, 1, 1234.5, 456]
a.index(456)
6
a.remove(456)
[2, 123, -1, 123, 1, 1234.5]
a.reverse()
[1234.5, 1, 123, -1, 123, 2]
a.sort()
[-1, 1, 2, 123, 123, 1234.5]
注意:类似 insert, remove 或 sort 等修改列表的方法没有返回值。
列表方法使得列表可以很方便的作为一个堆栈来使用,堆栈作为特定的数据结构,最先进入的元素最后一个被释放(后进先出)。用 append() 方法可以把一个元素添加到堆栈顶。用不指定索引的 pop() 方法可以把一个元素从堆栈顶释放出来。

stack = ['Baidu', 'ShowMeAI', 'google']
stack.append('ByteDance')
stack.append('Tencent')
print(stack)
stack.pop()
print('''stack.pop()''')
print(stack, "\
")
stack.pop()
print('''stack.pop()''')
print(stack, "\
")
stack.pop()
print('''stack.pop()''')
print(stack, "\
")
输出:
['Baidu', 'ShowMeAI', 'google', 'ByteDance', 'Tencent']
stack.pop()
['Baidu', 'ShowMeAI', 'google', 'ByteDance']
stack.pop()
['Baidu', 'ShowMeAI', 'google']
stack.pop()
['Baidu', 'ShowMeAI']
(2)将列表当做队列使用
也可以把列表当做队列用,只是在队列里第一加入的元素,第一个取出来;但是拿列表用作这样的目的效率不高。在列表的最后添加或者弹出元素速度快,然而在列表里插入或者从头部弹出速度却不快(因为所有其他的元素都得一个一个地移动)。

from collections import deque
queue = deque(['Baidu', 'ShowMeAI', 'google'])
queue.append('ByteDance')
queue.append('Tencent')
print(deque)
print('''queue.popleft()''')
print(queue.popleft(), "\
")
print('''queue.popleft()''')
print(queue.popleft(), "\
")
print(deque)
输出:
<class 'collections.deque'>
queue.popleft()
Baidu
queue.popleft()
ShowMeAI
<class 'collections.deque'>
备注:Python collections模块之deque()详解具体看这个Python collections模块之deque()详解_python collections.deque-CSDN博客
(3)列表推导式
列表推导式提供了从序列创建列表的简单途径。通常应用程序将一些操作应用于某个序列的每个元素,用其获得的结果作为生成新列表的元素,或者根据确定的判定条件创建子序列。

每个列表推导式都在 for 之后跟一个表达式,然后有零到多个 for 或 if 子句。返回结果是一个根据表达从其后的 for 和 if 上下文环境中生成出来的列表。如果希望表达式推导出一个元组,就必须使用括号。
vec = [1, 2, 3] # 将列表中每个数值乘三,获得一个新的列表: three_times_vec = [3*x for x in vec] print(three_times_vec) # 将列表中每个数值平方,并和原始值组成列表后再组成新的列表: cmp_x_square = [[x, x**2] for x in vec] print(cmp_x_square)
输出:[3, 6, 9]
[[1, 1], [2, 4], [3, 9]]
列表推导式还可以用来对序列里每一个元素都调用某函数方法:
fruits = ['banana', 'loganberry', 'apple'] print([x.upper() for x in fruits]) # fruits = ['banana', 'loganberry', 'apple'] # print([fruit.upper() for fruit in fruits])
输出:['BANANA', 'LOGANBERRY', 'APPLE']
还可以组合两个列表去使用列表推导式构建更复杂的结果
vec1 = [1, 2, 3] vec2 = [4, 5, 6] print([x*y for x in vec1 for y in vec2]) #两两相乘得到新列表 # 结果[4, 5, 6, 8, 10, 12, 12, 15, 18] print([x+y for x in vec1 for y in vec2]) #两两相加得到新列表 # 结果[5, 6, 7, 6, 7, 8, 7, 8, 9] print([vec1[i]*vec2[i] for i in range(len(vec1))]) #对应位置相乘得到新列表 # 结果[4, 10, 18]
输出:
[4, 5, 6, 8, 10, 12, 12, 15, 18]
[5, 6, 7, 6, 7, 8, 7, 8, 9]
[4, 10, 18]
(4)嵌套列表解析
Python的列表还可以嵌套。
以下代码展示了3X4的矩阵列表
matrix = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
]
# 将3X4的矩阵列表转换为4X3列表:
trans = [[row[i] for row in matrix] for i in range(4)]
print(trans)
# 等价于下列做法,但是上面的方式更简洁
transposed = []
for i in range(4):
transposed_row = []
for row in matrix:
transposed_row.append(row[i])
transposed.append(transposed_row)
print(transposed)
输出:
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
(5)del语句
使用 del 语句可以从一个列表中依索引而不是值来删除一个元素。这与使用 pop() 返回一个值不同。可以用 del 语句从列表中删除一个切割,或清空整个列表(我们以前介绍的方法是给该切割赋一个空列表)。例如:
a = [1, 2, 3, 456, 789, 1234.5] del a[0] print(a) del a[2:4] print(a) del a[:] print(a) 输出: [2, 3, 456, 789, 1234.5] [2, 3, 1234.5] []
(6)元组

(7)集合

集合是一个无序不重复元素的集。基本功能包括关系测试和消除重复元素。
可以用大括号({})创建集合。注意:如果要创建一个空集合,你必须用 set() 而不是 {} ;后者创建一个空的字典
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # 删除重复的
# 结果{'orange', 'banana', 'pear', 'apple'}
print('orange' in basket ) # 检测成员
# 结果True
print('crabgrass' in basket)
# 结果False
# 以下演示了两个集合的操作
a = set('abracadabra')
b = set('alacazam')
print(a) # a 中唯一的字母
# 结果{'a', 'r', 'b', 'c', 'd'}
print(a - b) # 在 a 中的字母,但不在 b 中
# 结果{'r', 'd', 'b'}
print(a | b) # 在 a 或 b 中的字母
# 结果{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
print(a & b) # 在 a 和 b 中都有的字母
# 结果{'a', 'c'}
print(a ^ b) # 在 a 或 b 中的字母,但不同时在 a 和 b 中
# 结果{'r', 'd', 'b', 'm', 'z', 'l'}
输出:
{'pear', 'banana', 'orange', 'apple'}
True
False
{'c', 'a', 'd', 'b', 'r'}
{'b', 'd', 'r'}
{'c', 'a', 'd', 'z', 'm', 'b', 'r', 'l'}
{'c', 'a'}
{'z', 'm', 'b', 'r', 'l', 'd'}
(8)字典

另一个非常有用的 Python 内建数据类型是字典。
序列是以连续的整数为索引,与此不同的是,字典以关键字为索引,关键字可以是任意不可变类型,通常用字符串或数值。
理解字典的最佳方式是把它看做无序的键=>值对集合。在同一个字典之内,关键字必须是互不相同。
一对大括号创建一个空的字典:{}。
company = {'ShowMeAI': 1234, 'Baidu': 5678}
company['guido'] = 4127
print(company)
# 结果{'Baidu': 5678, 'guido': 4127, 'ShowMeAI': 1234}
print(company['ShowMeAI'])
# 结果1234
del company['Baidu']
company['irv'] = 4127
print(company)
# 结果{'guido': 4127, 'irv': 4127, 'ShowMeAI': 1234}
print(list(company.keys()))
# 结果['irv', 'guido', 'ShowMeAI']
print(sorted(company.keys()))
# 结果['guido', 'irv', 'ShowMeAI']
print('guido' in company)
# 结果True
print('ShowMeAI' not in company)
# 结果False
输出:
{'ShowMeAI': 1234, 'Baidu': 5678, 'guido': 4127}
1234
{'ShowMeAI': 1234, 'guido': 4127, 'irv': 4127}
['ShowMeAI', 'guido', 'irv']
['ShowMeAI', 'guido', 'irv']
True
False
构造函数 dict() 直接从键值对元组列表中构建字典。此外,字典推导可以用来创建任意键和值的表达式词典:
print(dict([('ShowMeAI', 1234), ('Baidu', 5678)]))
print({x: x**2 for x in (2, 4, 6)})
输出:
{'ShowMeAI': 1234, 'Baidu': 5678}
{2: 4, 4: 16, 6: 36}
如果关键字只是简单的字符串,使用关键字参数指定键值对有时候更方便:
print(dict(ShowMeAI=1234, Baidu=5678))
输出:{'ShowMeAI': 1234, 'Baidu': 5678}
(9)遍历
在字典中遍历,关键字和对应的值可以使用items()方法同时解读起来:
company={'yd':123,'lt':456,'dx':789}
for k,v in company.items():
print(k,v)
输出:
yd 123
lt 456
dx 789
在序列中遍历时,索引位置和对应值可以使用 enumerate() 函数同时得到:
for i,v in enumerate(['a','b','c']):
print(i,v)
输出:
0 a
1 b
2 c
同时遍历两个或者更多的序列,使用zip()组合:
question=['name','age','color']
answer=['liming','40','red']
for q,a in zip(question,answer):
# print('What is the {0}? It is {1}.'.format(q, a))
print('what is the {0}? It is {1}.'.format(q,a))
输出:
what is the name? It is liming.
what is the age? It is 40.
what is the color? It is red.
要按顺序遍历一个序列,使用sorted()函数返回一个已排序的序列
basket = ['apple', 'orange', 'pear', 'banana'] for f in sorted(set(basket)): print(f)
输出:
apple
banana
orange
pear
51、模块
(1)Python模块
在程序开发过程中,文件代码越来越长,维护越不容易。我们把很多不同的功能编写成函数,放到不同的文件里,方便管理和调用。在Python中,一个.py文件就称之为一个模块(Module)。
使用模块可以大大提高了代码的可维护性,而且当一个模块编写完毕,就可以被其他地方引用。我们在使用python完成很多复杂工作时,也经常引用其他第3方模块,受益于强大的python社区,几乎我们完成任何一项任务,都可以有对应的方便快捷可引用的库和模块来协助。
(2)import语句
想要使用python模块,只需要在另一个原文件里执行import语句,语法如下:
import module1[,module2[,......,oduleN]]
当解释器遇到import语句,如果在当前的搜索路径能搜索到模块,就会直接导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。如果想要导入模块showmeai,需要把命令放在脚本的顶端。
(3)from...import语句
python的from语句能让你从模块中导入一个指定的部分到当前命名空间中,语法如下:
from modname import name1[,name2[,...nameN]]
例如,要导入模块fibo的fib和fib_new函数,使用如下语句
from fibo import fib,fib_new
--------
fibo.py文件:
def fib(n):
......
def fib_new(n):
......
(4)from ... import*语句
把一个模块中所有的内容全部导入到当前的命名空间中,也是可行的,只是需要使用如下的声明:
from modname import *
(5)包
包是一种管理Python模块命名空间的形式,我们经常会以「包.模块」的形式来导入模块,例如一个模块的名称是C.D, 那么他表示一个包C中的子模块D。使用这种形式不用担心不同库之间的模块重名的情况。
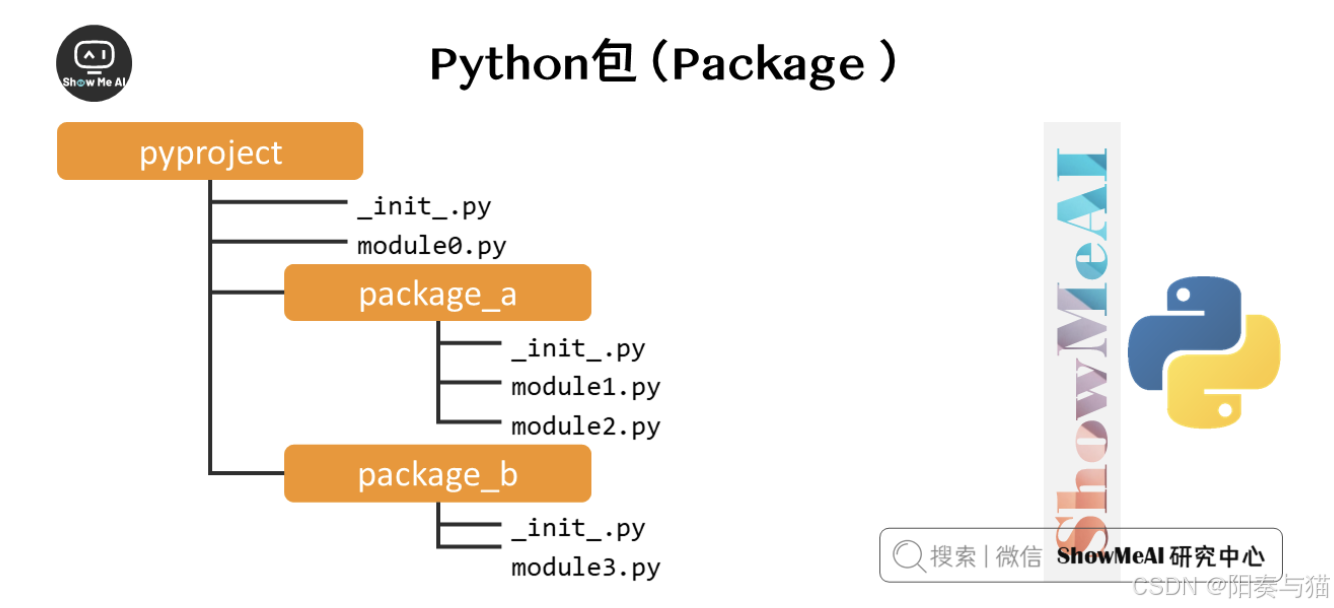
在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
目录只有包含一个叫做__init__.py 的文件才会被认作是一个包。最简单的处理是放一个空的__init__.py文件。
用户可以每次只导入一个包里面的特定模块,比如:
用户可以每次只导入一个包里面的特定模块,比如: import video.audio.io 这将会导入子模块:video.audio.io必须使用全名去访问: video.audio.io.readfile(input) 还有一种导入子模块的方法是: from video.audio import io 这同样会导入子模块:io,并且他不需要那些冗长的前缀,所以他可以这样使用: io.readfile(input) 还有一种变化就是直接导入一个函数或者变量: from video.audio.io import readfile 同样的,这种方法会导入子模块: io,并且可以直接使用他的 readfile() 函数: readfile(input)
当使用 from package import item 这种形式的时候,对应的 item 既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
import 语法会首先把 item 当作一个包定义的名称,如果没找到,再试图按照一个模块去导入。如果还没找到,抛出一个 exc:ImportError 异常。
如果我们使用形如 import item.subitem.subsubitem 这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









