






目录
一、从 “代码噩梦” 到 “积木游戏”:我与工作流的初次碰撞
一、从 “代码噩梦” 到 “积木游戏”:我与工作流的初次碰撞
作为一个计算机科学与技术专业的大三学生,我永远记得第一次听说ComfyUI时的困惑表情。"又一个可视化工具?"我当时的内心充满了不屑,"真正的程序员不都应该用代码搞定一切吗?"
这种傲慢在我安装ComfyUI的第一天就被彻底粉碎了。记得那是个周末的下午,我按照教程安装好ComfyUI后,面对空白的画布和侧边栏密密麻麻的节点选项,完全不知道从何下手。这与我想象中的"简单拖拽"相去甚远。
第一周的挫败感简直难以形容。我尝试复现一个基础的Stable Diffusion工作流,光是理解"CLIP文本编码"和"KSampler"之间的关系就花了两天时间。节点之间的连线总是出错,要么是数据类型不匹配,要么是忘记连接关键参数。有次我折腾了三个小时,就因为漏连了一个"latent_image"的输入。
# 这是我犯的第一个低级错误 - 漏连VAE解码器
# 错误示例:
wrong_workflow = {
"nodes": [
{"type": "CheckpointLoader", "id": 1},
{"type": "CLIPTextEncode", "id": 2, "text": "a cat"},
{"type": "KSampler", "id": 3},
# 忘记添加VAEDecode节点!
{"type": "PreviewImage", "id": 4}
],
"connections": [
{"from": 1, "to": 3, "output": "model", "input": "model"},
{"from": 2, "to": 3, "output": "output", "input": "positive"},
# 这里应该连接KSampler输出到VAE解码器
# 但我直接连到了PreviewImage,导致报错
{"from": 3, "to": 4, "output": "output", "input": "image"}
]
}转折点出现在第三周。当我终于成功搭建出第一个完整工作流时,那种成就感简直难以言表。点击"执行"按钮后,看着进度条一点点前进,最终在预览窗口显示出根据我的提示词生成的图像,我激动得差点从椅子上跳起来。这一刻我突然理解了ComfyUI的设计哲学 - 它不是在替代编程,而是在用另一种方式展现深度学习的数据流动。
二、深度学习:复杂而迷人的 “数字迷宫”
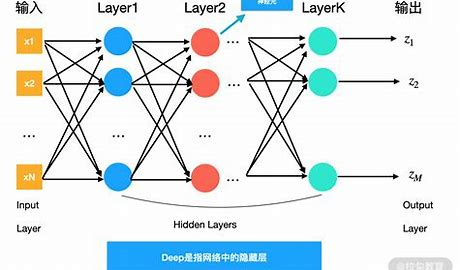
(一)深度学习的神秘面纱
深度学习,简单来说,就是让计算机通过大量的数据来学习模式和规律,从而实现对未知数据的预测和判断。它就像是一个超级智能的大脑,能够从海量的数据中提取出有价值的信息。
深度学习的核心是神经网络,它由多个层次的神经元组成,就像人类大脑中的神经元一样,通过相互连接和传递信号来完成复杂的任务。不同类型的神经网络适用于不同的场景,比如卷积神经网络(CNN)在图像识别方面表现出色,循环神经网络(RNN)则在自然语言处理中有着广泛的应用。
然而,深度学习的实现并不是一件容易的事情。它需要大量的计算资源和数据支持,同时还需要对模型进行精心的设计和调优。这就好比在一个复杂的迷宫中寻找出口,每一个选择都可能影响到最终的结果。
(二)深度学习的发展历程

深度学习的发展可以追溯到上世纪 40 年代,但真正取得重大突破是在近年来。随着计算机性能的不断提升和数据量的爆炸式增长,深度学习迎来了黄金发展期。
早期的神经网络由于计算资源的限制,规模较小,性能也不尽如人意。直到 2012 年,AlexNet 在 ImageNet 图像识别竞赛中取得了巨大的成功,它的准确率远远超过了传统的方法,这标志着深度学习时代的正式到来。
此后,各种新的深度学习模型和算法层出不穷,如 GoogleNet、ResNet、BERT 等,它们在图像识别、自然语言处理、语音识别等领域都取得了令人瞩目的成果。深度学习的应用也越来越广泛,从智能安防到医疗诊断,从自动驾驶到金融风控,无处不在。
(三)深度学习面临的挑战
尽管深度学习取得了巨大的成功,但它仍然面临着许多挑战。其中最大的挑战之一就是数据的质量和数量。深度学习模型需要大量的标注数据来进行训练,而数据的标注是一项非常耗时和费力的工作。此外,数据的质量也直接影响到模型的性能,如果数据存在噪声或偏差,那么模型的准确率也会受到影响。
另一个挑战是模型的可解释性。深度学习模型通常是一个黑匣子,我们很难理解它是如何做出决策的。这在一些关键领域,如医疗和金融,是一个非常严重的问题,因为我们需要知道模型的决策依据,以确保其安全性和可靠性。
此外,深度学习的计算资源需求也非常高,训练一个大型的深度学习模型需要消耗大量的电力和计算资源。这不仅增加了成本,还对环境造成了一定的压力。
三、ComfyUI到底是啥?它能吃吗?
经过一个月的实战,我开始系统地研究ComfyUI的架构设计。通过阅读源代码(虽然是Python写的,但结构非常清晰),我发现这个看似简单的可视化工具背后蕴含着精妙的设计思想。
节点系统的本质实际上是一个有向无环图(DAG)的执行引擎。每个节点都是一个独立的处理单元,它们通过输入输出插座相互连接。当工作流执行时,ComfyUI会按照拓扑排序依次执行各个节点,自动处理数据依赖关系。
# 简化的节点执行逻辑(基于源码分析)
class Node:
def __init__(self, node_type):
self.inputs = {} # 输入插座
self.outputs = {} # 输出插座
self.function = None # 处理函数
def execute(self):
# 收集输入数据
input_values = {}
for input_name, connection in self.inputs.items():
source_node, output_name = connection
input_values[input_name] = source_node.outputs[output_name]
# 执行节点逻辑
output_values = self.function(**input_values)
# 设置输出数据
for output_name, value in output_values.items():
self.outputs[output_name] = value
# 工作流执行器
class WorkflowExecutor:
def __init__(self, nodes):
self.nodes = nodes
def execute(self):
# 拓扑排序确保执行顺序正确
sorted_nodes = topological_sort(self.nodes)
for node in sorted_nodes:
node.execute()数据类型系统是ComfyUI另一个精妙设计。每个节点插座都有严格的数据类型要求,比如"LATENT"、"IMAGE"、"CONDITIONING"等。这种强类型系统在可视化环境下尤为重要,它能在连接时立即发现类型不匹配的错误,避免执行时才发现问题。
我特别欣赏ComfyUI对中间状态可视化的支持。在传统编程中,查看张量的中间值需要写print语句或使用调试器。而在ComfyUI中,只需在任何两个节点之间插入一个预览节点,就能实时观察数据变化。这对于理解Stable Diffusion这类复杂模型的工作机制帮助巨大。
四、深度学习的 “脚手架”:为什么需要工作流?
(一)传统开发的 “三座大山”
-
环境配置地狱:
深度学习模型对框架版本、依赖库、硬件驱动的要求极其苛刻。我曾因为 PyTorch 从 1.8 升级到 2.0,导致整个项目的 CUDA 核函数全部报错,花了三天时间逐行调试。更崩溃的是,不同模型可能需要完全隔离的环境,比如 Stable Diffusion 需要 Python 3.8+Torch 2.0,而 BERT 却依赖 Python 3.9+Torch 1.12,手动切换环境堪比玩俄罗斯方块。 -
流程可视化缺失:
传统代码式开发中,数据预处理、模型训练、推理部署的流程隐藏在成百上千行代码里,调试时就像在迷宫里找出口。有次我想调整数据增强的顺序,结果因为代码逻辑太复杂,改完后发现模型准确率暴跌,排查半天才发现是数据归一化步骤放错了位置。 -
协作成本爆炸:
小组合作开发时,最头疼的不是写代码,而是给队友解释 “为什么我的代码在你电脑上跑不起来”。去年我们做目标检测项目,光是统一开发环境就开了三次线上会议,最后还是用 Docker 打包环境才勉强解决,但每次更新代码都要重新构建镜像,效率低到让人想摔键盘。
(二)ComfyUI 工作流如何 “拆墙”?

ComfyUI 就像一个可视化的 “流程翻译官”,把深度学习开发中最繁琐的环节变成了图形化操作。比如搭建一个图像生成流程,只需要:
- 拖入 “图像输入” 节点,指定数据集路径;
- 连接 “UNet 模型” 节点,加载预训练权重;
- 接入 “文本嵌入” 节点,输入提示词;
- 最后用 “图像输出” 节点保存结果。
整个过程就像搭积木一样直观,每个节点的参数都可以双击修改,甚至可以实时预览中间结果。我第一次用 ComfyUI 复现 Stable Diffusion 时,只用了半小时就搭好了整个流程,而且通过可视化连线,一眼就看出数据流动的逻辑,调试效率比纯代码开发高了至少 3 倍。
# 传统代码实现图像生成(对比感受下)
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
prompt = "a photo of a cat wearing a hat"
image = pipe(prompt).images[0]
image.save("cat_with_hat.png")
# ComfyUI背后其实在帮你生成类似逻辑,但无需关心底层调用 五、蓝耘元生代:给工作流插上 “算力翅膀”
(一)当 ComfyUI 遇见弹性算力
以前在本地跑深度学习模型,最痛苦的就是 “算力焦虑”—— 我的 1660 显卡跑一个 512x512 的图像生成任务都要等 2 分钟,训练模型更是要挂着电脑一整夜。而蓝耘元生代平台直接把 ComfyUI 工作流和算力调度系统打通,点击 “运行” 按钮就能自动分配 GPU 资源,我试过用平台的 A100 显卡跑同样的图像生成任务,耗时直接缩短到 15 秒,这差距简直像从自行车换成了高铁。
# 蓝耘元生代平台调用算力的底层逻辑(简化版)
def run_workflow_on_gpu(workflow_json, gpu_type="A100"):
# 1. 解析工作流,生成可执行脚本
script = convert_comfyui_to_python(workflow_json)
# 2. 向平台申请GPU资源
gpu_instance = allocate_gpu(gpu_type=gpu_type)
# 3. 在GPU实例上运行脚本
result = execute_on_gpu(script, gpu_instance)
# 4. 释放资源
release_gpu(gpu_instance)
return result (二)工作流与模型训练的 “化学反应”
在蓝耘元生代平台上,用 ComfyUI 搭建训练工作流简直像玩 “策略游戏”。比如训练一个 MNIST 手写数字识别模型,我只需要:
- 拖入 “MNIST 数据集加载” 节点,自动拆分训练集和测试集;
- 连接 “CNN 模型构建” 节点,通过滑块设置卷积层数量、神经元个数;
- 接入 “损失函数” 节点,选择交叉熵损失;
- 添加 “模型评估” 节点,实时监控准确率;
- 最后用 “模型保存” 节点导出训练好的模型。
更厉害的是,平台支持工作流并行运行 —— 我曾经同时跑了三个不同超参数的训练流程,通过对比节点输出的准确率曲线,轻松找到了最优的模型配置,这要是用传统代码开发,得写三个独立的脚本还要手动切换环境,想想都头大。
登录与注册:打开浏览器,访问蓝耘 GPU 智算云平台官网(https://cloud.lanyun.net//#/registerPage?promoterCode=0131 )。新用户需先进行注册,注册成功后即可享受免费体验 18 小时算力的优惠。登录后,用户将进入蓝耘平台的控制台,在这里可以看到丰富的功能模块,如容器云市场、应用市场等 。
六、手把手搭建第一个工作流
(一) 基础图像生成工作流
让我们从最简单的Stable Diffusion文本生成图像开始。在ComfyUI中,基本工作流需要以下几个节点:
加载模型:选择要使用的Stable Diffusion模型
CLIP文本编码:把提示词转换为模型能理解的向量
KSampler:实际的采样器,控制生成过程
VAE解码:把隐变量解码为最终图像
图像预览:查看生成结果
具体实现如下:
# 伪代码表示基础工作流
def create_basic_workflow():
# 创建节点
checkpoint_loader = CheckpointLoaderSimple()
clip_text_encoder = CLIPTextEncode()
ksampler = KSampler()
vae_decoder = VAEDecode()
image_preview = PreviewImage()
# 连接节点
connect(checkpoint_loader.model, ksampler.model)
connect(checkpoint_loader.clip, clip_text_encoder.clip)
connect(clip_text_encoder.output, ksampler.positive)
connect(ksampler.output, vae_decoder.latent)
connect(vae_decoder.output, image_preview.image)
# 设置参数
checkpoint_loader.ckpt_name = "v1-5-pruned-emaonly.ckpt"
clip_text_encoder.text = "a cute cat playing with a ball"
ksampler.seed = random.randint(0, 2**32)
return [checkpoint_loader, clip_text_encoder, ksampler, vae_decoder, image_preview]在实际操作中,我们只需要在ComfyUI界面中拖拽这些节点并连接它们即可。这种可视化方式让我第一次真正理解了Stable Diffusion的工作流程。
(二) 添加ControlNet控制
基础工作流生成图像后,我想加入ControlNet来控制图像结构。这需要:
加载ControlNet模型
预处理输入图像(如边缘检测)
将处理结果作为条件输入
对应的节点添加:
# 伪代码表示添加ControlNet
def add_controlnet(workflow, controlnet_type="canny"):
# 添加新节点
controlnet_loader = ControlNetLoader()
image_loader = ImageLoader()
preprocessor = Preprocessor(controlnet_type)
apply_controlnet = ApplyControlNet()
# 连接节点
connect(controlnet_loader.output, apply_controlnet.control_net)
connect(image_loader.output, preprocessor.input)
connect(preprocessor.output, apply_controlnet.image)
connect(workflow.clip_text_encoder.output, apply_controlnet.positive)
# 更新原有连接
disconnect(workflow.clip_text_encoder.output, workflow.ksampler.positive)
connect(apply_controlnet.output, workflow.ksampler.positive)
# 设置参数
controlnet_loader.control_net_name = f"control_v11p_sd15_{controlnet_type}.pth"
image_loader.image_path = "input/reference.png"
workflow.nodes.extend([controlnet_loader, image_loader, preprocessor, apply_controlnet])
return workflow通过这种方式,我逐步理解了Conditional Generation的概念,以及如何通过额外输入控制生成过程。
七、自定义节点开发 - 释放ComfyUI的真正潜力
当内置节点无法满足需求时,开发自定义节点就成为必由之路。这个过程让我对ComfyUI的扩展机制有了全新认识。
(一)开发环境配置
首先需要搭建开发环境:
克隆ComfyUI源码
创建custom_nodes目录
编写节点Python文件
配置热重载开发模式
# 目录结构示例
comfyui/
├── custom_nodes/
│ └── my_nodes/
│ ├── __init__.py
│ ├── image_processing.py
│ └── utilities.py
└── ...(二)实现一个高级图像混合节点
我开发了一个支持多种混合模式的图像合成节点:
class AdvancedBlendNode(Node):
@classmethod
def INPUT_TYPES(cls):
return {
"required": {
"image1": ("IMAGE",),
"image2": ("IMAGE",),
"blend_mode": (["normal", "multiply", "screen", "overlay"],),
"opacity": ("FLOAT", {"default": 0.5, "min": 0, "max": 1})
}
}
RETURN_TYPES = ("IMAGE",)
FUNCTION = "blend_images"
def blend_images(self, image1, image2, blend_mode, opacity):
# 确保图像大小一致
if image1.shape != image2.shape:
image2 = self.resize_to_match(image2, image1.shape)
# 应用混合模式
if blend_mode == "normal":
result = opacity * image2 + (1 - opacity) * image1
elif blend_mode == "multiply":
result = image1 * image2
elif blend_mode == "screen":
result = 1 - (1 - image1) * (1 - image2)
elif blend_mode == "overlay":
result = torch.where(image1 < 0.5,
2 * image1 * image2,
1 - 2 * (1 - image1) * (1 - image2))
return (result.clamp(0, 1),)
def resize_to_match(self, img, target_shape):
# 简化的调整大小逻辑
return F.interpolate(img, size=(target_shape[2], target_shape[3]))(三)调试与优化自定义节点
开发过程中遇到的主要挑战包括:
数据类型转换问题
自动微分导致的显存泄漏
与ComfyUI原生节点的兼容性
多线程环境下的竞态条件
通过添加详细的日志和错误处理,最终使节点稳定运行:
class DebuggableNode(Node):
@classmethod
def INPUT_TYPES(cls):
return {"required": {"input": ("IMAGE",)}}
RETURN_TYPES = ("IMAGE",)
FUNCTION = "process"
def process(self, input):
try:
self.log(f"Input shape: {input.shape}")
self.log(f"Input range: {input.min():.2f}-{input.max():.2f}")
# 处理逻辑...
output = input * 2
self.log("Processing completed successfully")
return (output,)
except Exception as e:
self.error(f"Processing failed: {str(e)}")
# 返回输入作为fallback
return (input,)
def log(self, message):
print(f"[{self.__class__.__name__}] {message}")
def error(self, message):
print(f"[{self.__class__.__name__} ERROR] {message}")八、学生党视角:工作流如何改变深度学习开发?
(一)从 “调参侠” 到 “架构师” 的思维转变
以前写代码时,我大部分时间都花在处理数据格式、调试框架报错上,真正思考模型架构的时间少之又少。而用 ComfyUI 工作流开发时,我可以把精力集中在模型设计和超参数调整上 —— 比如尝试不同的注意力机制模块,只需要拖入不同的节点组合,几分钟就能看到效果对比,这种 “想法→验证” 的快速迭代,让我感觉自己更像一个算法架构师,而不是只会写样板代码的 “调参侠”。
(二)协作开发的 “破冰神器”
小组合作时,ComfyUI 工作流成了我们的 “共同语言”。上周我们做一个多模态情感分析项目,负责文本处理的同学用 ComfyUI 搭了文本嵌入流程,负责图像处理的同学搭了 CNN 特征提取流程,最后我只需要用 “特征融合” 节点把两者连接起来,整个过程像拼拼图一样顺畅。更方便的是,我们直接把工作流文件上传到平台,每个人都能在自己的环境中运行,再也不用为 “你的 PyTorch 版本比我新” 这种问题吵架了。
(三)低成本试错的 “炼丹炉”
作为学生,我们很难拥有企业级的算力资源,但蓝耘元生代平台让我们用很低的成本就能尝试各种 “大胆想法”。我曾经用平台的免费算力额度,跑了一个基于扩散模型的 3D 医学图像生成工作流,虽然最终效果没达到预期,但整个过程让我积累了宝贵的经验。这种 “低成本试错” 的机会,对我们学生党来说简直太珍贵了。
九、结语:工具只是起点,思考才是核心
从被深度学习「虐哭」到用 ComfyUI「虐菜」,我最大的感悟是:工具永远只是效率的放大器,真正重要的是背后的算法思维和问题解决能力。蓝耘元生代的 ComfyUI 工作流,本质上是把深度学习开发中「重复枯燥」的环节自动化,让我们有更多精力去思考「怎么做更好」。
作为学生,我们不必纠结于「代码写得多漂亮」,而应该关注「能不能用最简单的方式解决问题」。如果你也和我一样,曾在深度学习的代码迷宫里迷路,不妨试试用 ComfyUI 工作流重新定义开发方式 —— 毕竟,能把更多时间花在「想创意」而不是「调 bug」上,才是我们学计算机的终极浪漫,不是吗?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











