







文章目录
- 数据库指令速查
- 0. MySQL 概述
- 1. 权限管理
- 2. 数据库(Database)
- 3. 表(Table)
- 4. 操作数据(CRUD)
- 5. 视图(View)
- 6. 事务(Transaction)
- 7. 索引
数据库指令速查
0. MySQL 概述
0.1 安装
- 官网下载地址:https://downloads.mysql.com/archives/community/
0.2 连接
MySQL服务器启动完毕后,然后再使用如下指令,来连接MySQL服务器:
mysql -u用户名 -p密码 [-h数据库服务器的IP地址 -P(大写)端口号]
-h 参数不加,默认连接的是本地 127.0.0.1 的MySQL服务器
-P 参数不加,默认连接的端口号是 3306
1. 权限管理
1.1 创建账户
-- CREATE USER 用户名 IDENTIFIED BY '密码';
CREATE USER myuser IDENTIFIED BY 'mypassword';
(注:新创建的账户没有任何权限。)
1.2 修改账户名
-- RENAME 旧用户名 TO 新的用户名;
RENAME myuser TO newuser;
1.3 删除账户
-- DROP USER 用户名;
DROP USER myuser;
1.4 查看权限
-- SHOW GRANTS FOR 用户名;
SHOW GRANTS FOR myuser;
1.5 授予权限
- 用户名用 username@host 的形式定义,username@% 使用的是默认主机名。
-- GRANT SELECT, INSERT ON 数据库名称.* TO 用户名;
GRANT SELECT, INSERT ON mydatabase.* TO myuser;
1.6 删除权限
GRANT 和 REVOKE 可在几个层次上控制访问权限:
- 整个服务器,使用 GRANT ALL 和 REVOKE ALL;
- 整个数据库,使用 ON database.*;
- 特定的表,使用 ON database.table;
- 特定的列;
- 特定的存储过程。
-- REVOKE SELECT, INSERT ON 数据库名称.* FROM 用户名;
REVOKE SELECT, INSERT ON mydatabase.* FROM myuser;
1.7 更改密码
-- SET PASSWROD FOR 用户名 = Password('密码');
SET PASSWROD FOR myuser = Password('new_password');
2. 数据库(Database)
2.1 创建数据库(含判断)
-- CREATE DATABASE 数据库名称;
CREATE DATABASE database_name;
-- 判断数据库是否存在,不存在则创建数据库;
CREATE DATABASE IF NOT EXISTS database_name;
2.2 删除数据库(Drop)
-- DROP DATABASE 数据库名称;
DROP DATABASE database_name;
2.3 修改数据库名(Rename)
-- ALTER DATABASE 数据库名 RENAME TO 新表名;
ALTER DATABASE mydatabase RENAME TO newdatabase;
2.3 使用数据库(Use)
-- USE 数据库名称;
USE database_name;
3. 表(Table)
3.1 创建表(含判断)
-- 判断表是否存在,不存在则创建表;
CREATE TABLE IF NOT EXISTS 表名 (
id INT PRIMARY KEY , -- PRIMARY KEY 主键约束
age INT DEFAULT AUTO_INCREMENT, -- DEFAULT 默认约束 AUTO_INCREMENT 自增约束
name VARCHAR(50) NOT NULL, -- NOT NULL 非空约束
sex CHAR CHECK(sex = '男' AND sex = '女'), -- CHECK 检查约束
birth_date DATE FOREIGN KEY, -- FOREIGN KEY 外键约束
phone VARCHAR(15) NOT NULL UNIQUE -- UNIQUE 唯一约束
);
3.2 删除表(Drop Table)
-- Drop TABLE 表名;
Drop TABLE persons
警告:删除数据库或表是不可逆的。因此,在使用DROP语句时要小心,因为数据库系统通常不会显示任何警告,例如“您确定删除吗?”。它将立即删除数据库或表及其所有数据。
3.3 修改表(Alter Table)
3.3.1 添加表字段(Add)
-- ALTER TABLE 表名 ADD 列名 类型 约束(字段)
ALTER TABLE testalter_tbl ADD i INT NOT NULL UNIQUE
3.3.2 删除表字段(Drop)
-- ALTER TABLE 表名 DROP 列名(字段)
ALTER TABLE testalter_tbl DROP i
3.3.3 修改表字段(Modify)
-- ALTER TABLE 表名 MODIFY 列名(字段)
ALTER TABLE testalter_tbl MODIFY i INT DEFAULT
3.3.4 修改表名(Rename To)
-- ALTER TABLE 表名1 RENAME 表名2
ALTER TABLE testalter_tbl RENAME TO testalter_tb2
3.4 查看表(Describe)
-- DESCRIBE 表名;
DESCRIBE persons;
3.5 数据类型
| 数据类型 | 描述 |
|---|---|
| int(INT) | 存储介于-2147483648至2147483647之间的数值(-231~231-1) |
| declmal(DECIMAL) | 以精确的精度存储十进制值。 |
| char(CHAR) | 存储最大长度为255个字符的定长字符串。 |
| varchar(VARCHAR) | 存储最大长度为255个字符的定长字符串。 |
| text(TEXT) | 存储最大大小为65,535个字符的字符串。 |
| date(DATE) | 以YYYY-MM-DD格式存储日期值。 |
| datetime(DATETIME) | 以YYYY-MM-DD HH:MM:SS格式存储组合的日期/时间值。 |
| timestamp(DATETIME) | 存储时间戳值。TIMESTAMP值存储为自Unix纪元('1970-01-01 00:00:01’UTC)以来的秒数。 |
3.6 约束(Constraints)
3.6.1 AUTO_INCREMENT 自增约束
- 通过将前一个值增加1来自动为该字段分配一个值。仅适用于数字字段。
CREATE TABLE 表名 (
id INT AUTO_INCREMENT -- AUTO_INCREMENT 自增约束
);
-- 设置初始值 ; 设置步长
ALTER TABLE 表名 AUTO_INCREMENT = 值, AUTO_INCREMENT_INCREMENT = 步长;
3.6.2 NOT NULL 非空约束
- 限制指定列不接受NULL值。
CREATE TABLE 表名 (
id INT NOT NULL -- NOT NULL 非空约束
);
3.6.3 UNIQUE 唯一约束
- 列内的内容具有唯一性,不可以重复。
CREATE TABLE 表名 (
phone VARCHAR(15) UNIQUE -- UNIQUE 唯一约束
);
注意:可以在一个表上定义多个UNIQUE约束,而在一个表上只能定义一个PRIMARY KEY约束。而且,与PRIMARY KEY约束不同,UNIQUE约束允许NULL值。
3.6.4 DEFAULT 默认约束
- DEFAULT约束指定列的默认值。
CREATE TABLE 表名 (
country VARCHAR(30) DEFAULT '默认值' -- DEFAULT 默认约束
);
注意:如果将表列定义为NOT NULL,但为该列分配一个默认值,则在INSERT语句中无需为该列显式分配一个值即可在表中插入新行。
3.6.5 CHECK 检查约束
- CHECK约束用于限制(检查)可以放置在列中的值。
CREATE TABLE 表名 (
sex CHAR CHECK(sex = '男' AND sex = '女') -- CHECK 检查约束
);
3.6.6 PRIMARY KEY 主键约束
- PRIMARY KEY约束标识具有唯一标识表中的行值的列的列或集。表中的任何两行都不能具有相同的主键值。同样,您不能NULL在主键列中输入值。
CREATE TABLE 表名 (
id INT NOT NULL PRIMARY KEY, -- PRIMARY KEY 主键约束
PRIMARY KEY(id) -- PRIMARY KEY 主键约束
);
提示:主键通常由一个表中的一列组成,但是可以由多个列组成该主键,例如,员工的电子邮件地址或分配的标识号是员工表的逻辑主键。
3.6.7 FOREIGN KEY 外键约束
- 外键(FK)是一列或列的组合,用于在两个表中的数据之间建立和加强关系。
CREATE TABLE 表名 (
FOREIGN KEY (dept_id) REFERENCES 另一个表名departments(dept_id) -- FOREIGN KEY 外键约束
);
4. 操作数据(CRUD)
4.1 添加数据(Insert into)
-- INSERT INTO 表名(列名1,列名2,...) VALUES (值1,值2,...);
-- column ~ value 一一对应关系
INSERT INTO table_name (column1,column2,...) VALUES (value1,value2,...);
4.2 删除行数据(Delete)
-- 1.从表中删除列数据 DELETE FROM 表名 WHERE 列名;
DELETE FROM table_name WHERE column;
-- 2.根据条件删除记录 DELETE FROM 表名 WHERE (条件)id > 3;
DELETE FROM table_name WHERE id > 3;
-- 3.删除所有数据 DELETE FROM 表名;
DELETE FROM table_name;
警告:DELETE语句中的WHERE子句指定应删除的记录。 但是,它是可选的,但是如果您省略或忘记了WHERE子句,则所有记录将从表中永久删除。
4.3 清除表数据(Truncate Table)
- TRUNCATE TABLE语句删除并重新创建表,并使任何自动增量值都重置为其初始值(通常为1)。
-- TRUNCATE TABLE 表名;
TRUNCATE TABLE table_name;
4.4 修改数据(Update)
-- UPDATE 表名 SET 列名1 = 值1, 列名2 = 值2,... WHERE 条件;
UPDATE table_name SET column1_name = value1, column2_name = value2,...WHERE condition;
警告:UPDATE语句中的WHERE子句指定应更新的记录。 如果省略WHERE子句,则所有记录将被更新。
4.5 查询数据(Selete)
SELECT 字段1,字段2,...,字段n
FROM 表1
[INNER/LEFT/RIGHT JOIN 表2 ON 表1.字段1 = 表2.字段2]
[WHERE 条件]
[GROUP BY 字段]
[HAVING 条件]
[ORDER BY 字段 DESC/ASC]
[LIMIT 数字(数组0开头),步长]
4.5.1 六大关键字执行顺序:
FROM –> WHERE –> GROUP BY –> HAVING –> SELECT –> ORDER BY
4.5.2 删除重复数据(Distinct)
- DISTINCT子句用于从结果集中删除重复的行
-- SELECT DISTINCT 列名 FROM 表名;
SELECT DISTINCT column_list FROM table_name;
注意:DISTINCT子句的行为类似于UNIQUE约束(唯一性约束),除了它对待null的方式不同。 两个NULL值被认为是唯一的,而同时又不认为它们是彼此不同的。
4.5.3 选择记录(Where)
-- SELECT 列名 FROM 表名 WHERE 条件;
SELECT column_list
FROM table_name
WHERE condition;
- WHERE子句中支持的运算符
| 操作员 | 描述 | 示例 |
|---|---|---|
| = | 等于 | WHERE id = 2 |
| > | 大于 | WHERE age > 18 |
| < | 小于 | WHERE age < 18 |
| >= | 大于等于 | WHERE age >= 18 |
| <= | 小于等于 | WHERE age <= 18 |
| AND (and) | 与 | WHERE id = 2 AND id = 3 |
| OR (or) | 或 | WHERE id = 2 OR id = 3 |
| NOT (not) | 非(给整个条件取反) | WHERE NOT(id = 2 OR id = 3) |
- WHERE子句中支持的查询
| 操作员 | 描述 | 示例 |
|---|---|---|
| IN (in) | 检查指定值是否与列表或子查询中的任何值匹配 | WHERE country IN ('USA', 'UK') |
| LIKE (like) | 简单模式匹配(%匹配任意一个字符,任意多个字符;_匹配一个字符) | WHERE name LIKE '%_lisi' |
| BETWEEN (between) | 检查指定值是否在值范围内 | WHERE age BETWEEN 3 AND 18 |
| IS NULL (is null) | 数据包含为空 | WHERE age IS NULL |
| IS NOT NULL (is not null) | 数据包含不为空 | WHERE age IS NOT NULL |
4.5.4 分组(Group By)
-
分组就是把具有相同的数据值的行放在同一组中。
-
GROUP BY的主要功能是根据一个或多个列对数据进行分组,并对每个组进行聚合计算
-- SELECT 列名(聚合计算) FROM 表名 GROUP BY 列名 HAVING 条件;
SELECT class AS '班级'
FROM students
GROUP BY class
HAVING NOT(class = '1班');
4.5.5 分组后的筛选(Having)
- HAVING是从分组的数据源中进行有条件的筛选
-- SELECT 列名(聚合计算) FROM 表名 GROUP BY 列名 HAVING 条件;
SELECT class AS '班级'
FROM students
GROUP BY class
HAVING NOT(class = '1班');
“HAVING条件表达式”与“WHERE条件表达式”都是用来限制显示的。但是,两者起作用的地方不一样。
“WHERE条件表达式”作用于表或者视图,是表和视图的查询条件。
“HAVING条件表达式”作用于分组后的记录,用于选择满足条件的组。
4.5.6 排序(Order By)
-- SELECT 列名 FROM 表名 ORDER BY 列名1,列名2 ASC|DESC; ASC:升序 DESC:降序
-- 单列排序 + 多列排序 排序规则默认为:升序
SELECT column_list
FROM table_name
ORDER BY column_name1,column_name1 ASC|DESC;
注意:当指定多个排序列时,结果集首先按第一列排序,然后按第二列对该有序列表排序,依此类推。
4.5.7 分页(Limit)
- LIMIT子句用于限制返回的行数。
-- SELECT * FROM 表名 LIMIT 返回的行数;
SELECT *
FROM table_name
LIMIT 3;
-- SELECT * FROM 表名 LIMIT 起点,返回的行数;
-- 当指定了两个参数时,第一个参数指定要返回的第一行的偏移量,即起点,而第二个参数指定要返回的最大行数。初始行的偏移量是0(不是1)。
SELECT *
FROM table_name
LIMIT 0,3;
4.5.8 子查询
- 子查询中只能返回一个字段的数据。 可以将子查询的结果作为 WHRER 语句的过滤条件:
-- 1.子SQL充当字段:SELECT *,(SELECT 列名2 FROM 表名2) FROM 表名;
SELECT *,(SELECT col2 FROM mytable2)
FROM mytable1;
-- 2.子SQL充当表:SELECT * FROM (SELECT * FROM 表名2);
SELECT *
FROM (SELECT * FROM mytable2)1;
-- 3.子SQL充当字段:SELECT * FROM 表名 WHERE (SELECT 列名2 FROM 表名2) IN 值;
SELECT *
FROM mytable1
WHERE (SELECT col2 FROM mytable2) IN col1;
-- 4.子SQL充当值:SELECT * FROM 表名 WHERE 列名 IN (SELECT 列名2 FROM 表名2);
SELECT *
FROM mytable1
WHERE col1 IN (SELECT col2 FROM mytable2);
4.6 连表查询(Conncation)
- 说明 :当查询的数据来至于多张表时 ,就需要进行连表查询 ,连表查询可以是两张表或者多张表进行查询 。
- 连表的条件 : 两张表都有公共的业务字段 ,它的含义在两张表是一样的。
- 常见的连表方式有 : 内连接 、左连接 、右连接
4.6.1 内连接(Inner Join)
- 获取两个表中字段匹配关系的记录。
/* 方法一:
SELECT 表名1.列名1, 表名2.列名2
FROM 表名1 AS 别名1 INNER JOIN 表名2 AS 别名2
ON 表名1.列名 = 表名2.列名;
*/
SELECT A.value, B.value
FROM table_name1 AS A INNER JOIN table_name2 AS B
ON A.key = B.key;
/* 方法二:
SELECT 表名1.列名1, 表名2.列名2
FROM 表名1 AS 别名1, 表名2 AS 别名2
WHERE 表名1.列名 = 表名2.列名;
*/
SELECT A.value, B.value
FROM table_name1 AS A, table_name2 AS B
WHERE A.key = B.key;
4.6.1.1 自连接
- 自连接可以看成内连接的一种,只是连接的表是自身而已。
- 这种自连接的表结构可以用于表示层级结构数据,如组织机构结构、分类系统等。
-- 一张员工表,包含员工姓名和员工所属部门,要找出与 李三 处在同一部门的所有员工姓名。
/* 子查询版本:
SELECT 列名1
FROM 表名
WHERE 列名2 = (
SELECT 名2
FROM 表名
WHERE 列名1 = "李三");
*/
SELECT name
FROM employee
WHERE department = (
SELECT department
FROM employee
WHERE name = "李三");
/* 自连接版本:
SELECT 表名(别名1).列名
FROM 表名 AS 别名1 INNER JOIN 表名 AS 别名2
ON 表名(别名1).列名 = 表名(别名2).列名
AND 表名(别名2).列名 = "李三";
*/
SELECT e1.name
FROM employee AS e1 INNER JOIN employee AS e2
ON e1.department = e2.department
AND e2.name = "李三";
注意:在没有条件语句的情况下返回笛卡尔积。
4.6.1.2 自然连接(Natural Join)
-
当自然连接匹配成功时就是内连接
-
是一种很自然的连接,没有指定连接条件,但是连接语句会自动检索两个表的相同名称的列。
-- SELECT * FROM 表名1 NATURAL JOIN 表名2
SELECT *
FROM table_name1
NATURAL JOIN table_name2
注意:我说的是相同名称,如果不是相同名称,自然连接就会退化成笛卡尔积。
4.6.2 左连接(Left Join)
- 获取左表所有记录,即使右表没有对应匹配的记录。
/*
SELECT 表名1.列名1, 表名2.列名2
FROM 表名1 LEFT OUTER JOIN 表名2
ON 表名1.列名 = 表名2.列名;
*/
SELECT A.value, B.value
FROM table_name1 AS A LEFT JOIN table_name2 AS B
ON A.key = B.key;
4.6.3 右连接(Right Join)
- 获取右表所有记录,即使左表没有对应匹配的记录。
/*
SELECT 表名1.列名1, 表名2.列名2
FROM 表名1 LEFT (OUTER) JOIN 表名2
ON 表名1.列名 = 表名2.列名;
*/
SELECT A.value, B.value
FROM table_name1 AS A RIGHT JOIN table_name2 AS B
ON A.key = B.key;
4.7 组合查询(UNION)
- 使用 UNION 来组合两个查询,如果第一个查询返回 M 行,第二个查询返回 N 行,那么组合查询的结果一般为 M+N 行。
- 每个查询必须包含相同的列、表达式和聚集函数。
- 默认UNION(DISTINCT)会去除相同行,如果需要保留相同行,使用 UNION ALL。
/*
SELECT 列名
FROM 表名
WHERE 条件1
UNION ALL/DISTINCT
SELECT 列名
FROM 表名
WHERE 条件2
ORDER BY 条件3;
*/
SELECT column
FROM table_name
WHERE column = 1
UNION ALL/DISTINCT
SELECT column
FROM table_name
WHERE column =2
ORDER BY column;
注意:只能包含一个 ORDER BY 子句,并且必须位于语句的最后。
4.7 常用的函数(Function)
4.7.1 数值函数
| 函数名 | 描述 | 示例 |
|---|---|---|
| ABS(x) | 返回 x 的绝对值 | 返回 -1 的绝对值:SELECT ABS(-1) -- 返回1 |
| CEIL(x) | 返回大于或等于 x 的最小整数 | SELECT CEIL(1.5) -- 返回2 |
| FLOOR(x) | 返回小于或等于 x 的最大整数 | 小于或等于 1.5 的整数:SELECT FLOOR(1.5) -- 返回1 |
| MOD(x,y) | 返回 x 除以 y 以后的余数 | 5 除于 2 的余数:SELECT MOD(5,2) -- 1 |
| RAND() | 返回 0 到 1 的随机数 | SELECT RAND() --0.93099315644334 |
| ROUND(x) | 返回离 x 最近的整数 | SELECT ROUND(1.23456) --1 |
| TRUNCATE(x,y) | 返回数值 x 保留到小数点后 y 位的值(与 ROUND 最大的区别是不会进行四舍五入) | SELECT TRUNCATE(1.23456,3) -- 1.234 |
4.7.2 日期函数
| 函数名 | 描述 | 示例 |
|---|---|---|
| NOW() | 返回当前日期和时间 | SELECT NOW() -> 2018-09-19 20:57:43 |
| UNIX_TIMESTAMP(date) | 返回日期date的unix时间戳 | SELECT UNIX_TIMESTAMP(date) |
| FROM_UNIXTIME | 返回UNIX时间戳的日期值 | SELECT FROM_UNIXTIME |
5. 视图(View)
5.1 视图的概念
- 视图是虚拟的表,本身不包含数据,也就不能对其进行索引操作。
5.2 视图的好处
- 简化复杂的 SQL 操作,比如复杂的连接;
- 只使用实际表的一部分数据;
- 通过只给用户访问视图的权限,保证数据的安全性;
- 更改数据格式和表示。
5.3 创建视图(Create View)
/*
CREATE VIEW 视图名称 AS
SELECT Concat(col1, col2) AS concat_col, col3*col4 AS compute_col
FROM 表名
WHERE 条件;
*/
CREATE VIEW my_view AS
SELECT Concat(colmun1, colmun2) AS concat_colmun, colmun3*colmun4 AS compute_colmun
FROM table_name
WHERE colmun5 = value;
6. 事务(Transaction)
6.1 事务作用
- 在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
- 事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
- 事务用来管理 insert,update,delete 语句
6.2 事务的特点
一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
- 原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
- 隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- 持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
6.3 事务的基本术语
-
事务(transaction)指一组 SQL 语句;
-
回退(rollback)指撤销指定 SQL 语句的过程;
-
提交(commit)指将未存储的 SQL 语句结果写入数据库表;
-
保留点(savepoint)指事务处理中设置的临时占位符(placeholder),你可以对它发布回退(与回退整个事务处理不同)。
6.4 创建事务(Create Transaction)
/* 方法一
START TRANSACTION; 开始一个事务
ROLLBACK; 事务回滚
COMMIT; 事务确认
*/
START TRANSACTION; # 开始事务
INSERT INTO nhooo_transaction_test value(5);
ROLLBACK; # 回滚
INSERT INTO nhooo_transaction_test value(6);
COMMIT; # 提交事务
/* 方法二
SET AUTOCOMMIT=0 禁止自动提交
SET AUTOCOMMIT=1 开启自动提交
*/
SET AUTOCOMMIT = 0; // 关闭自动提交
UPDATE account SET balance = balance - 100 WHERE user_id = 1; // 执行第一个更新操作
UPDATE account SET balance = balance + 100 WHERE user_id = 2; // 执行第二个更新操作
COMMIT; // 手动提交事务
/* 方法三
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION ROLLBACK; // 异常发生时回滚事务
START TRANSACTION; // 开启事务
UPDATE account SET balance = balance - amount WHERE user_id = user_id_1; // 执行第一个更新操作
UPDATE account SET balance = balance + amount WHERE user_id = user_id_2; // 执行第二个更新操作
COMMIT; // 提交事务
END;
*/
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION ROLLBACK; // 异常发生时回滚事务
START TRANSACTION; // 开启事务
UPDATE account SET balance = balance - amount WHERE user_id = user_id_1; // 执行第一个更新操作
UPDATE account SET balance = balance + amount WHERE user_id = user_id_2; // 执行第二个更新操作
COMMIT; // 提交事务
END;
7. 索引
7.1 索引的作用
-
索引(index):是帮助数据库高效获取数据的数据结构 。
-
优点:
- 提高数据查询的效率,降低数据库的IO成本。
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。
-
缺点:
- 索引会占用存储空间。
- 索引大大提高了查询效率,同时却也降低了insert、update、delete的效率。
7.2 索引的原理
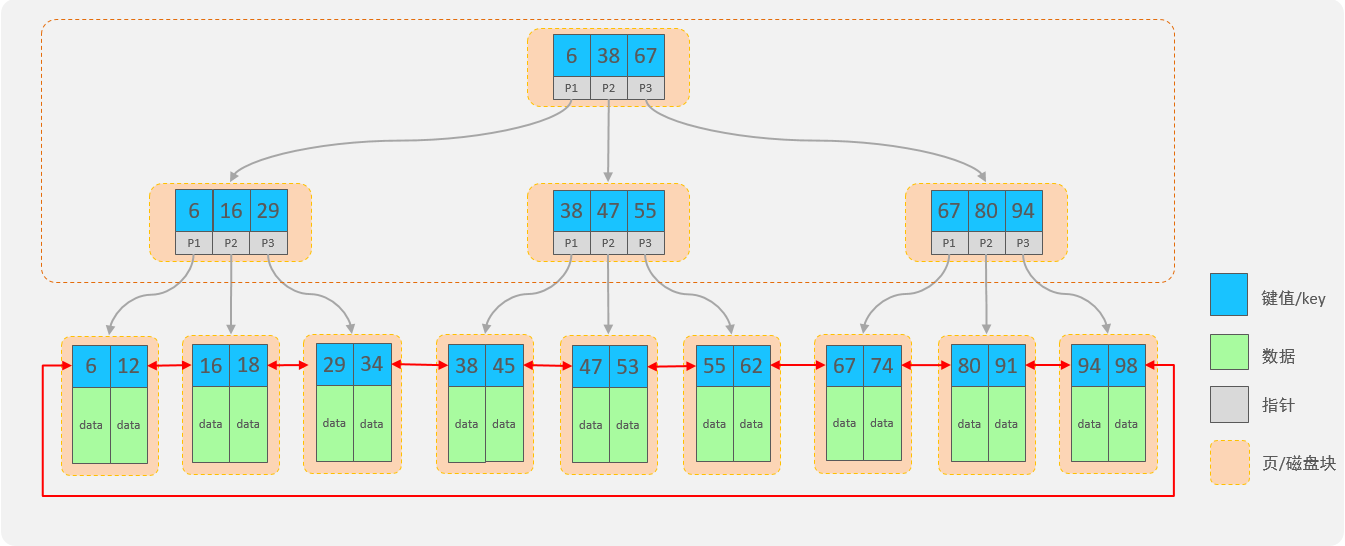
- MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引(默认)、Full-Text索引等。
B+Tree结构:
- 每一个节点,可以存储多个key(有n个key,就有n个指针)
- 节点分为:叶子节点、非叶子节点
- 叶子节点,就是最后一层子节点,所有的数据都存储在叶子节点上
- 非叶子节点,不是树结构最下面的节点,用于索引数据,存储的的是:key+指针
- 为了提高范围查询效率,叶子节点形成了一个双向链表,便于数据的排序及区间范围查询
7.3 索引的语法
- 创建索引
create [ unique(唯一索引) ] index 索引名 on 表名 (字段名,... ) ;
-- 实例:
create index quickly_cust_id on customers(cust_id);
- 查看索引
show index from 表名;
- 删除索引
drop index 索引名 on 表名;
注意事项:
主键字段,在建表时,会自动创建主键索引
添加唯一约束时,数据库实际上会添加唯一索引















 713
713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









