






什么是集合?
定义:集合是Java中的一种存储数据的容器,用来存放对象的容器
集合用来干什么?
集合主要就是用来存储数据和操作存储的数据
设计者为了存储多种类型的对象,设计了集合这个框架,在框架中定义了规范(利用接口),根据存储的方式,分为单列和双列,存储为单列的数据接口为collection集合,存储为双列的集合为Map集合,
什么时候使用集合?
集合和数组的区别:
数组只能存储同一类型的数据,可以存储基本数据类型,数组长度固定
集合能够存储不同类型的数据,只能存储引用数据类型,基本数据类型会转为引用数据类型(比如你存入一个int型数据66放入集合中,其实它是自动转换成Integer类后存入的,Java中每一种基本数据类型都有对应的引用类型),大小可以动态扩展。
总结:在存储不同数据类型时使用。
Collection
定义:Collection是单例集合的基本的集合接口
在Collection接口中又根据存储方式不同分为List和Set接口
List&Set的区别
List接口的实例存储的是有序,可重复的数据
Set接口的实例存储的是无序,不可重复的数据
List查找元素的效率高,插入和删除效率低,因为会引起其他元素的位置改变
Set查找元素的效率低,插入和删除效率高,不会导致其他元素位置的改变
List有索引
Set无索引
List集合特点
1、有索引
2、可以存储重复元素
3、元素存储有序
Set集合的特点
1、无索引,只能通过迭代器或增强for循环遍历
2、不能存储重复的元素、最多包含一个空值
3、元素存取无序
List的实现类
ArrayList
特点:
底层的实现是Object数组
线程不安全,效率高
什么时候使用?
1、频繁访问列表中的某一个元素
2、只需要在列表末尾进行添加和删除元素操作
Vector
特点
底层实现是Object类型数组
是线程同步的,即线程安全的,效率不高
什么时候使用?
需要线程同步安全时
LinkedList
特点
底层实现是双向链表
线程不安全
内存消耗比较大
什么时候使用?
1、需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作
2、
ArrayList&Vector的区别
相同:底层为可变数组
不同:
ArrayList线程不安全,效率高
Vector是线程安全的,效率不高
Arraylist扩容倍数:如果有参构造1.5倍,如果无参;第一次10,从第二次开始按1.5扩容
Vector扩容倍数:如果是无参,默认10,满后,就按2倍扩容,如果指定大小,则每次直接按2倍扩容
三者间的相同和不同
相同:都实现了List接口,都具有List规定的特点,他们的存储的元素都是有序,可重复的数据
不同:
Set的实现类
HashSet
地层实现其实是HashMap,底层维护的是一个数组+单向链表
特点:
无索引,只能通过迭代器和增强for循环遍历。存取是无序的,没有重复的数据,最多包含一个null值
线程不安全的
HashSet集合保证元素唯一性的原理
1.根据对象的哈希值计算存储位置
如果当前位置没有元素则直接存入
如果当前位置有元素存在,则进入第二步
2.当前元素的元素和已经存在的元素比较哈希值
如果哈希值不同,则将当前元素进行存储
如果哈希值相同,则进入第三步
3.通过equals()方法比较两个元素的内容
如果内容不相同,则将当前元素进行存储
如果内容相同,则不存储当前元素
LinkedHashSet
是HashSet的一个子类,底层是一个LinkedHashMap,底层维护了一个数组+双向链表
特点:
不允许元素重复
根据元素的HashCode值来决定元素的存储位置,同时是用链表维护元素次序,使得元素开起来是以插入顺序保存的
在HashMap的功能基础上,增加了访问顺序的能力
TreeSet
特点
元素具体排序方式取决于构造方法
TreeSet():根据其元素的自然排序进行排序
TreeSet(Comparator comparator) :根据指定的比较器进行排序
相同:
元素不允许重复
都是线程不安全的
不同点:
HashSet存取是无序的,LinkedHashSet存取是有序的,TreeSet在某种方式下可以让取出的元素具有顺序
Map
用于保存具有映射关系的数据,键和值一一映射. 可以通过键来获取值。
特点:
Map中的key不允许重复,value是可以重复的;可以通过key值来访问对象的值
Map中的key和value可以是任何引用类型的数据
HashMap
存储方式是一个散列表(哈希表)
特点
根据键的HashCode值存储数据
不支持线程同步,线程不安全
底层实现: 数组+链表+红黑树
HashTable
特点:
键和值都不能为null,否则会抛出NullPointerException
线程安全的
扩容 :
Properties :继承自HashTable,且实现了Map接口
HashMap&HashTable
相同
不同 :
继承不同
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口
线程安全不同
Hashtable的几乎所有函数都是同步的,即它是线程安全的,支持多线程。 HashMap的函数则是非同步的,它不是线程安全的。
支持的遍历种类不同
HashMap只支持Iterator(迭代器)遍历。
Hashtable支持Iterator(迭代器)和Enumeration(枚举器)两种方式遍历
对null值的支持不同
HashMap的key、value都可以为null
Hashtable的key、value都不可以为null
通过Iterator迭代器遍历时,遍历的顺序不同
HashMap是“从前向后”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历
Hashtabl是“从后往前”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历
容量的初始值 和 增加方式都不一样
HashMap默认的容量大小是16;增加容量时,每次将容量变为“原始容量x2”。
Hashtable默认的容量大小是11;增加容量时,每次将容量变为“原始容量x2 + 1”。
TreeMap
特点:
排序根据其键的自然顺序排序,可以使用map创建时提供的Comparator排序(有序)
不是线程安全的
key 不可以存入null
底层实现: 底层是基于红黑树实现的
LinkedHashMap
特点:
非线程安全
LikedHashMap额外保证了Map的遍历顺序与put顺序一致的有序性。
出现的问题
问题一:出现重复的了。
该代码想要实现的是如果存入的内容完全相同,则无法存入。
public class Test {
public static void main(String[] args) {
TreeSet<Book> books = new TreeSet<>();
books.add(new Book("小狗钱钱", "博多·舍费尔",18));
books.add(new Book("小狗钱钱", "博多·舍费尔",18));
books.add(new Book("纳瓦尔宝典"," 埃里克·乔根森 ",68));
books.add(new Book("纳瓦尔宝典"," 埃里克·乔根森 ",100));
books.add(new Book("财务自由之路", "博多·舍费尔",18));
books.add(new Book("财务自由之路", "博多·舍费尔",18));
//有问题,为什么重复了
books.add(new Book("小狗钱钱", "博多·舍费尔",18));
for (Object s : books) {
System.out.println(s);
}
}
}
public class Book implements Comparable{
private String title ;
private String author ;
private double price ;
public Book(String title, String author, double price) {
this.title = title;
this.author = author;
this.price = price;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"title='" + title + '\'' +
", author='" + author + '\'' +
", price=" + price +
'}';
}
@Override
public int compareTo(Object o) {
Book b = (Book) o;
//可以用字串比较
//
if (this.title.equals(b.title) && this.author.equals(b.author) && this.price == b.price)
{
return 0;
}
return 1;
}
}
出现问题的代码在47—57行:
我的理解是,只要全部一样的时候我只输出一个,其他情况都可以存入。
问题二:
这个问题其实特别搞笑,我发现我在高强度(那天,早上起来感觉就没睡醒,中午午觉也没进入睡眠,然后昏昏沉沉的来学习,3点后在力扣刷题,当时感觉脑子就转的特别慢,题没解出来,之后一直到了晚上会宿舍,做的这个,硬是没发现问题在哪.....)用脑之后,不知道为什么就是想不出来。
HashMap<String, String> hashMap = new HashMap<>();
hashMap.put("张无忌", "赵敏");
hashMap.put("郭靖", "黄蓉");
hashMap.put("杨过", "小龙女");要求:遍历出key和value就行:
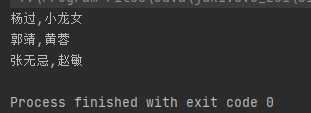
好我的代码:
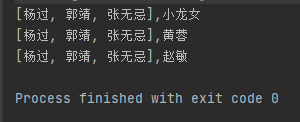
Set<String> strings = hashMap.keySet();
for (String o : strings) {
String s = hashMap.get(o);
System.out.println(strings +","+ s);
}
吐血的问题,好的我承认我基础太差!这要是放到以后,来找这样的问题,花费大量的时间岂不是很亏很亏!
解决:我TM输出o,不就行了,keySet()方法是获取所有key值...,增强for的时候会单个遍历所有key中的每一个元素。















 221
221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









