






一、爬虫概论
网络爬虫(web crawler)是一种自动检索工具,是一种“自动化浏览网络”的程序。
爬虫被广泛应用于互联网搜索引擎或其他类似网站,用来获取或更新这些网站的内容和检索方式。
爬虫是取代浏览器来实现向服务器发送请求并获取想要的结果。
二、爬虫应用
1、搜索引擎 爬虫程序可以为搜索引擎系统爬取网络资源,用户可以通过搜索引擎搜索网络上的一切资源。
2、数据挖掘 爬虫程序可以爬取相关数据后进行数据分析,获取价值数据。应用非常广泛。
三、爬虫原理
1、爬虫流程 爬虫程序获得URL地址→爬虫程序根据URL访问网络→网络返回HTML源代码给爬虫程序
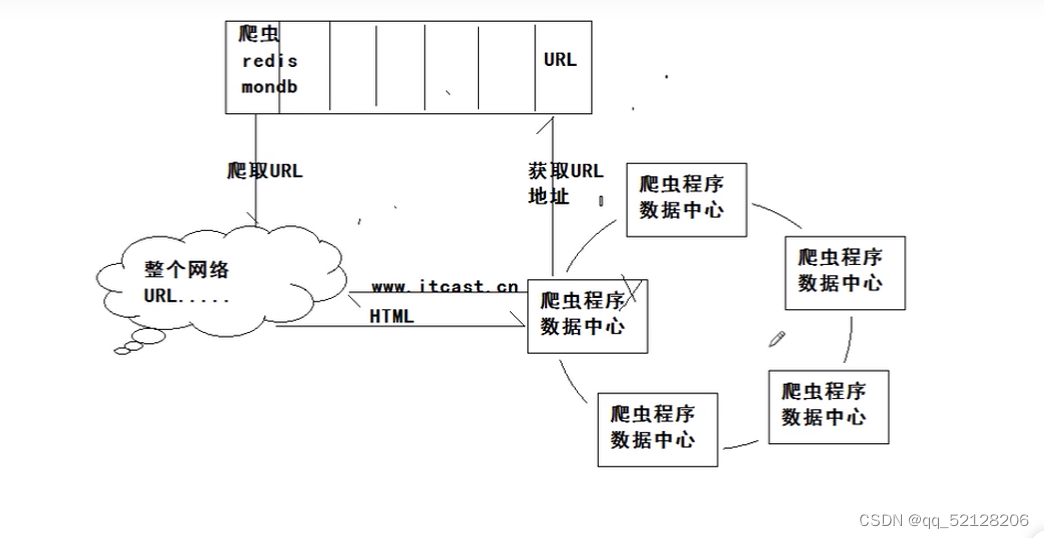
设计另外一个爬虫程序爬取URL即可实现循环
2、底层原理 爬虫程序是依据JDK里的URLConnection向网络发送请求,但使用URLConnection是非常复杂的,因此使用爬虫框架来对URLConnection进行一个封装,其中HttpClient和Jsoup是一个非常简单易用的框架
3、HttpClient简介
HttpClient是apache组织下面的一个用于处理HTTP请求和响应的来源工具,是一个在JDK基础类库是做了更好的封装的类库。
HttpClient项目依赖于HttpCore(处理核心的HTTP协议)、commons-codec(处理与编码有关的问题的项目)和commons-logging(处理与日志有关问题的项目)。
4、Jsoup简介
Jsoup 是一款java的HTML解析器,可以直接解析某个URL地址、HTML文本内容。
HttpClient负责模拟浏览器发送请求,Jsoup负责解析HttpClient请求返回的HTML页面,解析获取需要的数据。
5、HttpClient框架
获取URL→向网站发送请求→获取源代码
String url = ".....";//获取URL
Document doc0 = Jsoup.connect(url).get(); //请求方式获取到页面
String d = doc0.toString();//获得源码6、其他
设置响应时间,设置传输源代码时间,设置代理服务器、防止网页识别爬取IP
7、Jsoup解析源码
Jsoup将源码转换为documentt→Jsoup使用合适的选择器方式获取元素节点→Jsoup解析获取数据,可以搭配循环使用
Document doc = Jsoup.parse(d, "UTF-8"); //将页面转换为Document对象
Elements content = doc.getElementsByClass("......");//创建对象集合,class选择器
Elements content = doc.getElementsSelect("......");//创建对象集合,元素选择器
for (Element element : content) {//创建循环,解析
String price = element.getElementsByClass("......").text();//解析
}














 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









