







 本文介绍了推荐系统的发展历程,从协同过滤、逻辑回归到因子分解机等经典算法,并探讨了这些算法的应用场景及局限性。
本文介绍了推荐系统的发展历程,从协同过滤、逻辑回归到因子分解机等经典算法,并探讨了这些算法的应用场景及局限性。
深度学习推荐系统——传统机器学习推荐算法
此系列文章为《深度学习推荐系统》一书的读书笔记。
首先介绍一些传统的推荐模型。
文章目录
一、推荐系统的进化之路
传统算法:
- 协同过滤(Collaborative Filtering,CF)
- 逻辑回归(Logistic Regression,LR)
- 因子分解机(Factorization Machine,FM)
- 梯度提升树(Gradient Boosting Decision Tree,GBDT)
因子分解机 — 深度因子分解机 — 神经网络因子分解机
1. 传统推荐模型
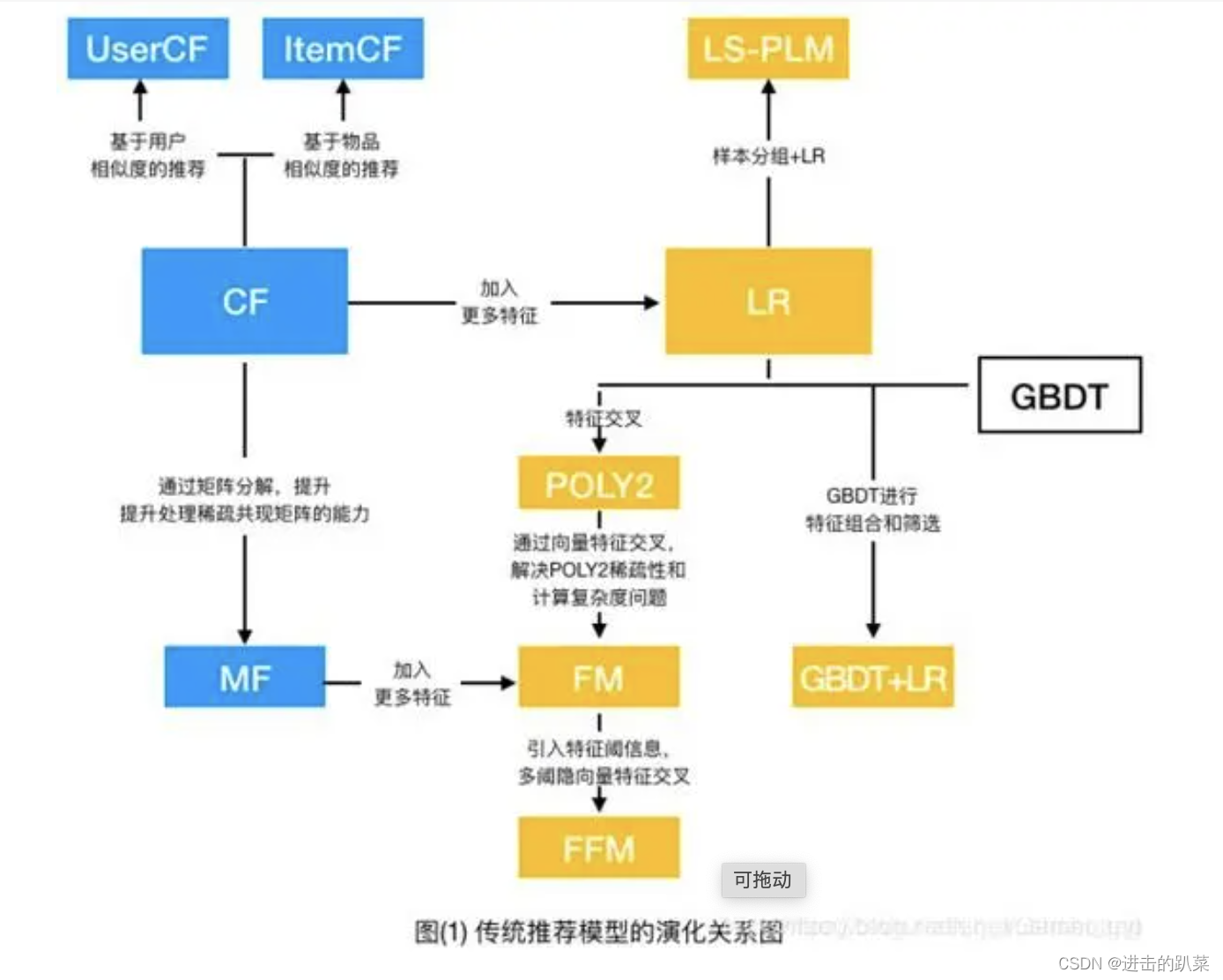
2. 协同过滤算法
协同过滤,根据字面意思,就是协同大家的反馈、评价和意见一起对海量的信息进行过滤,从中筛选出目标用户可能感兴趣的信息的推荐过程。
举例:
协同过滤过程中,用户相似度的计算是算法中最关键的一步。
共现矩阵中的行向量代表相应用户的用户向量,那么计算用户i和用户j之间相似度的问题,就可以转化成计算两个向量之间的相似度问题。常用的向量间相似度计算方法有:
(1)余弦相似度
(2)皮尔逊相关系数
以上算法主要基于用户相似度进行推荐,因此也被称为基于用户的协同过滤(UserCF),该类算法缺点主要有
(1)复杂度随用户增加显著提升,速度为n^2
(2)用户历史数据稀疏
UserCF和ItemCF的应用场景
UserCF基于用户相似度进行推荐,用户能够快速得知与自己兴趣相似的人的喜好。这一特点使其非常适用于新闻推荐场景。
ItemCF更适用于兴趣变化较为稳定的应用,例如Amazon的电商场景,用户在一个时间段内更倾向于寻找一类商品,此时利用物品相似度为其推荐相关物品是契合用户动机的。
UserCF:新闻推荐场景
ItemCF:电商场景、视频推荐场景
协同过滤的发展
协同过滤是一个非常直观、可解释性很强的模型。但是,基于数据相似性进行推荐的方式导致该算法极其依赖数据的完备性。当数据分布不均时,热门物品往往具有很强的头部效应,容易和大量物品产生相似性;而尾部物品由于特征向量稀疏,很难与其他物品产生相似性,因此很少被推荐。
这揭示了协同过滤的天然缺陷——推荐结果的头部效应明显、处理稀疏向量的能力弱。
3. 矩阵分解算法——协同过滤的进化
对协同过滤算法中的共现矩阵进行矩阵分解,分解方法有特征值分解、奇异值分解和梯度下降。
局限性
和协同过滤一样,不方便加入用户、物品、上下文等特征,丧失了利用其他有效信息的机会。
4. 逻辑回归——融合多种特征的推荐模型
逻辑回归将推荐问题看成一个分类问题,通过预测证样本的概率对物品进行排序(正样本可以是用户“点击”了某商品,也可以是用户“观看”了某视频,均是推荐系统希望用户产生“正反馈”的行为)。将推荐问题转换成一个点击率(Click Through Rate)预估问题。
局限性
表达能力不强,不能进行特征交叉、特征筛选等一系列较为“高级”的操作,因此不可避免地造成信息损失。
为解决这一问题,土建模型朝着复杂化的方向继续发展,衍生出因子分解机等高维复杂模型。
5. 从FM到FFM——自动特征交叉
因子分解机(Factorization Machine, FM)
域感知因子分解机(Field-aware Factorization Machine, FFM)
1. POLY2模型
POLY2模型采用特征暴力组合的方式进行特征组合。
二阶公式
Φ
P
O
L
Y
2
(
w
,
x
)
=
∑
j
1
=
1
n
∑
j
2
=
j
1
+
1
n
w
h
(
j
1
,
j
2
)
x
j
1
x
j
2
\Phi POLY2(w, x)=\sum_{j_1=1}^n \sum_{j_2=j_1+1}^n w_{h(j_1,j_2)}x_{j_1}x_{j_2}
ΦPOLY2(w,x)=j1=1∑nj2=j1+1∑nwh(j1,j2)xj1xj2
POLY2模型本质上仍是线性模型,其训练方法与逻辑回归并无区别,便于工程上的兼容。
2. FM模型——隐向量特征交叉
二阶公式
F
M
(
w
,
x
)
=
∑
j
1
=
1
n
∑
j
2
=
j
1
+
1
n
(
w
j
1
⋅
w
j
2
)
x
j
1
x
j
2
FM(w, x)=\sum_{j_1=1}^n \sum_{j_2=j_1+1}^n (w_{j_1} \cdot w_{j_2})x_{j_1}x_{j_2}
FM(w,x)=j1=1∑nj2=j1+1∑n(wj1⋅wj2)xj1xj2
引入特征隐向量,把POLY2模型
n
2
n^2
n2级别的权重参数数量减少到了
n
k
nk
nk 级别。同时,隐向量的引入使FM能更好地解决数据稀疏性的问题。
举例来说,。。。
FM在2012-2014年前后,成为业界主流的推荐模型之一。
3. FFM模型——引入特征域概念
FFM模型引入了特征域感知(field-aware)概念,提升模型表达能力。
F
F
M
(
w
,
x
)
=
∑
j
1
=
1
n
∑
j
2
=
j
1
+
1
n
(
w
j
1
,
f
2
⋅
w
j
2
,
f
1
)
x
j
1
x
j
2
FFM(w, x)=\sum_{j_1=1}^n \sum_{j_2=j_1+1}^n (w_{j_1, f_2}\cdot w_{j_2, f_1})x_{j_1}x_{j_2}
FFM(w,x)=j1=1∑nj2=j1+1∑n(wj1,f2⋅wj2,f1)xj1xj2
特征域的引入,为模型引入了更多有价值的信息,使模型表达能力更强,但与此同时,FFM的计算复杂度上升 到
k
n
2
kn^2
kn2,远大于FM的
k
n
kn
kn ,在实际工程应用中,需要在模型效果和工程投入之间进行权衡。
FM模型演化
理论上,FM模型的思路可以引申到三阶模型,但由于组合爆炸问题,三阶模型无论是在权重数量还是训练复杂度上都过高,因此,如何在实际工程应用中,突破二阶特征交叉的限制,进一步加强模型特征组合能力,成了推荐模型发展的方向。
6. GBDT+LR——特征工程模型化的开端
7. LS-PLM
大规模分段线性模型,Large Scale Piece-wise Linear Model

















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









