






1、什么是中间件
Java中间件是位于操作系统和应用程序之间的独立软件层,它为分布式程序提供通信、数据管理、事务处理、安全性、消息传递等服务。常见的Java中间件包括服务器、消息队列、缓存系统、服务总线等。
本项目包括技术:

Nginx(前端)
什么是nginx,什么是nginx反向代理
1、什么是nginx
Nginx 是一个高性能的 HTTP 服务器和反向代理服务器,同时也是一个 IMAP/POP3/SMTP 代理服务器。
2、正向代理
正向代理表示客户端通过代理服务器向目标服务器发送请求,并将返回的响应发送给客户端,比如,翻墙会用到正向代理 , 被代理的是客户端。
3、反向代理
反向代理是服务器端的代理,被代理的是服务器端,它可以收到客户端的响应,并请求转发给后端多个服务器,并返回结果。反向代理提高了访问速度,增强了系统的安全性和负载均衡。本项目前端管理就是应用nginx服务器反向代理运行的。
当前端请求地址和后端接口地址不一致时,仍然可以请求成功,这就是通过了nginx反向代理,浏览器也就是我们用户,发出的请求先是请求到 Nginx 服务器,由 Nginx 反向代理把这个请求转发给后端的 tomcat 服务器。

反向代理的好处
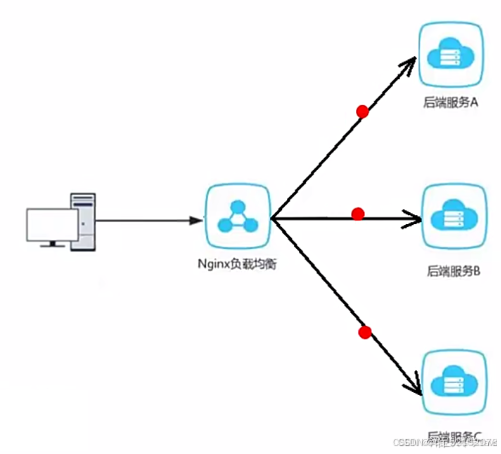
(1)进行负载均衡
负载均衡可以把大量的请求按着我们自己指定的方式均衡地分配给每台服务器,如下图所示,通过 Nginx 负载均衡,可以将前端发送的请求均匀地分发给服务A、B、C。如果没有 Nginx 负载均衡,就需要前端自己去访问后端的服务器,而前端只能固定的访问某一台服务器,效率就会大大折扣了。
(2)保正后端服务安全
在时间的开发中有了nginx,服务器端的A、B、C不会直接暴露出来,前端无法直接请求到后端,智能体通过nginx这个入口。
(3)提高访问速度
在请求nginx的时候,nginx会做一个缓存,比如前端之前访问过的接口地址,再次访问时,nginx就无须再次请求后端服务器,而是把缓存的数据响应给前端
微信小程序(前端)
本项目的客户端形式为小程序,开发一个微信小程序需要以下准备:
1、注册
2、完善信息
3、下载开发者工具
HttpClient(后端)
(1)什么是HttpClient
HttpClient 是 Apache Jakarta Common 下的子项目,是一种用于发送 HTTP 请求和接收响应的客户端编程工具包。它通常用于与基于 HTTP 协议的服务进行交互。可以在Java程序中通过 HttpClient 工具包来构造http请求,并且发送 http 请求。
(2)如何使用HttpClient
1、所需要导入Maven坐标,在本项目中,我们实现导入了aliyun-sdk-oss,其底层用到了HttpClient,所以不需要导入了。
2、创建HttpClient对象
3、创建Http请求 对象
4.调用HttpClient的execute方法发送请求
在本项目中已经提前准备好了一个工具类傀儡,使用时直接调用即可
MD5加密(后端)
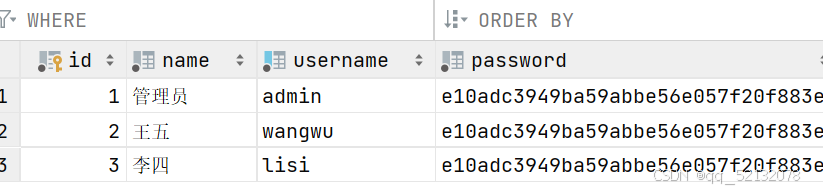
在初始代码中员工的登录密码是名文显示的,安全性较低,这里用到了MD5加密来加密密码
1、什么是MD5加密?
MD5信息摘要算法,一张广泛使用的密码散列函数,可以产生出一个128位(16)字节的散列值,用于确保信息传输完全一致,MD5加密不可逆,如果想要验证,只能将一个明文加密后对比
2、如何使用MD5加密功能
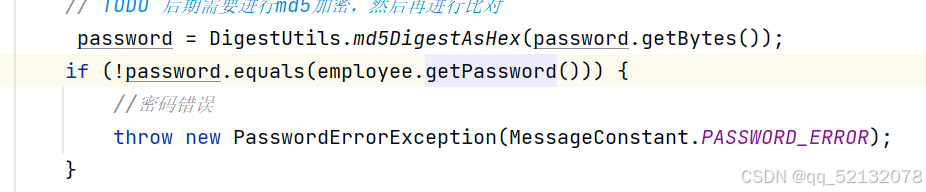
(1)首先将用户密码修改成MD5加密后的,如上图
(2)获取前端登录的密码进行MD5加密,与数据库中的密码做比较,验证是否正确
Swagger(后端)
本项目是基于前后端分离的方式进行的,这种开发方式需要提前把接口定义好,然后后端的开发人员才能进行开发,接口如何设计这里没有过多讲,直接给了接口文档,后端人员根据项目需求和接口文档开发完代码之后,如何去验证开发的代码是否正确,在项目制可以运用Apifox相机接口发送请求,但是非常麻烦,swagger可以提高我们的效率
1、什么是Swagger?
使用 Swagger 只需要按照它的规范去定义接口及接口相关信息,就可以做到生成接口文档,以及在线接口调试页面。直接使用 Swagger 是很繁琐的,因此项目中我们使用到的是 knife4j 框架。什么是 knife4j 呢?
2、什么是 knife4j?
knife4j 是为 Java MVC 框架集成 Swagger 生成 Api 文档的增强解决方案。
3、如何使用 knife4j?
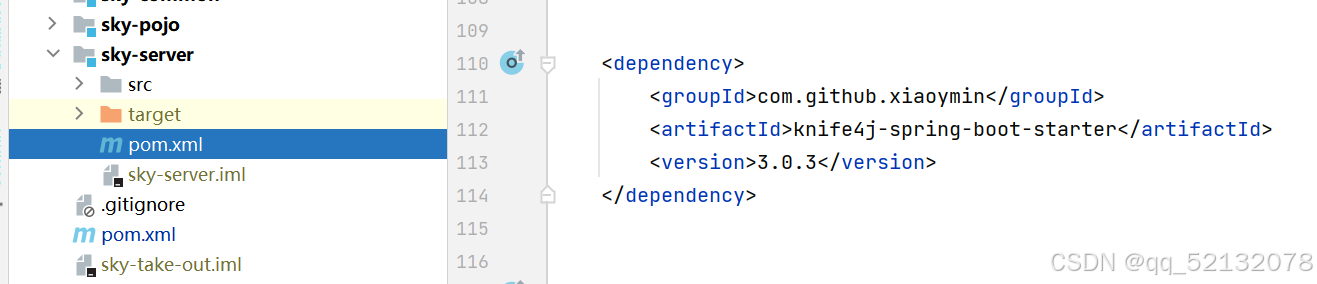
(1)导入Maven坐标
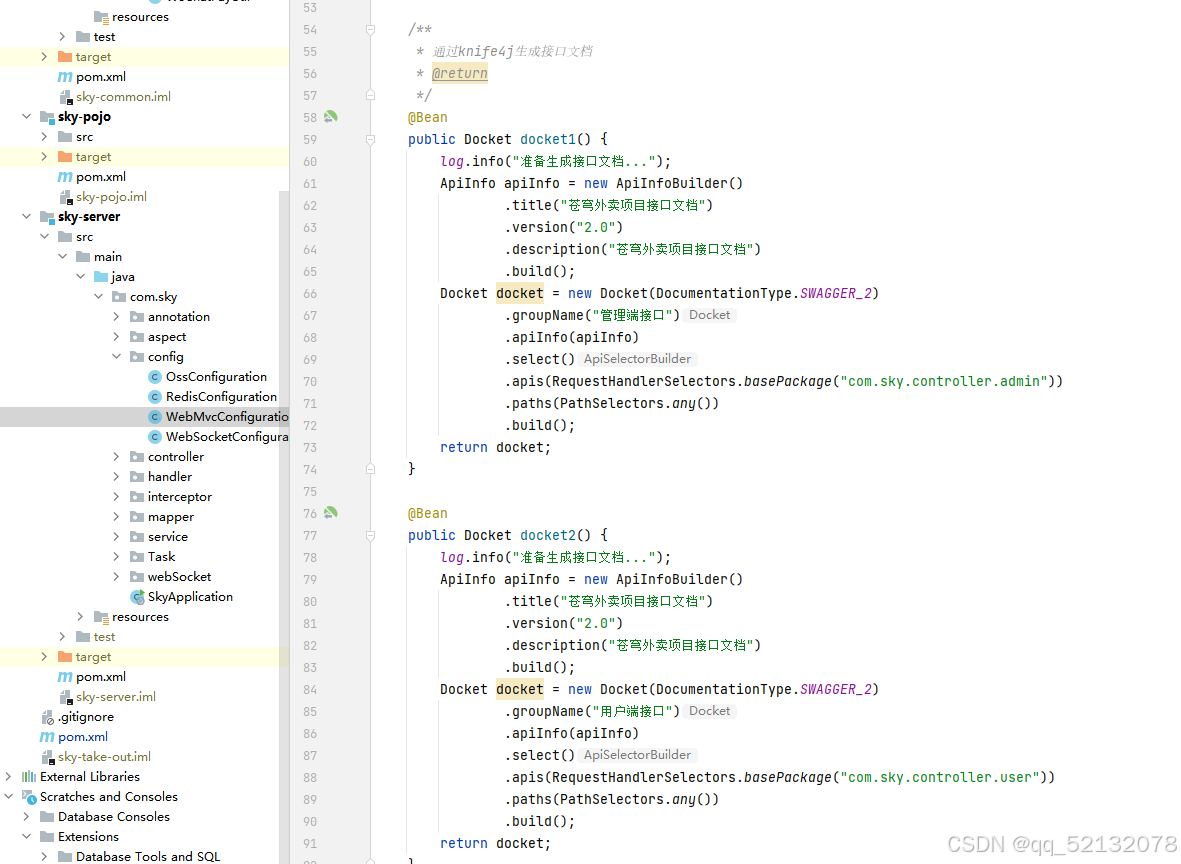
(2)在配置类中加入knife4j相关配置
(3)设置静态资源映射
因为项目的表现层是基于Spring MVC框架的,如果不设置静态资源,是访问不到接口文档的
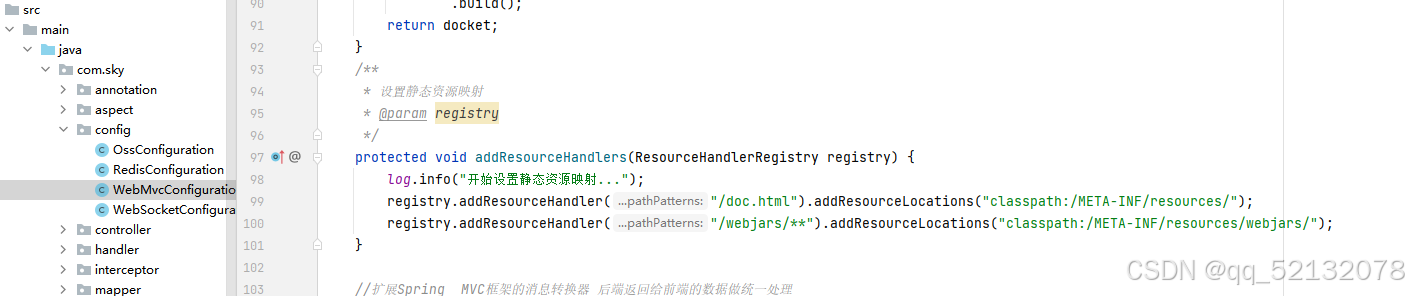
配置好讲项目启动以来,才可以访问接口文档,网址为: localhost:8080/doc.html
4、Swagger的常用注解
@Api加在类上
@Api(tags = "员工相关接口")@ApiOperation加在方法上
/**
* 退出
*/
@PostMapping("/logout")
@ApiOperation(value = "员工退出")
public Result<String> logout() {
log.info("员工退出登录");
return Result.success("退出成功");
}

JWT-JSON Web令牌 (后端)
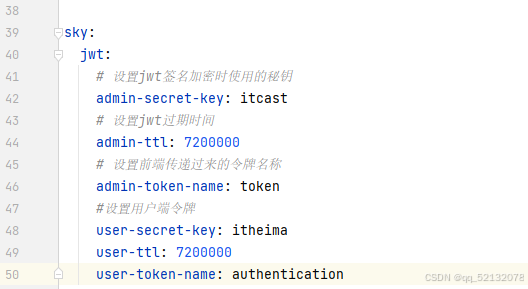
1、什么是JWT?
JWT定义了一种简洁的、自包含的格式,用于在通信双方以JSON数据格式安全带传输信息。JWT的简洁在于JWT就是一个字符串,可以在请求参数或者请求头中,直接传递JWT令牌。JWT令牌看似是一个随机字符串,但是可以根据自身需要在 JWT 令牌当中来存储自定义内容的,比如可以直接在 JWT 令牌中来存储用户相关的信息。相较于传统的会话跟踪方案,令牌技术有更多的优点,以及更高的安全性。
2、JWT的作用:
通过JSON形式作为Web应用中的令牌,用于在各方之间安全地将信息作为JSON对象传输。在数据传输过程中还可以完成数据加密、签名等相关处理。 用户输入用户名和密码正确时,登录到后端服务器,这时服务器会返回给前端一个JWT令牌,以后每次访问时,都在请求头中加上JWT令牌,验证通过后才可以登陆成功。还可以给JWT令牌设置时效
3、JWT的组成
整个 JWT 令牌是由三个部分组成的,三个部分之间只用 “.” 来分隔


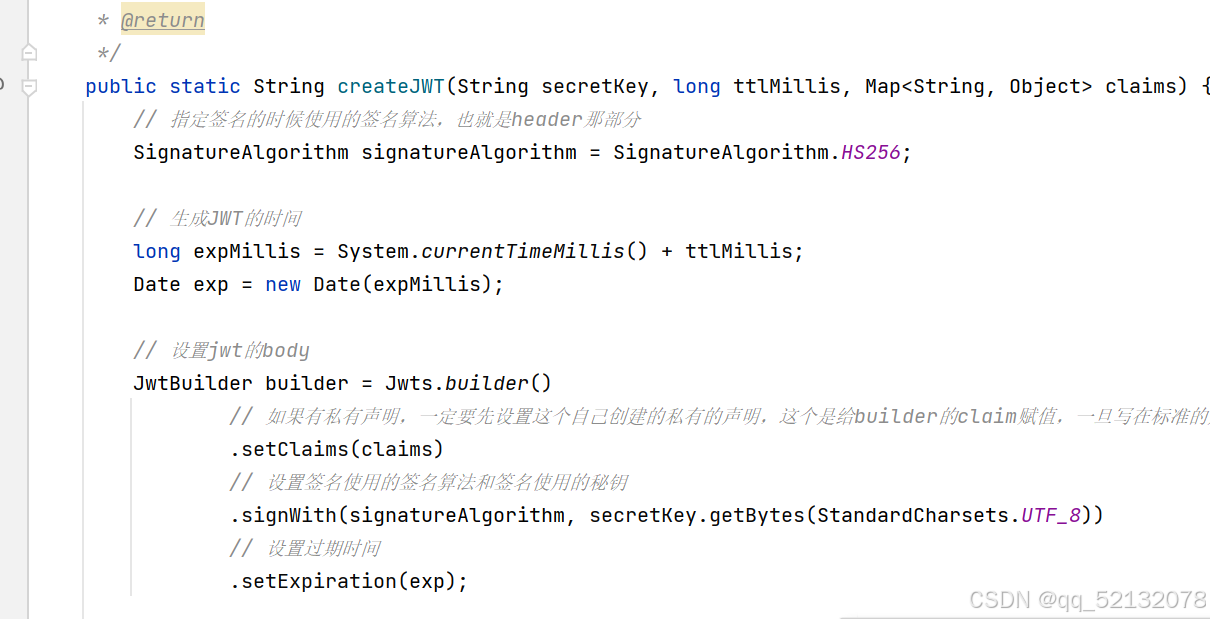
4、如何生成JWT令牌
(1)导入Maven坐标 ,在总的项目pom文件里

(2)生成JWT令牌
(3)校验JWT令牌
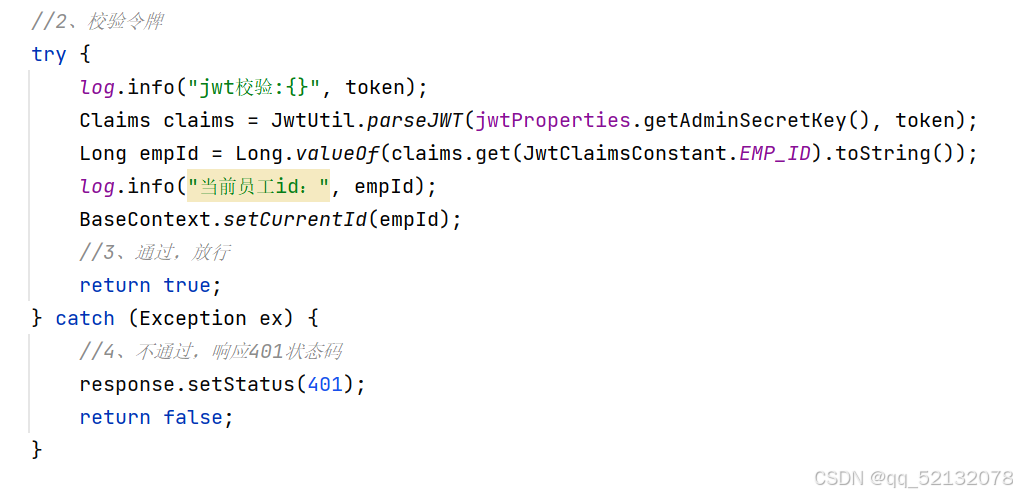
在接口文档中测试时,如果校验失败,很可能令牌已经过期,这是需要重新登陆账号,生成一个新的令牌,在接口文档中,设置成全局参数,关掉所有接口重新发送请求即可。意思是,用户要用生成的令牌去校验,一致才会通过,不一致会报错。
过滤器Filter(后端)
1、什么是过滤器
过滤器Filter,是 JavaWeb 三大组件(Servlet、Filter、Listener)之一,过滤器可以把对资源的请求拦截下来,从而实现一些特殊的功能,过滤器一般完成一些通用的操作,比如:登录校验、统一编码处理等。
使用时在 Filter类上加 @WebFilter 注解后,还需要在启动类上也加上一个注解,@ServletComponentScan,因为 Filter 是 JavaWeb 三大组件之一,并不是 spring boot 当中提供的,而如果想要在 spring boot 项目中使用 JavaWeb 三大组件就必须要在启动类上加上@ServletComponentScan 注解,加上该注解后就表示当前项目是支持 Servlet 相关组件的。
2、如何使用过滤器(省略)
3、过滤器的执行流程
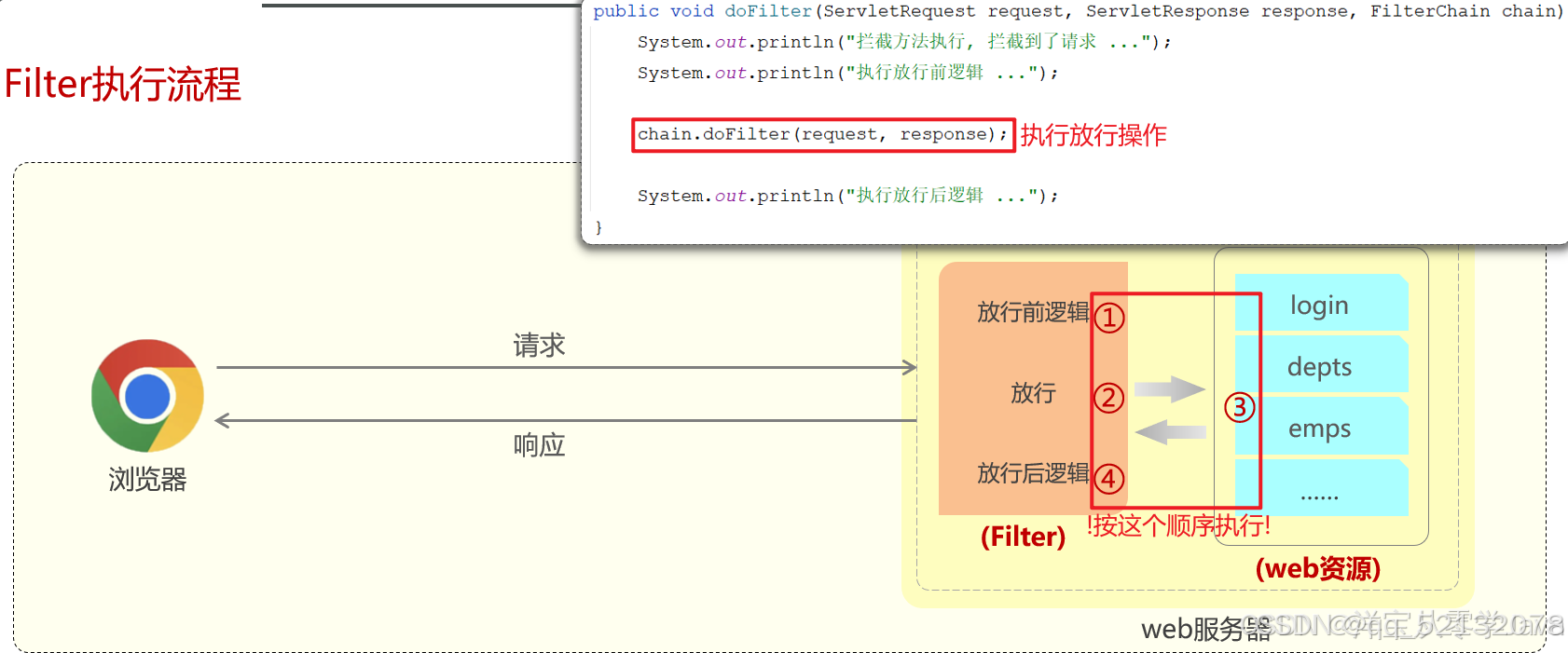
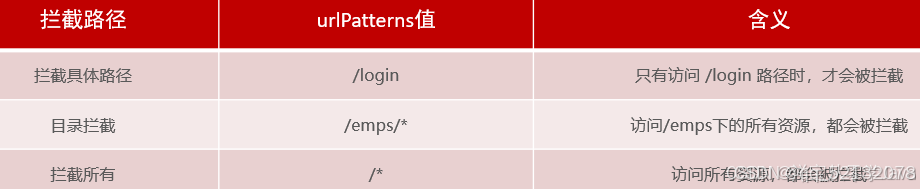
4、过滤器的拦截途径
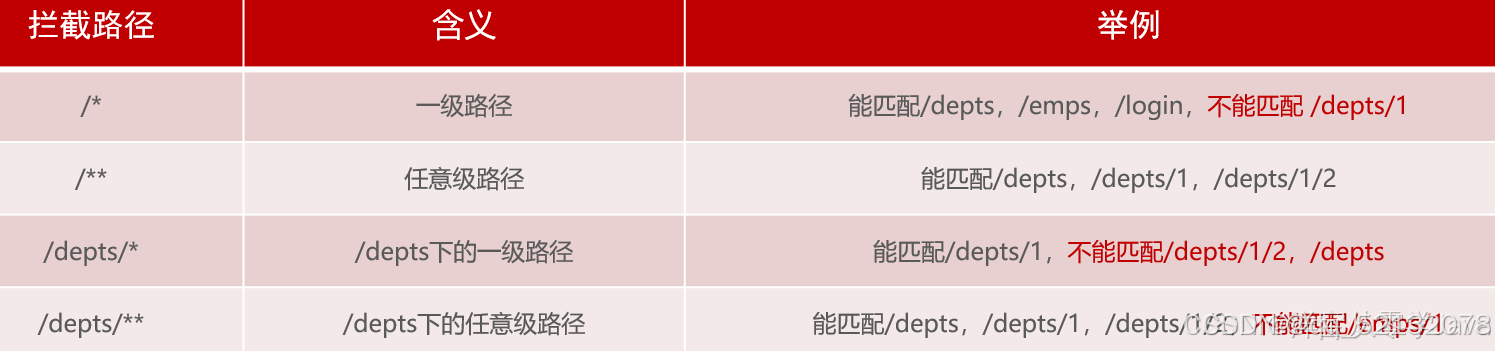
“/*”表示访问的所有资源都会被拦截

拦截器(后端)
1、什么是拦截器
拦截器是一种动态拦截方法的机制,类似于过滤器。是Spring 架构提供的,用来动态拦截控制器方法的执行,在指定的方法调用前后,根据业务需要执行预先设定的代码。
2、如何使用拦截器
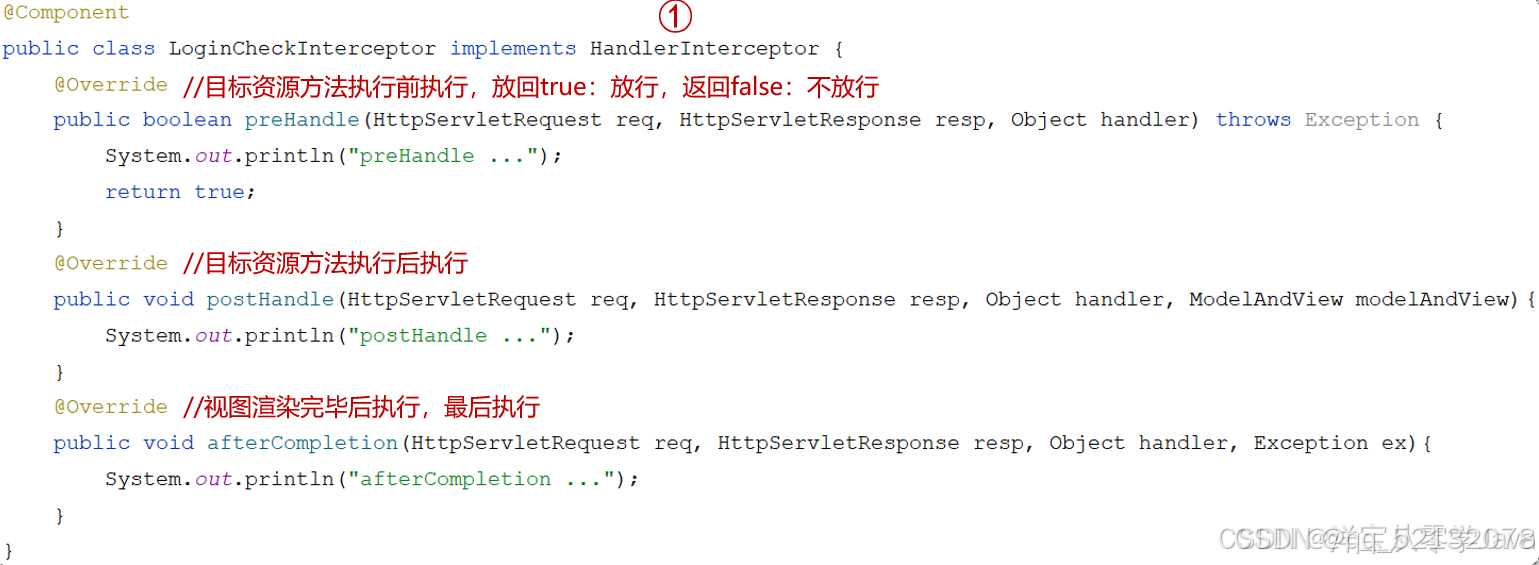
(1)定义interceptor,preHandle在方法前执行

还有另外两种可供选择:
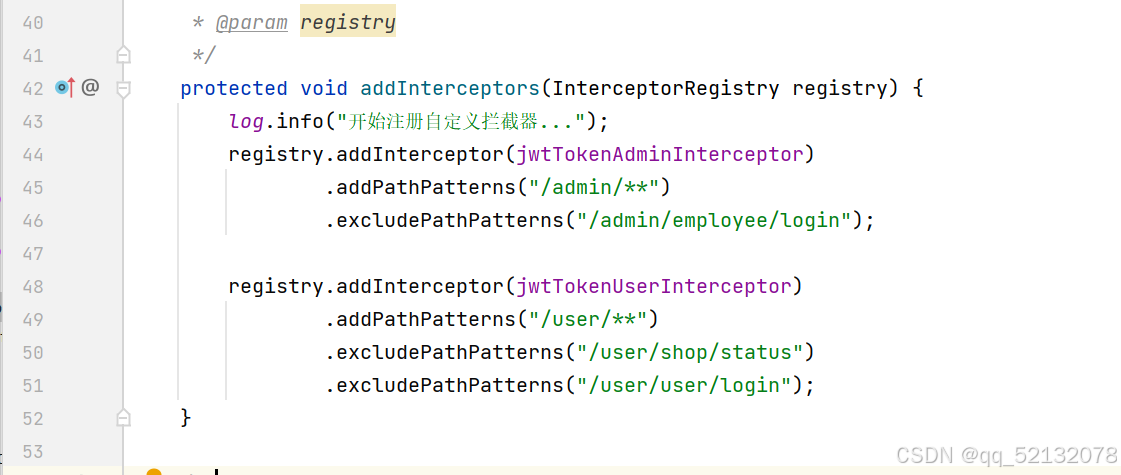
(2)配置Interceptor
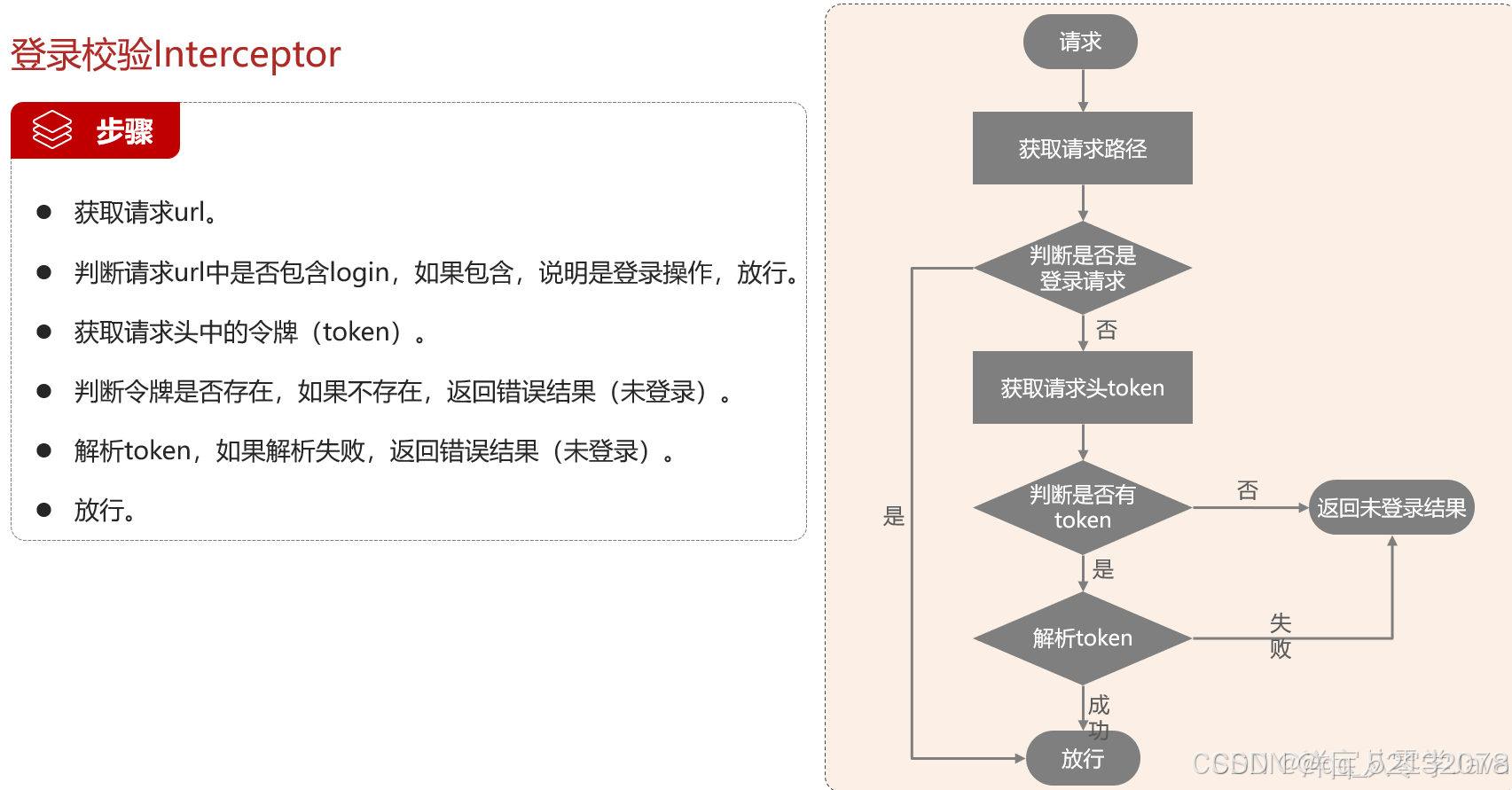
定义了需要拦截的目录,除去员工和用户登录方法,其他方法都要被拦截
(3)拦截器的执行流程
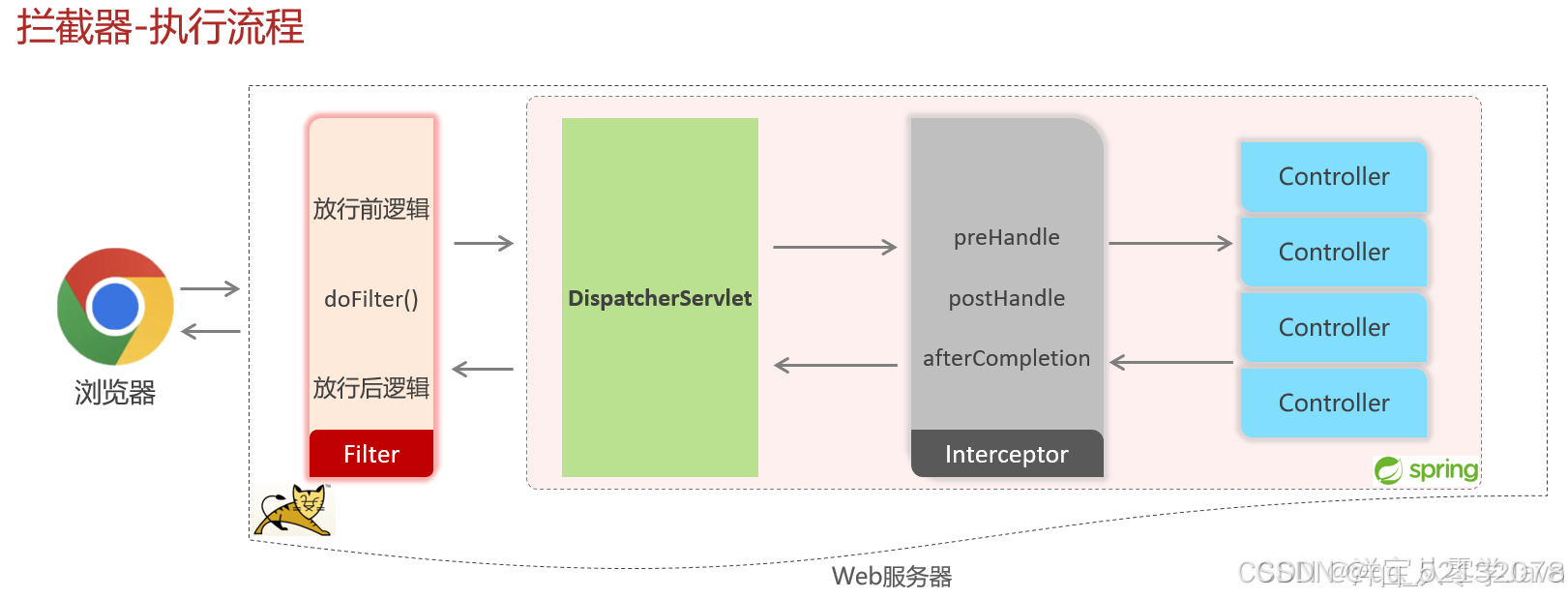
(4)拦截器的拦截路径
(4)拦截器作用下的登录校验
异常处理(后端)
方法一:在controller的方法中try...catch
缺点:太麻烦本文中有大量的controller方法,每个controller类中有很多接口,每一个都用try...catch太不优雅。
方案二:进行全局配置
不管是在 Controller层、Service层还是 Mapper层,只要出现了问题,都会统一的抛给全局异常处理器来处理,代码就会呈现更加优雅了
package com.sky.handler;
import com.sky.constant.MessageConstant;
import com.sky.exception.BaseException;
import com.sky.result.Result;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
import java.sql.SQLIntegrityConstraintViolationException;
/**
* 全局异常处理器,处理项目中抛出的业务异常
*/
@RestControllerAdvice
@Slf4j
public class GlobalExceptionHandler {
/**
* 捕获业务异常
*
* @param ex
* @return
*/
@ExceptionHandler
public Result exceptionHandler(BaseException ex) {
log.error("异常信息:{}", ex.getMessage());
return Result.error(ex.getMessage());
}
@ExceptionHandler
public Result exceptionHandler(SQLIntegrityConstraintViolationException ex) {
//获取报错信息 Duplicate entry 'zhangsan' for key 'employee.idx_username'
String message = ex.getMessage();
//若该信息中含有实体冲突的字段,表示添加重复
if (message.contains("Duplicate entry")) {
String[] split = message.split(" ");//得到报错信息按空格分的数组,想要的名字在2索引
String username = split[2];
String msg = username + MessageConstant.ALREADY_EXISTS;
return Result.error(msg);
}else {
return Result.error(MessageConstant.UNKNOWN_ERROR);
}
}
}
分层解耦(后端)
耦合:衡量软件各个层/模块之间的依赖、关联的程度
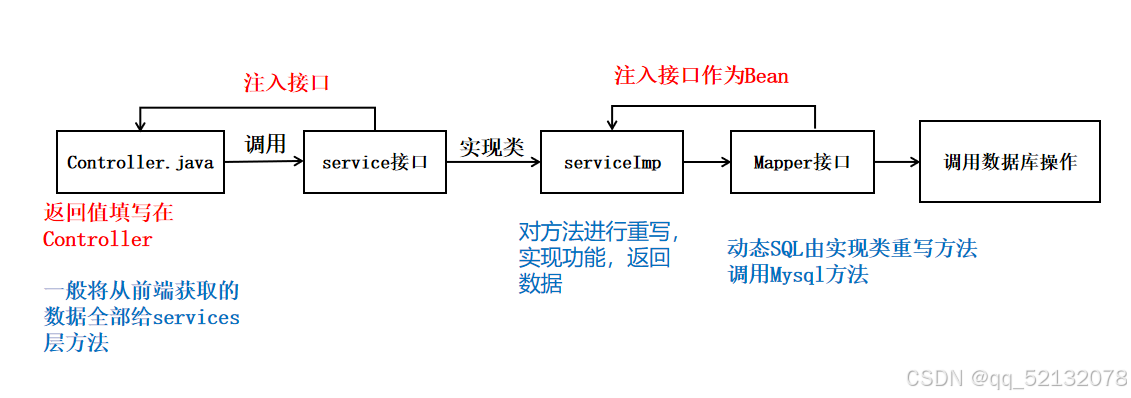
而在软件设计当中,有一个原则:高内聚低耦合。层与层之间相互依赖,牵一发而动全身。解耦后,即使service层代码发生变动,也不会影响到controller层和dao层

那么解耦开后,各个层之间如果再要调用该怎么办呢?这就涉及到了spring当中的两个重要的概念,IOC和DI。
1、什么是IOC
IOC容器是Spring 用来实现 IOC的载体, IOC容器实际上就是个Map(key,value),Map 中存放的是各种对象。原来需要什么对象就new什么对象,现在只需要放在IOC容器中统一管理,需要时直接取。
将对象之间的相互依赖关系交给 IoC 容器来管理,并由 IoC 容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。 IoC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件xml/注解即可,完全不用考虑对象是如何被创建出来的
通过@Component注解来完成,表示将当前类交给IOC容器,称为IOC容器的bean.
2、什么是DI
通过@Autowired注解,为所需要类注入对象,该注解表示运行时,IOC容器会提供该类型的bean对象,并赋值给该变量-依赖注入
3、什么是Bean对象

将对象或者类放进IOC容器时,就成为了容器中的Bean
注意事项:
- 声明bean的时候,可以通过value属性指定bean的名字,如果没有指定,默认为类名首字母小写。
-
使用以上四个注解都可以声明bean,但是在Springboot集成web开发中,声明控制器bean只能用@Controller
Bean组件扫描
-
前面声明bean的四大注解,要想生效,还需要被组件扫描注解@ComponentScan扫描。
-
@Componentscan注解虽然没有显式配置,但是实际上已经包含在了启动类声明注解 @SpringBootApplication中,默认扫描的范围是启动类所在包及其子包。
-
如果需要被声明bean的类和Application类不在同一包下,那么默认扫描是无法扫描到的,此时会报错,有两种解决办法:
-
在Aplication类中手动添加扫描,如@ComponentScan({“dao”,”com.wxh”}); (该方法不推荐)
-
推荐按照SpringBoot的规范将代码放在启动类所在包及其子包下,使得在默认的扫描范围里
当类型相同的声明bean的类的数量有多个时,程序会报错,因为IOC容器不知道提供哪一个作为该类型的bean对象,此时有三种解决办法:
(1)加@Primary注解,使得该类具有更高的优先级,依赖注入是优先注入
(2)@Qualifier注解
该注解一般加在@Autowired之前,表示提供哪一个作为bean对象,该方法会造成耦合,即三层框架之间会更加紧密,不利于修改代码。
(3)@Resource注解替代@Autowired 利用name属性指定对象
指定要注入的bean是哪个, 需要引入javax.annotation.Resource包
4、解耦步骤
AOP(后端)
1、什么是AOP
AOP 面相切面编程,用于在不改变原有代码的情况下,通过“切面”(Aspect)来增强或修改程序的行为。它通过将横切关注点(如日志记录、安全性、事务管理等)从核心业务逻辑中分离出来,减少代码的重复性,提高代码的可维护性。
2、AOP的核心概念
(1)连接点:JoinPoint,可以被AOP控制的方法(暗含方法执行时的相关信息)
(2)通知:Advice,指哪些重复的逻辑,也就是共性功能(最终体现为一个方法)
(3)切入点:Pointcut,匹配连接点的条件,通知仅会在切入点方法执行时被应用
切入点表达式: 表示在该类下的所有方法都是切入点
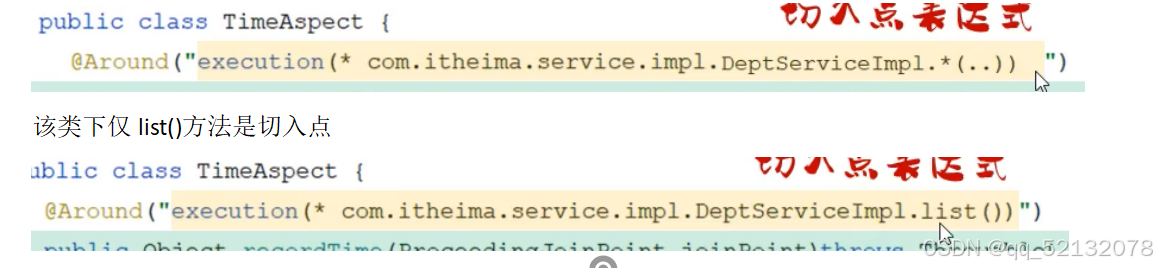
切入点重复时,抽取出来 pointcut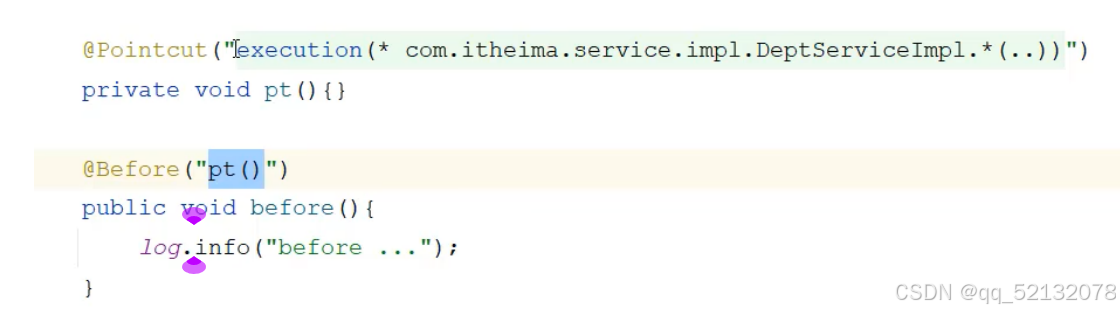
(4)切面(Aspect):包含横切关注点逻辑的模块,例如日志功能或安全性校验。
3、如何使用AOP
本项目中用于公共字段的填充,这些字段在员工表和分类表中都有,使用AOP比每一个数据都赋值简单,每一个业务都要这么去赋值的话,代码就会冗余,而且不方便我们后期去维护

持久层中不是每个方法都要拦截,只需要为插入操作和更新操作进行公共字段赋值,这时需要用到自定义注解方法,为需要的操作加注解,具体方法如下:
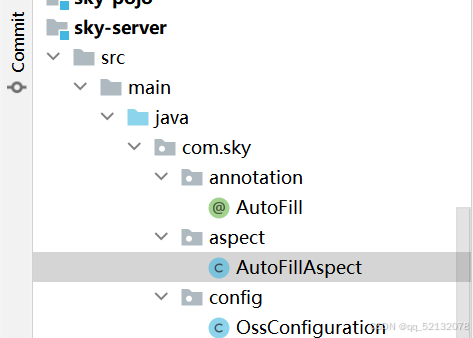
1.自定义注解 AutoFill,用于标识需要进行公共字段自动填充的方法
2.自定义切面类 AutoFillAspect,统一拦截加入了 AutoFill注解的方法,通过反射为公共字段赋值
3.在 Mapper 的方法上加入 AutoFill注解
自定义注解代码:
package com.sky.annotation;
//自定义注解,用于标识,讴歌方法需要进行功能字段自动填充处理
import com.sky.enumeration.OperationType;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.METHOD)//指定注解只能加在方法上
@Retention(RetentionPolicy.RUNTIME)
public @interface AutoFill {
OperationType value();
}
自定义切面类:
package com.sky.aspect;
import com.sky.constant.AutoFillConstant;
import com.sky.context.BaseContext;
import com.sky.enumeration.OperationType;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.Signature;
import org.aspectj.lang.annotation.Aspect;
import com.sky.annotation.AutoFill;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MemberSignature;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.context.annotation.EnableAspectJAutoProxy;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
import java.time.LocalDateTime;
@Aspect
@Slf4j
@Component
public class AutoFillAspect {
//切入点 表示 既要在mapper包下,又要满足在@AutoFill注解下
@Pointcut("execution(* com.sky.mapper.*.*(..)) && @annotation(com.sky.annotation.AutoFill)")
public void autoFillPointCut() {
}
//前置通知,在通知中进行公共字段的赋值
@Before("autoFillPointCut()")
public void autoFill(JoinPoint joinPoint) {
log.info("开始进行公共字段自动填充");
//获取到当前被拦截的方法上的数据库操作类型 查询操作还是更新操作
MethodSignature signature = (MethodSignature) joinPoint.getSignature();//包含拦截方法的基本信息。如方法名 数据类型
//获得方法上的注解对象
AutoFill autoFill = signature.getMethod().getAnnotation(AutoFill.class);
//获取数据的操作类型 这三句知道目的是获得操作类型即可
OperationType operationType = autoFill.value();
//获取到当前被拦截的方法的参数--实体对象
Object[] args = joinPoint.getArgs();
if (args == null || args.length == 0) {
return;
}
Object entity = args[0];//约定实体放在第一位
//准备赋值数据 当前的时间和id
LocalDateTime now = LocalDateTime.now();
Long currentId = BaseContext.getCurrentId();
//根据当前不同的操作类型,为对应的属性通过反射来赋值
if(operationType == OperationType.INSERT){
try {
Method setCreateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_CREATE_TIME, LocalDateTime.class);
Method setCreateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_CREATE_USER, Long.class);
Method setUpdateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_TIME, LocalDateTime.class);
Method setUpdateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_USER, Long.class);
//通过反射为对象赋值
setCreateTime.invoke(entity,now);
setCreateUser.invoke(entity,currentId);
setUpdateTime.invoke(entity,now);
setUpdateUser.invoke(entity,currentId);
} catch (Exception e) {
e.printStackTrace();
}
}else if(operationType == OperationType.UPDATE){
try {
Method setUpdateTime = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_TIME, LocalDateTime.class);
Method setUpdateUser = entity.getClass().getDeclaredMethod(AutoFillConstant.SET_UPDATE_USER, Long.class);
//通过反射为对象赋值
setUpdateTime.invoke(entity,now);
setUpdateUser.invoke(entity,currentId);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
位置:
Redis(后端)
1、什么是redis?
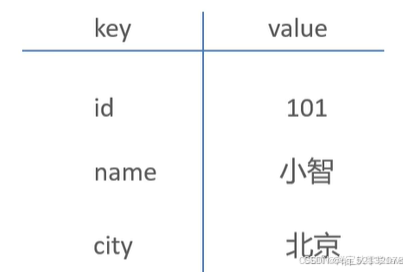
Redis是一个基于内存的 key-value 结构数据库。作为数据库,与 MySQL 类似,都是用来存储数据的。但不同的是,MySQL 是将数据以数据文件的方式存在磁盘上,本质上是磁盘存储,而 Redis 则是将数据存储在内存中的,本质上是内存存储。除了存储介质不一样,二者存储数据的结构也是不一样的,MySQL 是通过二维表来存储数据,而 Redis 则是基于 key-value 结构的,也就是键值对。如下图所示:
由于 Redis 是基于内存存储的,所以读写性能相对于 MySQL 会更高,但也正是因为其基于内存存储,而内存是有限的,所以不可能将所有的数据都存储到 Redis 当中。Redis 一般适合存储一些热点数据,热点数据的特点就是在某一个特定的时间点,会有大量的用户去访问它,比如在抢购秒杀的时候,会有大量的用户在这个时间点上同时去访问数据,这个时候数据就适合存储在 Redis 当中。由此可以看出,Redis 并不可以取代 MySQL,而相当于是对 MySQL 的一个补充,大部分情况下,二者是同时出现在一个项目中使用的,Redis 用来存储热点数据来提高读取性能,而 MySQL 则用来存储绝大部分的业务数据。
2、什么是key-value结构?
key是字符串类型,value有5中常用的数据类型

3、如何使用Redis?
使用Redis的Java客户端,常用的有:Jedis、Lettuce、Spring Data Redis,其中Spring Data Redis是Spring的一部分,对Redis底层开发进行了高度封装。在Spring项目中,可以使用Spring Data Redis来简化操作。
4、如何使用Spring Data Redis?
(1)首先需要导入Maven坐标,在service的pom文件中
(2)配置数据源
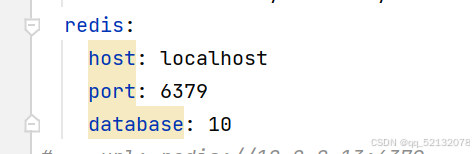
(3)编写配置类 通过RedisTemplate对象操作Redis
package com.sky.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
@Slf4j
public class RedisConfiguration {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory){
RedisTemplate redisTemplate = new RedisTemplate();
//设置redis的连接工厂对象
redisTemplate.setConnectionFactory(redisConnectionFactory);
//设置redis key的序列化器
redisTemplate.setKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
}
5、MySQL查询慢
当用户比较多时,一起访问数据库会造成MySQL压力过大,查询速度慢,性能下降,用户查询一个分类可能需要几秒钟,这时候我们需要用Redis缓存,读写速度相对于MySQL都要快很多,本项目的缓存思路如下:
根据用户端角度,查看一个分类,该分类下所有菜品都要立即展示,所一根据菜品分类进行缓存
public Result<List<DishVO>> list(Long categoryId) {
//构造redis的key,规则 dish_分类id
String key = "dish_"+categoryId;
//查询redis中是否存在菜品数据
List<DishVO> list = (List<DishVO>) redisTemplate.opsForValue().get(key);
//判断查到的内容是否为空
if(list !=null && list.size()>0){
//无需查询数据库,直接返回
return Result.success(list);
}
Dish dish = new Dish();
dish.setCategoryId(categoryId);
dish.setStatus(StatusConstant.ENABLE);//查询起售中的菜品(一个)
//如果不存在,查询数据库,将查询到的数据放入redis
list = dishService.listWithFlavor(dish);
redisTemplate.opsForValue().set(key,list);
return Result.success(list);
}Spring Cache
当数据库中菜品数据有变更时需要清理缓存数,比如管理端修改了菜品的价格,如果不清理掉缓存数据的话,用户端看到的还会是我们一开始缓存好的数据,这是需要对缓存进行清理,没修改一次,需要将dish_开头的数据清理掉,然后客户查询时会存入新的数据。
cleanCache("dish_*");1、什么是Spring Cache?
Spring Cache 是由 spring 提供的一个缓存框架,使用它可以进一步的简化我们的代码,通过注解的方式实现缓存的功能。当我们想要缓存数据时,只需要在相应的方法上加入它提供的注解即可。这种方式类似于事务管理,在要进行事务控制的时候,只需要在 Service 的方法上加入事务注解就可以了。二者是有点儿相似的。Spring Cache 提供了一层抽象,底层可以切换不同的缓存实现,如:EHCache、Caffeine、Redis,在本项目中,产品的数据都会缓存到 Redis 当中。但如果在后期,想换一个缓存实现,比如不想使用 Redis 了,想换成 EHCache 只需要再额外导入 EHCache 相关的 jar 包就可以了,而 Spring Cache 提供的注解,都是通用的。这样就可以非常轻松的来切换不同的缓存实现,且代码不需要再进行额外的修改。
使用时导入Maven坐标到service的pom文件即可

2、Spring Cache的常用注解
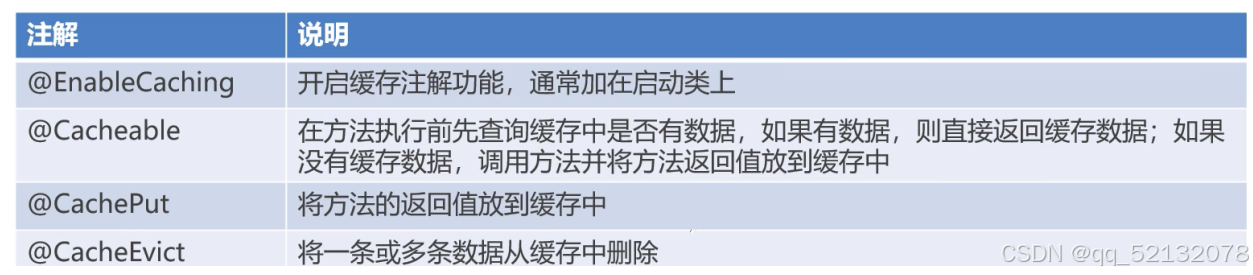
Spring Task
Spring Task 框架是Spring框架中提供的任务调度工具,可以按照约定的时间自动执行某个代码逻辑,比如外卖中倒计时支付订单
1、如何使用Spring Task?
(1)导入 maven 坐标 spring-context
(2)启动类添加注解 @EnableScheduling 开启任务调度

(3)自定义任务类
package com.sky.Task;
import com.sky.entity.Orders;
import com.sky.mapper.OrderMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.util.List;
@Component
@Slf4j
public class OrderTask {
@Autowired
private OrderMapper orderMapper;
//处理超时订单
@Scheduled(cron = "0 * * * * ?") //每分钟触发一次 cron.qqe2.com 网站生成
public void processTimeoutOrder(){
log.info("定时处理超时订单:{}", LocalDateTime.now());
LocalDateTime time = LocalDateTime.now().plusMinutes(-15);
List<Orders> orderList = orderMapper.getByStatusAndOrderTimeLT(Orders.PENDING_PAYMENT, time);
if(orderList != null && orderList.size()>0){
//有超时未支付的订单 更新每一个订单的状态为取消
for (Orders orders : orderList) {
orders.setStatus(Orders.CANCELLED);
orders.setCancelReason("订单超时,自动取消");
orders.setCancelTime(LocalDateTime.now());
orderMapper.update(orders);
}
}
}
//处理一直在派送中的订单
@Scheduled(cron = "0 0 1 * * ?")//每天陵城一点触发一次
public void processDeliveryOrder(){
//查询上一个工作日中,一直处于派送中的订单
LocalDateTime time = LocalDateTime.now().plusMinutes(-60);
List<Orders> orderList = orderMapper.getByStatusAndOrderTimeLT(Orders.DELIVERY_IN_PROGRESS, time);
if(orderList != null && orderList.size()>0){
//有这样的订单 更新状态信息为完成
for (Orders orders : orderList) {
orders.setStatus(Orders.COMPLETED);
orderMapper.update(orders);
}
}
}
}
2、Cron表达式
上面代码 “@Scheduled(cron = “0 0 1 * * ?”)” 中的 0 0 1 * * ? 被称为 cron 表达式
cron 表达式其实就是一个字符串,通过 cron 表达式可以定义任务触发的时间。
构成规则:分为 6 或 7 个域,由空格分隔开,每个域代表一个含义
每个域的含义分别为:秒、分钟、小时、日、月、周、年(可选)
例如:2022年10月12日上午9点整 对应的cron表达式为:0 0 9 12 10 ?2022
WebSocket
WebSocket 是基于 TCP 的一种新的网络协议。它实现了浏览器与服务器全双工通信——浏览器和服务器只需要完成一次握手,两者之间就可以创建持久性的连接,并进行双向数据传输。它与我们熟知的 http 协议是不一样的。
1、HTTP 协议和 WebSocket 协议对比:
(1)HTTP 是短连接
(2)WebSocket 是长连接
(3)HTTP 通信是单向的,基于请求响应模式
(4)WebSocket 支持双向通信
(5)HTTP 和 WebSocket 底层都是TCP连接
2、WebSocket 的缺点
(1)服务器长期维护长连接需要一定的成本
(2)各个浏览器支持程度不一
(3)WebSocket 是长连接,受网络限制比较大,需要处理好重连
3、在本项目的应用
当客户下单时需要有下单提醒(管理端播放来单铃声和提示框),催单时也要有催单提醒,因此需要使用到 WebSocket 实现管理端页面和服务端保持长连接状态。实现逻辑为当客户支付后,调用 WebSocket 的相关API实现服务端向管理员端推送消息。管理员端浏览器解析服务端推送的消息,判断是来单提醒还是客户催单,进行相应的消息提示和语音播报。
(代码省略)
Apache POI
Apache POI 是一个处理 Miscrosoft Office 各种文件格式的开源项目。简单来说就是,我们可以使用 POI 在 Java 程序中对 Miscrosoft Office 各种文件进行读写操作。在本项目中,可以使用该技术将店家运营数据进行导出为Excel报表。具体实现代码如下:
ReportController:
//导出运营数据报表
@GetMapping("/export")
@ApiOperation("导出运营数据报表")
public void export(HttpServletResponse response){
log.info("导出运营数据报表");
reportService.exportBusinessData(response);
}ReportService:
//导出运营数据报表
void exportBusinessData(HttpServletResponse response);ReportServiceImpl:
//导出运营数据报表
@Override
public void exportBusinessData(HttpServletResponse response) {
//查询数据库获得营业数据
LocalDate dateBegin = LocalDate.now().minusDays(30);
LocalDate dateEnd = LocalDate.now().minusDays(1);
BusinessDataVO businessData = workspaceService.getBusinessData(LocalDateTime.of(dateBegin,
LocalTime.MIN), LocalDateTime.of(dateEnd, LocalTime.MAX));
//通过POI将数据写到excel中
InputStream in = this.getClass().getClassLoader().getResourceAsStream("template/运营数据报表模板.xlsx");
//基于末班文件创建一个新的Excel文件
try {
XSSFWorkbook excel = new XSSFWorkbook(in);
//获取表格标签页
XSSFSheet sheet = excel.getSheet("Sheet1");
//填充数据--时间
sheet.getRow(1).getCell(1).setCellValue("时间" + dateBegin + "至" + dateEnd);
//获取第四行
XSSFRow row = sheet.getRow(3);
//营业额
row.getCell(2).setCellValue(businessData.getTurnover());
//订单完成率
row.getCell(4).setCellValue(businessData.getOrderCompletionRate());
//新增用户
row.getCell(6).setCellValue(businessData.getNewUsers());
//获取第五行
row = sheet.getRow(4);
//有效订单
row.getCell(2).setCellValue(businessData.getValidOrderCount());
row.getCell(4).setCellValue(businessData.getUnitPrice());
//填充明细数据---三十天
for (int i = 0; i < 30; i++) {
//遍历每一天
LocalDate date = dateBegin.plusDays(i);
//查询某一天的营业数据 该天从早到晚
BusinessDataVO businessDataVO = workspaceService.getBusinessData(LocalDateTime.of(date, LocalTime.MIN),
LocalDateTime.of(date, LocalTime.MAX));
row = sheet.getRow(7 + i);//获得某一行
row.getCell(1).setCellValue(date.toString());//日期 转成字符串 2001-10-02
row.getCell(2).setCellValue(businessDataVO.getTurnover());//营业额
row.getCell(3).setCellValue(businessDataVO.getValidOrderCount());//有效订单
row.getCell(4).setCellValue(businessDataVO.getOrderCompletionRate());//订单完成率
row.getCell(5).setCellValue(businessDataVO.getUnitPrice());//平均客单价
row.getCell(6).setCellValue(businessDataVO.getNewUsers());//新增用户
}
//通过输出流将文件下载到客户端浏览器
ServletOutputStream out = response.getOutputStream();
excel.write(out);
out.close();
excel.close();
} catch (IOException e) {
e.printStackTrace();
}
}

















 1911
1911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









