







文章目录
前言
对于本次内容的一些基本命令如果不熟悉的可以自行不足,只有在不断探索,学习才能有所收获。
一、Spark SQL与Hive集成(spark-shell)
1.第一步
把hive的配置文件hive-site.xml拷贝到spark的conf的目录下,然后在spark目录下的hive-site.xml中添加如下配置:
<property>
<name>hive.metastore.uris</name>
<value>thrift://panda-pro01.xiong.com:9083</value>
</property>
2.第二步
把hive目录下lib中MySQL的jar包拷贝spark的jars目录下
cp mysql-connector-java-5.1.46-bin.jar /opt/Hadoop/spark/jars
scp mysql-connector-java-5.1.46-bin.jar xiong@10.34.102.251:/opt/modules/spark-2.2.0-bin-custom-spark/jars
注:当hive和spark不在同一台机器时,可以scp发过去。
3.第三步
检查spark-env.sh文件中的hadoop的配置项
HADOOP_CONF_DIR=/opt/modules/hadoop-2.5.0/etc/hadoop
代码如下(示例):
4.启动服务
1.启动hadoop各个结点和mysql
sudo service mysql start 启动mysql
sudo service mysql status 查看状态
2.启动hive中的metastore
bin/hive --service metastore
之后再开一个窗口
bin/hive
5.测试
1.准备数据
0001 hadoop
0002 yarn
0003 hbase
0004 hive
0005 spark
0006 mysql
0007 flume
2.创建数据库
create database kfk;
3.创建表
use kfk;
create table if not exists test(userid string,username string)
row format delimited fields terminated by ' ' stored as textfile;
4.加载数据
load data local inpath "/opt/datas/kfk.txt" into table test;
5.通过spark-shell查看数据
spark.sql("select * from kfk.test").show

6.将数据写入MySQL
1.创建数据库
mysql -u root -p 进入mysql
create table test;
2.将spark sql分析hive中的数据写入到mysql中
import java.util.Properties 导包
val pro = new Properties()
pro.setProperty("driver","com.mysql.jdbc.Driver")
val df = spark.sql("select * from kfk.test")
df.write.jdbc("jdbc:mysql://panda-pro01.xiong.com/test?user=root&password=123456","f_spark",pro)
进入mysql
show tables; 查看所有表
select *from table;

二.Spark SQL 与Hive集成(spark-sql)
操作步奏和前面一样的,只需启动spark-sql看看里面表中数据
bin/spark-sql
只要上面步奏都操作,在spark-sql中会看到数据
use kfk;
show tables;
select *from test

三、Spark SQL之ThirftServer和beeline使用
1.ThirftServer和spark-shell/spark sql的区别:
1.spark-shell,spark-sql都是一个spark application
2.thriftserver,不管你启动多少个客户端(beeline/code),只要是连在一个thriftserver上,永远都是一个spark application,解决了一个数据共享的问题,多个客户端可以共享数据。
3.用thriftserver,在UI中能直接看到sql的执行计划,方便优化
基于Spark的thirftserver来访问hive中的数据,可以让多个客户端连接到同一个服务器端,跑的是同一个application
Thirftserver作为服务端,beeline作为客户端来访问服务端,支持多个客户端同时访问,有助于多个客户端之间数据的共享
2.启动服务
1.启动metastore
bin/hive --service metastore
2.启动thriftserver
sbin/start-thriftserver.sh
3.通过beeline链接
bin/beeline
然后输入
!connect jdbc:hive2://panda-pro02.xiong.com:10000

4.使用SQL命令来来访问hive中的数据表
show databases;
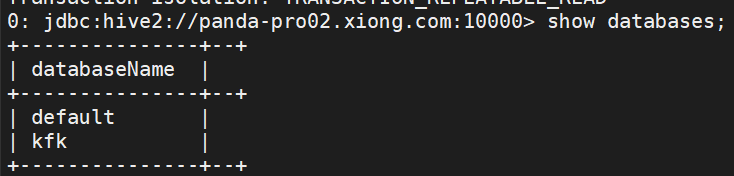
use kfk;
show tables;
select *from test;

可以使用多个客户端beeline连接,进行并行操作,但是只有一个application,每个beeline只作为一个job,这样也显示出了它的优点,而spark-shell/sql启动两个会是两个application,这样很浪费资源。
总结
Spark SQL 与Hive集成就到了这里了,作者水平有限,如有不当之处还请见谅。
















 592
592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











