







reserve1
一般来说,先查看一下字符串,简单的题目会有flag或者敏感数据字符等信息,方便我们定位函数查看字符串的方法为shift+F12。
ctrl+x(交叉引用)查看是哪段函数调用了该字符串
在IDA中,选中数字按"R"键可以将数字转换为字符
reserve2
.data:0000000000601080 flag db 7Bh ; DATA XREF: main+34↑r
.data:0000000000601080 ; main+44↑r ...
.data:0000000000601081 aHackingForFun db 'hacking_for_fun}',0
翻译一下
定义flag变量所存储的字符串为'{',也就是数字7Bh,
定义aHackingForFun变量所存储的字符串为'hacking_for_fun}\0'
因为定义flag字符串时没有结束符'\0',所以strlen(&flag)的长度是到'\0'为止,也就是说这两个字符串拼接了
db可以连续定义多个字符串,而数字0所代表的就是字符串的结束符’\0’。
reserve3
IDA打开,F5反编译出伪代码。
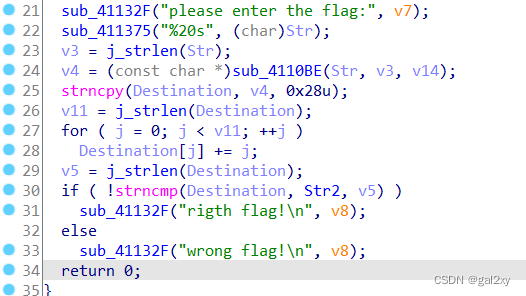
直接看30~33行的伪代码,显然Destination和Str2这两个字符串相同。而Str2的值为e3nifIH9b_C@n@dH。
来看看Destination是怎么得到的。它是通过将v4复制给Destination,然后for循环处理。进一步看v4是怎么得到的,进入到sub_4110BE函数中。
其代码主要思路是将flag按3个划分(最后不足3个的也还是一组),根据每组的个数进入相应的case,转换成4个字符,而它的转换表aAbcdefghijklmn正好是base64表,猜测跟base64有关。
(其实就是base64编码)
分析所有case的代码。
①byte_41A144[0] >> 2

②((byte_41A144[1] & 0xF0) >> 4) | (16 * (byte_41A144[0] & 3))
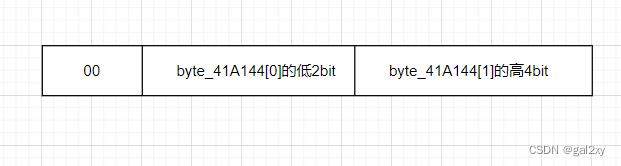
③((byte_41A144[2] & 0xC0) >> 6) | (4 * (byte_41A144[1] & 0xF))
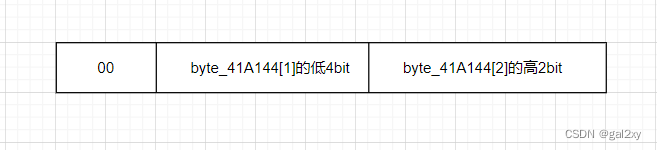
④byte_41A144[2] & 0x3F

很显然以上步骤相结合是可以恢复出相应的原字符,①②可以恢复byte_41A144[0],②③可以恢复byte_41A144[1],③④可以恢复byte_41A144[2]。
代码如下:
destination = 'e3nifIH9b_C@n@dH'
table = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/='
v12 = ''
for i in range(len(destination)):
v12 += chr(ord(destination[i])-i)
print(len(v12))
print(v12)
# v13是flag
v13 = ''
for i in range(0, len(v12), 4):
byte = [0, 0, 0, 0]
for j in range(4):
byte[j] = v12[i+j]
pos = [0, 0, 0, 0]
for j in range(4):
pos[j] = bin(table.index(byte[j]))[2:].zfill(8)
dec_byte0 = pos[0][2:] + pos[1][2:4]
dec_byte1 = pos[1][4:] + pos[2][2:6]
dec_byte2 = pos[2][6:] + pos[3][2:]
print(dec_byte0, chr(int(dec_byte0, 2)))
print(dec_byte1, chr(int(dec_byte1, 2)))
print(dec_byte2, chr(int(dec_byte2, 2)))
v13 += chr(int(dec_byte0, 2)) + chr(int(dec_byte1, 2)) + chr(int(dec_byte2, 2))
print(v13)
实际上,我们分析的case中,就是base64对应不同输入字符的处理过程。所以只需要对destination做预处理,然后进行base64解码就行了,用不着我这么大费周章。
import base64
destination = 'e3nifIH9b_C@n@dH'
v12 = ''
for i in range(len(destination)):
v12 += chr(ord(destination[i])-i)
print(v12)
print(base64.b64decode(v12))
不一样的flag
IDA打开,F5反编译出伪代码。
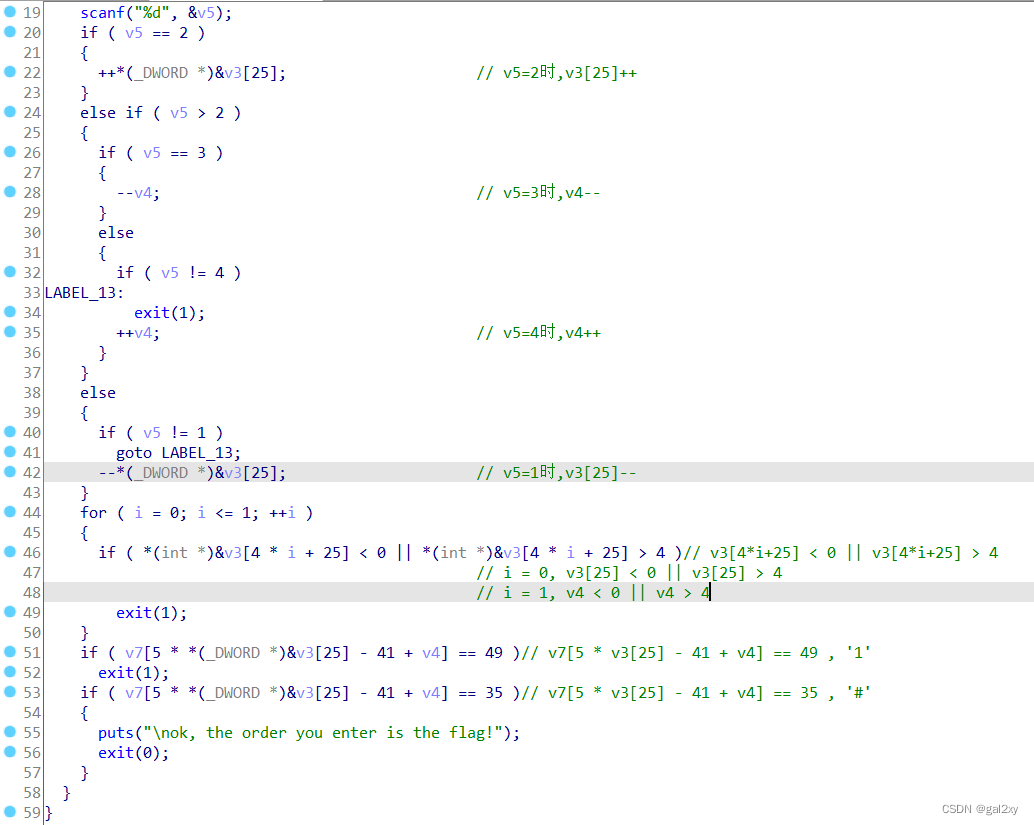
可以看出
v5=1时, v3[25]–
v5=2时, v3[25]++
v5=3时, v4–
v5=4时, v4++
根据第46行的代码可以看出,for循环是限制了v3[25]和v3[29]的范围为[0,4],而v3[29]因为数组下标越界,实际上是v4。所以,for循环的意义在于保证 0 ≤ v3[25], v4 ≤ 4。
继续往下看两个if语句,先看下标公式5 * v3[25] - 41 + v4,根据v3[25]和v4的取值范围,可以确定下标的值的范围为-41 ≤ pos ≤ -17,显然数组越界,那么就看一下它实际指向的位置吧。
首先是变量i 、v5、v4各占4个字节,v3占29个字节,它们总计41个字节,说明v7下标指向的是v3。那么将v7下标取值转换到v3下标,就是-29 ≤ pos ≤ -5。
于是乎,第一个if语句保证在v3[25]和v4变化的过程中,指向的不能是字符 ‘1’ (数值49)。第二个if语句保证在最后,指向的得是字符 ‘#’ (数值35)。
因为已经知道了在v3[25]和v4变化的过程中,始终指向的是v3,而v3的值由 *、1、0、#组成,说明能指向的字符只能是 *、0、#。
显然,还是不能得出很明显的结果。
我尝试遍历v3[25]、v4的取值,将对应的值按行排列,最终发现了秘密。
v3 = '*11110100001010000101111#' + '0'*4
# print(len(v3), v3[24])
# print(chr(49))
# print(chr(35))
maze = []
for v3_25 in range(0, 5):
line = []
for v4 in range(0, 5):
pos = 5*v3_25 - 41 + v4 + 12
line.append(v3[pos])
print(f'({v3_25},{v4}),pos={pos},v3[pos]={v3[pos]}')
maze.append(line)
for line in maze:
print(line)
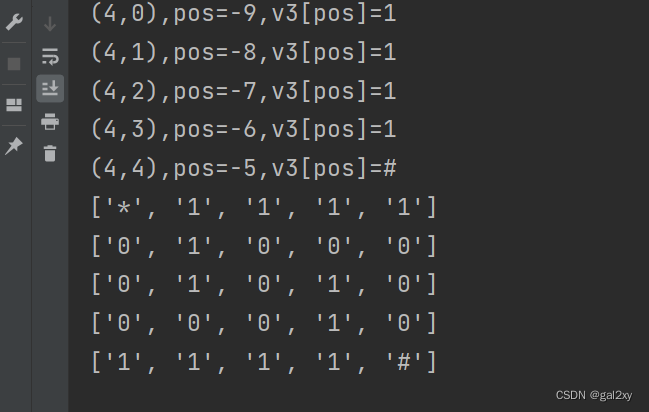
这就是迷宫嘛!起点是 ‘*’,终点是 ‘#’,能走的地方只有 ‘0’。
因为这里是以v3[25]为行,v4为列。根据它们的值的变化情况,有
1 向上走
2 向下走
3 向左走
4 向右走
flag很容易就得出来了。
SimpleRev
注意:数据在内存中是以小端模式存放的,但在IDA中却是以大端模式展示数据,所以在IDA中遇到数字转字符时,需要将转换后的字符进行反转。
IDA打开,F5反编译出伪代码。
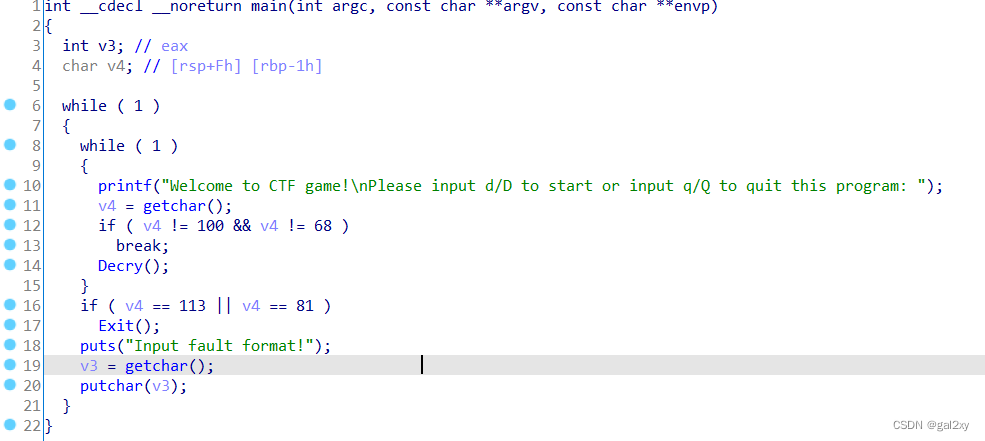
明显可以看出有用的地方是Decry()函数,进入里面进行查看。
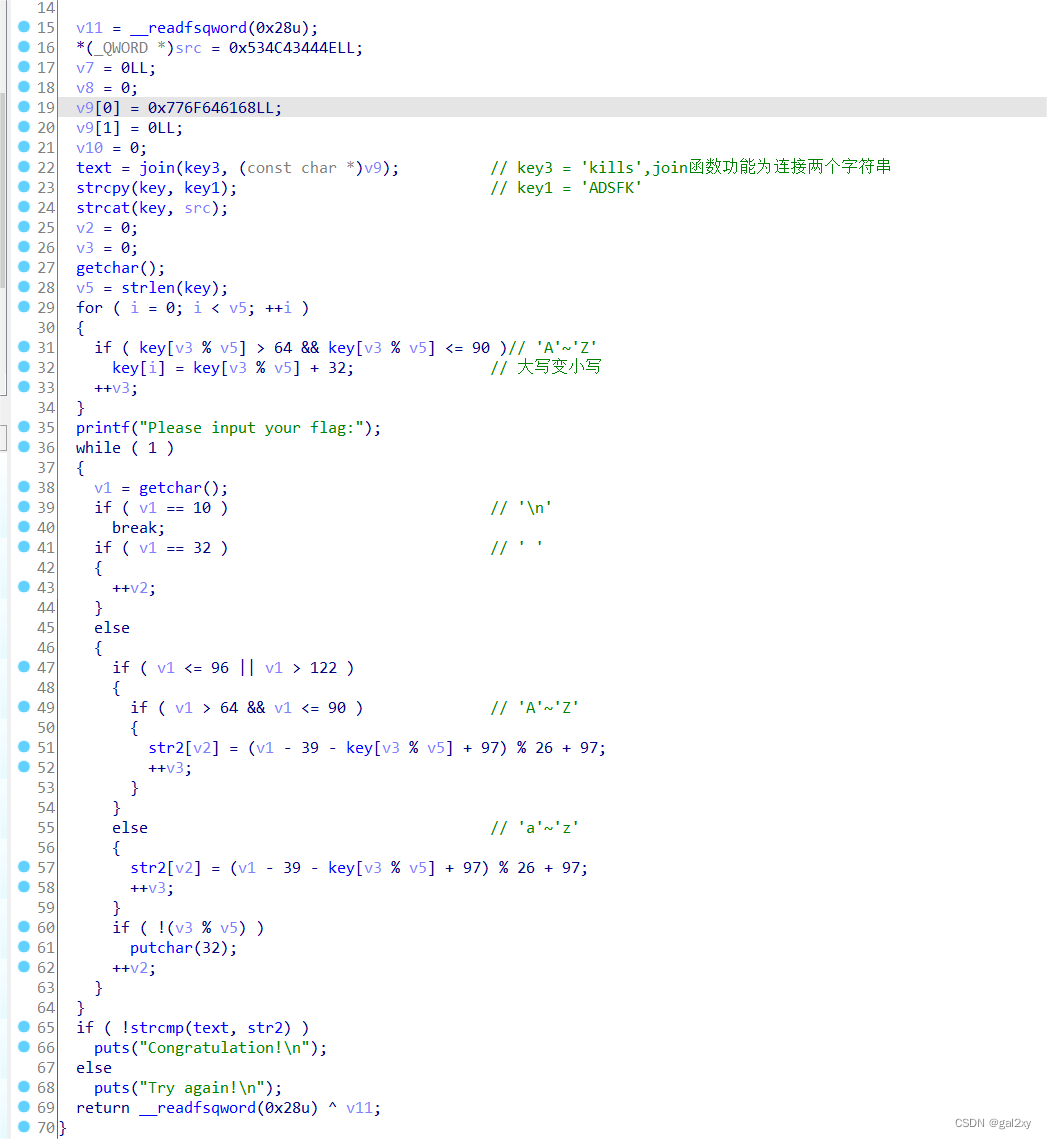
分析伪代码。
容易知道src和v9对应的值,根据后面的操作可以知道,我们处理时要将它们转成字符串,而数据在内存中是以小端模式存放的,但在IDA中却是以大端模式展示数据,所以在IDA中遇到数字转字符时,需要将转换后的字符进行反转。
进入join()函数中,容易分析出其功能是将两个字符串连接起来,故text=key3+v9。
第23~24行使得key=key1+src。
第29~34行的for循环就是将大写字母小写化。v3这个变量在这里毫无意义,因为即使v3累加,最终%v5还是从0开始。
第65~66行表明text必须与str2相同才行。
仔细分析第36~64行代码(str2的生成过程)。v1是用来接收我们输入的数据,当v1='\n'时,结束循环,当v1=' '时,str2对应下标为' ',当v1='A'~'Z'或v1='a'~'z'时,进行相同的加密。
根据text的字符串情况,显然是没有' ',所以我们只需要考虑大小写字母即可。
不过在对加密部分进行逆转时,我们不知道到底时大写字母还是小写字母,是不好进行处理的。用代码说明就是这样子:
加密过程逆过来好像不对劲!!!
((ord(text[i]) - 97) + 39 + (ord(key[i % v5]) - 97)) % 26 + ?(97/65)
改用爆破方法,对大小写字母进行爆破,拼接符合该加密公式的字母。但是离谱的是大小写都有,且是text长度的两倍。而题目没有明确说明是大写还是小写,但翻阅他人博客,都默认是大写字母😅,且没有任何说明。姑且就这样吧。
from Crypto.Util.number import *
from string import ascii_letters,ascii_uppercase,ascii_lowercase
src = 0x534C43444E
v9 = 0x776F646168
src = long_to_bytes(src).decode()[::-1]
v9 = long_to_bytes(v9).decode()[::-1]
key3 = 'kills'
key1 = 'ADSFK'
text = key3 + v9
key = key1 + src
key = key.lower()
v5 = len(key)
flag = ''
# 采取爆破方法
for i in range(len(text)):
for alp in ascii_uppercase:
if (ord(alp) - 39 - ord(key[i % v5]) + 97) % 26 + 97 == ord(text[i]):
flag += alp
print(flag)
Java逆向解密
java反编译软件:jd-gui
[GXYCTF2019]luck_guy
找到主要函数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pOZsDCup-1688435904453)([GXYCTF2019]luck_guy/1.png)]
容易知道case 1是输出flag的,而这个flag是由f1和f2组成的,f1已知,f2则是通过case 4和case 5得出的,那如何确定这两个case的顺序呢?
点击f2变量,发现其在内存中没有赋值,倘若进行case 5,肯定是毫无意义的,所以必然是先case 4将值赋给f2,然后对f2进行处理。
顺序理清楚了,代码也就容易实现了。
f1 = 'GXY{do_not_'
s = b'icug`of\x7F'
f2 = ''
for i in range(len(s)):
if i % 2 == 1:
f2 += chr(s[i]-2)
else:
f2 += chr(s[i]-1)
print(f1+f2)
刮开有奖
打开是个对话框,IDA中搜索Dialog函数,或者shift+F12查字符串,有可疑字符串U g3t 1T!。找到关键代码,如下:
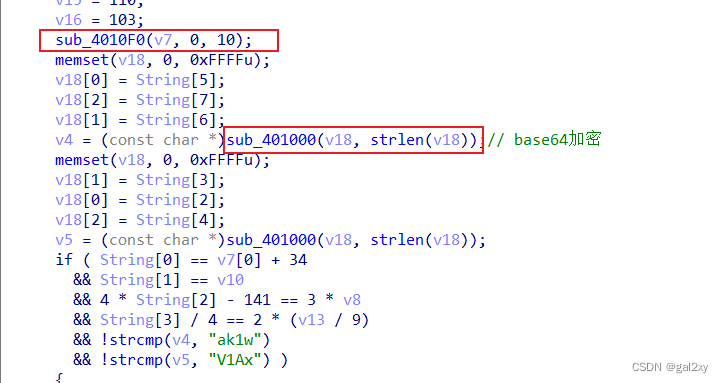
先看简单点的。进入sub_401000函数,简单查看一下,发现是每3个字符一组,不足3个仍为一组,而且byte_407830是base64对照表,那大概率就是base64加密了。
from base64 import b64decode
string = [0 for i in range(8)]
string567 = b64decode('ak1w')
string234 = b64decode('V1Ax')
print(string234+string567)
到这里,我们就解密出了第3~8个字符了,还差第1~2个字符。
再看这个sub_4010F0函数,分析了一下,里面有点复杂。但是我们可以将这个伪代码转成C语言代码,因为知道输入,运行一下就知道结果是什么了。
顺便说明一下,因为int为4字节,伪代码中a1+4*i就是v7[i],其余同理。因为传入的是数组的地址,但又int类型,所以强制转换一下就行了。
#include <stdio.h>
int sub_4010F0(int a1, int a2, int a3)
{
int result; // eax
int i; // esi
int v5; // ecx
int v6; // edx
result = a3;
for ( i = a2; i <= a3; a2 = i )
{
v5 = 4 * i;
v6 = *(int *)(4 * i + a1);
if ( a2 < result && i < result )
{
do
{
if ( v6 > *(int *)(a1 + 4 * result) )
{
if ( i >= result )
break;
++i;
*(int *)(v5 + a1) = *(int *)(a1 + 4 * result);
if ( i >= result )
break;
while ( *(int *)(a1 + 4 * i) <= v6 )
{
if ( ++i >= result )
goto LABEL_13;
}
if ( i >= result )
break;
v5 = 4 * i;
*(int *)(a1 + 4 * result) = *(int *)(4 * i + a1);
}
--result;
}
while ( i < result );
}
LABEL_13:
*(int *)(a1 + 4 * result) = v6;
sub_4010F0(a1, a2, i - 1);
result = a3;
++i;
}
return result;
}
int main(){
int a1[11] = {90, 74, 83, 69, 67, 97, 78, 72, 51, 110, 103};
sub_4010F0((int)a1,0,10);
for(int i=0;i<11;i++){
printf("%c",a1[i]);
}
}
#3CEHJNSZagn
根据String[0] == v7[0] + 34 && String[1] == v10,就可以解出相应的字符了。
简单注册器
apk文件,初始尝试使用的是APKIDE,反编译出的是smali语言。
Smali是Android虚拟机的反汇编语言。
我们都知道,Android代码一般是用java编写的,执行java程序一般需要用到java虚拟机,在Android平台上也不例外,但是出于性能上的考虑,并没有使用标准的JVM,而是使用专门的Android虚拟机(5.0以下为Dalvik,5.0以上为ART)。Android虚拟机的可执行文件并不是普通的class文件,而是再重新整合打包后生成的dex文件。dex文件反编译之后就是Smali代码,所以说,Smali语言是Android虚拟机的反汇编语言。
使用JEB打开apk文件,tab键反编译出java代码。
发现MainActivity类是关键代码,解密过程比较容易。
[ACTF新生赛2020]easyre
Exeinfo PE查壳发现是upx壳。
findit
apk文件APKIDE反编译,smali语言,使用JEB。
[ACTF新生赛2020]rome
关键代码如下:

伪代码看起来很复杂,其实就是对v1的每个字节进行加密.
如果是大写字母,则
v
1
i
′
=
(
v
1
i
−
51
)
%
26
+
65
v1_i' = (v1_i-51) \% 26 + 65
v1i′=(v1i−51)%26+65
如果是小写字母,则
v
1
i
′
=
(
v
1
i
−
79
)
%
26
+
97
v1_i' = (v1_i-79) \% 26 + 97
v1i′=(v1i−79)%26+97
如何求原来的
v
1
i
v1_i
v1i呢?
先将公式逆一下
{
(
v
1
i
′
−
65
+
51
)
≡
v
1
i
m
o
d
26
(
v
1
i
′
−
97
+
79
)
≡
v
1
i
m
o
d
26
\begin{cases} (v1_i'-65 + 51) ≡ v1_i\mod 26\\ (v1_i'-97 + 79) ≡ v1_i\mod 26 \end{cases}
{(v1i′−65+51)≡v1imod26(v1i′−97+79)≡v1imod26
然而这并不能求出
v
1
i
v1_i
v1i (无法确定
v
1
i
+
26
∗
k
v1_i+26*k
v1i+26∗k中的
k
k
k),但是我们可以改成求其对 a 或 A 的偏移量。
{
(
v
1
i
′
−
65
+
51
)
−
65
≡
(
v
1
i
−
65
)
≡
t
1
m
o
d
26
(
v
1
i
′
−
97
+
79
)
−
97
≡
(
v
1
i
−
97
)
≡
t
2
m
o
d
26
\begin{cases} (v1_i' - 65 + 51) - 65 ≡ (v1_i - 65) ≡ t1\mod 26\\ (v1_i' - 97 + 79) - 97 ≡ (v1_i - 97) ≡ t2\mod 26 \end{cases}
{(v1i′−65+51)−65≡(v1i−65)≡t1mod26(v1i′−97+79)−97≡(v1i−97)≡t2mod26
通过求出
t
1
t1
t1、
t
2
t2
t2,可以间接求出
v
1
i
v1_i
v1i。因为
t
1
t1
t1、
t
2
t2
t2 必定是小于26,求出来的值是准确的,这样一来也就确定了唯一的
v
1
i
v1_i
v1i。
v12 = 'Qsw3sj_lz4_Ujw@l'
flag = ''
for alp in v12:
if 65 <= ord(alp) <= 90:
flag += chr(((ord(alp) - 65) + 51 - 65) % 26 + 65)
elif 97 <= ord(alp) <= 122:
flag += chr(((ord(alp) - 97) + 79 - 97) % 26 + 97)
else:
flag += alp
print(flag)
[FlareOn4]login
正则表达式选取的是大小写字母,对它们进行加密
(c <= "Z" ? 90 : 122) >= (c = c.charCodeAt(0) + 13) ? c : c - 26
解密如下
from string import ascii_letters
print(ascii_letters)
enc = "PyvragFvqrYbtvafNerRnfl@syner-ba.pbz"
flag = ''
for alp in enc:
c = alp
if c in ascii_letters:
if ord(c) < ord("Z"):
a1 = 90
else:
a1 = 122
c = ord(c) + 13
if a1 >= c:
flag += chr(c)
else:
flag += chr(c - 26)
else:
flag += c
print(flag)
CrackRTF
常规操作,shfit+F12搜索字符,可疑字符串 pls input the first passwd(2):,跟进去,ctrl+x查找引用,再次跟进去,F5反汇编,找到了关键代码。
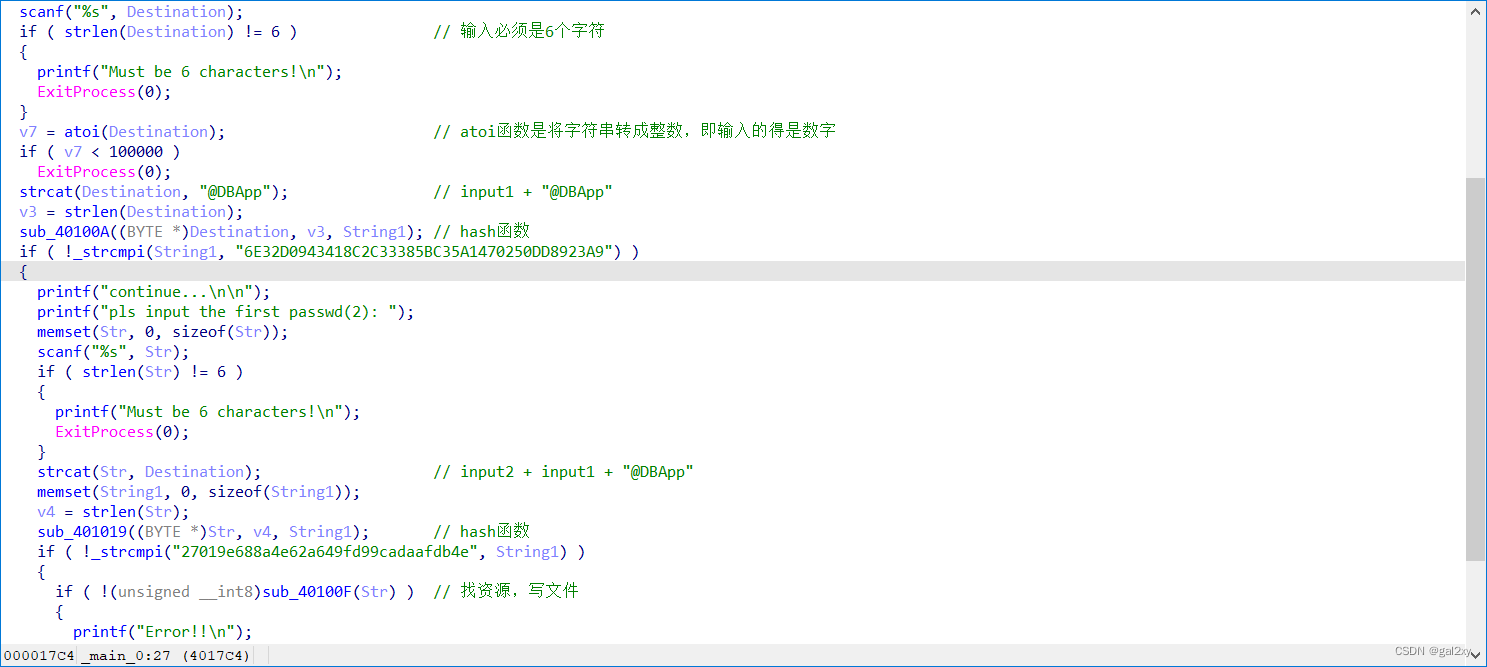
分析代码容易知道,我们需要先输入6个数字(暂且称它为input1)且要大于100000,然后与"@DBApp"连接(称为str1),利用str1生成哈希摘要,与已知哈希值对比,成功则进入第二步。仍然输入6个字符(称为input2),与str1连接(称为str2),同样哈希,然后对比。
在这两个哈希函数中,调用的都是系统API,计算哈希值的方法由CryptCreateHash函数中的第二个参数决定。
cryptCreateHash 函数 (wincrypt.h) - Win32 apps | Microsoft Learn
CryptCreateHash:第二个参数标识要使用的哈希算法的 ALG_ID 值。
ALG_ID 值:
CALG_SHA 0x00008004 SHA 哈希算法。 Microsoft 基础加密提供程序支持此算法。
CALG_SHA1 0x00008004 与 CALG_SHA相同。 Microsoft 基础加密提供程序支持此算法。
CALG_MD5 0x00008003 MD5 哈希算法。 Microsoft 基础加密提供程序支持此算法。
这样一来,就知道了计算哈希值时使用的哈希算法了。
第一部分:
import hashlib
def hashstring(partstr, hashstr):
for i in range(100000, 999999):
maystr = str(i) + partstr
mayhash = hashlib.sha1(maystr.encode()).hexdigest().upper()
if mayhash == hashstr:
return maystr
endpart = '@DBApp'
shahash = '6E32D0943418C2C33385BC35A1470250DD8923A9'
md5hash = '27019e688a4e62a649fd99cadaafdb4e'
str1 = hashstring(endpart, shahash)
print(str1)
#123321@DBApp
由于第一部分有输入限制条件,可以很轻松的爆破出来。但是很明显,第二部分如果爆破的话,时间是非常长的,所以需要另寻其他方法。
跟进到sub_40100F中,大都是API,百度一下就知道大概怎么回事了。
经分析发现,sub_401005的功能是两个字符串异或。sub_40100F整个功能就是寻找字符串,与str异或后,再写入dbapp.rtf文件中。
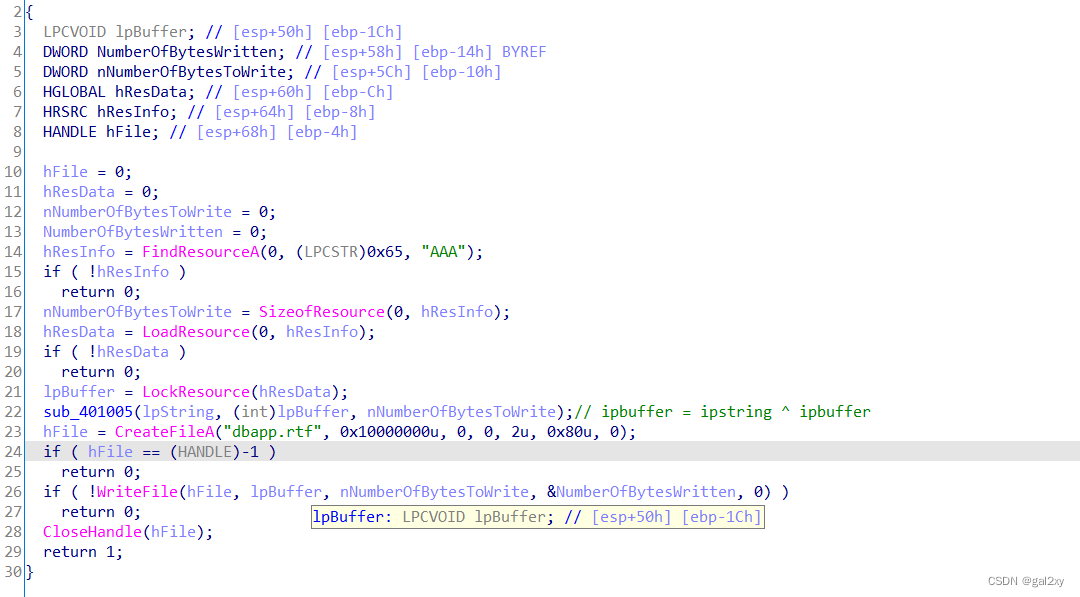
假设我们能够找到"AAA"类型资源和"dbapp.rtf"中的数据,那么两者异或不就是我们要找的str了?!
-
寻找"AAA"类型资源中的数据
既然是资源,那么就可以通过PE分析工具查找资源表,名为AAA的就是。
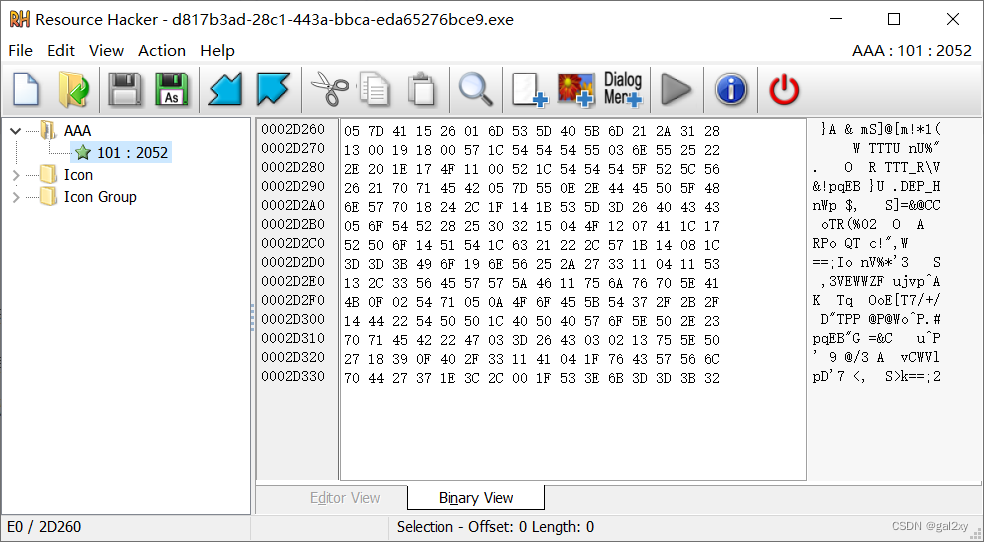
这些二进制数都是,但只要前六个字节就行了。
-
寻找"dbapp.rtf"中的数据
这个寻找不了,因为都没生成这种文件。自己尝试建了一个rtf文件,不写东西的话,拿到winhex中,啥也没有。但是写了数据之后,本以为会像txt文件那样,开头直接就是所写的内容,然而并不是,而是文件头:7B 5C 72 74 66(而且后面的数据写不是写入的数据)这里我存有疑惑。

两个数据都有了,就可以求出str2了。
AAA = [0x05, 0x7D, 0x41, 0x15, 0x26, 0x01]
rtf = [0x7B, 0x5C, 0x72, 0x74, 0x66, 0x31]
for i in range(len(AAA)):
c = chr(AAA[i] ^ rtf[i])
print(c, end='')
#~!3a@0
运行程序,把两次得到的字符串输入,就得到了dbapp.rtf文件,里面就是flag。
其实这个异或是有问题的。我们来仔细分析一下,先是lpString和lpBuffer异或,得到的数据写入dbapp.rtf文件中,但是我们这里取得数据是文件头啊!!!这样异或怎么会正确呢?按道理我们应该拿文件中得数据跟”AAA“资源中的数据异或才是我们第二次真正要输入的数据啊!
手动打开rtf文件再写入数据和用代码创建rtf文件并写入数据,其二进制数据完全不同。
- 手动打开rtf文件再写入数据,会带有rtf文件头。
- 用代码创建rtf文件并写入数据,其二进制数据就是写入的数据!!!
但这还是无法解释,即便是用代码创建rtf文件并写入数据这种情况,你怎么能肯定文件头就是写入的数据!!!
而且我还注意到运行createRTF.exe后得到的dbapp.rtf文件,其二进制数据符合第一种情况,也就是说,文件头不是写入的数据!!!
[GUET-CTF2019]re
毫无技术,注意a1[16]和a1[17]颠倒了顺序,且a1[6]未知,最终只能爆破flag!
[2019红帽杯]easyRE
基本操作,找到关键代码,如图:
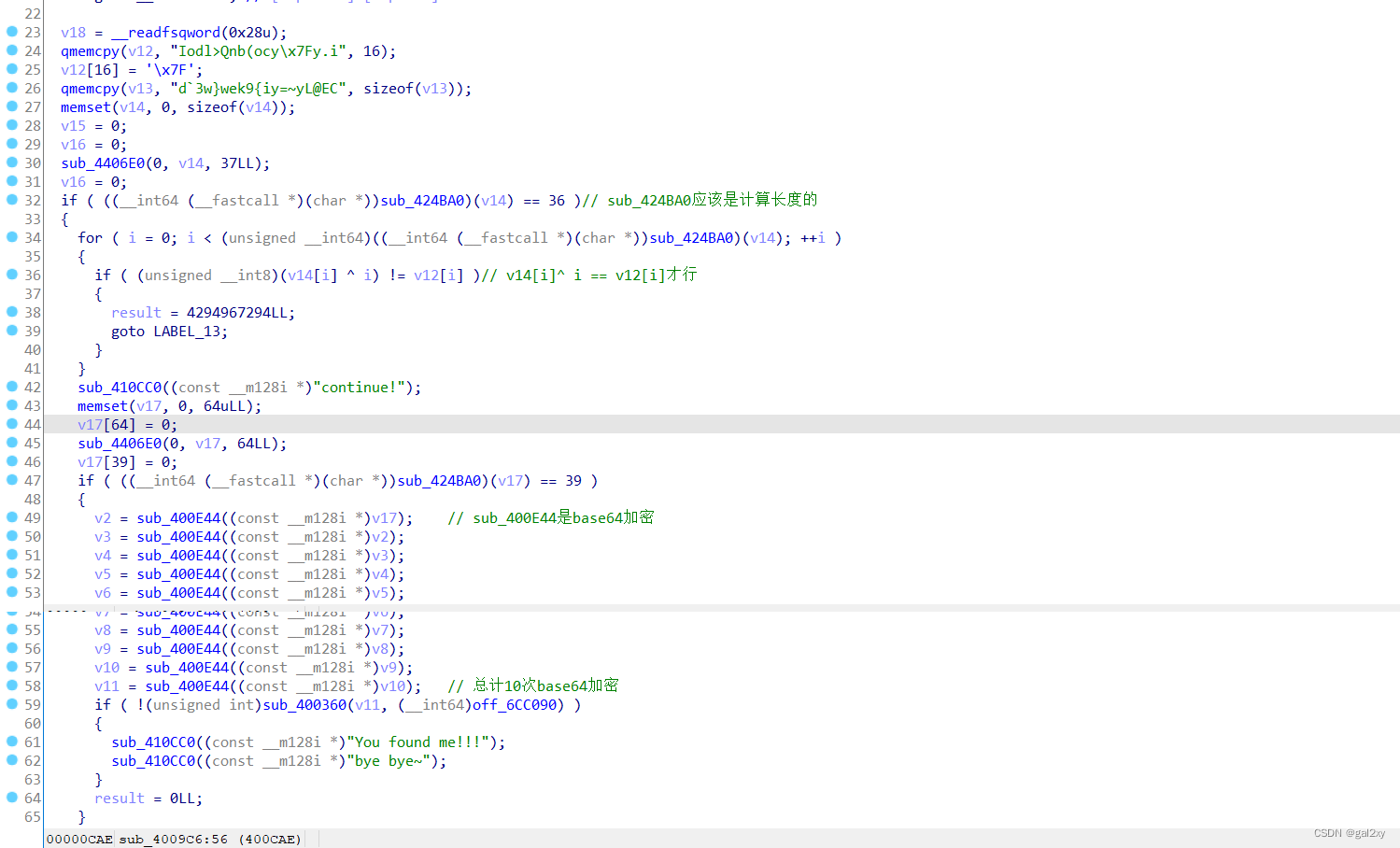
注意到sub_424BA0(v14) == 36,而且下面的for循环用到了这个,故猜测这个应该是计算长度的函数。下面的for循环是异或,解密如下:
v12 = 'Iodl>Qnb(ocy\x7Fy.i' + '\x7F' + 'd`3w}wek9{iy=~yL@EC'
print(len(v12))
v14 = ''
for i in range(len(v12)):
v14 += chr(ord(v12[i]) ^ i)
print(v14)
#Info:The first four chars are `flag`
是个提示信息。
继续往下走,是一个进行9次base64加密的代码,解密出来是个网站,对求解题目无用。
import base64
encbase64 = 'Vm0wd2VHUXhTWGhpUm1SWVYwZDRWVll3Wkc5WFJsbDNXa1pPVlUxV2NIcFhhMk0xVmpKS1NHVkdXbFpOYmtKVVZtcEtTMUl5VGtsaVJtUk9ZV3hhZVZadGVHdFRNVTVYVW01T2FGSnRVbGhhVjNoaFZWWmtWMXBFVWxSTmJFcElWbTAxVDJGV1NuTlhia0pXWWxob1dGUnJXbXRXTVZaeVdrWm9hVlpyV1hwV1IzaGhXVmRHVjFOdVVsWmlhMHBZV1ZSR1lWZEdVbFZTYlhSWFRWWndNRlZ0TVc5VWJGcFZWbXR3VjJKSFVYZFdha1pXWlZaT2NtRkhhRk5pVjJoWVYxZDBhMVV3TlhOalJscFlZbGhTY1ZsclduZGxiR1J5VmxSR1ZXSlZjRWhaTUZKaFZqSktWVkZZYUZkV1JWcFlWV3BHYTFkWFRrZFRiV3hvVFVoQ1dsWXhaRFJpTWtsM1RVaG9hbEpYYUhOVmJUVkRZekZhY1ZKcmRGTk5Wa3A2VjJ0U1ExWlhTbFpqUldoYVRVWndkbFpxUmtwbGJVWklZVVprYUdFeGNHOVhXSEJIWkRGS2RGSnJhR2hTYXpWdlZGVm9RMlJzV25STldHUlZUVlpXTlZadE5VOVdiVXBJVld4c1dtSllUWGhXTUZwell6RmFkRkpzVWxOaVNFSktWa1phVTFFeFduUlRhMlJxVWxad1YxWnRlRXRXTVZaSFVsUnNVVlZVTURrPQ=='
for i in range(10):
encbase64 = base64.b64decode(encbase64)
print(encbase64)
b'https://bbs.pediy.com/thread-254172.htm'
整段代码分析完了,但是并没有flag。只能根据提示信息找了!
查看他人博客才知道的。查看那一大串Base64编码的引用,跟进,在下面发现其他数据被sub_400D35引用。
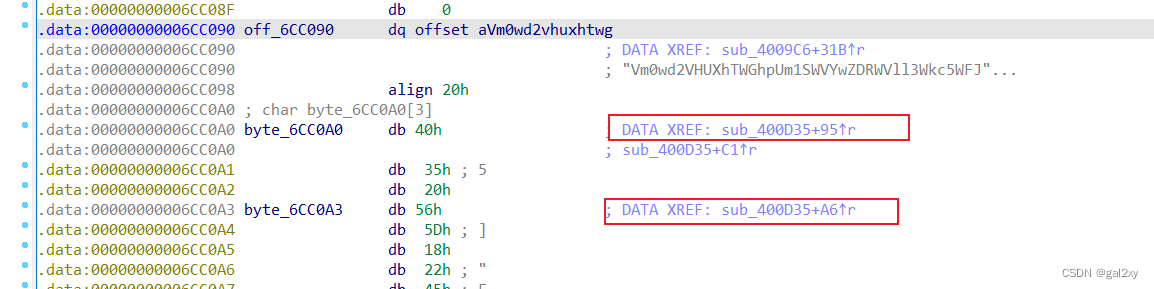
跟进这个函数

if语句中有’f’和’g’,而且byte_6CC0A0和byte_6CC0A3之间真好差2个字符,猜测很有可能是flag。
根据异或代码,发现v4是进行循环异或的,所以可以通过’flag’字符解出v4,然后反解出flag。
enc = '@5 V]\x18"E\x17/$nb<\x27THl$nr<2E['
print(len(enc))
dec = 'flag'
key = []
for i in range(len(dec)):
key.append(ord(enc[i]) ^ ord(dec[i]))
print(f'key={key}')
flag = ''
for i in range(len(enc)):
flag += chr(ord(enc[i]) ^ key[i % 4])
print(flag)
[MRCTF2020]Transform
简单,不记录详细步骤。
[SUCTF2019]SignIn
一眼RSA加密,简单,不记录详细步骤。
[ACTF新生赛2020]usualCrypt
常规操作,找到关键代码。
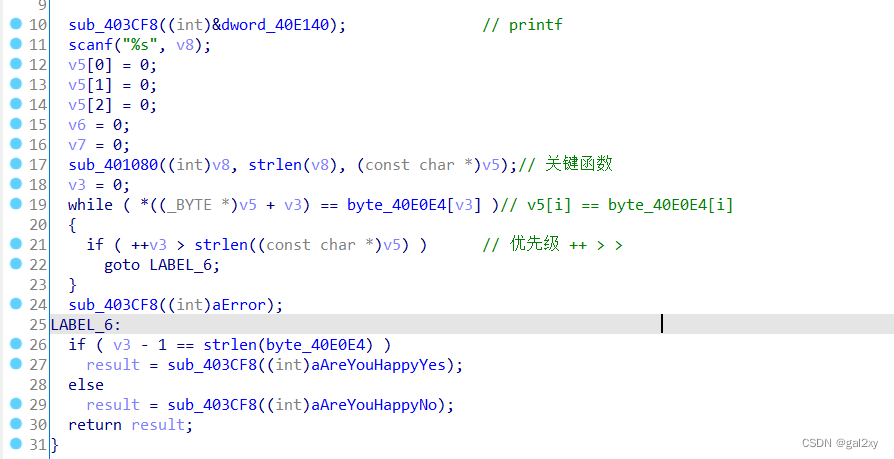
跟进sub_401080。

注意最后的返回函数sub_401030。跟进去查看,发现是大小写转换。
整体代码如下
import base64
import string
v5 = 'zMXHz3TIgnxLxJhFAdtZn2fFk3lYCrtPC2l9'
enc = ''
for i in range(len(v5)):
if v5[i].isupper():
enc += v5[i].lower()
elif v5[i].islower():
enc += v5[i].upper()
else:
enc += v5[i]
print(f'逆大小写转换后的密文:{enc}')
table1 = 'KLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' #byte_40E0AA
table2 = 'ABCDEFGHIJ' #byte_40E0A0
table1 = list(table1)
table2 = list(table2)
'''# 错误做法
table1 = 'KLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' #byte_40E0AA
table2 = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' #byte_40E0A0
for i in range(6, 15):
table1[i], table2[i] = table2[i], table1[i]
'''
# 有一部分共用内存,需要同时更新
for i in range(6, 15):
if i < len(table2):# 数组下标未越界时
table1[i], table2[i] = table2[i], table1[i]
else:# 数组下标越界时
table1[i], table1[i-len(table2)] = table1[i-len(table2)], table1[i]
tableNew = ''.join(table2 + table1) #因为数组越界的原因,需要拼接两个字符串
tableBase64 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
print(f'base64表为:{tableNew}')
# 换表
maketrans = str.maketrans(tableNew, tableBase64)
# 转换成字符
translate = enc.translate(maketrans)
print(f'变表之后对应的密文:{translate}')
flag = base64.b64decode(translate)
print(f'明文:{flag}')
[HDCTF2019]Maze
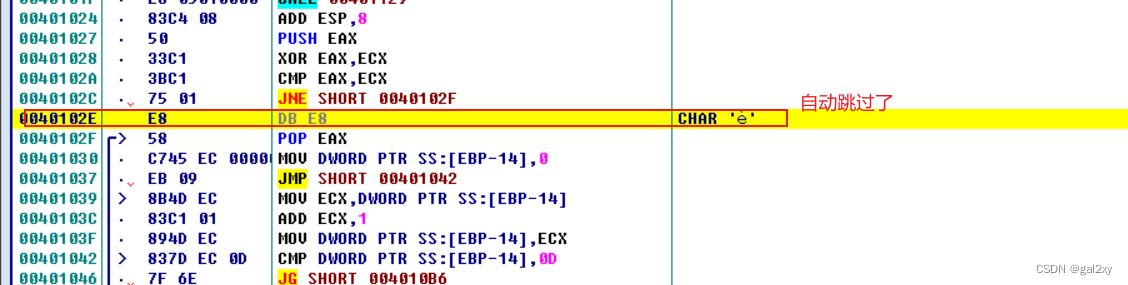
一般用IDA打开某可执行文件,IDA-view界面最终会出现一堆框框(里面含汇编)。但这题不同,打开后并没有出现上述情况,而是直接停在_main入口,且出现标红的地方。
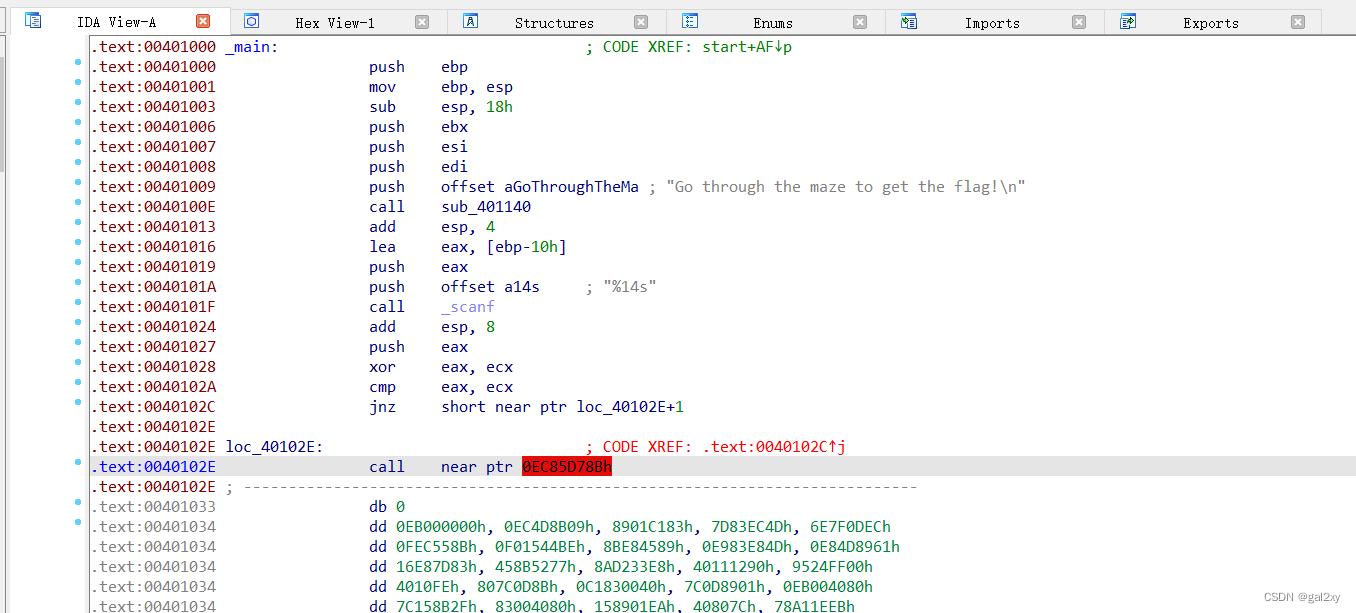
我们来简单分析一下。jnz这个跳转指令,跳转地址居然不是指令的起始位置,而是在中间。
这个就涉及到花指令。
我们只需要把call这条指令转成数据(按D键),然后略过E8,将下方的数据转成代码(按C键)。然后按P键转成函数,F5反汇编。得到如下代码
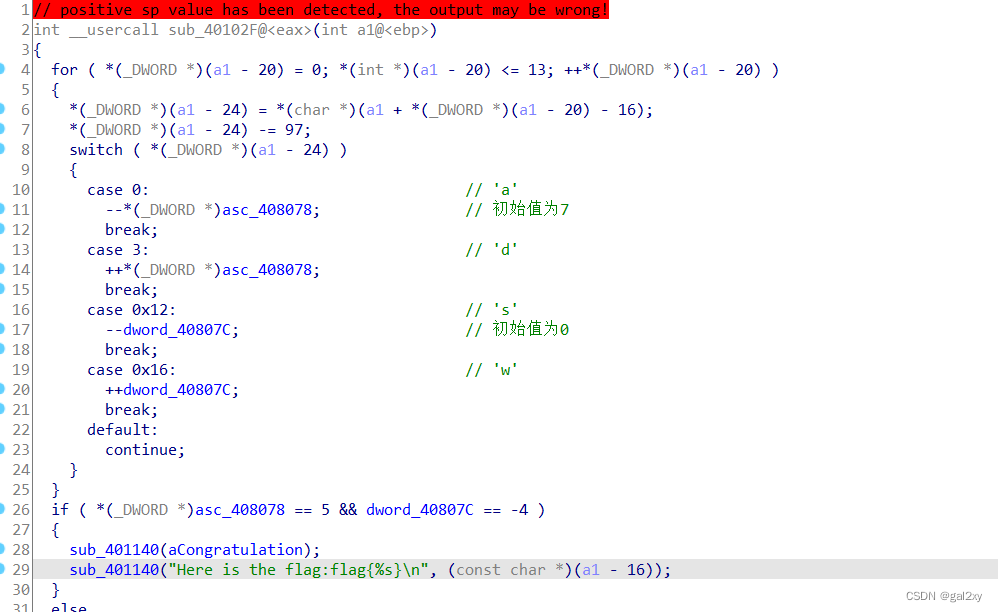
结合题目和代码中的’asdw’可以知道,是道走迷宫的题目。shift+F12找迷宫路径。
*******+********* ****** **** ******* **F****** **************
总计70个字符,所以要么是7×10或者10×7的矩阵。尝试后发现是10×7。
*******+**
******* **
**** **
** *****
** **F****
** ****
**********
故路径为
ssaaasaassdddw
花指令
加壳原理笔记07:花指令入门 - 『脱壳破解区』 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|www.52pojie.cn
花指令总结-安全客 - 安全资讯平台 (anquanke.com)
OD与IDA在处理花指令方面的不同之处。
就拿这个例子进行说明。在OD中,似乎使用的是递归下降反汇编,如图所示:
在IDA中,似乎使用的递归算法是线性扫描反汇编?
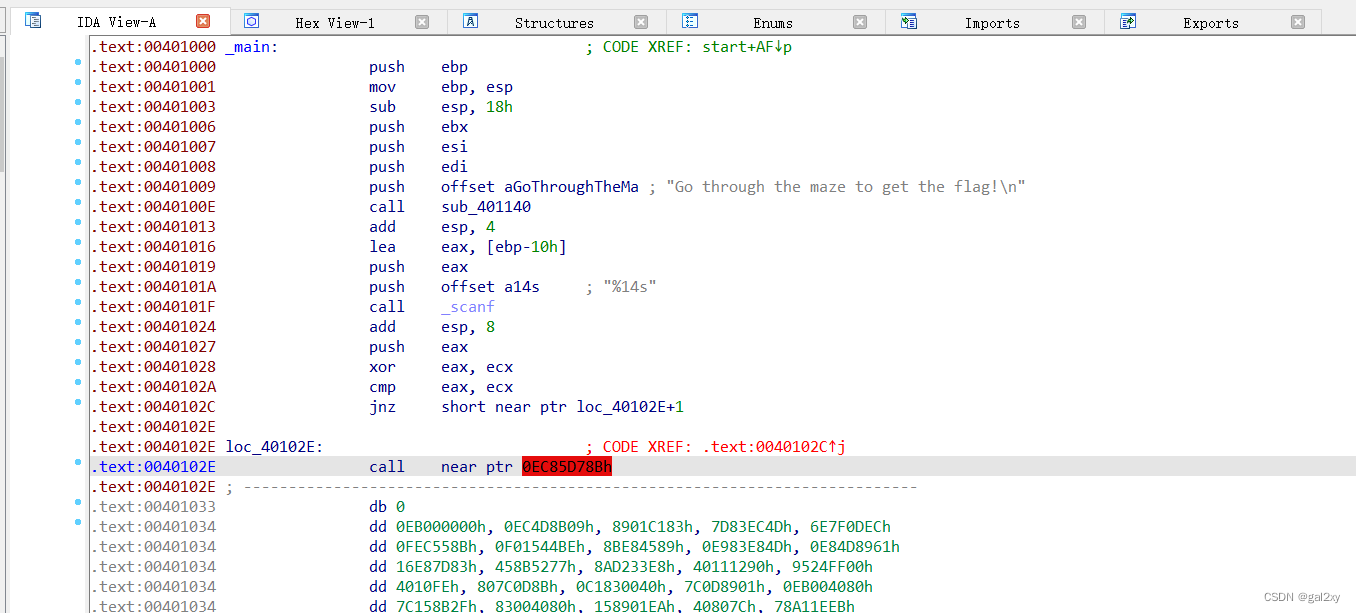
(猜测IDA是静态分析的缘故造成的)
[MRCTF2020]Xor
方法一
OD动态分析。右键查找所有被引用的字符串,找到可疑字符,进入对应汇编代码。
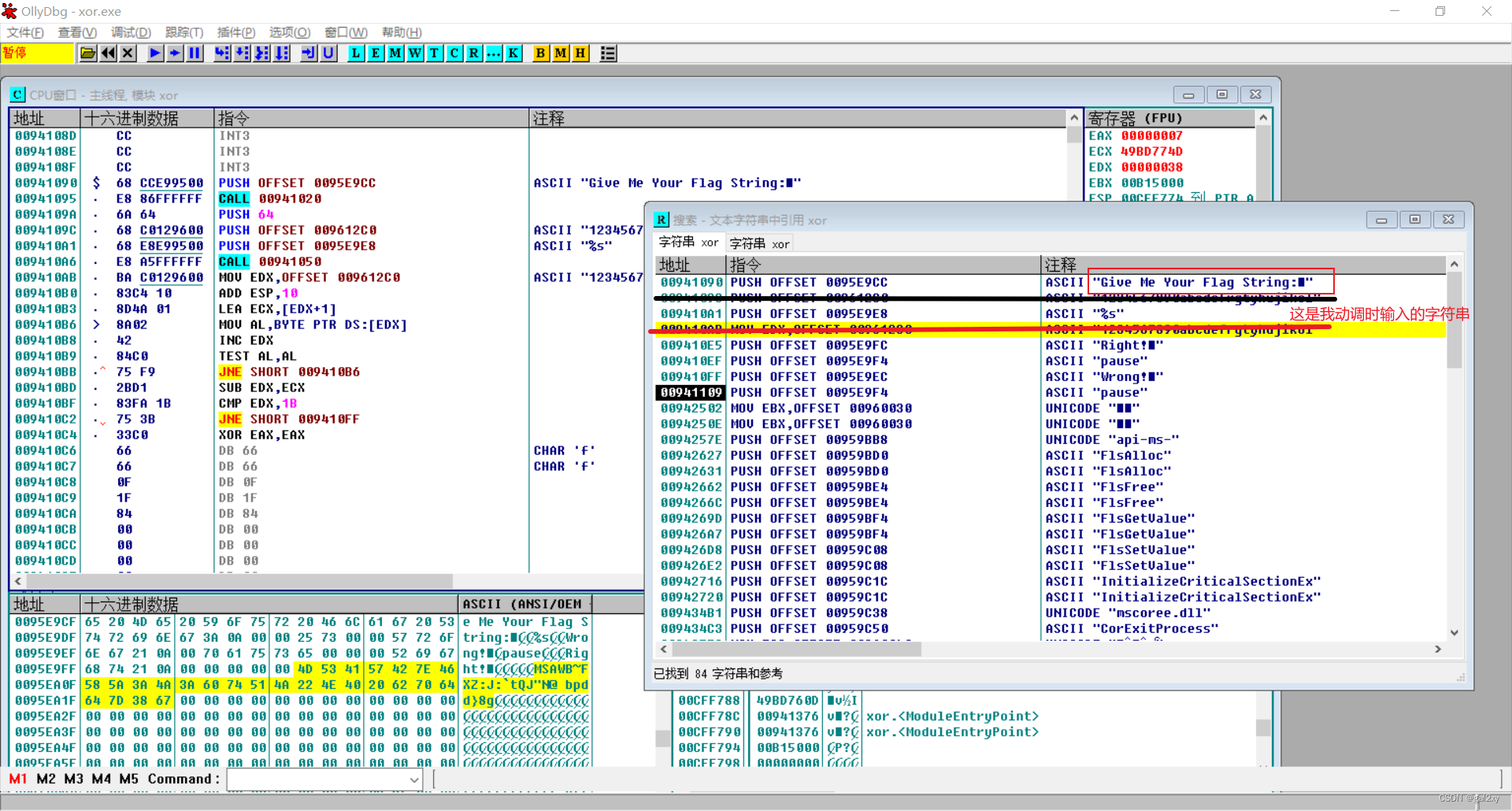
在图中0x9410BF位置下断点,这一块估计是判断长度的,长度不是27就跳到"wrong"那一块。动调之后发现是对的。
继续向下分析

这一块就是异或加密了(图是我动调后的结果)。容易看出是将输入的字符串循环跟AL(初始值为0,可在寄存器中查看)异或,每一次异或后,AL++。最终和“MSAWB……”那一串字符作比较。所以解密代码如下:
c = '4D 53 41 57 42 7E 46 58 5A 3A 4A 3A 60 74 51 4A 22 4E 40 20 62 70 64 64 7D 38 67'.split(' ')
flag = ''
for i in range(len(c)):
flag += chr(i ^ int(c[i], 16))
print(flag)
方法二
使用IDA静态分析。F5反汇编失败,报call analysis failed错误。
Decompilation failure:
-
call analysis failed
IDA不能F5查看伪代码的解决方法(call analysis failed) | Xhy’s Blog (xhyeax.com)
IDA F5 在 CTF逆向中的坑 - SecPulse.COM | 安全脉搏
-
IDA无法识别出正确的调用约定(calling convention)
-
IDA无法识别出正确的参数个数。
解决方法:①定位报错的代码位置,鼠标点击调用函数,按y键,修改参数个数。
②定位报错的代码位置,鼠标点击调用函数,进入函数,F5,再返回就可以F5了。
具体参数个数,需要根据函数调用约定及汇编代码确定(看它传入了几个参数)。
-
-
sp-analysis failed
堆栈不平衡
Options->General->勾选Stack pointer,可以查看到堆栈状态,一般是retn处不为0,通过最近的call修正堆栈(快捷键Alt+K)。
不过这是一种强行修正的方法,可能会影响其他函数。应从上往下分析每个call,看是否堆栈平衡。
[推荐]IDA sp-analysis failed 不能F5的 解决方案之(二)-软件逆向-看雪论坛-安全社区|安全招聘|bbs.pediy.com (kanxue.com)
所以这道题按照对应的类型操作一波就可以了。
Youngter-drive
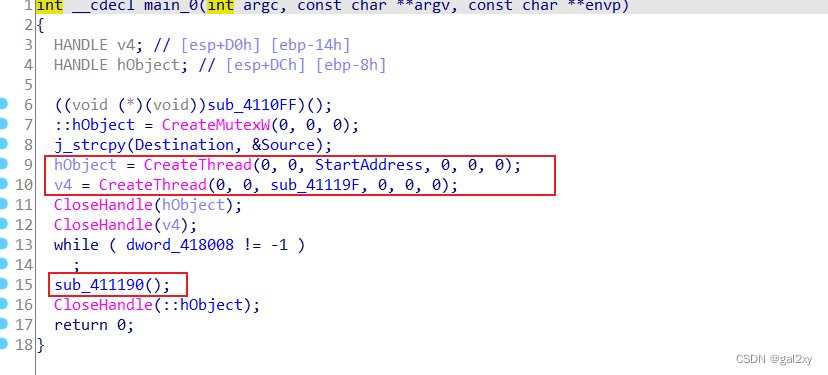
注意CreateThreadAPI函数会绑定线程处理函数(详见CreateThread 函数 (processthreadsapi.h) - Win32 apps | Microsoft Learn),所以需要跟进这些函数查看。
跟进线程处理函数StartAddress,线程处理函数如下
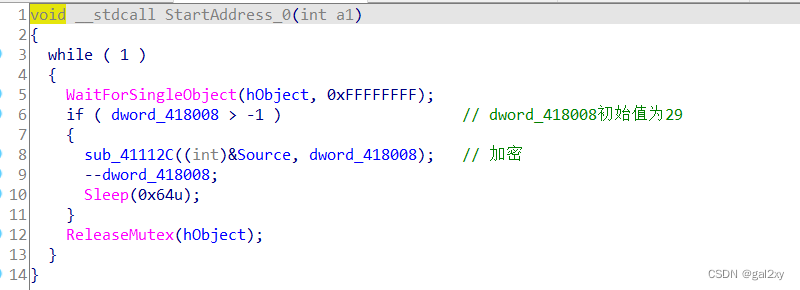
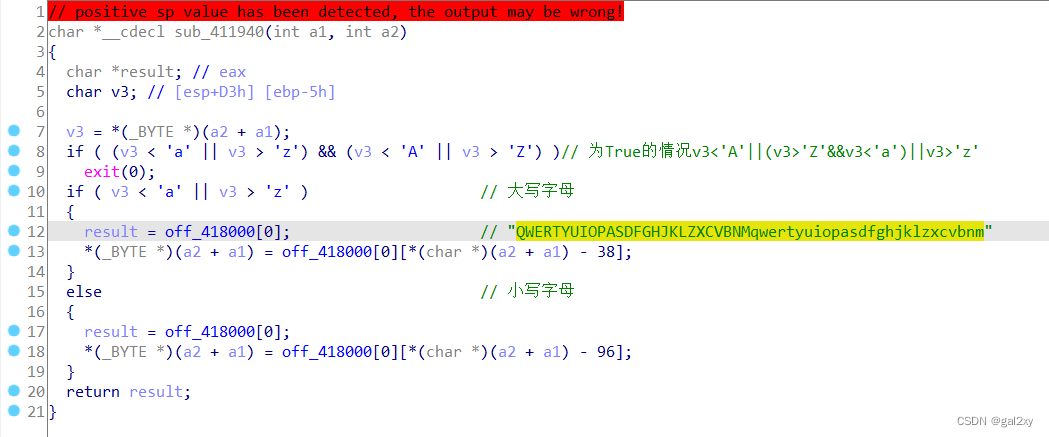
上图说明是从后往前进行加密。加密函数sub_41112C如下。加密过程为:大写字母-38作为下标索引,从off_418000中找字符;小写字母类似。大写字母 - 38 >= 27,所以加密后是小写字母,而小写字母 - 96 >= 1,所以加密后是大写字母。
再跟进另一个线程处理函数sub_4119F,如下
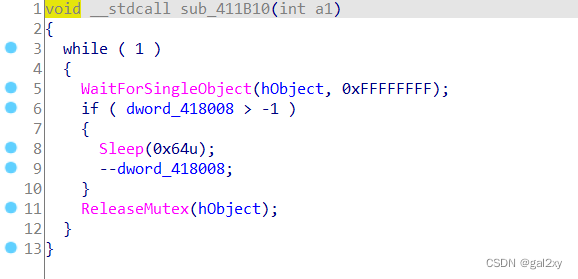
仅仅只做了dword_418008自减。但是线程处理函数StartAddress中,也进行了自减,这就意味着整个加密过程是交替进行的。
最后还剩sub_411190函数了,其实就是字符串比较。
因为不知道是哪个进程先执行,尝试发现是偶数位。所以代码如下
key = 'QWERTYUIOPASDFGHJKLZXCVBNMqwertyuiopasdfghjklzxcvbnm'
c = 'TOiZiZtOrYaToUwPnToBsOaOapsyS'
clen = len(c)-1
flag = ''
while clen >= 0:
if clen % 2 == 0:
flag += c[clen]
else:
pos = key.index(c[clen])
if c[clen].isupper()://如果是大写字母,就要变成小写字母
flag += chr(96+pos)
else://如果是小写字母,就要变成大写字母
flag += chr(38+pos)
clen -= 1
print(flag[::-1])















 201
201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









