







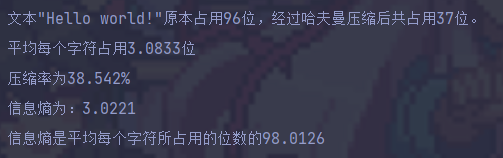
执行效果

代码
package com.huffman.spd.www;
import java.io.*;
import java.util.*;
public class Huffman {
private final Map<Character, List<Boolean>> encodeMap;
private final Map<List<Boolean>, Character> decodeMap;
private final String fileName;
private final List<Boolean> res;
private static class TreeNode {
char ch;
int weigh;
TreeNode left;
TreeNode right;
public TreeNode(TreeNode left, TreeNode right) {
weigh = left.weigh + right.weigh;
this.left = left;
this.right = right;
}
public TreeNode(Map.Entry<Character, Integer> entry) {
ch = entry.getKey();
weigh = entry.getValue();
}
public TreeNode() {
}
public boolean isAvailableLeaf() {
return ch != '\0' && left == null && right == null;
}
public int getWeigh() {
return weigh;
}
}
public Huffman(String path) {
String[] wholeName = path.split("\\.");
fileName = wholeName[0];
if (!wholeName[1].equals("txt")) {
throw new IllegalArgumentException("錯誤的文件格式!請選擇其他文件或修改文件後綴。");
}
String str = readString(path);
Map<Character, Integer> map = new HashMap<>();
for (char ch : str.toCharArray()) {
map.put(ch, map.containsKey(ch) ? map.get(ch) + 1 : 1);
}
Queue<TreeNode> pQueue = new PriorityQueue<>(Comparator.comparingInt(TreeNode::getWeigh));
double log2 = Math.log(2);
for (Map.Entry<Character, Integer> entry : map.entrySet()) {
pQueue.add(new TreeNode(entry));
}
TreeNode root = new TreeNode();
while (pQueue.size() > 1) {
root = new TreeNode(pQueue.poll(), pQueue.poll());
pQueue.offer(root);
}
encodeMap = new HashMap<>();
decodeMap = new HashMap<>();
res = new ArrayList<>();
setMaps(root);
}
private void setMaps(TreeNode root) {
if (root == null) return;
if (root.isAvailableLeaf()) {
List<Boolean> bits = new ArrayList<>(res);
encodeMap.put(root.ch, bits);
decodeMap.put(bits, root.ch);
return;
}
res.add(false);
setMaps(root.left);
res.remove(res.size() - 1);
res.add(true);
setMaps(root.right);
res.remove(res.size() - 1);
}
public int encode (String name) throws IOException {
List<Boolean> bits = new ArrayList<>();
String text = readString(name + ".txt");
for (char ch : text.toCharArray()) {
for (boolean b : encodeMap.get(ch)) {
bits.add(b);
}
}
Iterator<Boolean> itr = bits.listIterator();
byte[] arr = new byte[(bits.size() >>> 3) + ((bits.size() & 0b111) == 0 ? 0 : 1)];
int j = 0;
while (itr.hasNext()) {
byte b = 0;
for (int i = 0; i < 8; i++) {
b <<= 1;
if (itr.hasNext() && itr.next()) b++;
}
arr[j++] = b;
}
ByteArrayInputStream bais = new ByteArrayInputStream(arr);
FileOutputStream fos = new FileOutputStream(name + ".hfm");
int len = -1;
/* 緩衝區為16字節 */
byte[] buffer = new byte[0x10];
while ((len = bais.read(buffer)) != -1) {
fos.write(buffer, 0, len);
}
fos.flush();
return bits.size();
}
public String decode (String name, int length) throws IOException {
FileInputStream fis = new FileInputStream(name + ".hfm");
List<Boolean> bits = new ArrayList<>();
int len = -1;
byte[] buffer = new byte[0x10];
while((len = fis.read(buffer))!=-1) {
for (int i = 0; i < len; i++) {
for (byte j = -128; j != 0 && length > 0; j = (byte) ((j > 0 ? j : -j) >> 1), length--) {
bits.add((buffer[i] & j) != 0);
}
}
if (length < 0) break;
}
StringBuilder sb = new StringBuilder();
List<Boolean> flush = new ArrayList<>();
for (boolean b : bits) {
flush.add(b);
Character ch = decodeMap.get(flush);
if (ch != null) {
sb.append(ch);
flush.clear();
}
}
writeString(fileName + ".txt", sb.toString());
return sb.toString();
}
public int encode() throws IOException {
return encode(fileName);
}
public String decode(int length) throws IOException {
return decode(fileName, length);
}
private static String readString(String path) {
StringBuilder sb = new StringBuilder();
String str;
try(BufferedReader br =
new BufferedReader(
new InputStreamReader(
new FileInputStream(path)))) {
boolean flag = false;
while ((str = br.readLine()) != null) {
if (flag) {
sb.append('\n');
}
flag = true;
sb.append(str);
}
} catch (IOException e) {
System.err.println("文件讀取異常");
}
return sb.toString();
}
private static void writeString(String path, String str) {
try(BufferedWriter bw =
new BufferedWriter(
new OutputStreamWriter(
new FileOutputStream(path)))) {
bw.write(str);
bw.flush();
} catch (IOException e) {
System.err.println("文件写入异常");
}
}
private static StringBuilder bitsString(List<Boolean> bits) {
StringBuilder sb = new StringBuilder();
for (boolean b : bits) {
sb.append(b ? '1' : '0');
}
return sb;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(fileName).append('\n');
for (Map.Entry<Character, List<Boolean>> entry : encodeMap.entrySet()) {
sb.append(entry.getKey()).append(" = ").append(bitsString(entry.getValue())).append('\n');
}
return sb.toString();
}
public static double infoEntropy(String str) {
Map<Character, Integer> map = new HashMap<>();
double entropy = 0;
for (char ch : str.toCharArray()) {
map.put(ch, map.containsKey(ch) ? map.get(ch) + 1 : 1);
}
double log2 = Math.log(2);
for (char ch : map.keySet()) {
double p = (double) map.get(ch) / (double) str.length();
entropy -= p * Math.log(p) / log2;
}
return entropy;
}
public static void main(String[] args) throws IOException {
Huffman huffman = new Huffman("text.txt");
int size = huffman.encode();
String str = huffman.decode(size);
int originSize = str.getBytes().length * 8;
double entropy = Huffman.infoEntropy(str);
System.out.println((str.length() > 0x20 ? "该文本" : "文本\"" + str + "\"")
+ "原本占用" + originSize + "位,经过哈夫曼压缩后共占用" + size + "位。");
System.out.printf("平均每个字符占用%.4f位\n", (double) size / (double) str.length());
System.out.printf("压缩率为%.3f", (double) size / (double) originSize * 100);
System.out.println("%");
System.out.printf("信息熵为:%.4f\n", entropy);
System.out.printf("信息熵是平均每个字符所占用的位数的%.4f", entropy / ((double) size / (double) str.length()) * 100);
}
}
优化方案
由于java中没有一一映射的数据结构,所以我只好采用两个映射的mao来实现映射。很明显这是很低小的。虽然查找出来很快,但却有大量的内存开销,这是不应该出现的。
所以我们应该像我这个源代码中自己构建一个二叉树那样自己构建一个一一映射的数据结构。
















 1710
1710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











