






爬虫基本原理
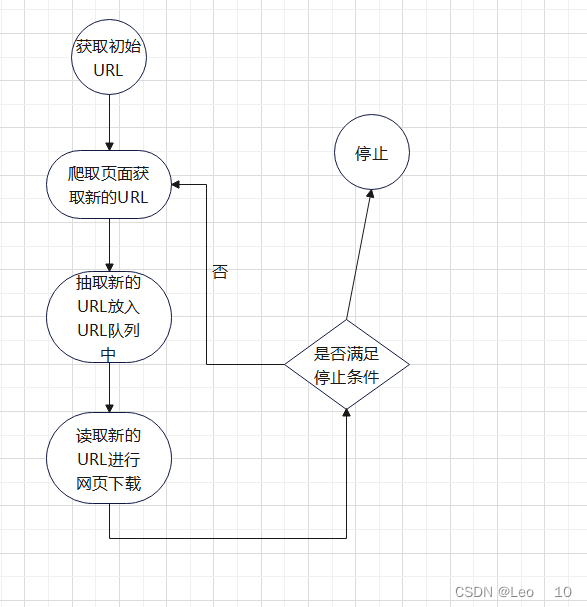
爬虫最重要的就是需要获取URL地址,以便于来爬取我们需要的网页数据
爬虫模块
| 模块名称 | 描述 |
| urllib.request | 定义了打开URL的方法与种类, |
| urllib.error | 主要包括异常类 |
| urllib.parse | URL解析和URL引用 |
| urllib.robotparser | 用于解析robots.txt文件 |
利用urllib.request发送请求并读取网页内容示例:
import urllib.request
response = urllib.request.urlopen('http://www.xxx.com')
html = response.read()
print(html)post获取网页内容
import urllib.parse
import urllib.request
把数据利用urlencode编码后,再使用encoding编码为utf-8
data = bytes(urllib.parse.urlencode({'word':'hello'}),encoding='utf-8')
response = urllib.request.urlopen('http://httpbin.org/post',data = data)
html = response.read()
print(html)















 2007
2007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











