







一、BS4
什么是bs4
Beautigul Soup 和Requests一样是第三方库,它可以从html或者xml文档中快速提取到指定的数据
需要通过 pip install bs4 去引入
正常使用requests返回text结果是网页的源代码,要去寻找想要获取的数据很繁琐
import requests
rq_heard = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
content = requests.get('https://blog.csdn.net/qq_52380395/article/details/138854024?spm=1001.2014.3001.5501',headers=rq_heard)
print(content.text)
如何使用bs4
1. 导入bs4
from bs4 import BeautifulSoup # 引入bs42.创建一个BeautifulSoup对象
bs4_test = BeautifulSoup(content.text,"html.parser")这里面有两个参数,一个是要解析的html文本,一个是参数要使用的解析器。
解析器有4种,分别是:html.parser、lxml、xml、html5lib
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(html,’html.parser’) | Python内置标准库;执行速度快 | 在python2.7.3和3.2.2之前的版本中文档容错能力差 |
| lxml html解析器 | (需要额外导入)BeautifulSoup(html,’lxml’) | 速度快;容错能力强 | 需要安装C语言库 |
| lxml XML解析器 | (需要额外导入)BeautifulSoup(html,[‘lxml’,’xml’])或BeautifulSoup(html,’xml’) | 唯一支持解析xml | 需要安装C语言库 |
| htm5lib | BeautifulSoup(html,’htm5llib’) | 以浏览器方式解析,最好的容错性,生成html5 | 速度慢 |
3.具体使用
bs4_test = BeautifulSoup(content.text,"html.parser")
print(bs4_test.p) # 会打印第一个标签元素
4. findAll( )方法
这是一个可以查找所有符合要求的标签的方法
例如 我想获取到豆瓣图书的Top250的书名。
import requests
from bs4 import BeautifulSoup # 引入bs4
rq_heard = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
content = requests.get('http://douban.com/doulist/152361157/',headers=rq_heard).text
bs4_test = BeautifulSoup(content,"html.parser")
print(bs4_test.a) # 会打印第一个标签元素
all_div = bs4_test.find_all("div",attrs={"class":"title"}) # 查找bs4_test下所有的div标签,另外可以传入一个可选参数,这个可选参数是指的是对应div标签的类名
for show in all_div:
print(show)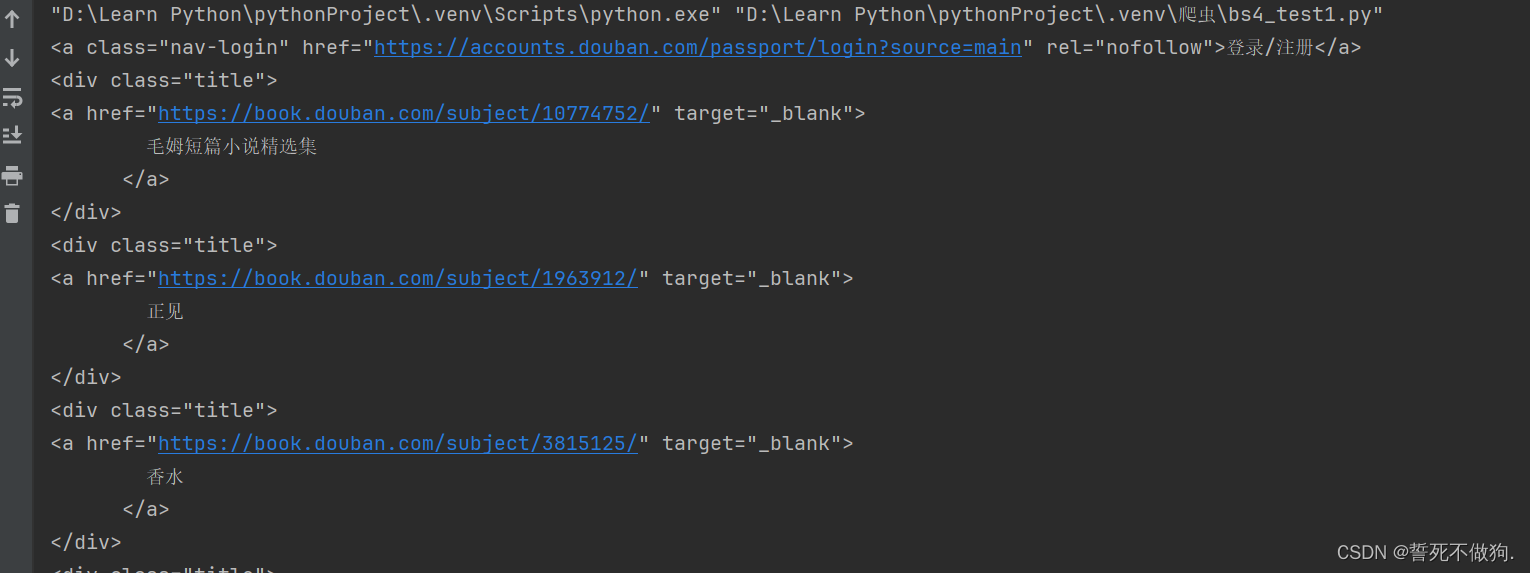
但是这样看依旧有点小复杂,可以再循环一次 只获取书名:
import requests
from bs4 import BeautifulSoup # 引入bs4
rq_heard = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
content = requests.get('http://douban.com/doulist/152361157/',headers=rq_heard).text
bs4_test = BeautifulSoup(content,"html.parser")
print(bs4_test.a) # 会打印第一个标签元素
all_div = bs4_test.find_all("div",attrs={"class":"title"}) # 查找bs4_test下所有的div标签,另外可以传入一个可选参数,这个可选参数是指的是对应div标签的类名
for show in all_div:
all_a = show.find_all("a")
for show_1 in all_a:
print(show_1.string)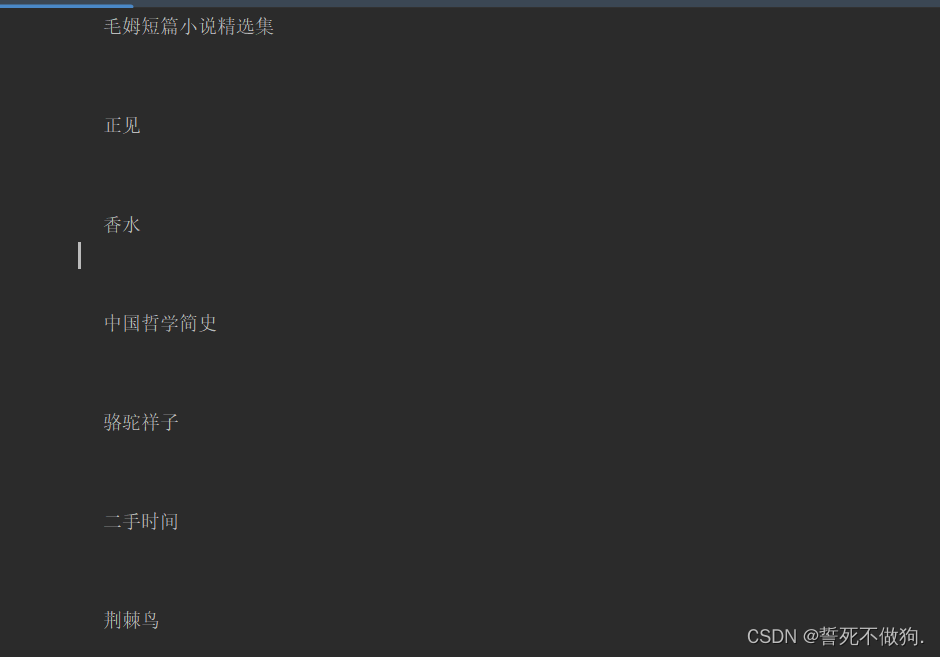
此时 已经找到第一页的所有书名 如何找到所有的书名呢?
通过for循环使用f字符串拼接需要插入的star数据
划重点 这是常用的几个字符串的具体方法:
笔记:
一、字符串前加r,f,b,u的含义
| 作用 | 如何使用 | |
| r | 去除所接字符串中转义字符的影响。 | str1 = r'test_r\n' |
| f | 表示在字符串内支持大括号内的python 表达式 | print(f'{name} done in {time.time() - t0:.2f} s') |
| b | 后面字符串是bytes 类型。 | response = b'<h1>Hello World!</h1>' |
| u | 后面字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出现乱码。 | u"我是含有中文字符组成的字符串。" |
为了方便看我是否顺利爬完250条数据,我再通过i去给每一个书名加个序号 具体代码如下:
import requests
from bs4 import BeautifulSoup # 引入bs4
rq_heard = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
i = 0
for page_num in range (0,250,25):
content = requests.get(f'http://douban.com/doulist/152361157/?start={page_num}', headers=rq_heard).text
bs4_test = BeautifulSoup(content, "html.parser")
print(bs4_test.a) # 会打印第一个标签元素
all_div = bs4_test.find_all("div",
attrs={"class": "title"}) # 查找bs4_test下所有的div标签,另外可以传入一个可选参数,这个可选参数是指的是对应div标签的类名
for show in all_div:
all_a = show.find_all("a")
for show_1 in all_a:
i += 1
print(i,show_1.string) # 通过string属性获取a标签里面的内容。
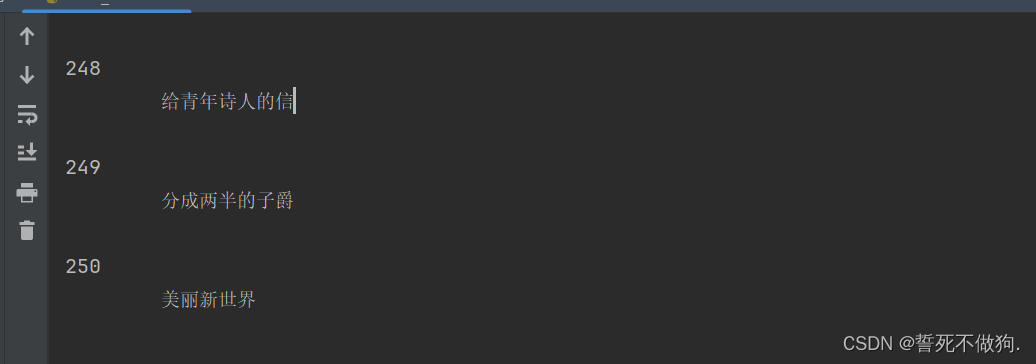
ok 爬取成功。这就是bs4的一个简单的使用方法
















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









