







图神经网络的相关知识
机器学习的分类
按有无标签分类
监督学习
监督学习指的是每个训练数据的样本都有标签,通过标签可以指导模型进行学习,学到具有判别性的特征,然后对未知样本进行预测。
翻译成人话:班里的人分为内卷人和摆烂人,有一个机器会自动观察内卷人的成绩和摆烂人的成绩,等观察的人够多了之后,他就可以根据成绩判断哪个是摆烂人哪个是内卷人,这样机器看到小废物rytter的成绩后就能判断出rytter是个摆烂人。
无监督学习
无监督学习是指训练的数据没有标签,通过算法来发现数据中的约束关系。
翻译成人话:某个机器观察了班里的成绩,根据成绩机器人就能自动将成绩分成两类,内卷人和摆烂人,小废物rytter自然就被分到了摆烂人一类。
半监督学习
半监督学习指的是介于监督学习和无监督学习之间的一种学习方式,他的训练集既包含标签数据,又包含无标签数据。无标签数据会包含数据分布的信息,可以作为标签数据之外的一些补充,因为人工去标记这些数据会有很大代价,而半监督学习可以提供一些解决思路。
翻译成人话:略了,小废物rytter开摆!
按算法输出分类
分类问题
输出一个离散值,比如可以读取一个肿瘤的大小,然后判断是否为恶性肿瘤,这种情况下只有是或者否两种情况,这类问题就叫做分类问题
回归问题
我们通过读取这个数据集,然后给出一个可以和这些值相拟合的一条线,然后可以通过这个函数进行一个预测。列如单变量线性回归方程。
机器学习流程的概述
举个例子
比如我们要给一些商品分类,我们需要建立一个模型,并使用商品的图片数据训练模型,得到有个可以对未知图片进行分类的预测模型。然后我们需要进行的步骤如下:
(1)提取商品图片的特征
首先我们需要找到图片的一些具有区分性的特征,我们可以人为规定特征,这个过程称为特征工程。其实我们还可以通过算法自动提取,这就是深度学习涉及的范围了。
(2)建立模型
选择一个合适的模型进行建模,其实建模就是一个复杂的函数 y = f ( X ; W ) y=f(X;W) y=f(X;W),W是模型的一些参数,是需要不断调整的,X就是前面的特征,通过特征X和训练所得的W得到一个y,就是我们需要的结果。
(3)确定损失函数和进行优化求解
建立模型后如何判断模型好不好用,为了解决这个问题我们提出了损失函数,利用损失函数来判断拟合性如何,基于损失函数的值我们可以通过优化方法进行调整,直到损失函数的值达到我们可接受范围内。
数学模型
以分类模型为例子
首先我们有一个可爱的数据集 X = { ( x i , y i ) ∣ i = 1 , 2 , 3 , . . . , N } X=\{ {(x_i,y_i)|i=1,2,3,...,N} \} X={(xi,yi)∣i=1,2,3,...,N},每个样本x都会有一个标签y,注意x不是一个单独的值,而是具有一系列特征的d维向量,y就是我们要分的类别,可以是一个值,也可以是多个值,就像鞋子可以分为运动鞋和非运动鞋,也可以分为老年鞋和非老年鞋。
我们的目的就是建立一个模型 f : R d → R K f:R^d{\rightarrow}R^K f:Rd→RK,K代表种类数,输入的是d维的向量,经过f的映射后,输出在各个分类上的概率分布 P ( Y ∣ x i ) = f ( x i ; θ ) P(Y|x_i)=f(x_i;{\theta}) P(Y∣xi)=f(xi;θ)(翻译成人话:就是算出这个鞋有多大概率属于运动鞋,有多大概率属于老年鞋)。这样可以取最大概率的作为结果,即 y i ∗ = a r g m a x ( P ( Y ∣ x i ) ) y^*_i=argmax(P(Y|x_i)) yi∗=argmax(P(Y∣xi))(翻译成人话:如果运动鞋概率更大,我们就认为它是运动鞋)。
如何判断分类模型的好坏?
很简单,我们比较一下我们预测的结果跟实际结果的差别就可以了,如果能对大部分样本进行有效的预测,那我们的模型肯定没有问题。如何衡量这个差别呢?那就是用损失函数进行预测。
**损失函数(loss function)**通常用 L ( y , f ( x ; θ ) ) L(y,f(x;{\theta})) L(y,f(x;θ))来表示,y代表实际的结果, f ( x i ; θ ) f(x_i;\theta) f(xi;θ)代表我们预测的结果,我们会通过不停的训练,不停的调整 θ \theta θ的值,让损失函数最小,当损失函数最小时,我们也就得到了 θ \theta θ的最优值,这时的 f ( x i ; θ ) f(x_i;\theta) f(xi;θ)也就是我们使用的模型的最优情况,我们可以通过测量不同模型的最优的 θ \theta θ来判断哪种模型更贴切。求最优 θ \theta θ的过程被称为优化求解。这个过程可以用下式表示:
θ ∗ = a r g m i n [ 1 N ∑ i = 1 N L ( y i , f ( x i ; θ ) ) + λ ϕ ( θ ) ] {\theta}^*=argmin[\frac{1}{N}{\sum_{i=1}^N}L(y_i,f(x_i;\theta))+\lambda\phi(\theta)] θ∗=argmin[N1∑i=1NL(yi,f(xi;θ))+λϕ(θ)]
后面的 ϕ \phi ϕ表示的是正则化项(regularizer)或者说是惩罚项(penalty term),这个以后再进行详细解释。
在实际优化中,我们会不断进行迭代,直到最终的 θ \theta θ不再变化或者变化缓慢即可,这种情况下我们就说该模型已经收敛了。
过拟合现象:就是指我们的模型能完美符合训练集中的数据,但是对新样本的数据拟合情况十分糟糕,这种情况就是过拟合。正则化项就是为了解决过拟合现象而提出的。
常见的损失函数
1.平方损失函数
L ( y , f ( x ; θ ) ) = 1 N ∑ i = 1 N ( y i − f ( x i ; θ ) ) 2 L(y,f(x;\theta))=\frac{1}{N}\sum_{i=1}^{N}(y_i-f(x_i;\theta))^2 L(y,f(x;θ))=N1∑i=1N(yi−f(xi;θ))2
其中N是样本数量,常用于回归问题。
2.交叉熵损失
常用于分类问题,这个不过多解释了,可以去查一下熵的概念和定义。在离散情况下用的比较多,器形式如下:
L ( y , f ( x ) ) = H ( p , q ) = − 1 N ∑ i = 1 N p ( y i ∣ x i ) l o g [ q ( y i ^ ∣ x i ) ] L(y,f(x))=H(p,q)=-\frac{1}{N}\sum_{i=1}^{N}p(y_i|x_i)log[q(\hat{y_i}|x_i)] L(y,f(x))=H(p,q)=−N1∑i=1Np(yi∣xi)log[q(yi^∣xi)]
其中p代表真实分布,q代表模型预测的分布, p ( y i ∣ x i ) p(y_i|x_i) p(yi∣xi)代表样本标签的真实分布。
梯度下降算法
梯度下降算法的原理
梯度下降是一种经典的方法,利用梯度信息,通过不断迭代调整参数来寻找合适的解。
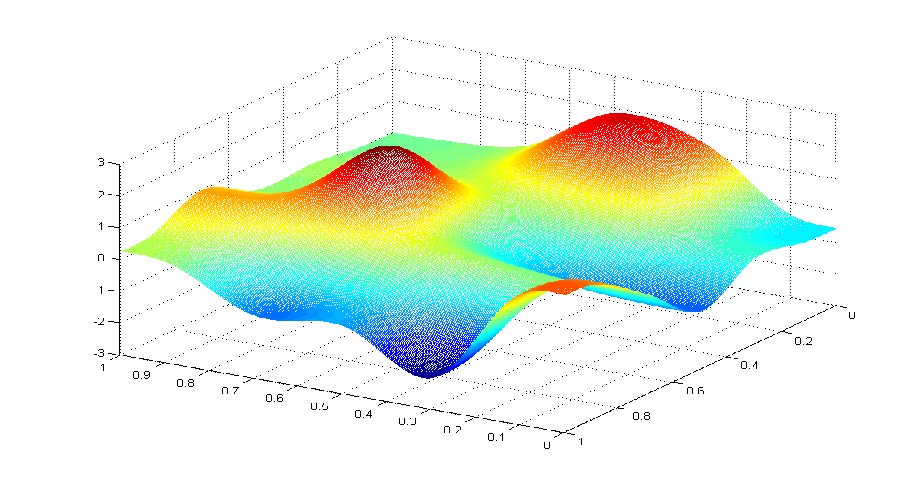
对于一个多元函数 f ( x ) f(x) f(x)(x是多维向量),梯度是指其中每个自变量的偏导数构成的向量, f ′ ( x ) f'(x) f′(x)表示
f ′ ( x ) = ∇ f ( x ) = [ ∇ f ( x 1 ) , . . . , ∇ f ( x n ) ] T f'(x)=\nabla{f(x)}=[\nabla{f(x_1)},...,\nabla{f(x_n)}]^T f′(x)=∇f(x)=[∇f(x1),...,∇f(xn)]T
让 f ( x + △ x ) f(x+\triangle{x}) f(x+△x)在x处泰勒展开可得:
f ′ ( x + △ x ) = f ( x ) + f ′ ( x ) T △ x + o ( △ x ) f'(x+\triangle{x})=f(x)+f'(x)^T{\triangle{x}}+o(\triangle{x}) f′(x+△x)=f(x)+f′(x)T△x+o(△x)
要使 f ( x + △ x ) < f ( x ) f(x+\triangle{x})<f(x) f(x+△x)<f(x),忽略高阶项,就要 f ′ ( x ) T △ x < 0 f'(x)^T{\triangle{x}}<0 f′(x)T△x<0,满足这个条件就可以让函数值变小,进一步
f ′ ( x ) T △ x = ∣ ∣ f ′ ( x ) T ∣ ∣ ⋅ ∣ ∣ △ x ∣ ∣ ⋅ c o s θ f'(x)^T\triangle{x}=||f'(x)^T||\cdot||\triangle{x}||\cdot{cos\theta} f′(x)T△x=∣∣f′(x)T∣∣⋅∣∣△x∣∣⋅cosθ
令 △ x = − α f ′ ( x ) \triangle{x}=-\alpha{f'(x)} △x=−αf′(x),就可以让更新后的函数变小,因为这样的话向量刚好相反, α \alpha α是一个超参数,用于调整步长的。
算法的步骤
- 给求解参数赋个值,作为优化的起点
- 对所有样本进行预测,算出损失值
- 利用损失值进行求导,得到相应的梯度
- 基于梯度调整参数
- 重复2-4的过程,直到达到预期
For i=0,1,2,3,…,N
L i = L ( X ; f ( X ; θ i ) L_i=L(X;f(X;\theta_i) Li=L(X;f(X;θi)
∇ θ i = ∂ L i ∂ θ i = { ∇ θ i ( 0 ) , . . . , ∇ θ i ( k ) } \nabla{\theta_i}=\frac{\partial{L_i} }{\partial{\theta{_i}} }=\{ {\nabla{\theta_i^{(0)} } },...,{\nabla{\theta_i^{(k)} } }\} ∇θi=∂θi∂Li={∇θi(0),...,∇θi(k)}
θ i + 1 = { θ i ( 0 ) − α ∇ θ i ( 0 ) , θ i ( k ) − α ∇ θ i ( k ) } \theta{_{i+1}}=\{ {\theta_i^{(0)}-\alpha{\nabla{\theta_i^{(0)} } } },{\theta_i^{(k)}-\alpha{\nabla{\theta_i^{(k)} } } }\} θi+1={θi(0)−α∇θi(0),θi(k)−α∇θi(k)}
随机梯度下降算法
上述算法在数据集较大时效率是比较低的,因为它的计算的数量以及处理的维度会特别大,会消耗大量的时间。像上述这种基于所有样本计算梯度值的算法叫做批梯度下降法(Batch Gradient Descent).
如果不使用全量的样本,而是选单个样本估计梯度,就能提高效率,而且这种方法的收敛性是可以保证的,这种方法叫随机梯度下降法(Stochastic Gradient Descent,SGD)。就是每次随机选一个样本进行计算,概率上来讲就是单个样本的梯度就是整个数据梯度的无偏估计,但由于不确定性,所以收敛速度会更慢。
改进的方法是每次选取多个样本进行计算。这种方法叫做小批量随机梯度下降(mini-batch,SGD)每次迭代选取的样本数量叫批大小(batch size)
基本算法同上,不在赘述。















 887
887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









