






分布式调用与高并发处理
Zookeeper介绍
Zookeeper是一个开源的分布式协调服务,由Apache软件基金会开发和维护。它被设计为一个高可用、高性能的系统,用于管理大型分布式系统中的配置信息、命名服务、分布式锁和协调服务等。

一、Zookeeper分布式协调服务
1.1 集中式到分布式
-
单机架构
一个项目的业务量代码很小的时候可以把所有的代码放到一个项目中,然后这个项目部署在一台服务器上就行,一整个系统的服务都是由这一台服务器来提供。
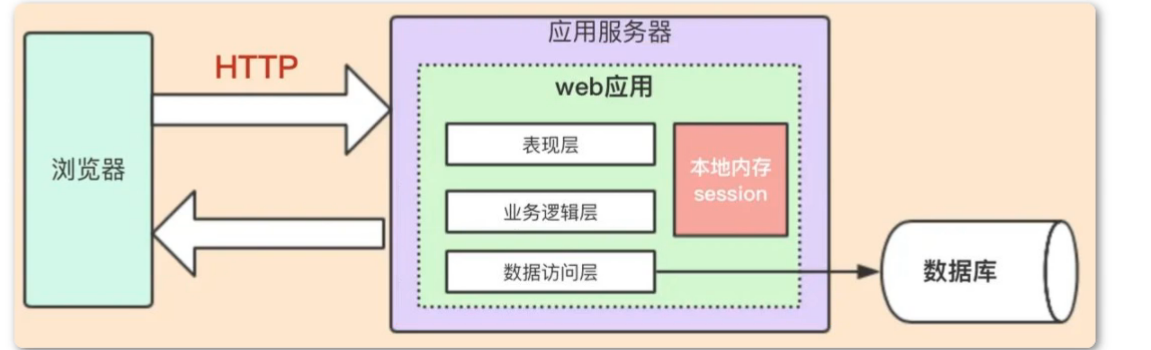
缺点:
- 服务性能存在瓶颈
- 不可伸缩
- 代码量庞大,系统臃肿,牵一发动全身
- 单点故障问题
- 集群架构
单处理机出现瓶颈的时候,吧单击复制几份,这样就构成了一个集群架构。

通过Nginx技术做反向代理负载均衡,将之前单机架构上的压力均衡分发到每一个Tomcat上。
举个梨子,比如之前的单机架构支持300个并发,现在集群架构就能支持900个并发了。
- 集群存在的问题
当业务发展的一定程度的规模的时候,无论怎么增加应用服务器的节点,整个集群的性能的提升效果就变得非常的不明显了。
1.2 什么是分布式
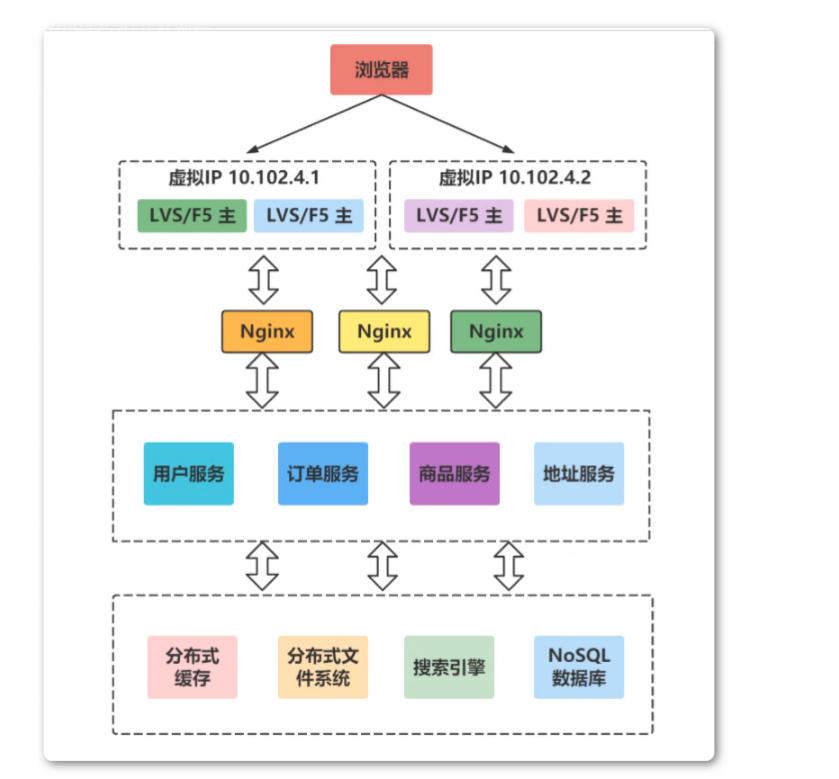
分布式架构就是讲一个完整的系统,按照业务功能,拆分成一个个独立的子系统,在分布式结构中,每一个子系统就称为 “服务”。这些子系统能够独立的运行再独立的web容器中,他们之间通过RPC通信。
- 分布式架构的优势:
- 系统(“子系统”)之间耦合度大大降低,可以独立开发,独立部署,独立测试,独立测试,系统与系统的边界非常的明确。使用这种架构能大大提升开发效率。
- 系统之间的耦合度降低,从而使系统更易于扩展。可以很容易的扩展某些服务(子系统)。
- 服务的可用性跟更高。如我们将用户当做单独的服务后,该公司的所有产品都能使用该系统的用户系统(服务),无需要再次开发独立的用户系统。
- 总结
将一套系统差分成不同的子系统咋不同的服务器上(分布式),然后部署多个相同的子系统在不同的服务器上,这就是集群。
1.3 CAP定理
分布式系统正在变得越来越重要,大型网站几乎都是分布式的。分布式系统最大的难点就在于,各个结点的状态改如何同步。CAP定理就是在这方面的基本定理。
- 分布系统的三个指标
- Consistency :一致性
- Availability :可用性
- Partition tolerance : 分区容错性
分别取其首字母组成了CAP定理,这三个指标不可能同时做到.
- 分区容错性
大多数分布式系统都分布在多个子网咯。每个自网络就是一个区。分区容错就是,区间通信可能会失败。例如,一个服务器在中国,另一台服务器在美国,这就是两个不同的区,它们之间可能无法通信。
在分布式系统中,分区容错无法避免,因此可以认为CAP的P总是成立,CAP定理告诉我们,剩下的A和C无法同时做到。
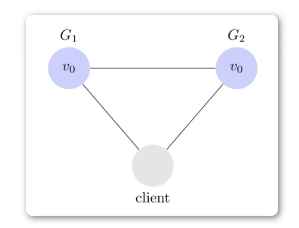
- 一致性
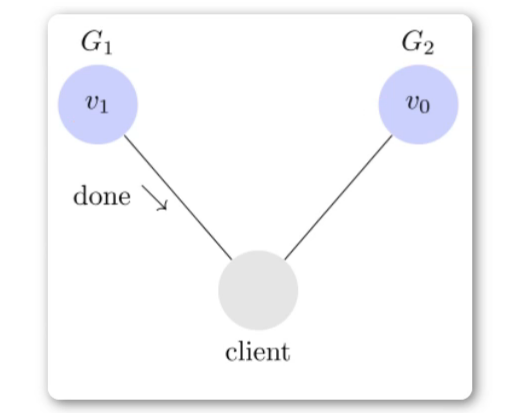
写操作之后的读操作,必须返回该值。比如有两个分区G1 和 G2,记录着V0 ,
用户向 G1 发起一个写操作,将其改为 v1。
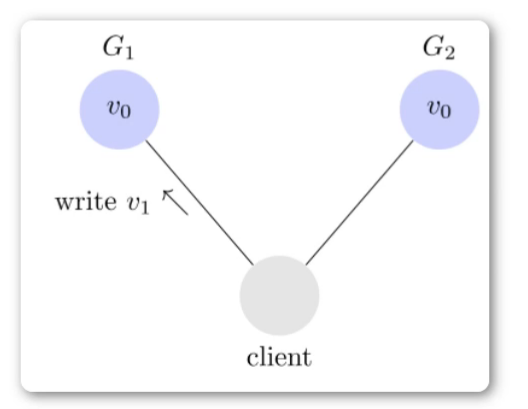
接下来,用户的读操作就会得到 v1。这就叫一致性
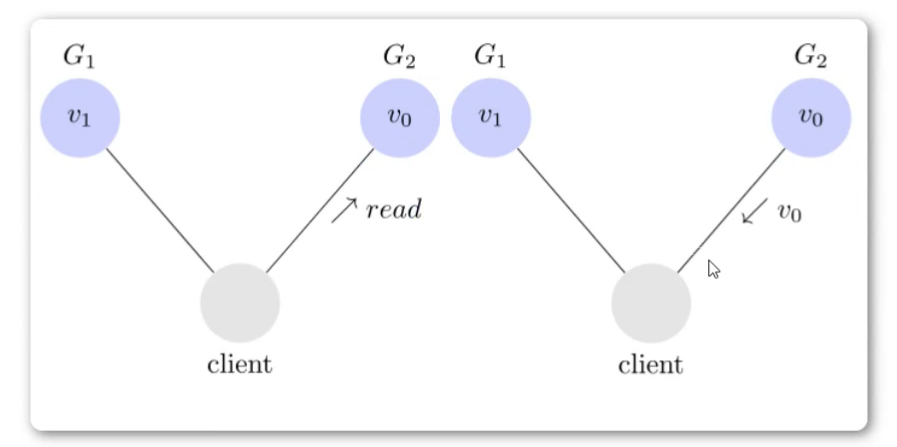
但是问题是用户有可能他不读G1,而是去读G2,由于G2的值没有发生变化,因此返回V0.
此时G1与G2的读操作结果就不一致了,这就不满足一致性。
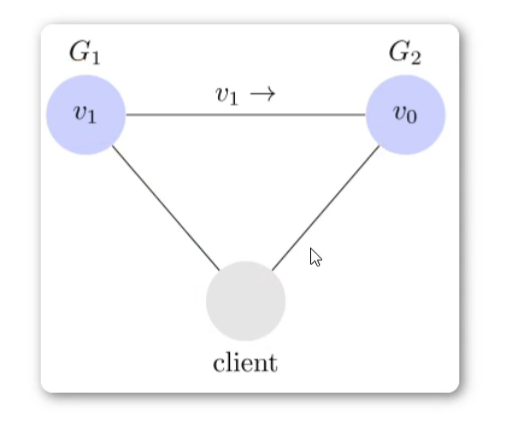
为了让 G2 也能变为 v1,就要在 G1 写操作的时候,让 G1 向 G2 发送一条消息,要求 G2 也改成 v1。
- 可用性
某一分区只要收到请求,该分区的服务必须给出相应的回应。
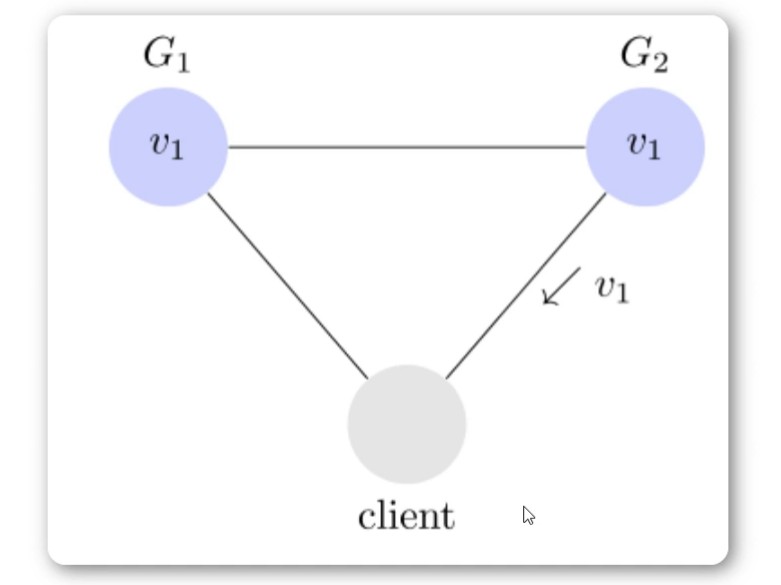
用户可以选择向 G1 或 G2 发起读操作。不管是哪台服务器,只要收到请求,就必须告诉用户,到底是 v0 还是 v1,否则就不满足可用性。
- 一致性和可用性的矛盾
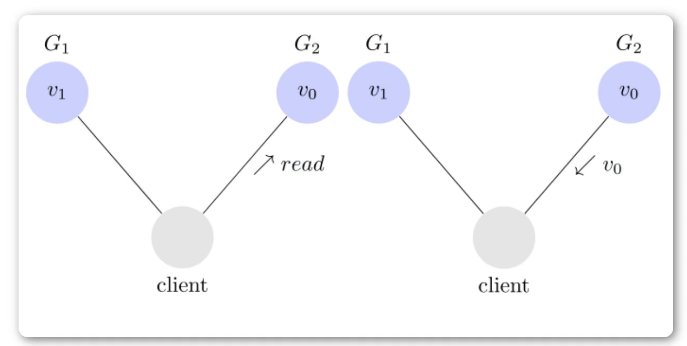
如果保证 G2 的一致性,那么 G1 必须在写操作时,锁定 G2 的读操作和写操作。只有数据同步后,才能重新开放读写。锁定期间,G2 不能读写,没有可用性不能保证。
- 一致性和可用性如何选者
- 可用性:特别是设计重要的数据,金钱、商品数量、商品价格。
- 可用性:网页的更新不是特别强调一致性,短使其内,一些用户拿到的网页是老版本,另一些用户拿到新版本,这样的问题往往问题不大,可以优先保证可用性。
1.3 什么是Zookeeper
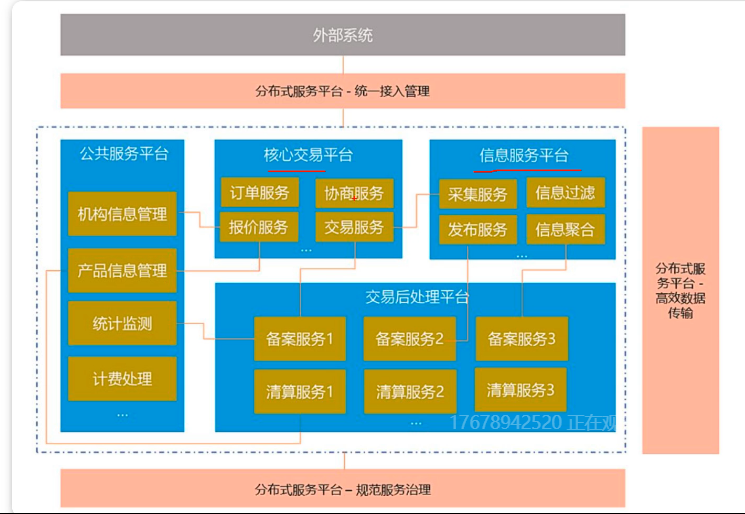
在该系统中。可以发现这是一个由很多个的子系统(服务),存在很多问题例如:
- 多节点协同问题
- 每天的定时任务由谁哪个节点来执行?
- RPC调用时的服务发现?
- 如何保证并发请求的幂等
这些问题可以统一归纳为多节点协调问题,如果靠节点自身进行协调这是非常不可靠的,性能上也不可取。必须由一个独立的服务做协调工作,它必须可靠,而且保证性能。
- ZooKeeper介绍
ZooKeeper是一个开放源代码的 分布式协调服务。ZooKeeper的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
1.4 Zookeeper应用场景
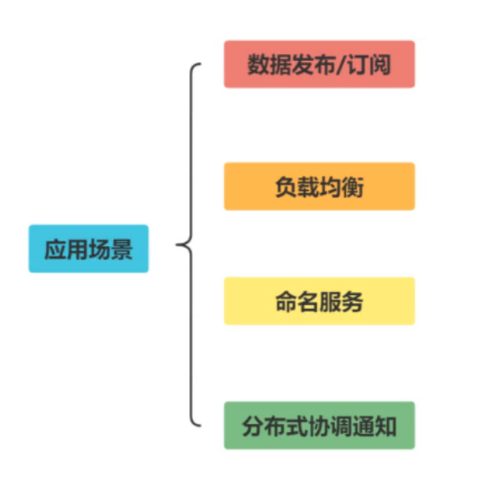
Zookeeper是一个典型的发布/订阅模式的分布式数据管理与协调框架。
1.4.1 数据发布/订阅
数据发布/订阅的一个常见的场景是配置中心,发布者把数据发布到 ZooKeeper 的一个或一系列的节点上,供订阅者进行数据订阅,达到动态获取数据的目的。
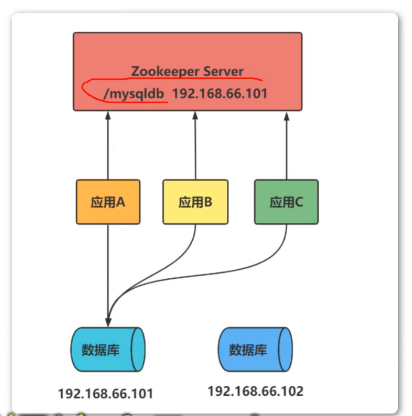
Zookeeper采用的是 推拉结合的方式。
- 推:服务端会推 给注册了监控结点的客户端Wathcer事件通知。
- 拉:客户端获得通知后。然后主动到服务端不拉去最新的数据。
- 实现思路
例如:将此配置信息放到数据节点上,共供程序拉取使用,发布、订阅模式是,配置文件发生改变时候,就会发布到注册里监控节点啥的客户端应用的一个Wather时间通知。之后有客户端来拉去最新的数据库配置信息。
- 具体流程
- 将此数据库连接信息放到,ZooKeeper的数据模式的节点上,例如/DBConfiguration。
- 客户端启动初始化阶段读取服务端节点的数据,并且注册一个数据变更的 Watcher监控。
- 配置变更只需要对 Znode 数据进行 set 操作,数据变更的通知会发送到客户端,客户端重新获取新数据,完成配置动态修改。而不是需要进行应用程序上的修改。
1.4.2 负载均衡
负载均衡是一种手段,用来把对某个资源的访问分摊给不同的设备,目的是为了减轻单点的压力。

在分布式系统中,将一个完整的系统分成许多个子系统(服务),比如用户服务。假设在某一时间段,并发访问量太大,一时间绷不住怎么办?是不是得多加几个用户服务,使用Zookeeper负载均衡分发到每个用户服务,从而减轻单点压力。
-
实现思路
- 首先建立 Servers 节点,并建立监听器监视 Servers 子节点的状态(用于在服务器增添时及时同步当前集群中服务器列表)
- 在每个服务器启动时,在 Servers 节点下建立临时子节点 Worker Server,并在对应的字节点下存入服务器的相关信息,包括服务的地址,IP,端口等等。
- 可以自定义一个负载均衡算法,在每个请求过来时从 ZooKeeper 服务器中获取当前集群服务器列表,根据算法选出其中一个服务器来处理请求。
1.4.3 命名服务
命名服务就是提供名称的服务。ZooKeeper 的命名服务有两个应用方面。
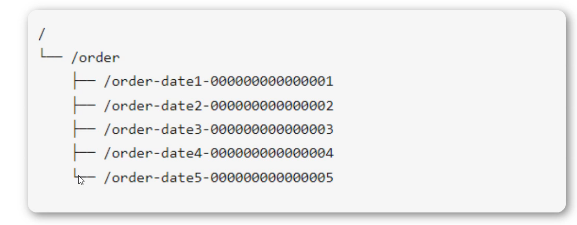
功能
提供类 JNDI 功能,可以把系统中各种服务的名称、地址以及目录信息存放在 ZooKeeper,需要的时候去 ZooKeeper 中读取。
制作分布式的序列号生成器。之前我们是单机的使用MySql的ID自动增长,是没有问题的,但是在分布式架构中肯定会出现问题。所以此处我们就需要命名服务功能来制作序列ID。
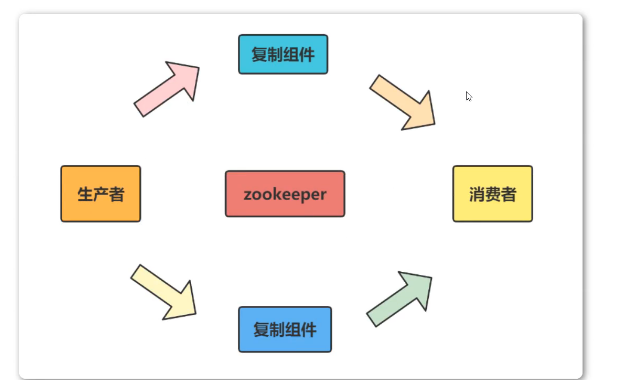
1.4.4 分布式协调/通知
分布式协调/通知服务是分布式系统中不可缺少的一个环节,是将不同的分布式组件有机结合起来的关节所在。对于一个在多台机器上部署运行的应用而言,通常需要一个协调者来控制整个系统的运行流程。
1.5 Zookeeper概念_基本概念
-
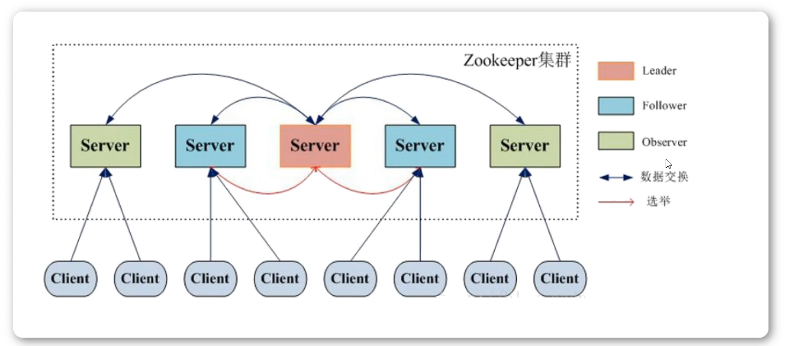
集群角色
通常在分布式系统中,构成一个集群的每一台机器都有着自己的角色,最典型的集群模式就是Master/Slave(主备模式),在这种模式中,能够处理所有写操作的机器称为Master机器,把所有通过异步复制方式获取最新数据,并提供读服务的机器称为Slave机器。
而在ZooKeeper中,这些概念被颠覆了。它没有沿用传统的MasterlSlave概念,而是引入了Leader、Follower和 Observer三种角色。
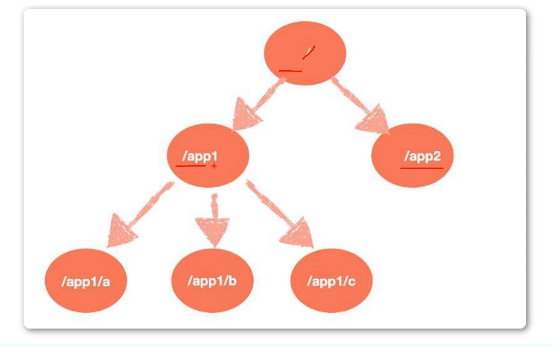
- 数据节点(znode)
在分布式系统中,我们常说的的“结点” 是指组成集群的每一台机器。
在Zookeeper中节点分为两类
- 第一类是指集群中的机器,称之为机器结点。
- 第二类是数据模型中的数据单元,称之为数据节点----ZNode
- Watcher监听机制
Watcher(事件监听器),是ZooKeeper 中的一个很重要的特性。
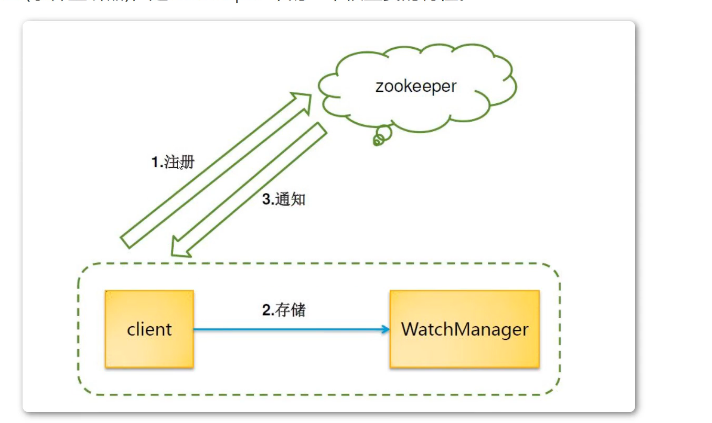
ZooKeeper 允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是ZooKeeper实现分布式协调服务的重要特性。
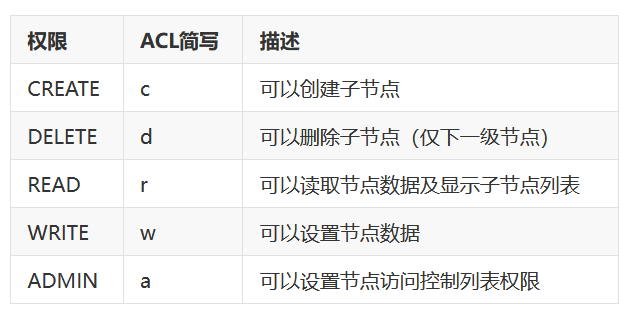
- ACL权限控制
ZooKeeper 采用ACL (Access Control Lists)策略来进行权限控制,类似于UNIX文件系统的权限控制。ZooKeeper定义了如下5种权限。

注意: create和delete这两种权限都是针对子节点的权限控制。
1.6 Zookeeper伪集群安装
1.6.1 虚拟机准备以及常见配置
- 安装3台虚拟机,zk1,zk2,zk3,过程省略。
- 关闭防火墙
- 查看防火墙状态:firewall-cmd --state
- 停止firewall:systemctl stop firewalld.service
- 禁止firewall开机启动:systemctl disable firewalld.service
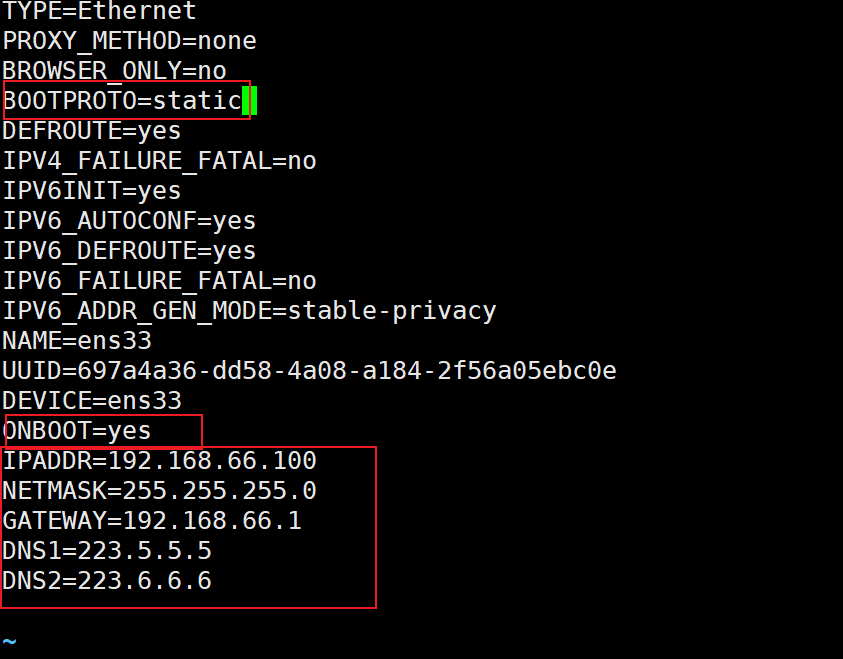
- 配置网卡ens33(注意三虚拟机的ip,等会要用)


编辑之后
- 重启网卡
service network restart
- 测试是否正常
ping www.baidu.com

- 为了方便装上vim 命令
yum -y install vim*
1.6.2 下载Zookeeper
https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.8.1/apache-zookeeper-3.8.1-bin.tar.gz
1.6.3 使用Xftp上传到虚拟机/服务器中的opt目录中

1.6.4 解压zookeeper 和 JDK
tar -zxvf jdk-8u361-linux-i586.tar.gz -C /usr/local/
- 进入安装目录:cd /usr/local/
- 更改jdk和zookeeper的名字
mv apache-zookeeper-3.8.1-bin/ zookeeper
- 配置jdk环境变量
vim /etc/profile
- 最后一行配置jdk路径

- 保存退出,执行source /etc/profile
- 输入java -version 出错原因是缺少了,运行yum install ld-linux.so.2装入这个插件解决。

- 修改Zookeeper 修改配置文件
进入zookeeper的安装目录的conf目录
cd /usr/local/zookeeper/config
cp zoo_sample.cfg zoo.cfg
- 修改zoo.cfg

# The number of milliseconds of each tick
tickTime=2000initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/zkdata
dataLogDir=/usr/local/zookeeper/zklogs
clientPort=2181
zkServer.sh start
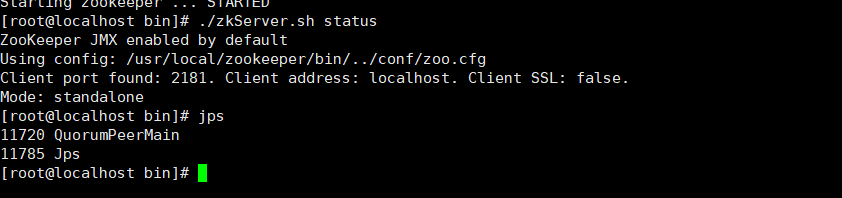
- 查看Zookeeper运行状态
zkServer.sh status
如图:启动成功
1.7 Zookeeper集群安装
- 将zk1的jdk复制到zk2、zk3
scp -r jdk/ 192.168.66.102:$PWD
Zookeeper同样的道理。

-
配置zk2,zk3的java环境变量
-
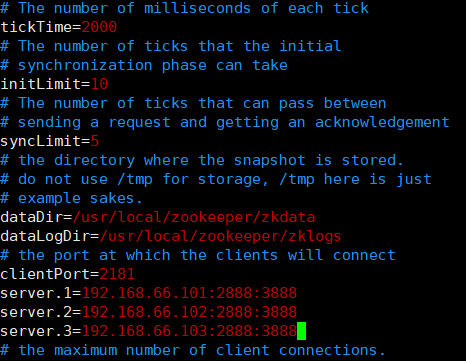
配置zk1 conf下的zoo.cfg
server.1=192.168.66.101:2888:3888
server.2=192.168.66.102:2888:3888
server.3=192.168.66.103:2888:3888
由于其他的服务器也用,我们将其发送到zk2 zk3
scp -r zoo.cfg 192.168.66.103:$PWD
scp -r zoo.cfg 192.168.66.102:$PWD

分别进入Zookeeper目录下
cd zkdata/
然后分别执行:
第一台机器上: echo 1 > /usr/local/zookeeper/zkdata/myid
第二台机器上: echo 2 > /usr/local/zookeeper/zkdata/myid
第三台机器上: echo 3 > /usr/local/zookeeper/zkdata/myid
进入到Zookeeper下的bin目录中:
zookeeper没有提供自动批量启动脚本,需要手动一台一台地起zookeeper进程 在每一台节点上,运行命令:
./zkServer.sh start
注意
启动后,用jps应该能看到一个进程:QuorumPeerMain。光有进程不代表已经成功启动了服务,用使用bin/zkServer.sh status能看到角色 模式,为leader或者followr,才算正常启动集群。
- 使用xshell同步命令到三个服务器(窗口)
1.7 部署运行_服务管理
| 脚本 | 说明 |
|---|---|
| zkCleanup | 清除Zookeeper历史数据,包括事务日志文件和快照数据文件 |
| zkCli | Zookeeper的简易客户端 |
| zkEnv | 设置Zookeeper的环境变量 |
| zkServer | Zookeeper服务器的启动、停止和重启脚本 |
-
每次都要去到Zookeeper安装目录的不能目录下启动/关闭/查看状态等,很不方便我们配置一下全局变量。
./zkServer.sh start -
配置环境变量
- 修改文件:将其添加到
vim /etc/profileexport ZOOKEEPER_HOME=/usr/local/zookeeper export PATH=$PATH:$ZOOKEEPER_HOME/binsource /etc/profile -
启动服务
sh zkServer.sh start
- 停止服务
sh zkServer.sh stop
sh zkServer.sh status
#!/bin/bash
# 验证传入的参数
if [ $# -ne 1 ]; then
echo "无效参数,用法为: $1 {start|stop|restart|status}"
exit
fi
# IP地址列表
hosts=(192.168.66.101 192.168.66.102 192.168.66.103)
# 遍历所有节点
for host in "${hosts[@]}"; do
echo "========== $host 正在 $1 ========="
# 发送命令给目标机器
ssh "$host" "source /etc/profile; /usr/local/zookeeper/bin/zkServer.sh $1"
done
1.8 数据模型
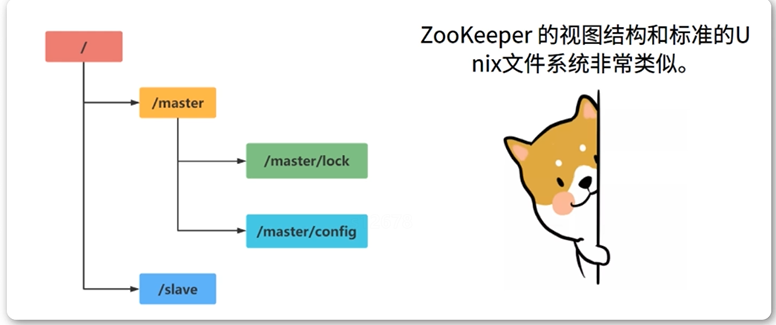
在Zookeeper中,可以说 Zookeeper中的所有存储的数据是由znode组成的,节点也称为 znode,并以 key/value 形式存储数据。
以 key/value 形式存储数据。key就是znode的节点路径,比如 /java , /server。
1.9 节点特性
Zookeeper节点是有生命周期的,这取决于,接单的类型。节点类型可以分为持久节点、临时节点、以及时序节点,具体在节点创建过程中,一般是组合使用,可以生成以下 4 种节点类型。
- 持久节点
持久节点是zookeeper中最常见的节点类型。所谓的持久节点,是指改数据节点被创建后,就会一致存在于zookeeper服务器上,直到有删除操作来主动秦楚这个节点。这个节点才会删除。
- 持久顺序节点
持久顺序节点的基本特性和持久节点是一致的,与其不同的是,在Zk中,每一个父节点会为它的第一级子节点维护一份时序,会记录每个子节点创建的先后顺序。
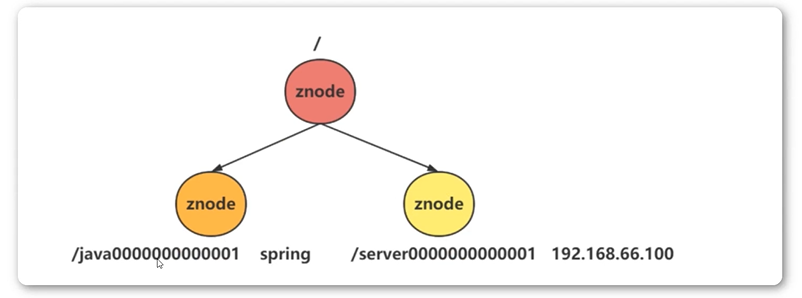
- 临时节点
从名称上可以看出该节点的一个最重要的特性就是临时性。
所谓临时性是指,如果将节点创建为临时节点,那么该节点数据不会一直存储在Zookeepr服务器上。
其和持久节点不同的是,临时节点的生命周期和客户端会话绑定。也就是说如果客户端会话失效,那么这个节点就会自动抹除掉。
会话失效,而非断开连接。最重要的是在临时节点下不能创建子节点。
- 临时顺序节点
临时顺序节点的基本特征和临时节点是一值的,同样是在临时节点的基础上,添加了顺序的特性。
1.10 Zookeeper系统模型_客户端命令行
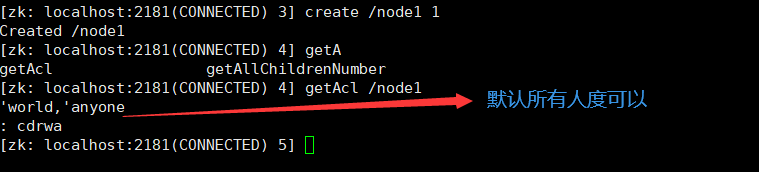
- 创建节点
创建ZK节点
create [-s] [-e] path data acl

- 进入客户端
zkCli.sh
创建节点


- 连续创建节点
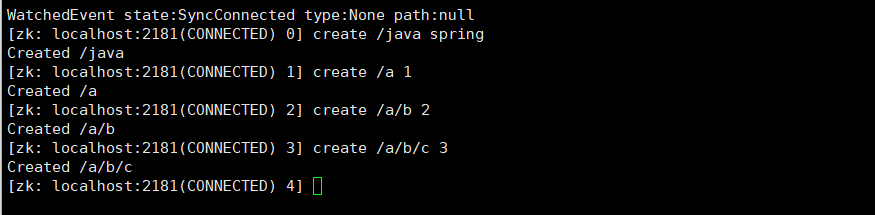
- 查看当前路径下有哪一些节点
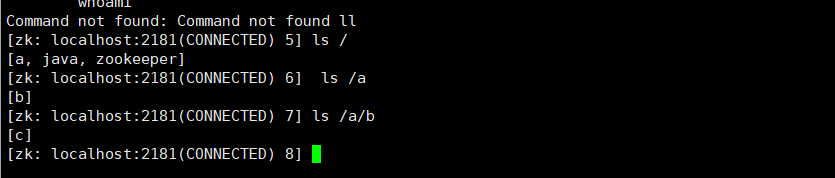
- 拿取某个节点的值

- 修改某一节点的值

- 删除结点

此处提示,该节点已不存在。
- 当接单下有子节点时候不能删除

- 注意
第一次部署的ZooKeeper集群,默认在根节点“1”下面有一个叫作/zookeeper的保留节点。
1.21 Zookeeper系统模型_节点数据信息

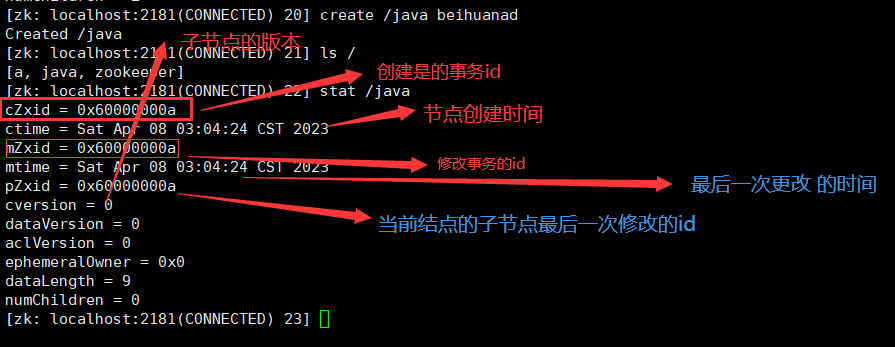
- 查看结点的状态结构
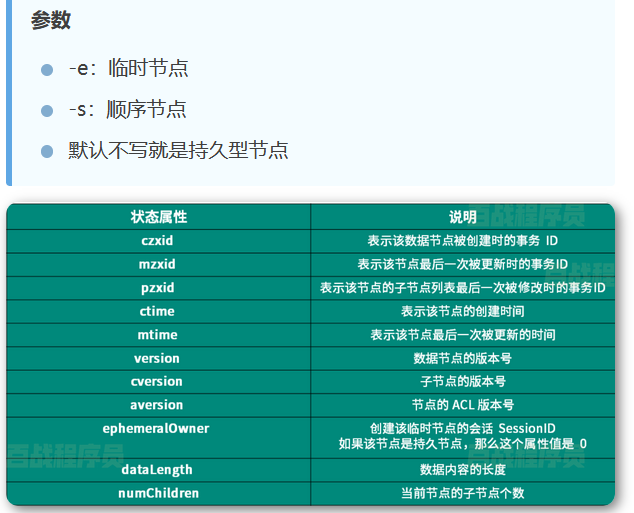
- 创建临时节点
create -e /tem baizhan
- 创建顺序节点
create -s /baijinhangtian basihd
1.22 Zookeeper系统模型_Watcher监听机制
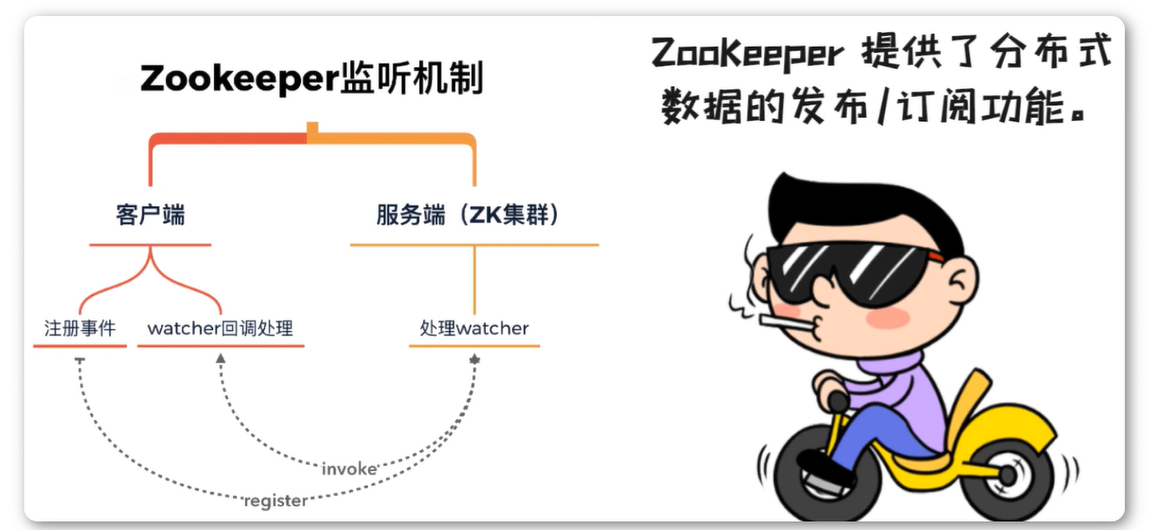
Zookeeper提供看分布式数据的发布/订阅功能。典型的发布/订阅系统定义了一种一对多的订阅关系,能够让多个订阅者同时间同某一个对象,当这个逐日对象自身状态发生变化时,会通知所有订阅者,使他们能够做出相应的变化的处理。

- 监听节点变化
ls -w path

语法结构
get -w path

1.23 Zookeeper系统模型_权限控制 ACL
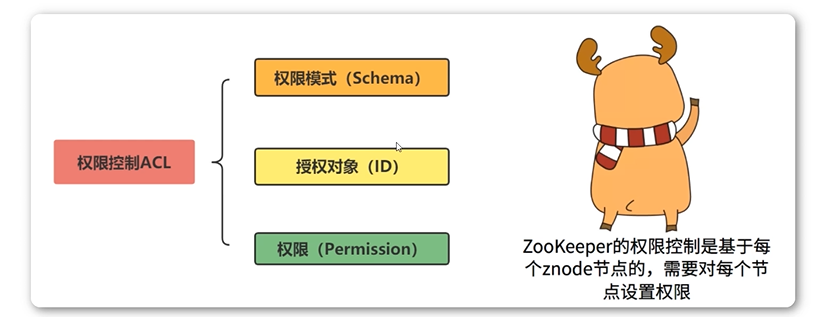
在实际开发中,Zookeeper的使用往往都是搭建一个公共的Zookeeper集群,统一为若干个应用提供服务。在这种情况下,不同的应用之间往往是不会存在共享数据的使用场景的,因此不需要解决不同引用之间的权限问题。
- ACL权限控制
- 权限模式
- 授权对象
- 权限
ZooKeeper的权限控制是基于每一个znode节点的,需要对每个节点设置权限。
每个znode节点支持设置多种权限控制方案和多个权限。
子节点不会继承父节点的权限,客户端无权访问某节点,但是可能可以访问其他的子节点。
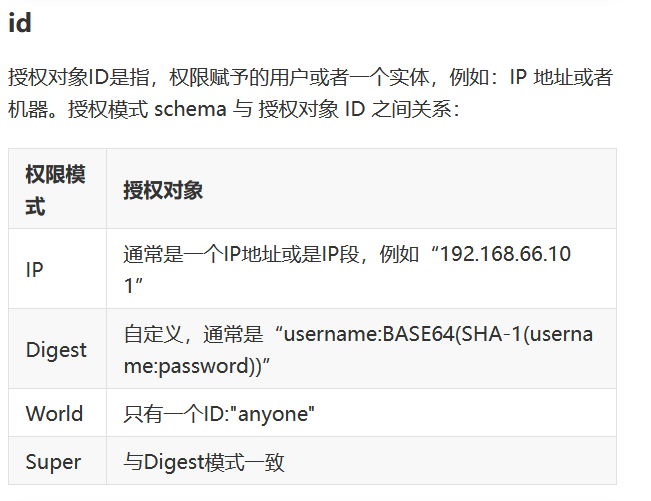
- schema模式
ZooKeeper内置了一些权限控制方案,可以用以下方案为每个节点设置权限:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BZ3pa5HE-1681006459324)(https://raw.githubusercontent.com/tjy17678942520/DrawingBed/master/images202304072033116.png)]
 ==
==
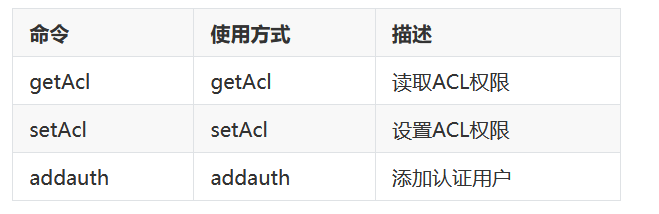
- 权限permision
- 相关命令
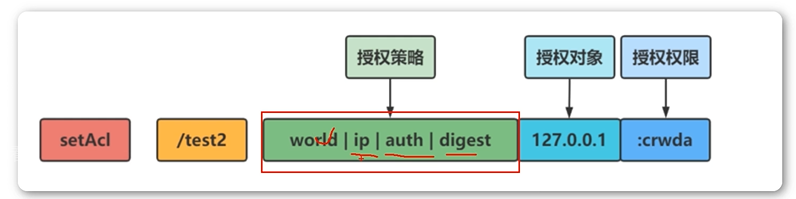
- World方案练习
语法格式
setAcl <path> world:anyone:<acl>
客户端实例
#任何人都拥有所有权限
- IP方案练习
语法格式
setAcl <path> ip:<ip>:<acl>


- 客户端实例
- Auth方案
语法格式:
setAcl
添加认证用户
addauth digest :
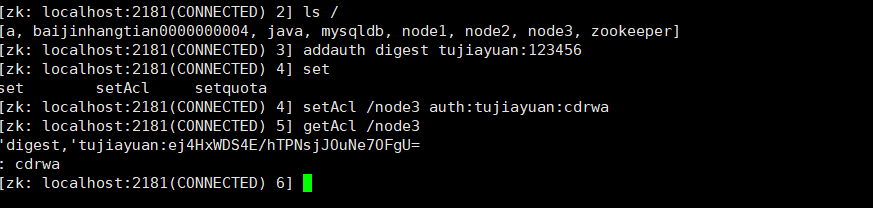
不熟悉参考一下模板
#创建节点
[zk: localhost:2181(CONNECTED) 0] create /node3 1
Created /node3
#添加认证用户
[zk: localhost:2181(CONNECTED) 1] addauth digest baizhan:123456
#设置权限
[zk: localhost:2181(CONNECTED) 2] setAcl /node3 auth:yoonper:cdrwa
#获取权限
[zk: localhost:2181(CONNECTED) 3] getAcl /node3
'digest,'baizhan:UvJWhBril5yzpEiA2eV7bwwhfLs=
: cdrwa
- Digest方案
语法格式:
setAcl <path> digest:<user>:<password>:<acl>
这里的密码是经过SHA1及BASE64处理的密文,在SHELL中可以通过以下命令计算:
先退出客户端,回去加密秘钥

echo -n tujiayuan:123456 | openssl dgst -binary -sha1 | openssl base64
//秘钥
ej4HxWDS4E/hTPNsjJOuNe7OFgU=

二、Java客户端_原生api操作Zookeeper
利用Zookeeper广发的原生java api进行连接,比较繁琐。

- 依赖
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.8</version>
</dependency>
- 基本从操作
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.util.List;
public class ZkMain {
public static void main(String[] args) {
try {
/**
* 创建连接
* 第一个参数据:服务器地址:端口
* 第二个超市时间
* 第三个坚挺机制
*/
ZooKeeper zooKeeper = new ZooKeeper("192.168.66.101:2181,192.168.66.102:2181,"+
"192.168.66.103:2181", 4000, null);
//查看结点状态
System.out.println(zooKeeper.getState());
//创建结点 成功返回创建结点的路径
String s = zooKeeper.create("/zknode4", "123456".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
if (s!=null){
System.out.println(s);
}
//判断当前节点是否存在
// Stat exists = zooKeeper.exists("/zknode4", null);
// System.out.println(exists.toString());
//删除结点
// zooKeeper.delete("/zknode4",-1);
//修改数据
//zooKeeper.setData("/zknode4","guihsm".getBytes(),-1);
//获取几点数据
byte[] data = zooKeeper.getData("/zknode4", null, null);
System.out.println(data);
//获取结点
List<String> children = zooKeeper.getChildren("/", null);
for (String s : children
) {
System.out.println(s);
}
} catch (IOException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (KeeperException e) {
throw new RuntimeException(e);
}
}
}
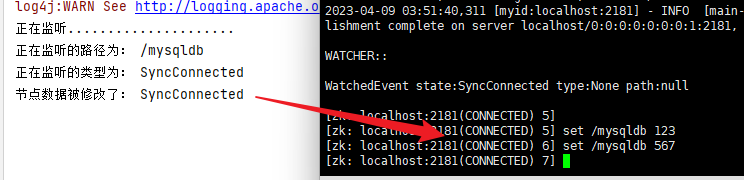
- 实现监听机制(注册监听getChilren)
通过连接对象调用getchildren(“/”,new watch()){}来注册监听,监听的是整个根本结点,但是这个监听只能监听一次,程序中的线程休眠是为了让监听机制等待事件发生。不让程序直接结束。

监听节点和数据方式。
三、Java客户端_zkClient操作Zookeeper

zkclient是Github上一个开源的Zookeeper客户端,在Zookeeper原生 API接口之上进行了包装,是一个更加易用的Zookeeper客户端。同时Zkclient在内部实现了诸如Session超时重连,Watcher反复注册等功能,从而提高开发效率。
- 添加依赖
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.10</version>
</dependency>
- 创建会话
//创建会话
ZkClient zk = new ZkClient("192.168.66.101:2181,192.168.66.102:2181,192.168.66.103:2181");
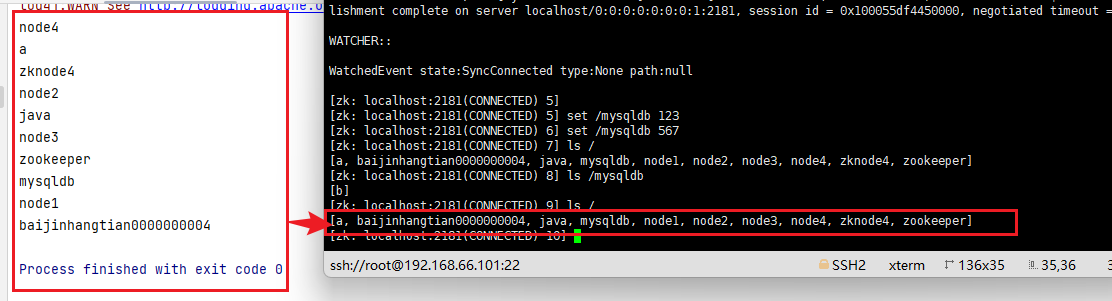
- 获取子节点
//获取子节点
List<String> children = zk.getChildren("/");
children.forEach(f ->{
System.out.println(f);
});
- 创建结点
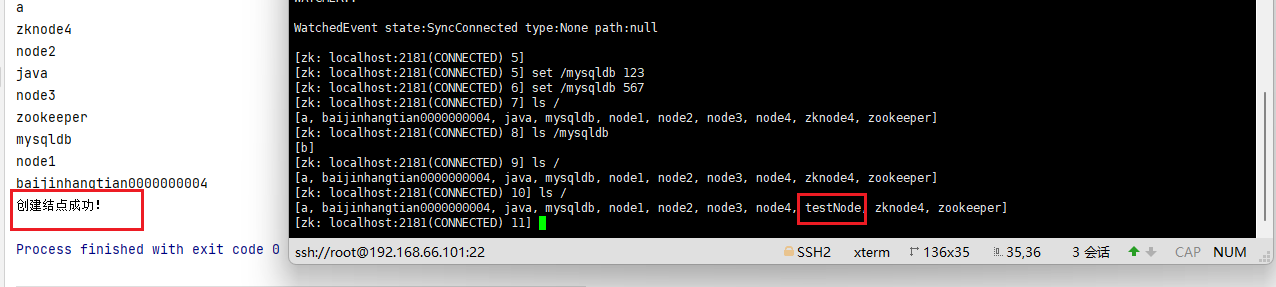
//创建结点
zk.create("/testNode","tututjian", CreateMode.PERSISTENT);
System.out.println("创建结点成功!");
- 修改结点
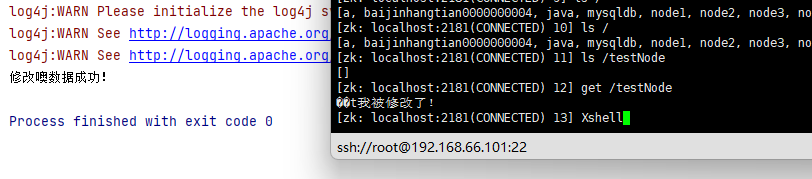
zk.writeData("/testNode","我被修改了!");
System.out.println("修改噢数据成功!");
- 获取数据

//获取数据
Object o = zk.readData("/testNode");
System.out.println(o.toString());
- 删除数据
//删除结点
zk.delete("/testNode");
- 注册事件监听事件
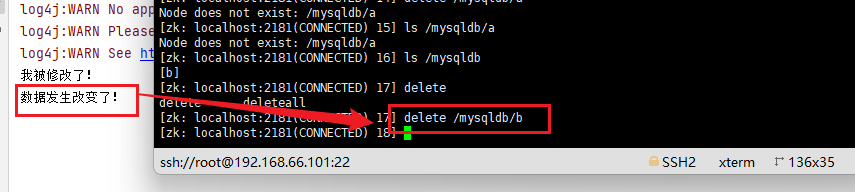
//注册节点监听事件
zk.subscribeChildChanges("/mysqldb",new IZkChildListener(){
@Override
public void handleChildChange(String s, List<String> list) throws Exception {
System.out.println("节点发生改变了!");
list.forEach(f ->{
System.out.println(f);
});
}
});
- 注册节点数据监听事件
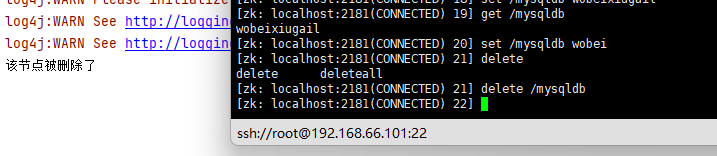
zk.subscribeDataChanges("/mysqldb", new IZkDataListener() {
@Override
public void handleDataChange(String s, Object o) throws Exception {
System.out.println("该节点数据b改了!");
}
@Override
public void handleDataDeleted(String s) throws Exception {
System.out.println("该节点被删除了");
}
});
Thread.sleep(Long.MAX_VALUE);
四、Java客户端_ApacheCurator操作Zookeeper
- 添加依赖
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.2.0</version>
</dependency>
- 创建会话
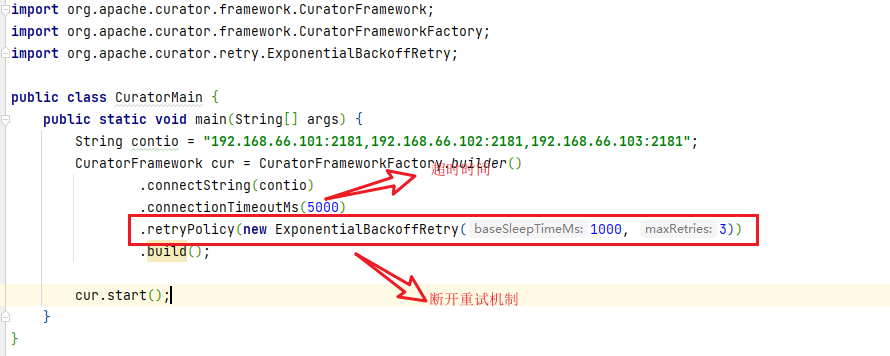

//创建结点
cur.create().withMode(CreateMode.PERSISTENT)
.forPath("/root","jiayouwozhidaowohenben!".getBytes());
- 获取数据
//获取数据
byte[] bytes = cur.getData().forPath("/mysqldb");
System.out.println(new String(bytes));
- 删除数据节点
//删除结点
cur.delete().forPath("/testNode");
**注意:**该方法只能删除叶子结点,否则会出现异常!

- 删除一个结点,并且递归删除其所有的子节点
比如这种有子节点的,我们使用递归去删

cur.delete().deletingChildrenIfNeeded().forPath("/java");
删除后

- 更新一个结点的数据内容

该接口会返回一个Stat实例;
- 获取某个节点的所有子节点
client.getChildren().forPath("path");
- 监听机制
//监听机制
NodeCache nodeCache = new NodeCache(cur, "/node3");
nodeCache.getListenable().addListener(()->{
System.out.println("被修改了");
});
Thread.sleep(Long.MAX_VALUE);
五、Zookeeper四字命令

之前我们使用过stat命令来验证Zookeeper服务器是否启动成功,这里的stat命令就是Zookeeper中最为典型的命令之一。Zookeeper中有很多类似的命令,他们的长度通常是4个字。
- 四肢命令----conf
该命令是输出服务器的详细配置信息。如客户端端口。数据存储路径、最大连接数、日志路径、数据同步端口、主节点推举端口、session超时时间等等。
echo conf| nc localhost 2181



出现这个是没有安装nc和配置原因,安装就好
-
添加配置vim zoo.cfg
4lw.commands.whitelist=* -
安装nc
yum install nc

- 四字命令—cons
该命令用于输出这台服务器上所有客户端连接的详细信息,包括每个客户端的ip,会话id和最后一次与服务器交互的操作类型等

echo cons | nc localhost 2181
- 四字命令—rouk
ruok命令用于输出当前ZooKeeper服务器是否正在运行。如果当前ZooKeeper服务器正在运行,那么返回“imok”, 否则没有任何响应输出。

- 四字命令—stat
stat命令用于获取ZooKeeper服务器的运行时状态信息,包括基本的ZooKeeper版本、打包信息、运行时角色、集群数据节点个数等信息,另外还会将当前服务器的客户端连接信息打印出来。
echo stat | nc localhost 2181
- 四字命令—mntr
列出集群的关键性能数据,包括zk的版本、最大/平均、最小延迟数、数据包接收/发送量、连接数、zk角色(Leader/Follower)、node数量、watch数量、临时节点数。
echo mntr | nc localhost 2181
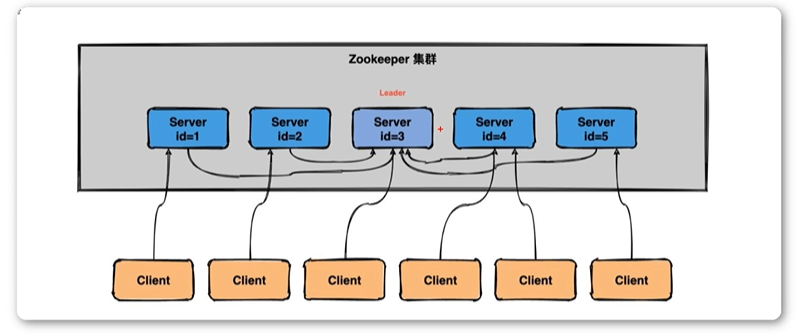
六、选举机制
- 核心选举原则
- Zookeeper集群中只有超过半数以上的服务器启动,集群才能正常工作;
- 在集群正常工作前,nyid小的服务器会给myid大的服务器偷跑,知道集群正常工作,选出leader。
- 半数机制;
-
选举机制流程
- 服务器1启动,给自己头一票,然后发送投票信息,由于其他的服务器还没有启动,他收不到反馈信息,服务器1的状态一直处于Looking(选举状态)。
- 服务2启动,首先给自己投出一票,同时与之前启动的服务器1贾环结果,由于服务器2的编号大,所以服务器2胜出,但此时投票数没有大于集群数的一半,所以这两个集群任然是Looking。
- 服务器31栋,先投自己一票,同时与之前服务器交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟。
-
选举机制中的概念
- 服务器ID:Serverid:比如3台服务器,编号分别是1,2,3.

- 数据ID:Zxid:服务器中存放的最大数据的id

-
逻辑时钟
或者叫投票的次数,同一轮投票的过程中的逻辑时钟值是相同的。没投完一次票这数据就会增加,然后与接收到的其他服务器返回的投票信息相比,根据不同的值做出不同的判断。
小涂碎碎念
花了差不多两周多的时间学习,虽然在很多更深层次的东西,还不是很了解。对Zookeeper分布式协调服务有了初略的认识,我会在后面的学习中不断的加强,力求达到更高的层次。
坚持一定会好起来的!笨,但不能不往前走!
















 215
215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











