







从0开始带你成为Kafka消息中间件高手—第二讲
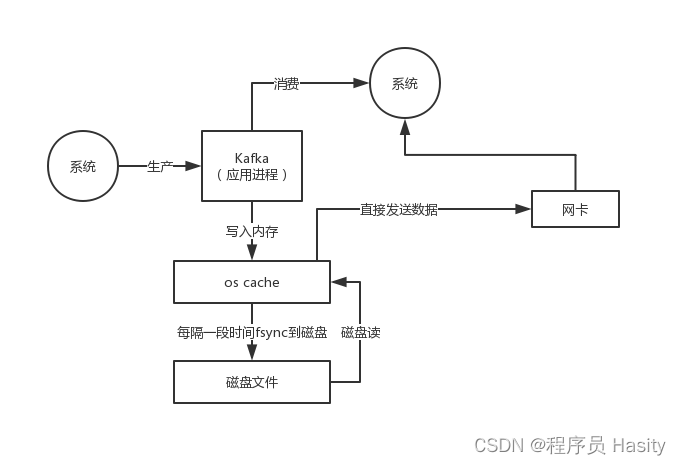
那么在消费数据的时候,需要从磁盘文件里读取数据后通过网络发送出去,这个时候怎么提升性能呢?
首先就是利用了page cache技术,之前说过,kafka写入数据到磁盘文件的时候,实际上是写入page cache的,没有直接发生磁盘IO,所以写入的数据大部分都是停留在os层的page cache里的
这个本质其实跟elasticsearch的实现原理是类似的
然后在读取的时候,如果正常情况下从磁盘读取数据,先尝试从page cache读,读不到才从磁盘IO读,读到数据以后先会放在os层的一个page cache里,接着会发生上下文切换到系统那边,把os的读缓存数据拷贝到应用缓存里
接着再次发生上下文二切换到os层,把应用缓存的数据拷贝到os的socket缓存中,最后数据再发送到网卡上
这个过程里,发生了好几次上下文切换,而且还涉及到了好几次数据拷贝,如果不考虑跟硬件之间的交互,起码是从os cache到用户缓存,从用户缓存到socket缓存,有两次拷贝是绝对没必要的
但是如果用零拷贝技术,就是linux的sendfile,就可以直接把操作交给os,os看page cache里是否有数据,如果没有就从磁盘上读取,如果有的话直接把os cache里的数据拷贝给网卡了,中间不用走那么多步骤了
对比一下,是不是所谓的零拷贝了?
所以呢,通过零拷贝技术来读取磁盘上的数据,还有page cahce的帮助,这个性能就非常高了

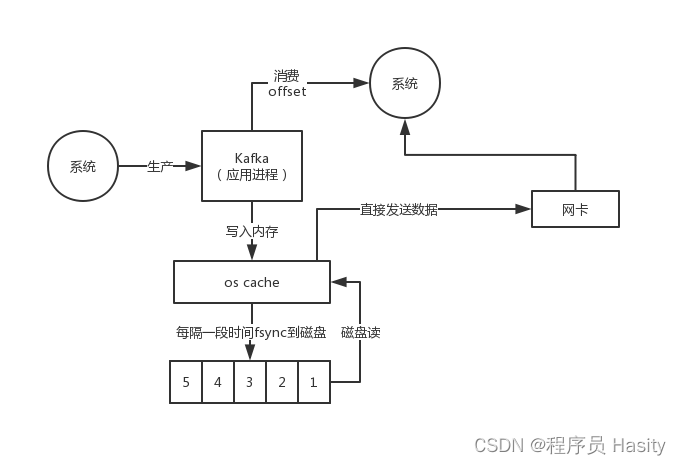
基本上可以认为每个partition就是一个日志文件,存在于某台Kafka服务器上,然后这个日志里写入了很多消息,每个消息在partition日志文件里都有一个序号,叫做offset,代表这个消息是日志文件里的第几条消息
但是在消费消息的时候也有一个所谓的offset,这个offset是代表消费者目前在partition日志文件里消费到了第几条消息,是两回事儿
kafka的消息格式如下:
crc32(确保消息没有修改),magic,attribute(属性),时间戳,key长度,key,value长度,value
kafka是直接通过NIO的ByteBuffer以二进制的方式来保存消息的,这种二级制紧凑保存格式可以比使用Java对象保存消息要节约40%的内存空间
然后这个消息实际上是封装在一个log entry里的,你可以认为是一个日志条目吧,在kafka里认为每个partition实际上就是一个磁盘上的日志文件,写到parttion里去的消息就是一个日志,所以log entry就是一个日志
这个日志条目包含了一个offset,一个消息的大小,然后是消息自身,就是上面那个数据结构,但是这里要注意的一点,就是这个message里可能会包含多条消息压缩在一起,所以可能找一条消息,需要从这个压缩数据里遍历搜索
而且这里还有一个概念就是消息集合,一个消息集合里包含多个日志,最新名称叫做RecordBatch
后来消息格式演化为了如下所示:
(1)消息总长度
(2)属性:废弃了,已经不用
(3)时间戳增量:跟RecordBatch的时间戳的增量差值
(4)offset增量:跟RecordBatch的offset的增量差值
(5)key长度
(6)key
(7)value长度
(8)value
(9)header个数
(10)header:自定义的消息元数据,key-value对
通过时间戳、offset、key长度等都用可变长度来尽可能减少空间占用,v2版本的数据格式比v1版本的数据格式要节约很多磁盘开销
但是这里有一个很大的问题,就是不可能说把TB量级的数据都放在一台Kafka服务器上吧?这样肯定会遇到容量有限的问题,所以Kafka是支持分布式存储的,也就是说你的一个topic,代表了逻辑上的一个数据集
你大概可以认为一个业务上的数据集合吧,比如说用户行为日志都走一个topic,数据库里的每个表的数据分别是一个topic,订单表的增删改的变更记录进入一个topic,促销表的增删改的变更记录进入一个topic
每个topic都有很多个partition,你认为是数据分区,或者是数据分片,大概这些意思都可以,就是说这个topic假设有10TB的数据量需要存储在磁盘上,此时你给他分配了5个partition,那么每个partition都可以存放2TB的数据
然后每个partition不就可以放在一台机器上,通过这个方式就可以实现数据的分布式存储了,每台机器上都运行一个Kafka的进程,叫做Broker,以后大家记住,borker就是一个kafka进程,在一台服务器上就可以了

但是这里就有一个问题了,如果此时Kafka某台机器宕机了,那么一个topic就丢失了一个partition的数据,此时不就导致数据丢失了吗?所以啊,所以对数据做多副本冗余,也就是每个parttion都有副本
比如最基本的就是每个partition做一个副本,副本放在另外一台机器上
然后呢kafka自动从一个partition的多个副本中选举出来一个leader partition,这个leader partition就负责对外提供这个partiton的数据读写,接收到写过来的数据,就可以把数据复制到副本partition上去
这个时候如果说某台机器宕机了,上面的leader partition没了,此时怎么办呢?通过zookeeper来维持跟每个kafka的会话,如果一个kafka进程宕机了,此时kafka集群就会重新选举一个leader partition,就是用他的某个副本partition即可
通过副本partition可以继续体统这个partition的数据写入和读取,这样就可以实现容错了,这个副本partition的专业术语叫做follower partition,所以每个partitino都有多个副本,其中一个是leader,是选举出来的,其他的都是follower partition
多副本冗余的机制,就可以实现Kafka高可用架构

光是依靠多副本机制能保证Kafka的高可用性,但是能保证数据不丢失吗?不行,因为如果leader宕机,但是leader的数据还没同步到follower上去,此时即使选举了follower作为新的leader,当时刚才的数据已经丢失了
ISR是:in-sync replica,就是跟leader partition保持同步的follower partition的数量,只有处于ISR列表中的follower才可以在leader宕机之后被选举为新的leader,因为在这个ISR列表里代表他的数据跟leader是同步的
如果要保证写入kafka的数据不丢失,首先需要保证ISR中至少有一个follower,其次就是在一条数据写入了leader partition之后,要求必须复制给ISR中所有的follower partition,才能说代表这条数据已提交,绝对不会丢失,这是Kafka给出的承诺

假如说很多partition的leader都在一台机器上,那么不就会导致大量的客户端都请求那一台机器?这样是不对的,kafka集群会自动实现负载均衡的算法,尽量把leader partition均匀分布在集群各个机器上
然后客户端在请求的时候,就会尽可能均匀的请求到kafka集群的每一台机器上去了,假如出现了partition leader的变动,那么客户端会感知到,然后下次就可以就可以请求最新的那个leader partition了
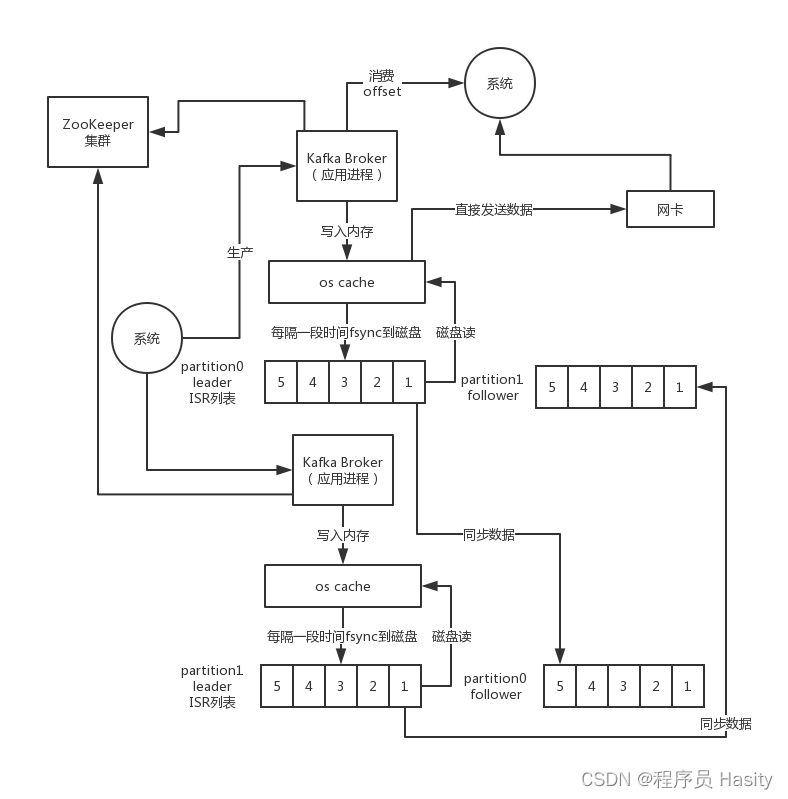
Kafka的broker尽量是无状态的,状态数据存入Zookeeper,zookeeper用来管理Broker的状态
















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









