






copy到接口到python里面访问发现不能访问,但是浏览器可以重攻击。
使用过去经验使用httpx采用http2.0方式访问依然不行。
采用wireshare发现浏览器和python的ja3算法的信息不同,所以可能是python请求的和浏览器的TLS指纹差异,服务器屏蔽了python的请求。所以用python模拟浏览器请求可解。
参考代码:https://lukasa.co.uk/2017/02/Configuring_TLS_With_Requests/
修改CIPHERS长度直至和浏览器类似,或者可以获得结果
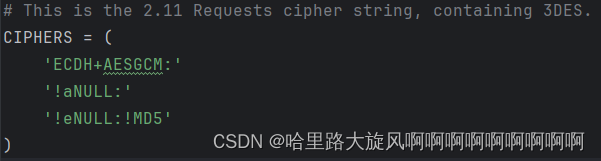
参考链接:https://www.cnblogs.com/Eeyhan/p/15662849.html
TLS指纹,JA3算法参考链接:https://blog.csdn.net/god_zzZ/article/details/123010576
以下代码:
import requests
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.ssl_ import create_urllib3_context
# This is the 2.11 Requests cipher string, containing 3DES.
CIPHERS = (
'ECDH+AESGCM:'
'!aNULL:'
'!eNULL:!MD5'
)
class DESAdapter(HTTPAdapter):
"""
A TransportAdapter that re-enables 3DES support in Requests.
"""
def init_poolmanager(self, *args, **kwargs):
context = create_urllib3_context(ciphers=CIPHERS)
kwargs['ssl_context'] = context
return super(DESAdapter, self).init_poolmanager(*args, **kwargs)
def proxy_manager_for(self, *args, **kwargs):
context = create_urllib3_context(ciphers=CIPHERS)
kwargs['ssl_context'] = context
return super(DESAdapter, self).proxy_manager_for(*args, **kwargs)
headers = {
'cookie': '是什么呢?'
}
def getPage(page):
sss = 0
page = str(page)
s = requests.Session()
s.mount(f'https://match.yuanrenxue.cn/api/match/19?page={page}', DESAdapter())
r = s.get(headers=headers, url=f'https://match.yuanrenxue.cn/api/match/19?page={page}')
values = r.json()['data']
for i in values:
sss += int(i['value'])
# print(i['value'])
return sss
sum = 0
for i in range(1, 6):
sum += getPage(i)
print(sum)















 1170
1170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









