






目录
第二章 从口令系统说起
2.1 身份鉴别常见手段及例子
-
知道什么:口令
-
拥有什么:汽车钥匙 or 加密狗
-
唯一特征:指纹 or 虹膜
2.2 多因子认证
多因子认证是指在进行身份验证时,需要提供两个或以上的验证因素,以提高系统的安全性和防范恶意攻击。这些因素可以是以下几种类型之一:
-
知道的事情:例如用户名+密码。
-
拥有的物品:例如手机验证码和校园卡刷卡。
-
生理特征:例如人脸识别。
2.3 计时攻击
计时攻击(Timing attack)是一种利用计算机程序执行时间的差异,推断出密钥或其他敏感信息的攻击方式。该攻击方式主要利用了程序中某些部分的执行时间和输入数据的关系,通过多次尝试不同的输入数据,对比它们的执行时间来推断出正确的数据或密钥。
这是一个程序比较输入密码和正确密码的程序示例
def compare_password(correct_password, user_password):
# 密码长度是否一致
if len(correct_password) != len(user_password):
return False
# 逐个字符比较密码是否一致
for i in range(len(user_password)):
if correct_password[i] != user_password[i]:
return False
return True2.3.1 攻击示例
可以看出,攻击者可以利用程序中比较密码长度是否一致的代码段,推断正确密码的长度。以下是一个模拟计时攻击的示例代码:
correct_password = "xxxxxxxx" # 8个x
# 暴力破解密码,统计每个长度可能的密码尝试所耗费的时间
for i in range(1, 256):
user_password = "a" * i
start_time = time.time()
compare_password(correct_password, user_password)
end_time = time.time()
print("测试密码长度 ", i, " 所耗费时间: ", end_time - start_time)依次尝试所有可能长度的密码,然后统计每个长度可能的密码尝试所花费的时间。攻击者可以根据运行时间来推断正确的密码长度,从而缩小猜测范围。
2.3.2 攻击防御
如果需要防御计时攻击也是不难的,我们可以前后加上 time.sleep(random.uniform(0, 0.1)),就可以让攻击者无所适从
def compare_password(correct_password: str, user_password: str) -> bool:
# 随机时间*2
time.sleep(random.uniform(0, 0.1))
time.sleep(random.uniform(0, 0.1))
# 比较长度
if len(correct_password) != len(user_password):
return False
# 随机时间*3
time.sleep(random.uniform(0, 0.1))
time.sleep(random.uniform(0, 0.1))
time.sleep(random.uniform(0, 0.1))
for a, b in zip(correct_password, user_password):
if ord(a) ^ ord(b) != 0:
return False
return True2.4 口令机制
口令是指在计算机系统中,由用户自己设定的一段字符串,用于验证用户身份合法性的一种方式。通过口令验证,可以有效增强计算机系统的安全性。常见的口令包括密码、PIN码。
口令系统是指基于口令验证技术的计算机安全系统。它通过要求用户输入正确的口令来验证用户的身份,从而允许或拒绝用户对计算机系统中资源的访问,口令系统是计算机安全的重要组成部分。
2.4.1 公式及含义
在口令机制的强度中 P=LR/S 公式中:
密码最大存活期L: lifetime
登录尝试率R: login attempt rate
密码空间大小S: size of space
猜测攻击概率:P=LR/S
常见的增强口令和口令系统方法,可以有效的增加攻击者成本。常见方法不难想到、查到,方法如下:
-
双重验证。现在Google,Github都以手机端APP验证为首选的口令认证方式,这确实是避免了很多的安全问题。
-
缩短密码最大存活期L:密码的存活期越长,攻击者越有机会进行猜测攻击。因此,缩短密码的存活期可以有效减少攻击者的机会,提高攻击成本。
-
限制登录尝试次数R:限制用户在一定时间内可以进行的登录尝试次数,例如智慧安大密码输入错误最大次数为15次,安徽大学教务系统为5次。限制登录尝试次数可以阻止攻击者对口令进行暴力破解,增加攻击者成本。
-
增大密码空间大小S:增大密码空间大小可以使攻击者在猜测密码时需要更多的时间和计算资源,从而增加攻击者成本。我们可以通过使用更复杂的密码组合,如数字、字母、符号等,来增大密码空间大小。也可以通过避免使用常见密码。
2.4.2 Hash+salt安全性分析
Hash+salt是一种常用的密码存储方法,其中,Hash函数用于将明文密码转化为一段固定长度的哈希值,而salt则是一段随机字符串,用于增加哈希值的随机性和独立性。当用户注册时,系统将将原始密码与salt值组合,并通过Hash函数生成哈希值,并将salt和哈希值一起保存到数据库中。当用户进行登录时,系统使用相同的salt值和哈希函数来处理输入的密码,并将结果与保存的哈希值进行比较。如果结果一致,则证明用户提供的密码是正确的。
这样的密码存储方式虽然不能避免暴力破解,但可以防御彩虹表攻击和重放攻击。
2.4.3 防御
单台设备破解,每秒尝试100次——错误达到10次后,每5min才能尝试一次
控制僵尸网络破解——统计,加入黑名单;多因素身份验证
2.5 假托和钓鱼
2.5.1 概念与实例
假托:一种制造虚假情形,使人吐露不愿泄露的信息的手段。该方法通常预含对特殊情景专用术语的研究,以建立合情合理的假象。(自称某某工作人员)
钓鱼:一种企图从电子通讯中,透过伪装成信誉卓著的法人媒体以获得如用户名、密码和信用卡明细等个人敏感信息的犯罪诈骗过程。(钓鱼网站)
2.5.2 防范措施
浏览器厂商、xx管家:钓鱼警告工具栏。
检查SSL锁和url英语的精确性。
双因素认证;双通道身份认证。
第三章 安全协议
3.1 认证协议
3.1.1 口令协议
最简单的认证协议。口令/密码,PIN都是典型例子。
3.1.2 单向认证
发送序列号+认证块,认证块包括序列号+Nonce,Nonce每个人是唯一的。
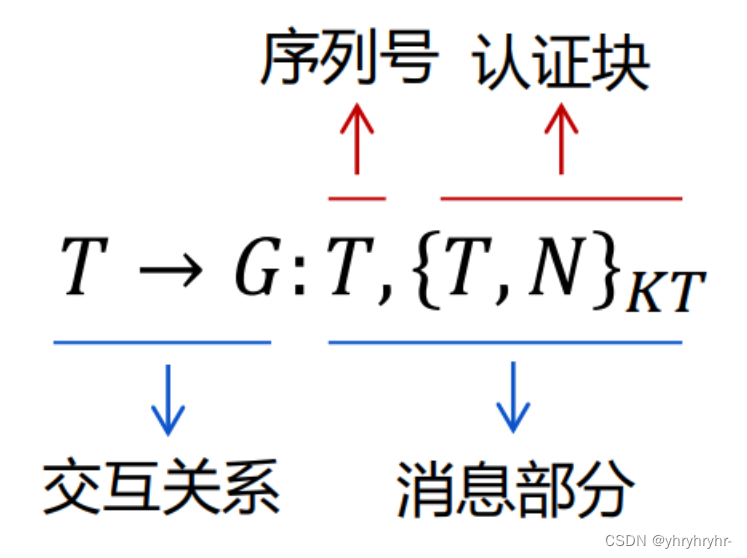
认证过程:
-
获取序号𝑇
-
解密 {𝑇, 𝑁}
-
验证 𝑇
-
验证 𝑁
Nonce的实现上:
-
随机数:伪随机函数,但实际可能存在规律,规律破解则协议不安全
-
计数器:协议未完成(或攻击)导致不一致
-
从第三方收到的随机质询:如何获得?网络是否鲁棒/可靠?
质询/响应协议:
认证方发送质询(随机数) <-----> 被认证方发送认证块(包括质询随机数)
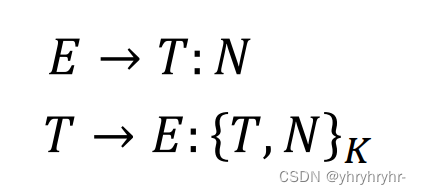
口令生成器:
-
登录界面提供一个随机数
-
将该随机数与PIN一同输入口令生成器, 得到登录口令
-
键入登录口令

IFF协议(Identify Friend or Foe):雷达向战机发出质询,战机必须回应正确应答,否则会被当做敌机。
3.2 安全协议攻击
3.2.1 重放攻击
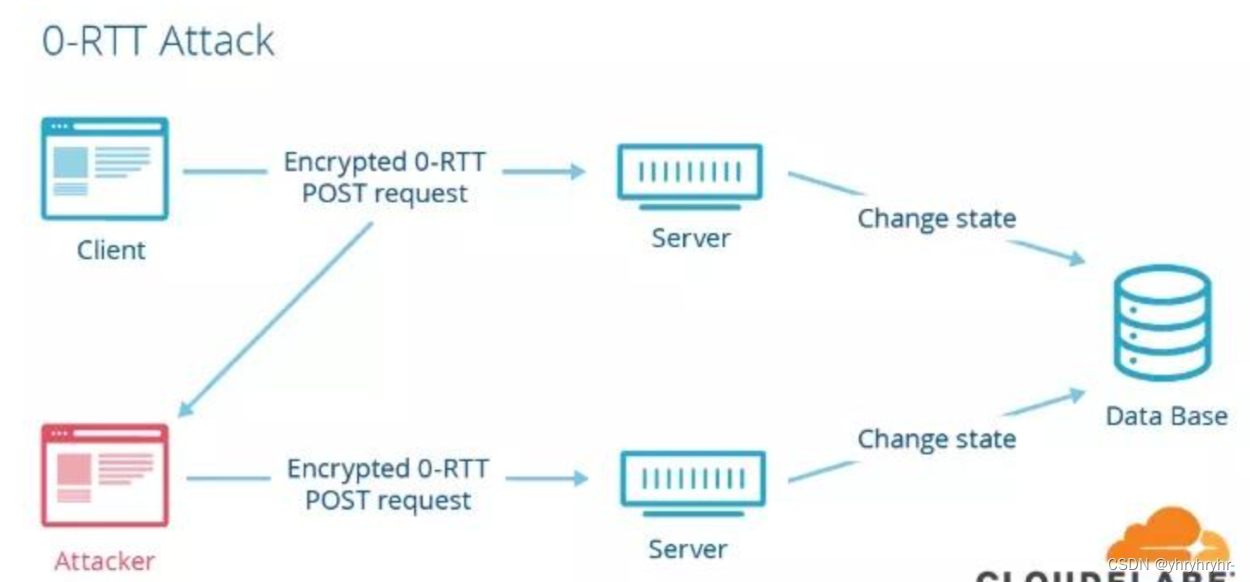 例如车钥匙远程开门,攻击者使用抢夺器获取开锁器的广播并重放。
例如车钥匙远程开门,攻击者使用抢夺器获取开锁器的广播并重放。
重放攻击的防御方式即是加入时间戳,使得信号有一个有效期。
3.2.2 中间人攻击
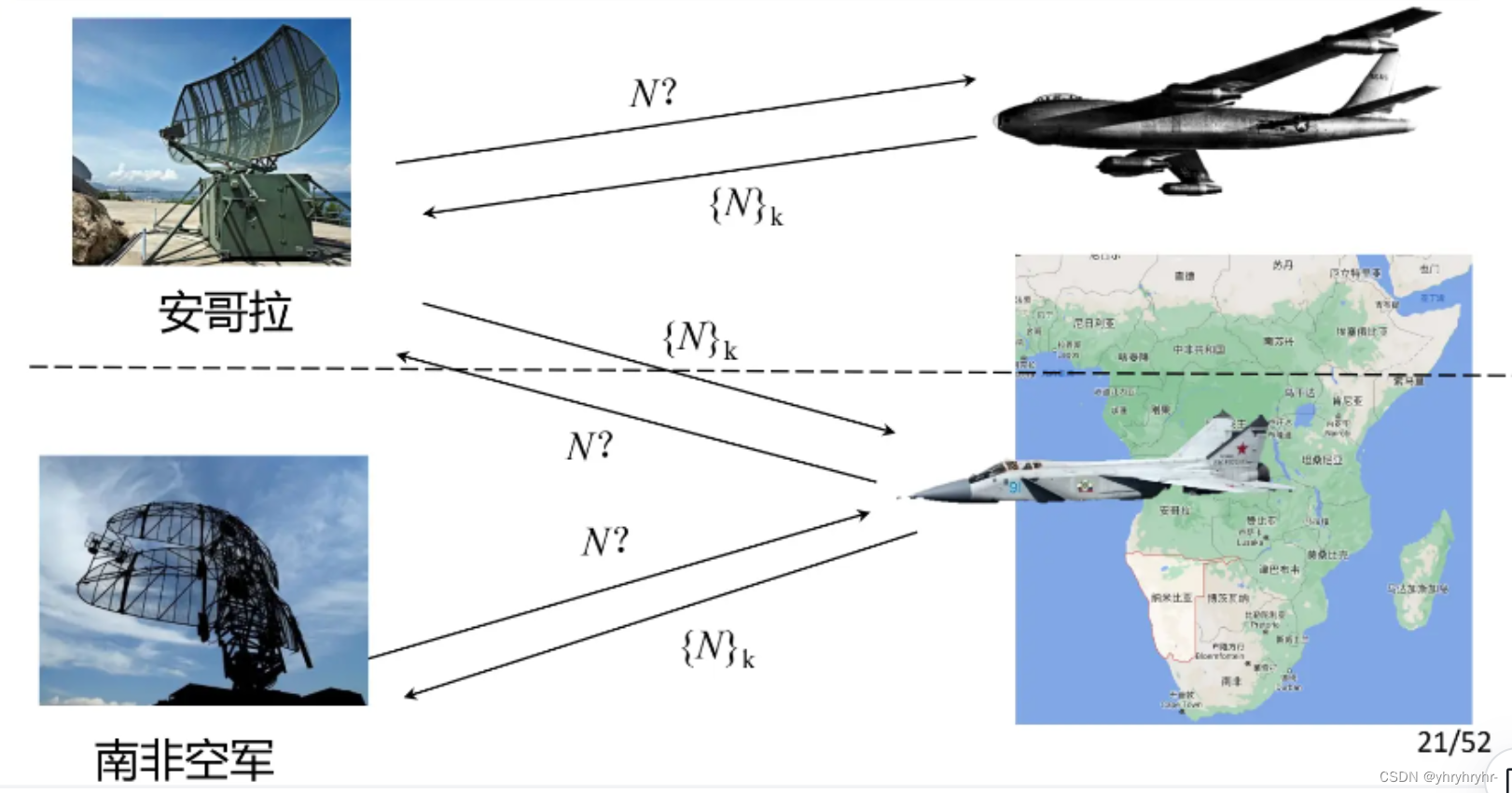
如上图,白飞机为敌机,黑飞机为战斗机。安哥拉服务器向战斗机发出质询,战斗机用密钥K加密N,返回给服务器{N}_k。南非空军向敌机质询时,由于敌机没有密钥K,所以将密钥K转发给安哥拉服务器,安哥拉服务器返回的{N}_k再转发给南非空军服务器,敌机即可认证战斗机身份。
中间人攻击很好的防御方式即使用加密技术,让中间人拿不到任何有效信息。或者使用安全套接字或者传输层安全协议,保护网络通信安全性。
3.3 密钥分配协议
3.3.1 基本密钥分配
A、B想要进行通信,A即向S发送A和B。服务器返回,T是时间戳。
A通过K_{AS}解密第一块,获得K_{AB},将第二块消息和使用K_{AB}加密后的通信消息M发给B。B用自己的K_{BS}解密,获得K_{AB},将消息用K_{AB}解密出来。
但A可以使用重放攻击获取服务器的信任,因此要增加时间戳。

3.3.2 Needham-Schroeder协议

3.3.3 Kerberos协议
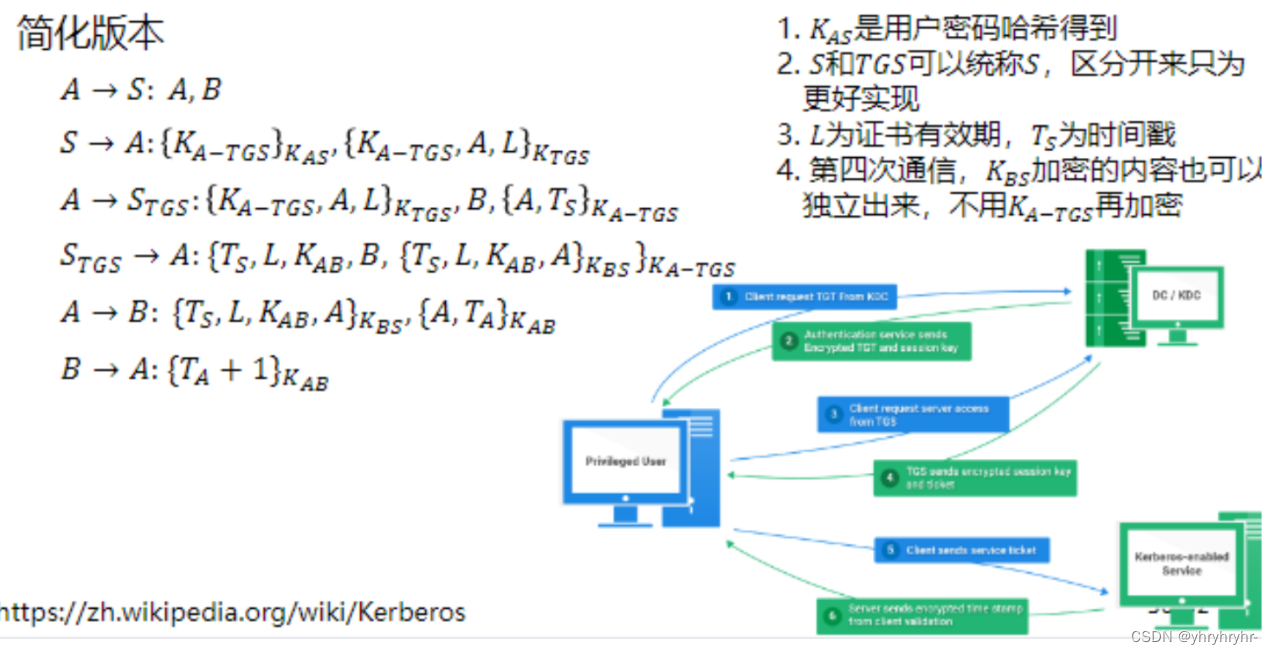
3.4 课后作业
1.阅读下述安全协议,并回答后续问题
A→S:A,NA,{A,B,NA,Password}`KAS`
S→A:{A,B,NA + 1,KAB}`KAS`
S→B:{A,B,NA + 2,KAB}`KBS`
A→B:A,{A,B,NA + 2}KAB
B→A:{NA + 3}KAB3.4.1 问题1
请分析该协议的目的,以及如何实现了该目的。其中password是用户A在服务器S注册时预留的登录密码。
Step1:A→S:A,NA,{A,B,NA,Password}KAS
A向S发送自己的:标识符A、随机数NA、与S共享的密钥KAS加密的消息。
加密消息中包含:用户A的标识符、用户B的标识符、随机数NA、用户A在服务器S注册时预留的登录密码。
Step2:S→A:{A,B,NA + 1,KAB}KAS
服务器S收到A发送的消息后,用KAS解密消息,验证密码是否正确。
如果密码正确,服务器S生成一个新的随机数NA+1,并用KAS加密消息{A,B,NA+1,KAB},将其发送给A。A收到后用KAS解密消息。
Step3:S→B:{A,B,NA + 2,KAB}KBS
服务器S再生成一个新的随机数NA+2,并使用自己与B共享的密钥KBS加密消息{A,B,NA+2,KAB},将其发送给B。B收到后用KBS解密消息。
Step4:A→B:A,{A,B,NA + 2}KAB
用户A收到服务器S的消息后,用KAS解密消息,得到新的随机数NA+1和A与B的共享密钥KAB,向B发送A的标识符、用KAB加密后的消息{A,B,NA+2}。
Step5:B→A:{NA + 3}KAB
用户B收到用户A的消息后,使用与A共享的密钥KAB解密消息,得到随机数NA+2,并向A发送加密后的消息{NA+3}KAB,表示已经收到并成功解密了消息。
分析后不难看出,整个协议的目的即为:在服务器S的帮助下,让A、B之间能够进行通信。
-
首先,A发送给服务器一段消息,其中包含可以验证身份的密码;
-
接着,如果密码正确服务器会回给A
KAB,同时也会把KAB发送给B一份。 -
然后,A向B发送使用
KAB加密后的密文NA + 2,B回给AKAB加密后的密文NA + 3,这样就证明了AB彼此间能够安全的通信。
3.4.2 问题2
如果服务器S受到了脱库攻击影响,用户的password泄露了,会带来什么影响?
如果是服务器受到了脱库攻击,并不会造成很严重的问题。因为正常人的服务器里,密码都不会存明文。即便是最简单的哈希加密,服务器里也只会存哈希加密后的明文,攻击者很难从中获得用户的私钥。
第四章 访问控制
4.1 概念
访问控制是在身份认证的基础上,依据授权对提出的资源访问请求加以控制,他是系统安全防范和保护的主要策略,它可以限制对关键资源的访问,防止非法用户的侵入或合法用户的不慎操作所造成的破坏。
4.2 控制访问三要素
-
客体(Object): 接受其他实体访问的被动实体。可以被操作的信息、资源、对象都可以认为是客体,例如信息、文件,网络硬件设施。
-
主体(Subject): 提出资源访问请求或要求的实体。 用户或其它任何代理用户行为的实体,例如计算机资源,如管理员、合法用户。
-
控制策略(Policy):确定主体是否对客体拥有访问能力的规则。 从数学角度来看,访问控制本质上是一个矩阵,行表示资源,列表示用户,行和列的交叉点表示某个用户对某个资源的访问权限(读、 写、执行、修改、删除等)。
4.3 控制访问基本原则
最小特权原则:最小特权原则是指应限定网络中每个主体所必须的最小特权,确保可能的事故、错误、网络部件的篡改等原因造成的损失最小。
多人负责原则:即授权分散化,对于关键的任务必须在功能上进行划分,由多人来共同承担,保证没有任何个人具有完成任务的全部授权或信息。
职责分离原则:指将不同的责任分派给不同的人员以期达到互相牵制,消除一个人执行两项不相容的工作的风险。例如收款员、出纳员、审计员应由不同的人担任。
4.4 访问控制每层应用
-
应用层:可实施灵活,丰富和复杂的安全策略
-
中间件:维护基本的保护特性(簿记系统,数据库系统)
-
操作系统:对操作系统级的资源实施保护(文件,网络等)
-
硬件:进程的物理保护(处理器和内存管理硬件)
4.5 经典访问控制策略
4.5.1 自主访问控制
允许用户自己对客体将已有的权限赋予给其他主体,也可以撤销自己赋予给其他主体的权限。
矩阵结构分为三个主要的表:
-
访问控制矩阵
-
访问控制列表
-
权能表
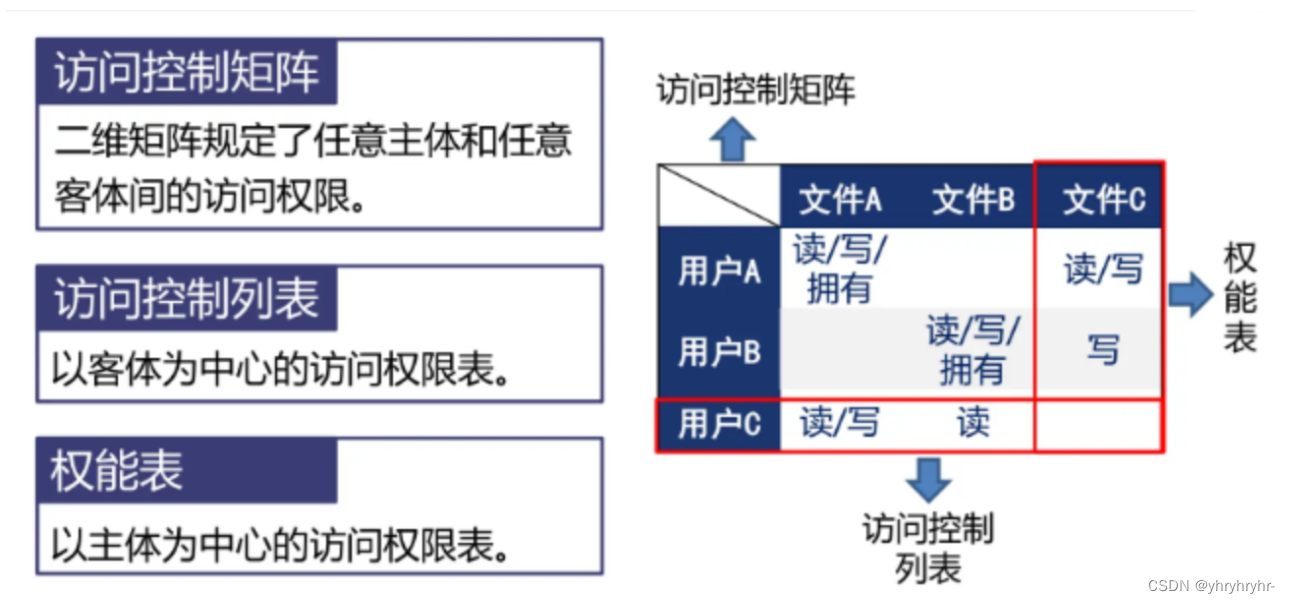
矩阵的局限性:
-
大小为主体数量×客体数量,容易造成空间浪费
-
搜索权限效率低
-
扩展性差
优化办法or解决办法:
-
按行和列进行矩阵拆分
-
将同类用户分为一个用户组
4.5.2 强制访问控制
见第五章
4.6 课后习题
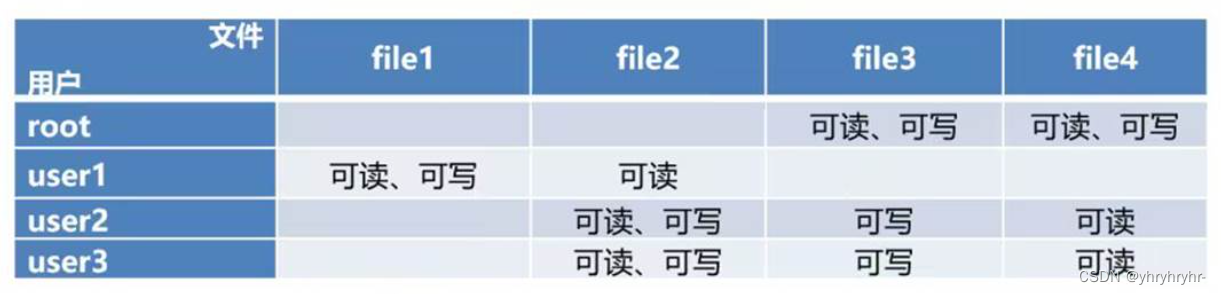
4.6.1 访问控制矩阵
为了保证数据安全,系统管理员可对不同的文件针对不同的用户/用户组设置不同的权限。现假设系统中的不同用户/组对不同文件的权限如下矩阵。请据此回答问题。
-
请结合上述矩阵,指出主体和客体在这里分别指什么。
-
采用访问控制矩阵进行权限管理,当文件、用户数量较多时,存在什么问题?
-
针对2中的问题,采用不少于2种方式改进本题中的访问控制矩阵,并画出改进后的访问控制矩阵。
Q1:矩阵中的主体和个体:
主体:root、user1、user2、user3
客体有:file1、file2、file3、file4
Q2:访问控制矩阵进行权限管理的局限性:
-
大小为主体数量×客体数量,容易造成空间浪费
-
搜索权限效率低
-
扩展性差
Q3:在用户、文件数量越来越多时,访问控制列表(ACLs)、基于角色的访问控制(RBAC)是更好的权限管理方法。
访问控制列表(ACLs)是一种将资源(如文件、目录或网络对象)和用户权限之间的关系存储在列表中的方法。它为每个资源分配了一个列表,其中包含了所有被授权访问该资源的用户和他们的权限。这样,管理员只需要针对每个资源设置权限,而无需在整个系统中进行权限分配。这可以减少权限管理的复杂度,并提高安全性。
一个用户对多个文件——>全能表;一个文件对多个用户——>访问控制列表。
基于角色的访问控制(RBAC)是一种将用户和权限之间的关系存储在角色上的方法,而不是直接存储在用户上。这种模型将用户分组为不同的角色,并将权限分配给这些角色,而不是直接分配给用户。当用户加入或离开某个角色时,他的权限也会随之改变,从而简化了权限管理过程。
4.6.2 权能表
| 用户\文件 | file3 | file4 |
|---|---|---|
| root | 可读、可写 | 可读、可写 |
| 用户\文件 | file1 | file2 |
|---|---|---|
| user1 | 可读、可写 | 可读 |
| 用户\文件 | file2 | file3 | file4 |
|---|---|---|---|
| user2 | 可读、可写 | 可写 | 可读 |
| 用户\文件 | file2 | file3 | file4 |
|---|---|---|---|
| user3 | 可读、可写 | 可读 | 可读 |
4.6.3 访问控制列表
| 文件\用户 | user1 |
|---|---|
| file1 | 可读、可写 |
| 文件\用户 | user1 | user2 |
|---|---|---|
| file2 | 可读 | 可读、可写 |
| 文件\用户 | root | user2 | user3 |
|---|---|---|---|
| file3 | 可读、可写 | 可写 | 可写 |
| 文件\用户 | root | user2 | user3 |
|---|---|---|---|
| file4 | 可读、可写 | 可写 | 可读 |
4.6.4 RBAC
按照算法思想,将权限存储在角色,而非直接存储在用户上,再给每个用户分配一个角色实现权限管理。我们不难发现可以将user2、user3当做一个角色,将root、user1各设一个角色,改进后的矩阵如下:
| 角色\文件 | file1 | file2 | file3 | file4 |
|---|---|---|---|---|
| root | 可读、可写 | 可读、可写 | ||
| user1 | 可读、可写 | 可读 | ||
| 角色组(user2、user3) | 可读、可写 | 可写 | 可读 |
4.7 常见突破访问控制手段
-
SQL注入
-
缓冲区溢出漏洞
第五章 多级安全
建立安全模型的方法:
-
信息流模型
-
访问控制模型
5.1 BLP模型
5.1.1 模型构建
不能下写、不能上读,保持数据的机密性。
 例子:军事、商务、外交的机密性强场景。下级可以给上级进行汇报,但下级不能读取上级的作战计划。
例子:军事、商务、外交的机密性强场景。下级可以给上级进行汇报,但下级不能读取上级的作战计划。
5.1.2 隐通道问题
时间隐通道:高密存在一个木马病毒希望发给低密。每隔时间固定间隔访问低密的文件夹,访问即发送1,不访问发送0
存储隐通道:通过信道指针的移动,访问指针左边空间为1,访问右边为0
5.2 Biba模型
5.2.1 模型构建
不能上写、不能下读,保持数据的完整性。
 例子:铁路旅客信息系统可以读取轨道信令但不可写
例子:铁路旅客信息系统可以读取轨道信令但不可写
第六章 多边安全
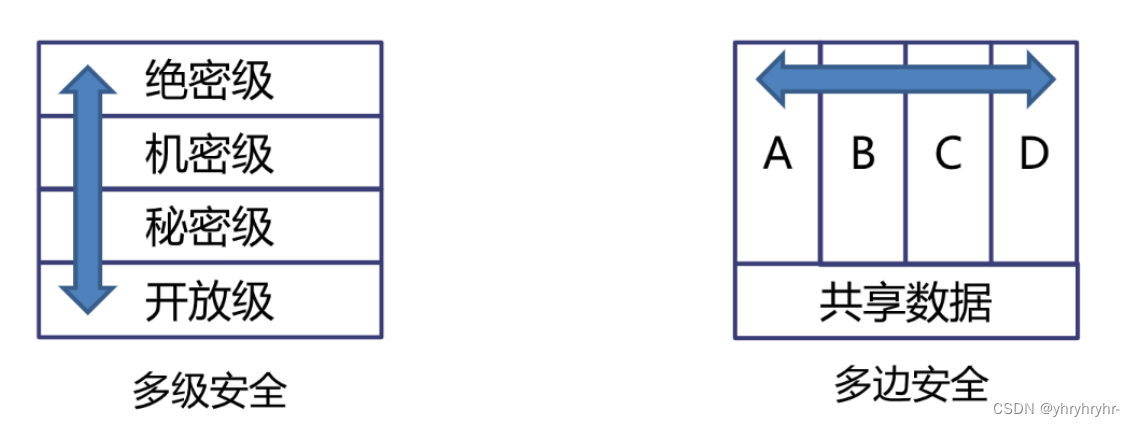
6.1 概念
-
多边安全(Multilateral Security):多边安全是指通过国际合作、协商和机制等多方参与的方式来维护国际安全。在多边安全体系中,各国通过共同努力来解决安全问题,建立相互信任和合作的关系。它强调各国之间的互利共赢和平等对话,以维护共同的安全利益。
-
多级安全(Multilevel Security):多级安全是指在一个系统或网络内,根据用户的权限和需要,将信息进行不同级别的分类保护,并设置相应的访问控制策略以确保信息的机密性、完整性和可用性。多级安全的主要目标是防止敏感信息泄露、数据篡改和未经授权的访问,以保护系统和数据的安全。
综上所述
-
多边安全是国际层面关注的安全问题合作与协商
-
多级安全则是系统或网络内部的信息保护问题,着重于信息的保密性、完整性和可用性。
6.2 网格模型
为什么Kevin既可以访问左边,但不能访问右边?
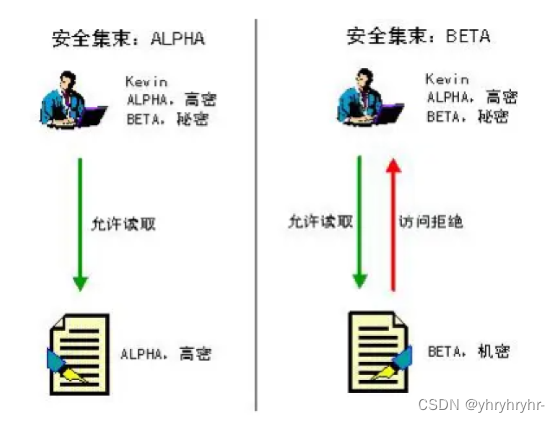
对于Kevin,在Alpha组中是高密权限,在Beta组中是秘密权限。所以,Kevin可以在左边访问高密权限,但不能在右边访问低密权限,这完全取决于权限的高低。
6.3 长城模型
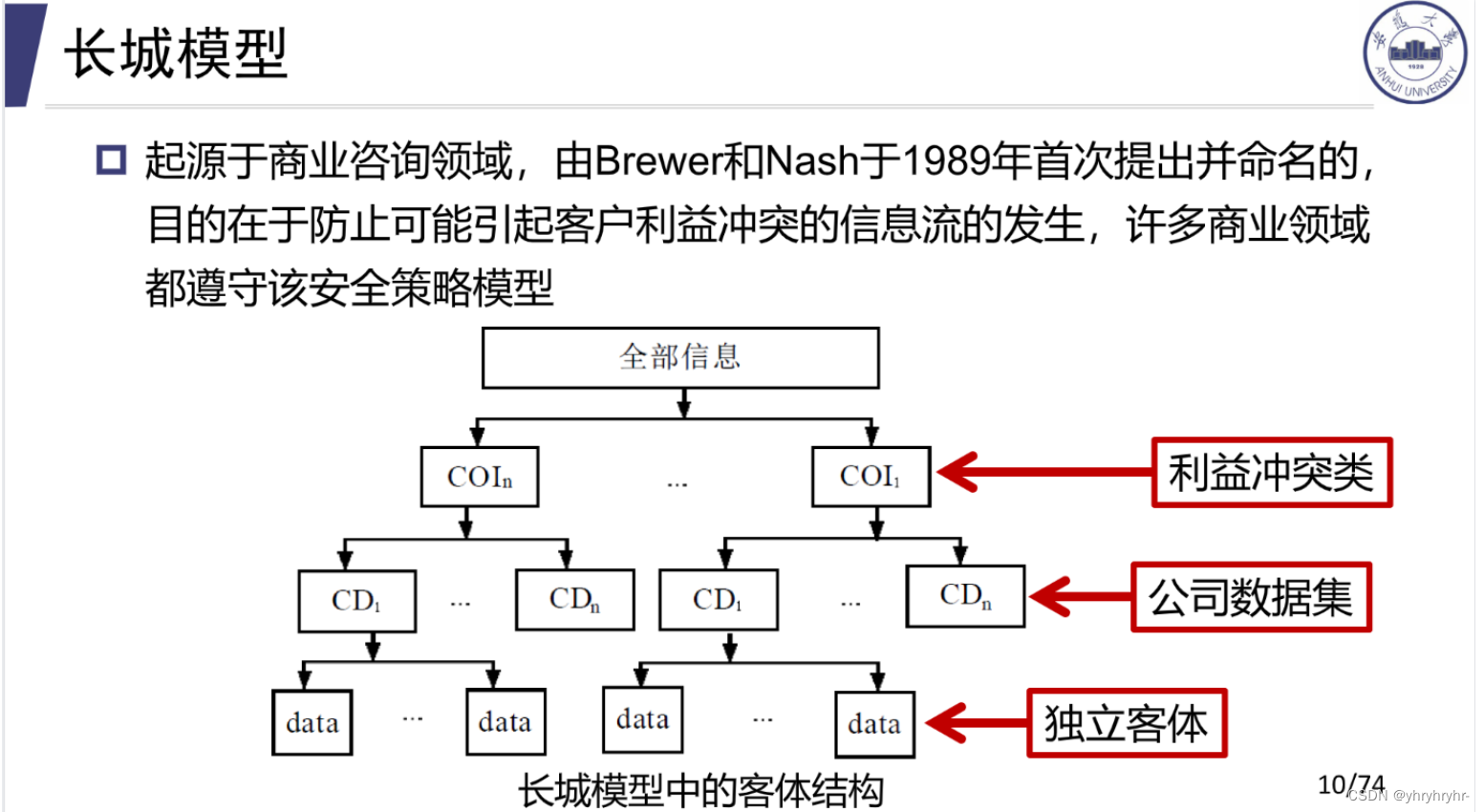
-
利益冲突类=兴趣冲突组=COI
-
数据集=公司=CD
-
独立客体=数据=data
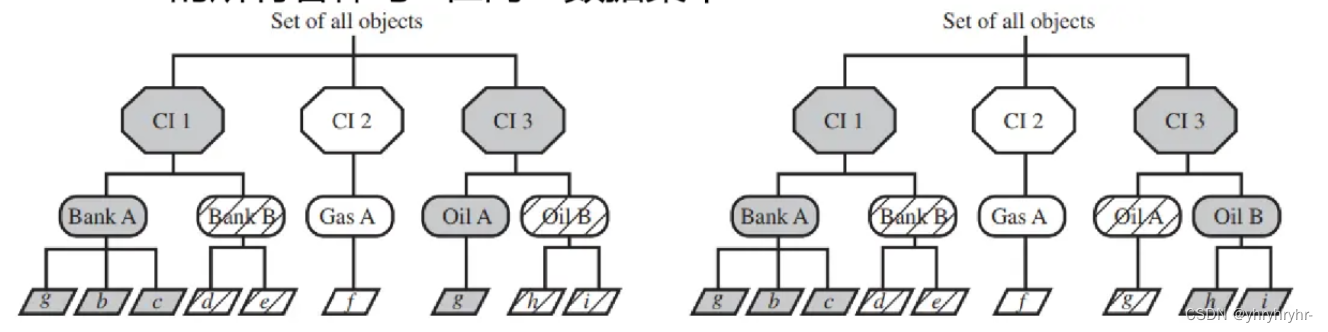
-
读规则:同一个利益冲突类中,只能访问一个数据集。
-
写规则:全部加起来,只能访问一个数据集。
缺点
-
在一个冲突类下,最多只能访问一个数据集,现实例子是竞业禁止。
-
第二个缺点是主体相关性没有约束,即对不同主体没有管控。如果两个具有利益相关的用户,访问同一个冲突类中的不同数据集信息,就会产生信息泄露。
第七章 分布式安全
7.1 时钟
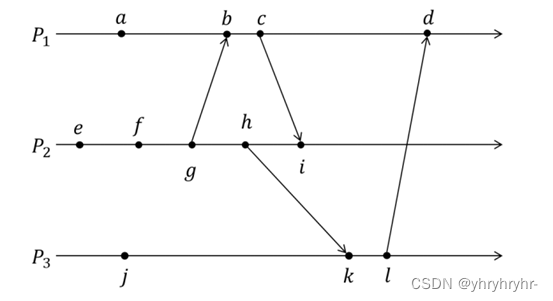
7.1.1 作业题目
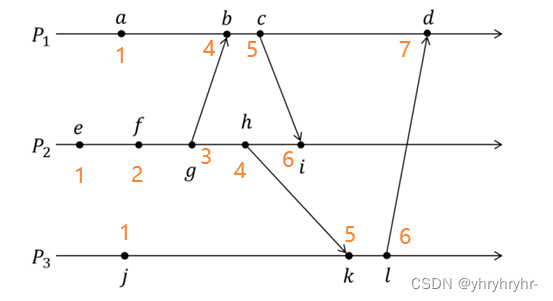
图中P1、P2、P3是相互通信的进程,a、b...l是分布在不同进程中的事件,分别按照Lamport时间戳算法的逻辑时钟和向量时钟,分别给出事件a、b...l的时间戳,并分析可以并发执行的事件。
7.1.2 逻辑时钟
逻辑时钟指的是分布式系统中用于区分事件的发生顺序的时间机制。 从某种意义上讲,现实世界中的物理时间其实是逻辑时钟的特例。Lamport logical clocks的实现:
每个进程Pi维护一个本地计数器Ci,相当于logical clocks,按照以下的规则更新Ci
每次执行一个事件(例如通过网络发送消息,或者将消息交给应用层,或者其它的一些内部事件)之前,将Ci加1
当Pi发送消息m给Pj的时候,在消息m上附着上Ci
当接收进程Pj接收到Pi的发送的消息时,更新自己的Cj = max{Cj,Ci}+1
逻辑时钟结果示意图如下:
7.1.3 向量时钟
Lamport 逻辑时钟算法中每个进程只拥有自己的本地时间,没有其他进程的时间,导致无法描述事件的因果关系。如果每个进程都能够知道其他所有进程的时间,是否就能够得到事件的因果关系了呢?为此,有人提出了向量时钟算法,在 Lamport 逻辑时钟的基础上进行了改良,提出了一种在分布式系统中描述事件因果关系的算法。
每个进程的VC可以通过以下规则进行维护:
进程Pi每次执行一个事件之前,将VCi[i]加1
当Pi发送消息m给Pj的时候,在消息m上附着上VCi(进程Pi的向量时钟)
当接收进程Pj接收到Pi的发送的消息时,先将自己的逻辑时钟VCj[j]加1,再更新自己的VCj[k] = max{VCj[k],VCi[k]} for k = 1 to N
向量时钟结果示意图如下:
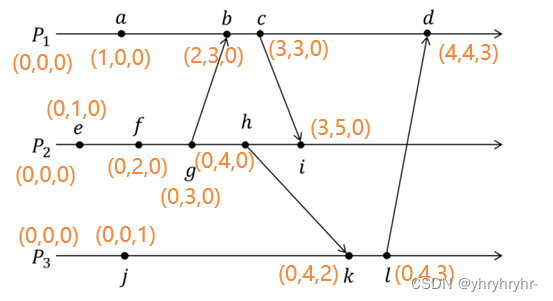
7.1.4 并发关系
-
a、e、j可以并发执行;
-
b、h可以并发执行;
-
c、k可以并发执行;
-
i、l可以并发执行
7.2 Lamport算法及其改进
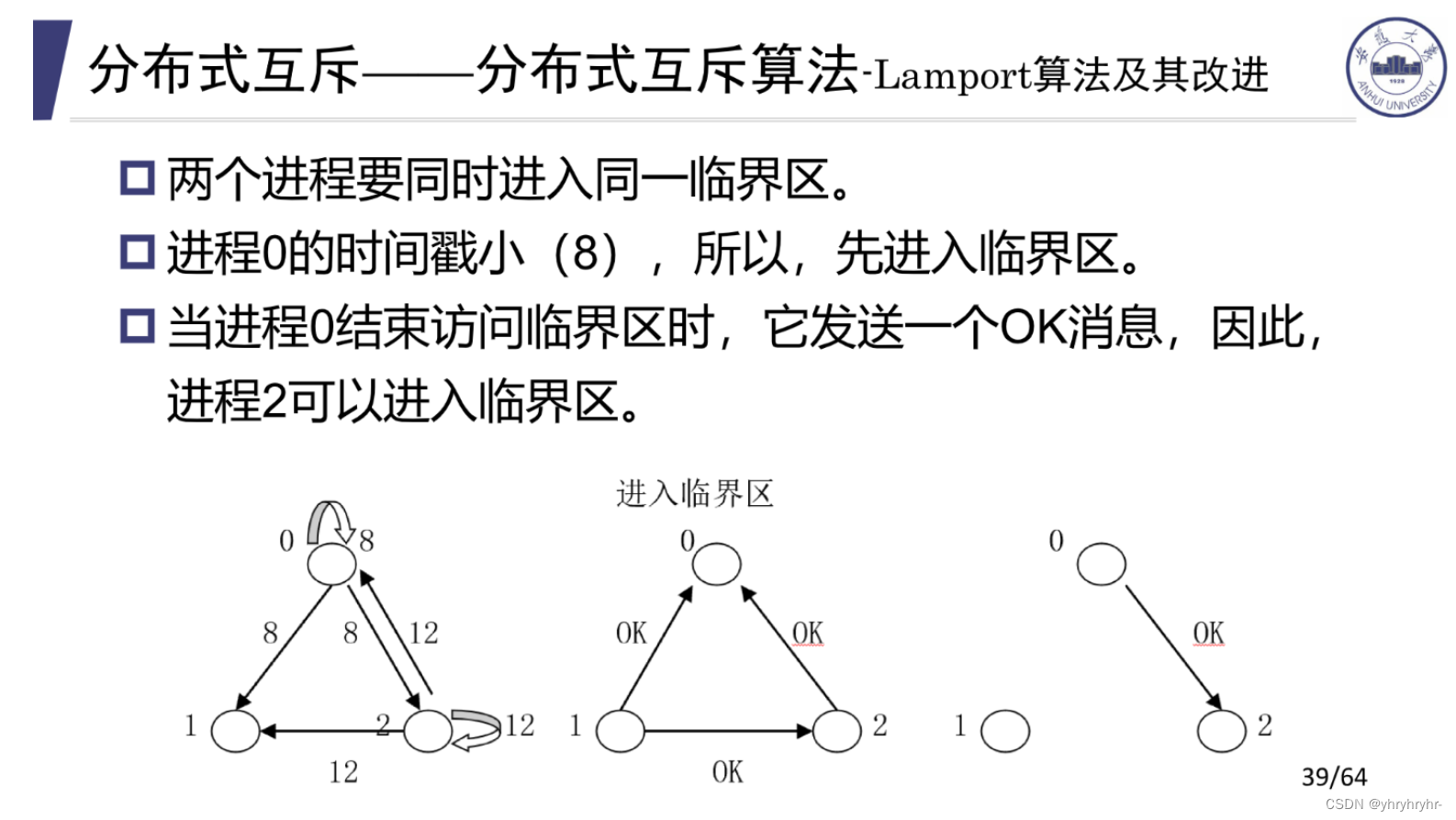
算法流程:
-
如果一个进程要进入临界区,就需要建立一个消息,发送给其他进程
-
当一个进程收到另一个进程发来的请求消息时,它根据消息中指定临界区的状态采取相应的措施
-
-
如果接收者不在临界区&不想进入临界区,回一个OK
-
如果接收者不在临界区&想进入临界区,则比较时间戳,优先时间戳小的进程(即如果对方小则回OK,自己小则将请求排队)
-
如果接受者已在临界区,将请求排队
-
-
一个进程发送完请求消息后,就一直等待所有进程回送OK消息,所有的OK消息都回送完毕它才可以进入指令临界区。
在上图的例子中:
-
0和2进程都请求访问临界区。0请求1&2,时间戳为8;2请求0&1,时间戳为12。
-
之后,1响应0进程OK,1响应2进程OK。由于12>8,2进程响应0进程OK。0进程将2进程的请求消息排队,这里0进程回返了所有OK,因此进入临界区。
-
0进程退出临界区,发送OK消息给要进入临界区的进程2,并将2进程的请求消息从队列移除。
7.3 广播和多播
-
广播
将消息告诉所有的机器,当机器接受到消息宿主不是自己时,那么他又会将消息再次广播给其他机器,当数据传递到宿主时,就会沿着广播过来的路径,一步步的往回传,传回拥有者。
多适用小型的局域网,广播一到两跳就差不多结束了,但是大型网络就容易出现泛洪,消息会容易不断兜圈形成风暴,让网络性能下降。
-
多播:
即组播,与广播不同的地方就是,消息传播给限定的一些邻居节点,即特定的多播组。
7.4 分布式散列表DHT
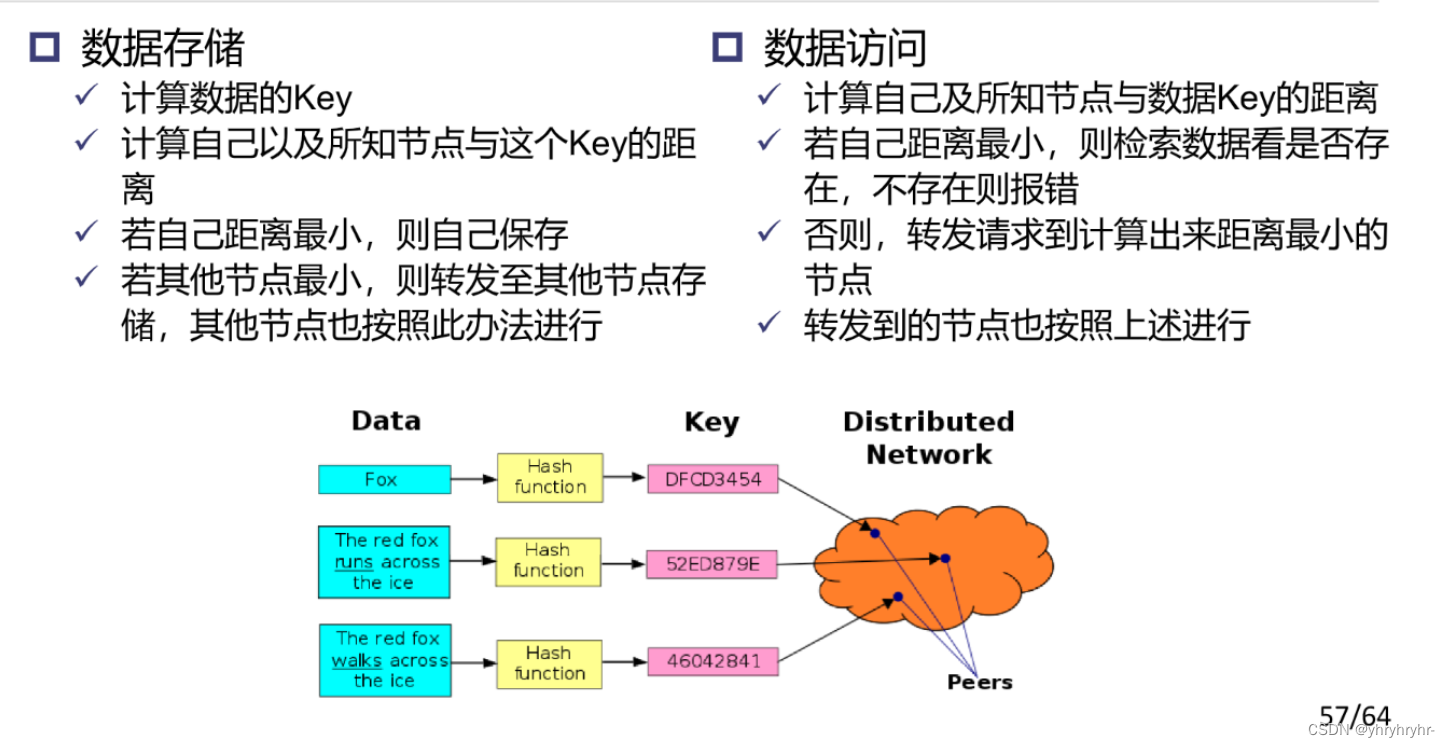
7.5 Chord环形散列表
可以理解为环形的DHT。散列表就是将数据进行哈希,并根据哈希值进行分块存储。为了保证散列表的查找效率,不是每个结点都存储数据,这样可以保证散列表的结构健康,不是很长也不是很宽,这些存储结点是人为预设的,由于不是每个结点都存储数据,所以数据存储在自己哈希值最邻近的存储结点中,这里的距离是按照顺时针计算,不可以逆向走。例如,2,3都会存储在结点4
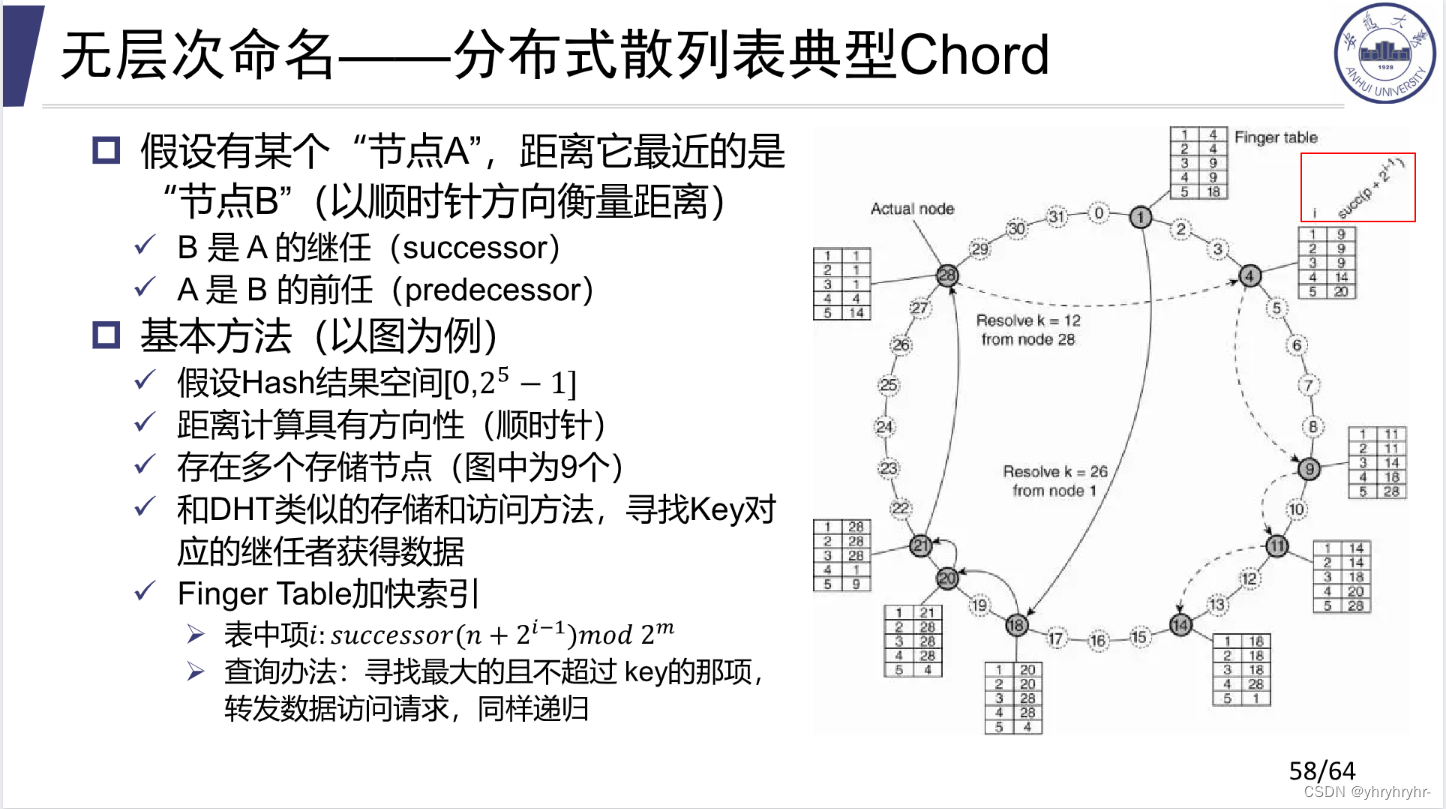 下面讲每个存储结点的具体数值怎样计算。1-5表示整个散列表以2为底的对数长度,这里是
下面讲每个存储结点的具体数值怎样计算。1-5表示整个散列表以2为底的对数长度,这里是。这些数值的目的是帮助某个哈希值快速找到自己对应的存储结点,下面以结点1为例:
| 表中项1 | successor(n+2^{i-1} \mod 2^m) | Finger table |
|---|---|---|
| 1 | 2 | 4 |
| 2 | 3 | 4 |
| 3 | 5 | 9 |
| 4 | 9 | 9 |
| 5 | 17 | 18 |
假设1结点进入了一个哈希值为26的,我们要在Finger table中找到最大且不超过的结点,这里是18,我们跳到18,同样的道理在18的Finger table中跳到20,接着是21。在21中我们没有再找到最大且不超过的(如果不能过0点),我们直接选择i=1的值,即跳到28。从结果来看,26应该在28结点存储,至此我们找到了哈希值为26的数据应该存储到结点28。
第八章 入侵检测
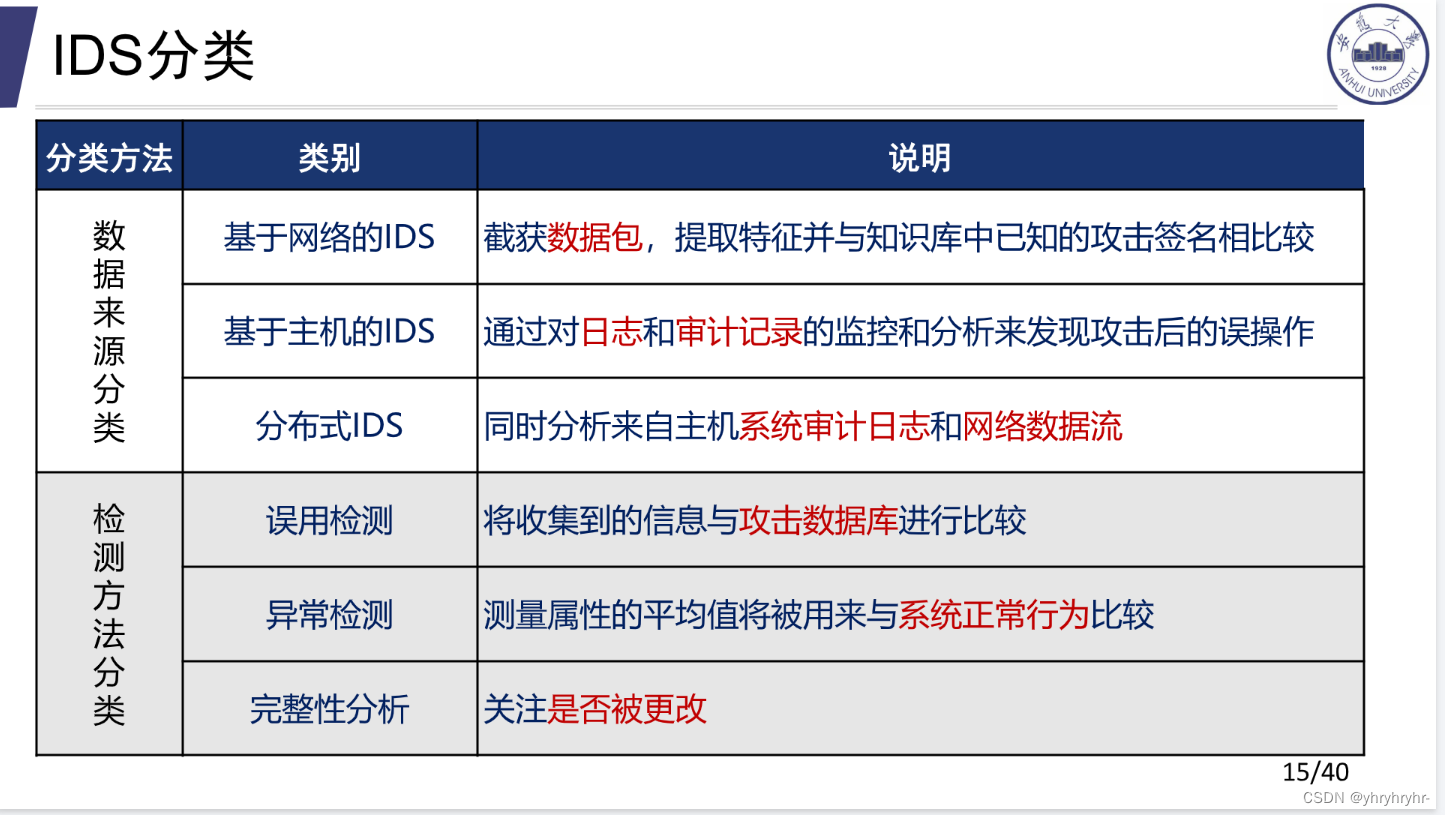
8.1 IDS分类
8.2 作业内容
为了保障系统安全,除了部署登录验证系统,通常还会部署入侵检测系统。问:
-
登录验证可阻碍未授权的访问,请结合入侵检测系统工作原理,分析为何还需要部署入侵检测系统。
-
简述基于主机的入侵检测和基于网络的入侵检测的区别;为检测病毒、木马等恶意代码所产生的入侵行为需要哪种类型的入侵检测系统?
-
假设某集团所有子部分对外的服务采用集团云服务的方式进行部署,并部署了相关入侵检测系统,其采用判断网络传输信息中是否存在
lcgi-bin/phf?来判断是否存在特定漏洞。请问,据此该分析入侵检测系统属于哪一类入侵检测系统,并说明理由。
8.3 问题1
部署登录验证系统可以阻止未经授权的访问,但仍然存在其他威胁和入侵行为的可能性。
攻击者可以使用各种技术手段绕过登录验证系统,如钓鱼、社会工程学攻击和密码破解等方式获取合法用户的凭据,从而以所谓合法身份入侵系统。此外,即使经过验证的用户登录系统,仍然可能从内部发起恶意行为,如尝试非法访问敏感数据、执行恶意代码或攻击其他系统组件等。因此即便有了登录验证,还是要部署一套完整的入侵检测系统。
入侵检测系统的工作原理是通过监视和分析系统中的网络流量、日志记录和其他活动,识别出与已知攻击模式和异常行为相关的指标。它使用预定义的规则、模型或算法来检测威胁,并及时发出警报或采取相应的措施来防御或应对入侵行为。
因此,尽管登录验证系统可以阻止未授权的访问,但入侵检测系统可以帮助发现已经成功登录系统的恶意用户或攻击者的活动。它可以检测到异常的行为模式、未经授权的访问尝试、恶意软件的存在以及其他潜在的威胁,从而提供了一层额外的保护,增强了系统的安全性。
8.4 问题2
基于主机的入侵检测和基于网络的入侵检测是两种不同的入侵检测方法,他们的主要区别在于监测的对象和数据源的不同。
-
基于主机的入侵检测系统(Host-based Intrusion Detection System,HIDS)通过监视主机上的操作系统、应用程序和日志等数据,来检测潜在的入侵行为。HIDS主要关注主机本身的安全,可以检测到在主机上运行的恶意软件、未经授权的访问、异常行为等。它可以分析主机的文件系统、注册表、日志文件等,以检测和识别异常或恶意活动,检测信息来自于主机的活动。
-
基于网络的入侵检测系统(Network-based Intrusion Detection System,NIDS)通过监视网络流量和数据包,来检测潜在的入侵行为。NIDS主要关注网络层面的安全,可以检测到网络中传输的恶意流量、入侵尝试和已知的攻击模式。它可以分析网络数据包的头部和负载,以检测和识别与已知攻击模式相匹配的数据包,检测信息来自于网络中的数据包。
实例:对于检测病毒、木马等恶意代码所产生的入侵行为,更适合使用基于主机的入侵检测系统(HIDS)。因为这种类型的入侵行为通常发生在主机上,HIDS可以监测主机上的文件系统和应用程序等,及时发现恶意代码的存在并进行报警、隔离、清除等操作。
8.5 问题3
该入侵检测系统可以被归类为基于网络的入侵检测系统(NIDS)。
该入侵检测系统采用判断网络传输信息中是否存在lcgi-bin/phf?来判断是否存在特定漏洞,表明该系统主要关注网络层面的安全,并通过分析网络流量来检测入侵行为。它可以检测是否有攻击者尝试利用特定漏洞进行入侵,以及是否有恶意的请求传输到目标系统。
因此,基于判断网络传输信息中是否存在特定漏洞的特征,该入侵检测系统可以被归类为基于网络的入侵检测系统(NIDS)。
第九章 银行与簿记系统
9.1 ATM机的三个认证协议
9.1.1 离线认证协议
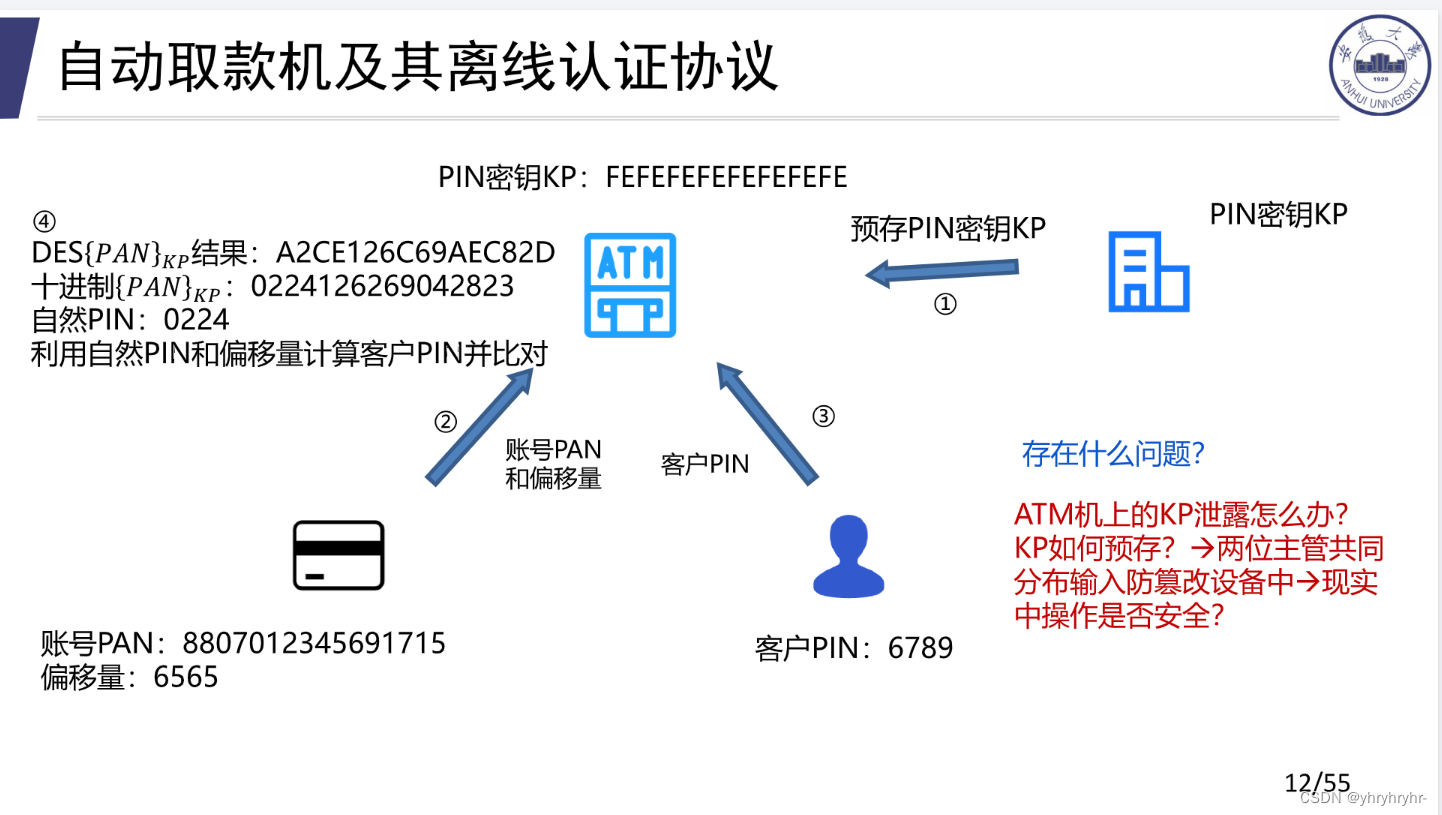
ATM机上KP泄露怎么办?
KP放在防篡改设备里,这样攻击者即使接入ATM机子电路,也无法从防篡改设备里获取KP的数值,如果有人故意破坏ATM机子,防篡改设备也能检测到ATM机子被破坏,这时防篡改设备就会删除ATM机子里的KP,防止KP泄露给攻击者。
KP如何预存?
一般KP是由经理两个人分别输入,这样保证KP不会被单个的人直接获取。
现实中操作是否安全?
不安全
-
比如人为行为,经理觉得尊严受损让KP由别的人输入,导致泄露
-
比如肩窥行为,在输入时被被人窃取
9.1.2 在线认证协议
在线认证过程:(相比于离线, 密钥KP的获取方式和ATM机加密方式不同)。多家银行之间跨行交易,每家银行间都需要互通密钥,为了解决密钥膨胀的问题和信任问题,所以通过银联(第三方的密钥中介)解决。
9.1.3 跨行认证协议
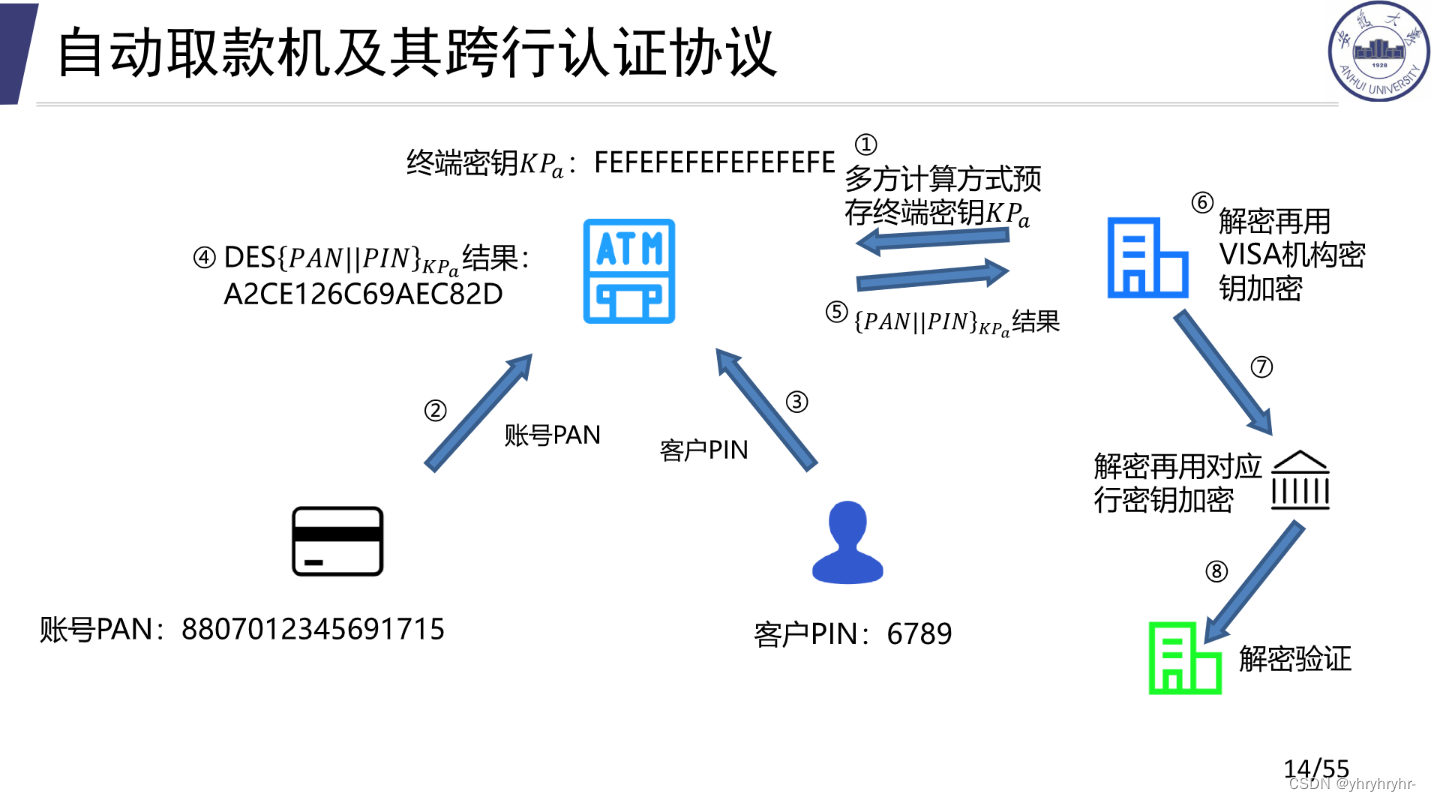
在线认证过程:(相比于在线就是后面验证环节多套了几个娃)
解密后,使用VISA的密钥进行加密,发给VISA机构。VISA机构解密后,用对应银行的密钥进行加密。最后一步,目标银行用自己的私钥进行解密,即完成了跨行认证。
思考题
相比较离线协议,在线协议和跨行认证,安全假设有变化吗?
在线协议基本没有变化,还是要存KP,银行自己本身还有防篡改设备。跨行认证由于引入了银联/VISA这种中间第三方以及其他银行,安全假设有变化,一般认为银联是可信的监管机构。
上述协议安全吗?
加入防篡改设备的情况下是比较安全的。但是防篡改设备要求的前置安全假设较强,有的时候会存在工作异常,引入过多设备导致受攻击的面会越来越多。
为什么不采用公钥基础设施?
这里的协议都是DES加密等方式,不采用公钥基础设施的原因,不能从信安的角度去考虑,因为DES的提出的年份由于和公钥密码学差不多,都是1990年,当时还没有成熟的公钥密码学。
跨行跨组织跨国交易如何做?(信任更难构建)
这里主要需要解决信任的问题,因为几个国家打个仗信任就破裂了
这些交易其实一直都存在,但是耗时耗力,交易过程比较冗长。
这里做法是在国家之外构建了一个单独的机构,用于联系各个国家的信任。
9.2 智能卡数据验证
9.2.1 静态数据验证
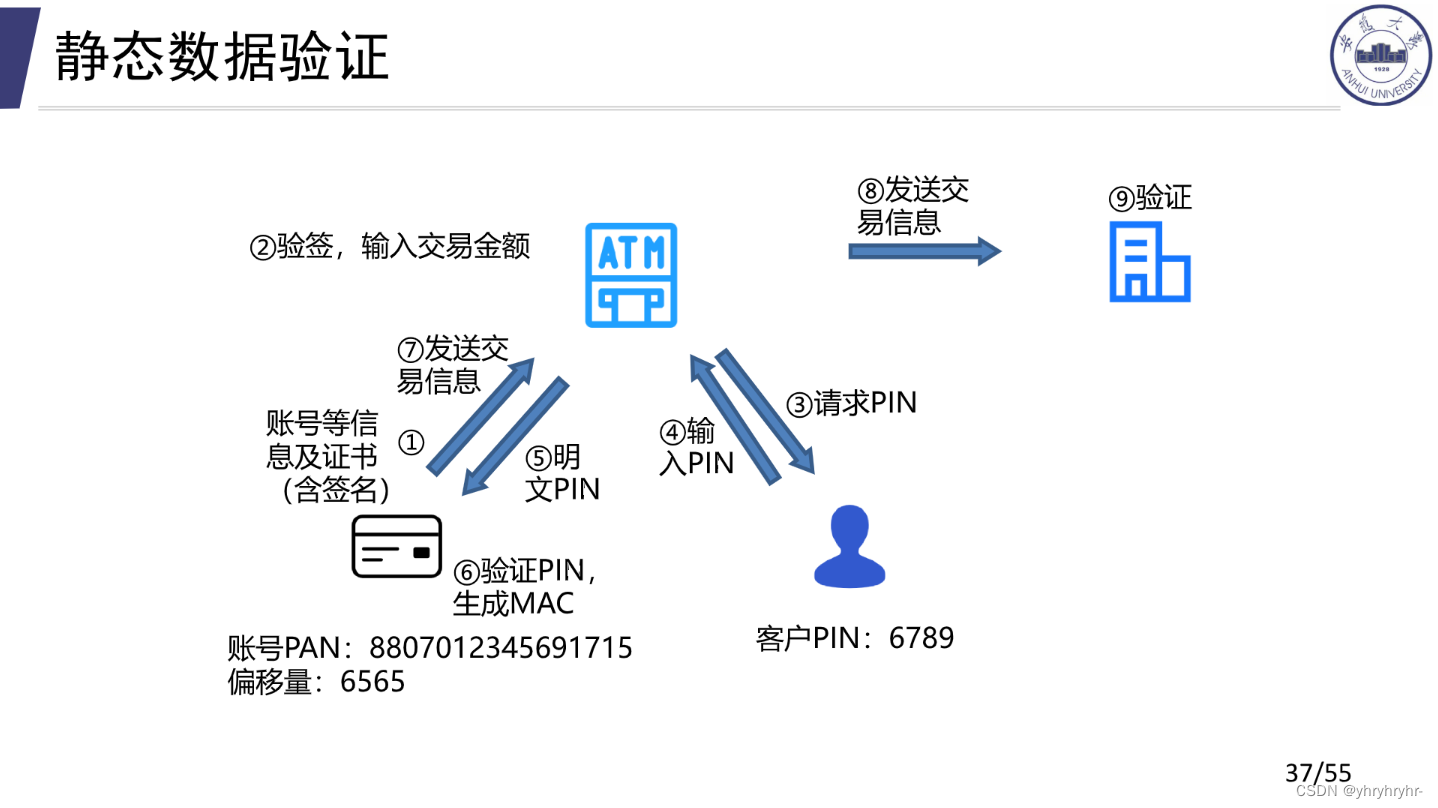 无法防御重放攻击、中间人攻击和无PIN攻击。
无法防御重放攻击、中间人攻击和无PIN攻击。
9.2.2 动态数据验证
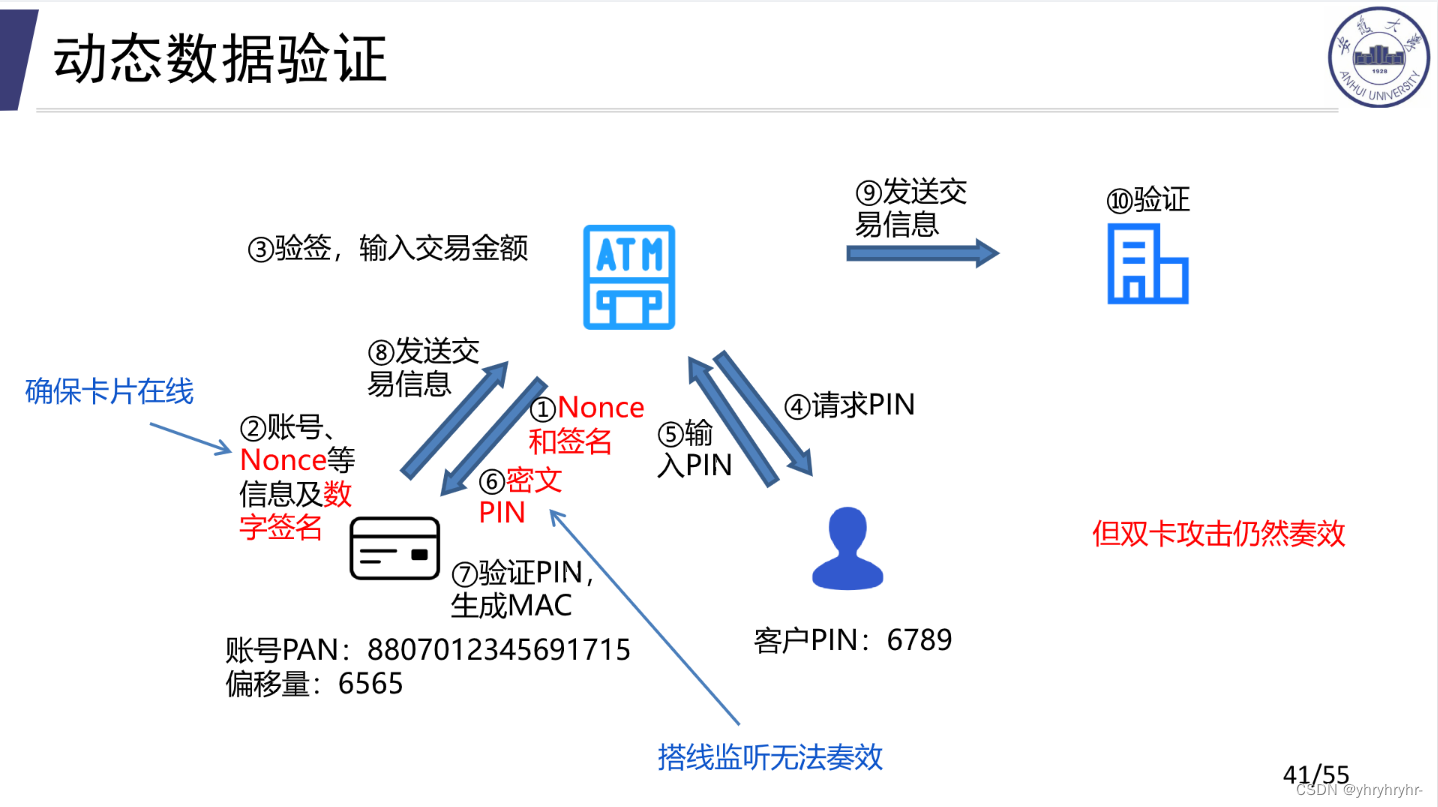 动态数据验证,可以靠Nonce随机数来保证卡片始终在线,抵御重放攻击,并且ATM机与终端传输使用密文PIN(TLS加密),导致搭线监听无效,抵御中间人攻击。
动态数据验证,可以靠Nonce随机数来保证卡片始终在线,抵御重放攻击,并且ATM机与终端传输使用密文PIN(TLS加密),导致搭线监听无效,抵御中间人攻击。
9.2.3 混合数据验证
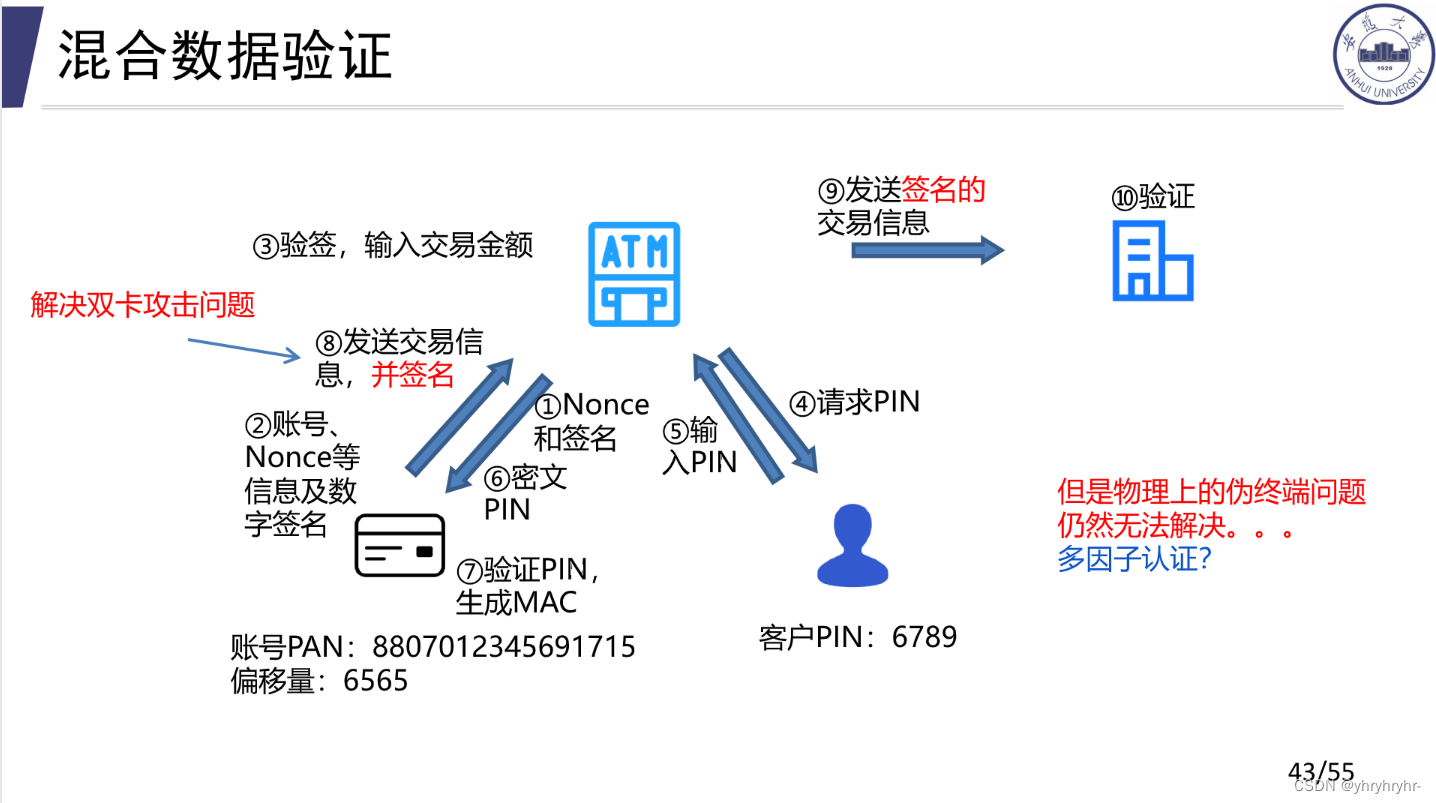 混合数据验证则在此基础上,在⑧⑨环节加入了签名,以此让认证(第一阶段)和转账(第二阶段)关联起来,保证始终是一张卡进行操作
混合数据验证则在此基础上,在⑧⑨环节加入了签名,以此让认证(第一阶段)和转账(第二阶段)关联起来,保证始终是一张卡进行操作
9.3 无PIN攻击
他的本质上就是中间人攻击。
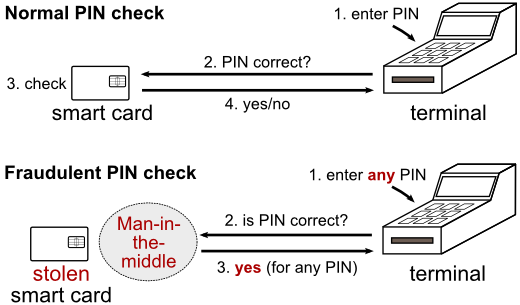
图片的上半部分是正常的PIN验证,下半部分是攻击手段。攻击者使用中间人攻击,给右边的终端发送"PIN正确"的消息,给左边的银行卡发送"没有收到PIN"的消息,卡会认为这个刷卡机不支持PIN支付验证,因此选择卡的签名验证或者干脆不验证。终端认为PIN验证成功(因此生成零字节),卡认为没有尝试(因此将接受零字节),就可以成功蒙混过关。

















 2062
2062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









