







目录
一、图的基本概念与术语
1.1 基本概念与特点
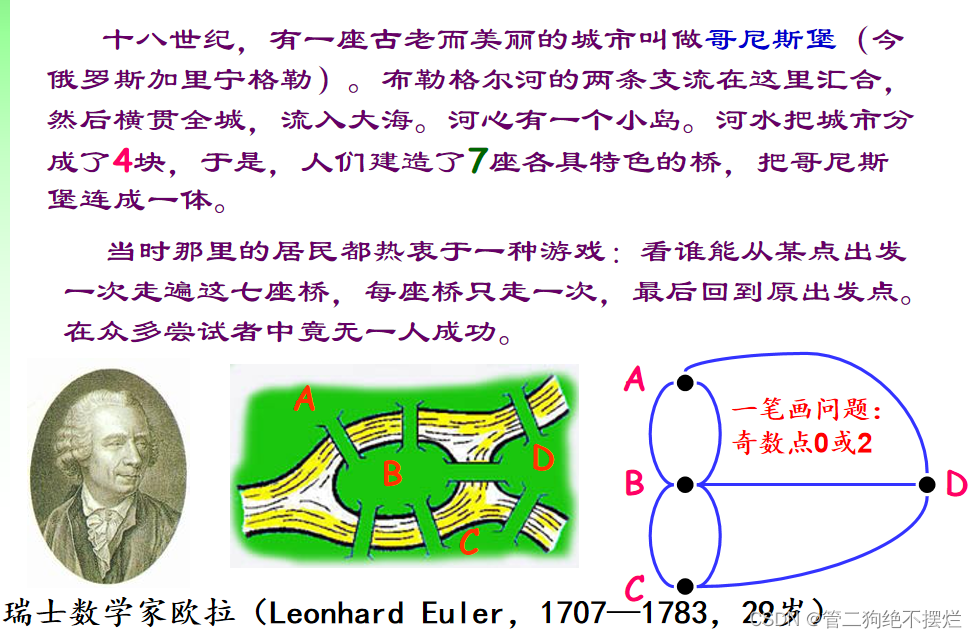
图1.1-1 图论的起源(了解)

图1.1-2 图的应用实例(了解)
(1)基本定义
1. 图(Graph):由两个集合V(G)和E(G)组成,记为G=(V,E)
其中:
- V(G)是顶点的非空有限集
- E(G)是边的有限集合,边是顶点的有序对或无序对,E(G)可以是空集,如果为空则图没有边。
2. 有向图(Digraph):由两个集合V(G)和E(G)组成
其中:
- V(G)是顶点的非空有限集
- E(G)是有向边(即弧)的有限集合,弧是顶点的有序对,记<v,w>,v为弧尾(Tail),w为弧头(head)。
3. 无向图(Undigraph):由两个集合V(G)和E(G)组成
其中:
- V(G)是顶点的非空有限集
- E(G)是边的有限集合,边是顶点的无序对,记(v,w)或(w,v),并且(v,w)=(w,v)
举例如下:G1为有向图,G2为无向图

图1.1-3 有向图和无向图实例
(2)相关术语
- 有向完全图:n个顶点的有向图最大边数是n(n-1);
- 无向完全图:n个顶点的无向图最大边数是n(n-1)/2;
- 权:每条边都可以标上具有某种含义的数值该数值称为该边的权值;
- 网:边上带有权值的图;
- 子图:设有两个图G = (V,E)和G' = (V',E'),若V'是V的子集,且E'是E的子集,则称G'是G的子图。若有满足V(G')=V(G)的子图G',则称其为G的生成子图。(注意:并非V和E的任何子集都能构成G的子图,这样的子集首先要满足图的定义);
- 邻接点:顶点v和顶点w之间存在一条边,则称v和w互为邻接点;边(v,w)和顶点v和w相关联;
- 顶点的度:无向图中,顶点的度为与每个顶点相连的边数;有向图中,顶点的度分成入度与出度;入度:以该顶点为头的弧的数目;出度:以该顶点为尾的弧的数目;
- 路径——若从顶点vi经过若干条边能到达vj,称顶点vi和vj是连通的,又称顶点vi到vj有路径。
- 路径长度——沿路径边的数目或沿路径各边权值之和
- 回路——第一个顶点和最后一个顶点相同的路径
- 简单路径——序列中顶点不重复出现的路径
- 简单回路——除了第一个顶点和最后一个顶点外,其余顶点不重复出现的回路;
- 连通——从顶点V到顶点W有一条路径,则说V和W是连通的
- 连通图——图中任意两个顶点都是连通的图
- 连通分量——非连通图的每一个连通部分
- 强连通图——有向图中,如果对每一对Vi,Vj,从Vi到Vj 和从Vj到 Vi都存在路径,则称G是强连通图

图1.1-4 相关术语实例(一)

图1.1-5 相关术语实例(二)

图1.1-6 相关术语实例(三)
二、图的存储结构及基本操作
2.1 邻接矩阵法
(1)基本方式
设G=(V,E)是有n>=1个顶点的图,邻接矩阵存储结构用两个数组分别存储图中顶点的信息(一维数组)和顶点间相关联的关系(边或弧,n阶方阵)

图2.1-1 邻接矩阵元素定义
举例如下:


图2.1-2 图与邻接矩阵
对于带权图而言,若顶点Vi和Vj之间有边相连,则邻接矩阵中对应项存放着该边对应的权值, 若顶点Vi和Vj不相连,则用无穷来代表这两个顶点之间不存在边:

图2.1-3 带权图的邻接矩阵元素定义

图2.1-4 带权图的邻接矩阵
(2)存储结构
邻接矩阵存储表示如下:
# define Max_Vertex_Num 20 //图中最大顶点个数
typedef struct ArcCell
{ int adj; // 对无权图,用1或0表示相邻否;
对带权图,则为权值
InfoType *info; //该弧相关信息指针(可无)
} ArcCell, AdjMatrix[Max_Vertex_Num] [Max_Vertex_Num];
(3)相关特点与注意事项

图2.1-5 相关特点
注意:
- 在简单应用中,可直接用二维数组作为图的邻接矩阵(顶点信息等均可省略)。
- 无向图的邻接矩阵是对称矩阵,对规模特大的邻接矩阵可采用压缩存储。
图的邻接矩阵存储有以下特点:
- 无向图的邻接矩阵一定是对称矩阵(并且唯一)。因此,在实际存储邻接矩阵时只需存储上(或下)三角矩阵的元素。
- 对于无向图,邻接矩阵的第i行(或第i列)非零元素(或非无穷元素)的个数正好是顶点 i 的度 。
- 对于有向图,邻接矩阵的第i行非零元素(或非无穷元素)的个数正好是顶点 i 的出度;第i列非零元素(或非无穷元素)的个数正好是顶点的入度。
- 用邻接矩阵存储图,很容易确定图中任意两个顶点之间是否有边相连。但是,要确定图中有多少条边,则必须按行、按列对每个元素进行检测,所花费的时间代价很大。
- 稠密图适合使用邻接矩阵的存储表示。
- 设图G的邻接矩阵为A,A^n的元素A^n[i][j]等于由顶点 i 到顶点 j 的长度为 n 的路径的数。
(4)优缺点
邻接矩阵表示法的优缺点
优点
- 便于判断两个顶点之间是否有边。
- 便于计算各个顶点的度。
缺点:
- 不便于增加和删除顶点。
- 不便于统计边的数目,需要扫描邻接矩阵所有元素才能统计完毕,时间复杂度为0(n^2)。
- 空间复杂度高。对于稀疏图而言尤其浪费空间。
2.2 邻接表法
(1)基本方式
邻接表(Adjacency List)是图的一种链式存储结构。对图中每个顶点v,建立一个单链表,把与v相邻接的顶点放在这个链表中。邻接表中每个单链表的第一个结点存放有关顶点的信息,把这一结点看成链表的表头,其余结点存放有关边的信息。

图 2.2-1 邻接表法储存基本方式

图 2.2-2 无向图的邻接表储存
 图 2.2-3 有向图的邻接表储存
图 2.2-3 有向图的邻接表储存
(2)存储结构
// 弧结点
typedef struct Arcnode
{ int adjvex;
struct Arcnode *nextarc;
} ArcNode;
//顶点节点
typedef struct Vnode
{ VertexType data;
ArcNode *firstarc;
} VNode, AdjList[Max_Vertex_Num];
//图的定义
typedef struct
{ AdjList vertices;
int vexnum, arcnum; //顶点及弧的数目
} ALGraph;
(3)相关特点与注意事项

图2.1-4 相关特点
图的邻接表存储方法具有以下特点:
- 若G为无向图,则所需的存储空间为O(V+2E);若G为有向图,则所需的存储空间为 O(V+E)。
- 对于稀疏图,采用邻接表表示将极大地节省存储空间。
- 在邻接表中,给定一顶点,能很容易地找出它的所有邻边。但是,若要确定给定的两个顶点间是否存在边,在邻接表中则需要在相应结点对应的边表中查找另一结点,效率较低。
- 在有向图的邻接表表示中,求一个给定顶点的出度只需计算其邻接表中的结点个数;但求其顶点的入度则需要遍历全部的邻接表。
- 图的邻接表表示并不唯一,因为在每个顶点对应的单链表中,各边结点的链接次序可以是任意的,它取决于建立邻接表的算法及边的输入次序。
(4)优缺点
1.优点:
- 便于增加和删除顶点。
- 便于统计边的数目。
- 空间效率高。
2.缺点:
- 不便于判断顶点之间是否有边。
- 不便于计算有向图各个顶点的度。
2.3 十字链表法
(1)基本方式
十字链表(Orthogonal List)是有向图的另一种链式存储结构。可以看成是将有向图的邻接表 和逆邻接表结合起来得到的一种链表。在十字链表中,对应于有向图中每一条弧有一个结点,对 应于每个顶点也有一个结点。

图2.3-1 十字链表结点结构
孤结点中有5个域:尾域(tailvex)和头域(headvex)分别指示弧尾和弧头;链域hlink指向弧头相同的下一条弧;链域tlink指向弧尾相同的下一条弧; info域指向该弧的相关信息。
顶点结点中有3个域:data域存放顶点相关的数据信息;firstin和 firstout两个域分别指向以该顶点为弧头或弧尾的第一个弧结点。

图2.3-2 有向图的十字链表表示
(2)代码构建
十字链表法的构建过程:(如若为了应付考试,一般不会考这部分代码)
#define MAX_VERTEX_NUM 20
#define InfoType int//图中弧包含信息的数据类型
#define VertexType int
typedef struct ArcBox{
int tailvex,headvex;//弧尾、弧头对应顶点在数组中的位置下标
struct ArcBox *hlik,*tlink;//分别指向弧头相同和弧尾相同的下一个弧
InfoType *info;//存储弧相关信息的指针
}ArcBox;
typedef struct VexNode{
VertexType data;//顶点的数据域
ArcBox *firstin,*firstout;//指向以该顶点为弧头和弧尾的链表首个结点
}VexNode;
typedef struct {
VexNode xlist[MAX_VERTEX_NUM];//存储顶点的一维数组
int vexnum,arcnum;//记录图的顶点数和弧数
}OLGraph;
int LocateVex(OLGraph * G,VertexType v){
int i=0;
//遍历一维数组,找到变量v
for (; i<G->vexnum; i++) {
if (G->xlist[i].data==v) {
break;
}
}
//如果找不到,输出提示语句,返回 -1
if (i>G->vexnum) {
printf("no such vertex.\n");
return -1;
}
return i;
}
//构建十字链表函数
void CreateDG(OLGraph *G){
//输入有向图的顶点数和弧数
scanf("%d,%d",&(G->vexnum),&(G->arcnum));
//使用一维数组存储顶点数据,初始化指针域为NULL
for (int i=0; i<G->vexnum; i++) {
scanf("%d",&(G->xlist[i].data));
G->xlist[i].firstin=NULL;
G->xlist[i].firstout=NULL;
}
//构建十字链表
for (int k=0;k<G->arcnum; k++) {
int v1,v2;
scanf("%d,%d",&v1,&v2);
//确定v1、v2在数组中的位置下标
int i=LocateVex(G, v1);
int j=LocateVex(G, v2);
//建立弧的结点
ArcBox * p=(ArcBox*)malloc(sizeof(ArcBox));
p->tailvex=i;
p->headvex=j;
//采用头插法插入新的p结点
p->hlik=G->xlist[j].firstin;
p->tlink=G->xlist[i].firstout;
G->xlist[j].firstin=G->xlist[i].firstout=p;
}
}(3)优缺点
1.优点
- 把邻接表和逆邻接表整合在一起。
- 既容易找到以vi为尾的弧,也容易找到以vi为头的弧,容易求得顶点的出度和入度。但创建图算法的时间复杂度与邻接表相同。
2.缺点:
- 结构稍为复杂
2.4 邻接多重表法
(1)基本方式
邻接多重表(Adjacency Multilist)是无向图的另一种链式存储结构。
邻接多重表的结构和十字链表类似。在邻接多重表中,每一条边用一个结点表示,它由如图 6个域组成。其中,mark为标志域,可用以标记该条边是否被搜索过;ivex和jvex 为该边依附的两个顶点在图中的位置;ilink指向下一条依附于顶点ivex的边;jlink指向下一条依附于顶点jvex的边,info为指向和边相关的各种信息的指针域。

图2.4-1 邻接多重表的结构
每一个顶点也用一个结点表示,它由如图的两个域组成。其中,data域存储和该顶点相关的信息,firstedge域指示第一条依附于该顶点的边。

图2.4-2 邻接多重表顶点结构

图2.4-3 无向图的邻接多重表表示
例如,上图所示为无向图的邻接多重表。
其有以下特点:
1.表头结点即顶点结点,与邻接表一样是顺序存储。
2.对于每个顶点结点之后是与之相关联的边结点(与该顶点结点相连的边),而邻接表则是一些与顶点结点相连接的点。
3.从每个顶点结点开始有一条链表,这条链表将所有与该顶点相连的边都连接了起来。
4.邻接多重表中边结点的个数就是无向图中边的数量,又因为无向图中的边必然连接两个顶点,所以便边结点结构中的ilink和jlink会连接两个不同的链表
三、图的遍历
3.1 深度优先
(1)遍历过程

图3.1-1 深度优先遍历方法与过程
深度优先搜索( DFS )遍历是树的先序遍历的推广。对于一个连通图,深度优先搜索遍历的过程如下。
- 从图中某个顶点V出发,访问V。
- 找出刚访问过的顶点的第一个未被访问的邻接点,访问该顶点。以该顶点为新顶点,重复此步骤,直至刚访问过的顶点没有未被访问的邻接点为止。
- 返回前一个访问过的且仍有未被访问的邻接点的顶点,找出该顶点的下一个未被访问的邻接点,访问该顶点。
- 重复步骤(2)和(3),直至图中所有顶点都被访问过,搜索结束。

图3.1-2 深度优先举例

图3.1-3 深度优先举例2
(2)算法实现
深度优先搜索遍历连通图是一个递归的过程。为了在遍历过程中便于区分顶点是否已 被访问,需附设访问标志数组visited[n];其初值为“false”,一旦某个顶点被访问,则其相应的分量置为“true”。

图3.1-4 深度优先算法基本思路
深度优先算法遍历连通图:
- 从图中某个顶点v出发,访问V,并置visited[v]的值为true。
- 依次检査v的所有邻接点w,如果visited[w]的值为false,再从w出发进行递归遍历, 直到图中所有顶点都被访问过。
bool visited[MVNum]; //访问标志数组,其初值为"false”
void DFS(Graph G,int v)
{//从第v个顶点岀发递归地深度优先遍历图G
cout«v; visited[v]=true; //访问第v个顶点,并置访问标志数组相应分量值为true
for(w=FirstAdjVex(G,v);w>=0;w=NextAdjVex(G,v,w))
〃依次检査v的所有邻接点w , FirstAdjVex (G, v)表示v的第一个邻接点
//NextAdjVex(G,v,w)表示v相对于w的下一个邻接点,wNO表示存在邻接点
if (!visited[w]) DFS(G,w); //对v的尚未访问的邻接顶点w递归调用DFS
}
图3.1-5 深度优先算法遍历连通图基本思路
若是非连通图,上述遍历过程执行之后,图中一定还有顶点未被访问,需要从图中另选一个未被访问的顶点作为起始点,重复上述深度优先搜索过程,直到图中所有顶点均被访问 过为止。这样,要实现对非连通图的遍历。
void DFS(ALGraph G, int v)
{ ArcNode *w; int i;
printf("%d\t",v); visited[v]=1;
w=G.vertices[v].firstarc;
while(w)
{ i=w->adjvex;
if(visited[i]==0) DFS(G,i);
else w=w->nextarc; }
}

图3.1-6 深度优先算法遍历非连通图基本思路
(3)算法分析
分析上述算法,在遍历图时,对图中每个顶点至多调用一次DFS函数。
因此,遍历图的过程实质上是对每个顶点查找其邻接点的过程,其耗费的时间则取决于所采用的存储结构。
- 当用邻接矩阵表示图时,查找每个顶点的邻接点的时间复杂度为0(n^2), n 为图中顶点数。
- 当以邻接表做图的存储结构时,查找邻接点的时间复杂度为O(e),其中e为图中边数,深度优先搜索 遍历图的时间复杂度为O(n+e)。
3.2 广度优先
(1)遍历过程
广度优先搜索( BFS )遍历类似于树的按层次遍历的过程。

图3.2-1 广度优先遍历方法与过程
广度优先搜索遍历的过程如下。
(1)从图中某个顶点V出发,访问V。
(2)依次访问v的各个未曾访问过的邻接点。
(3)分别从这些邻接点出发依次访问它们的邻接点,并使“先被访问的顶点的邻接点”先于 “后被访问的顶点的邻接点”被访问。重复步骤(3),直至图中所有已被访问的顶点的邻接点都被访问到

图3.2-2 广度优先举例
(2)算法实现
广度优先搜索遍历的特点是:尽可能先对横向进行搜索。设x和y是两个相继被访问过的顶点,若当前是以X为出发点进行搜索,则在访问X的所有未曾被访问过的邻接点之后, 紧接着是以y为出发点进行横向搜索,并对搜索到的y的邻接点中尚未被访问的顶点进行访问。 为此,算法实现时需引进队列保存已被访问过的顶点。

图3.2-3 广度优先算法基本思路
连通图遍历:
【算法步骤】
- 从图中某个顶点v出发,访问v,并置visited[v]的值为true,然后将v进队。
- 只要队列不空,则重复下述操作:
- 队头顶点u出队;
- 依次检查u的所有邻接点w,如果visited[w]的值为false,则访问w,并置visited[w]的值为true,然后将w进队。
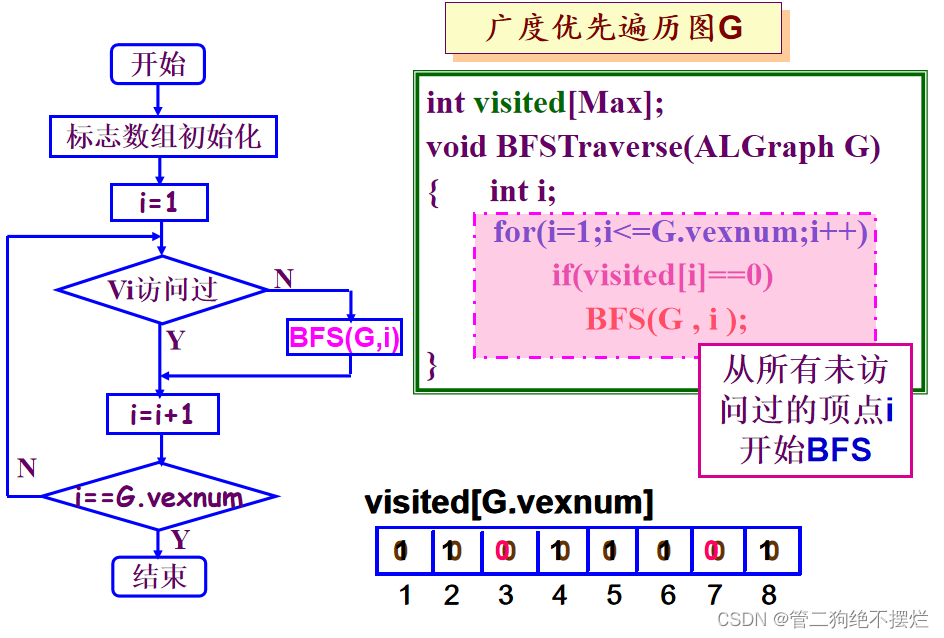
图3.2-4 广度优先算法遍历连通图基本思路
若是非连通图,上述遍历过程执行之后,图中一定还有顶点未被访问,需要从图中另选 一个未被访问的顶点作为起始点,重复上述广度优先搜索过程,直到图中所有顶点均被访问过为止。
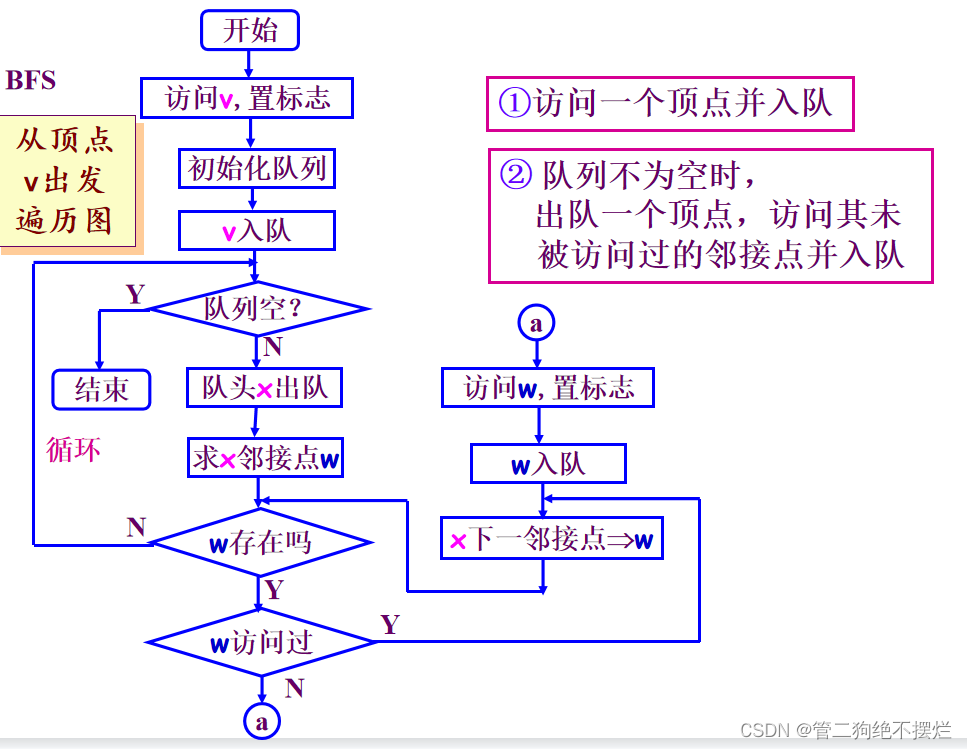
图3.2-5 广度优先算法遍历非连通图基本思路
void BFS( ALGraph G, int v)
{ int Q[MAX],f=0,r=0,x;
ArcNode *w;
printf("%d\t",v); visited[v]=1;
Q[r++]=v;
while(f<r)
{ x=Q[f++];
w=G.vertices[x].firstarc;
while(w)
{ x=w->adjvex;
if(visited[x]==0)
{ visited[x]=1;
printf("%d\t",x);
Q[r++]=x; }
w=w->nextarc;
}
}
}
(3)算法分析
每个顶点至多进一次队列。遍历图的过程实质上是通过边找邻接点的过程, 因此广度优先搜索遍历图的时间复杂度和深度优先搜索遍历相同,两种遍历方法的不同之处仅仅在于对顶点访问的顺序不同。
3.3 生成树

图3.3-1 生成树定义域说明
在广度遍历的过程中,我们可以得到一棵遍历树,称为广度优先生成树。给定图的邻接矩阵存储表示是唯一的,故其广度优先生成树也是唯一的,但由于邻接表存储表示不唯一,故其广度优先生成树也是不唯一的。

图3.3-2 广度优先生成树
深度优先搜索会产生一棵深度优先生成树。
当然,这是有条件的, 即对连通图调用DFS才能产生深度优先生成树,否则产生的将是深度优先生成森林,基于邻接表存储的深度优先生成树是不唯一的。

图3.3-3 深度优先生成树

图3.3-4 生成树举例


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











