







目录
一、选择排序
选择排序的基本思想:
每次从待排序记录中选出关键字最小的记录,顺序放在已排序的记录序列的后面,直到全部排完为止。
1.1 简单选择排序
排序过程
- 首先通过n-1次关键字比较,从n个记录中找出关键字最小的记录,将它与第一个记录交换
- 再通过n-2次比较,从剩余的n-1个记录中找出关键字次小的记录,将它与第二个记录交换
- 重复上述操作,共进行n-1趟排序后,排序结束
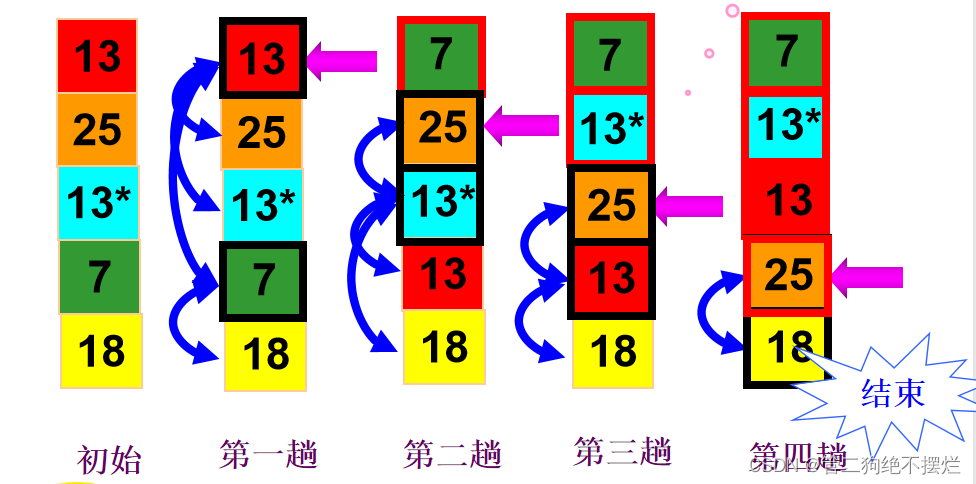
图1.1-1 算法演示
代码实现
void SelectSort( SqList &L)
{ int i, j, k;
for(i=1;i<L.length;i++)
{ k=i;
for(j=i+1;j<=L.length;j++)
if(L.r[j].key<L.r[k].key) k=j;
if(i!=k)
{ L.r[0].key=L.r[i];
L.r[i]=r[k];
L.r[k]=L.r[0].key; }
}
}
复杂度分析:

图1.1-2 算法评价
稳定性:为不稳定排序
1.2 树形选择排序
树形选择排序,是按照锦标赛的思想进行选择排序的方法。
首先对n个记录的关键字进行两两比较,然后在其中n/2个较小者之间再进行两两比较,如此重复,直至选出最小关键字的记录为止。这个过程可用一棵有n个叶子结点的完全二叉树表示。
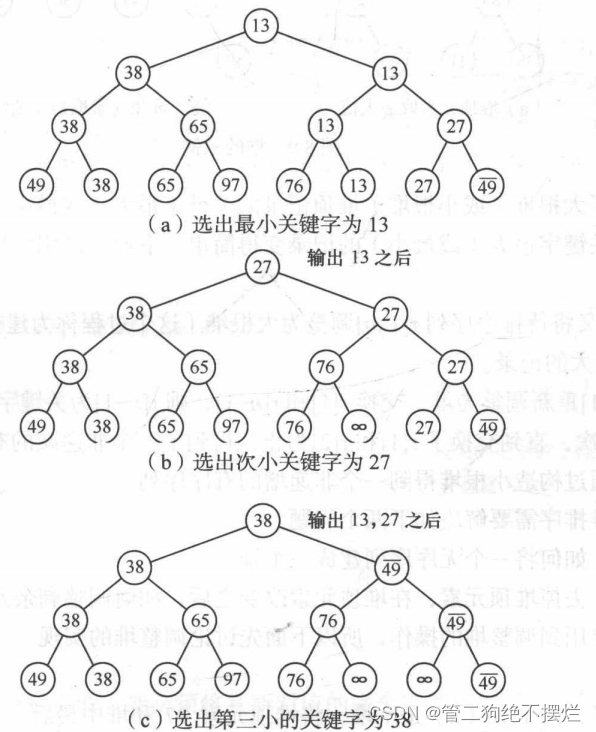
图1.2-1 树形选择排序实例
它的时间复杂度为O(nlogn)。但是,这种排序方法尚有辅助存储空间较多、和“最大值” 进行多余的比较等缺点。
1.3 堆排序(重点)
堆定义:n个元素的序列(k1,k2,……kn),当且仅当满足下列关系时,称之为堆

图1.3-1 堆的条件
可将堆序列看成完全二叉树的顺序存储,堆顶元素(完全二叉树的根)必为序列中n个元素的最小值或最大值
例 (96,83,27,38,11,9)
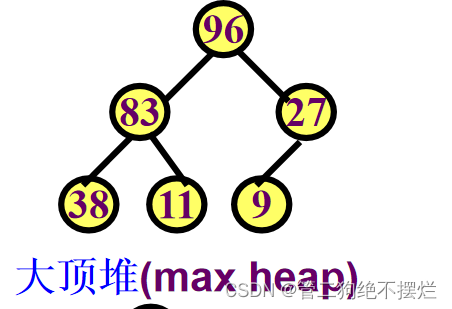
图1.3-2 堆的举例1
例 (13,38,27,50,76,65,49,97)
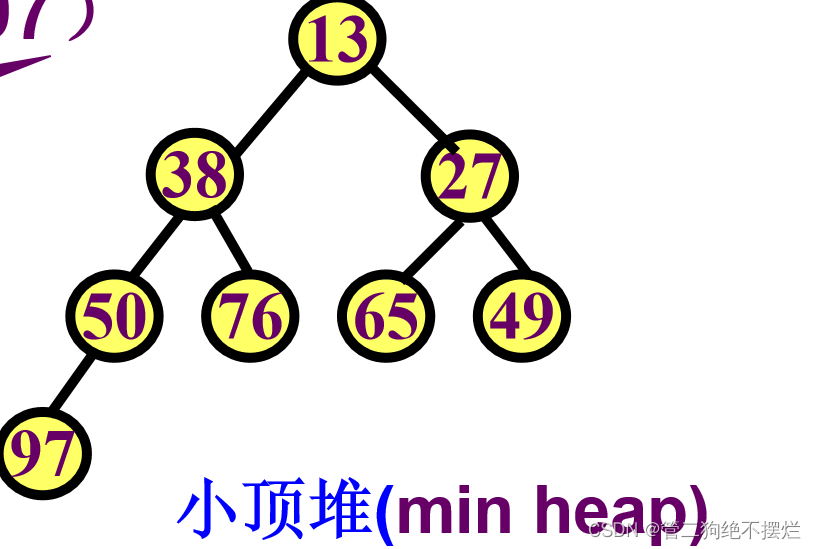
图1.3-3 堆的举例2
堆排序过程:
①将无序序列建成一个堆,则堆顶是关键字最小(或最大) 的记录;
②输出堆顶记录后,将剩余的记录重新调整成一个新堆,则可得到次小值(或次大值) ;
③重复执行② ,直到得到一个有序序列。
在输出元素后调整堆:
筛选法调整堆
输出堆顶记录(根)之后,以堆中最后一个记录替代之;
然后将根结点值与其左、右孩子进行比较,并与其中小者(或大者)进行交换;
重复上述操作,直至叶子结点,将得到新的堆,这个从堆顶至叶子的调整过程称为“筛选”
代码实现:
void HeapAdjust(HeapType &H, int s, int m)
{ RcdType rc; int j;
rc = H.r[s];
for( j=2*s; j<=m; j*=2 )
{
if ( j<m && H.r[j].key>H.r[j+1].key)
++j;
if ( rc.key <= H.r[j].key )
break;
H.r[s] = H.r[j];
s = j;
}
H.r[s] = rc;
}
初建堆:
方法:从无序序列的第n/2个元素(即此无序序列对应的完全二叉树的最后一个非叶子结点)起,至第一个元素止,进行反复筛选
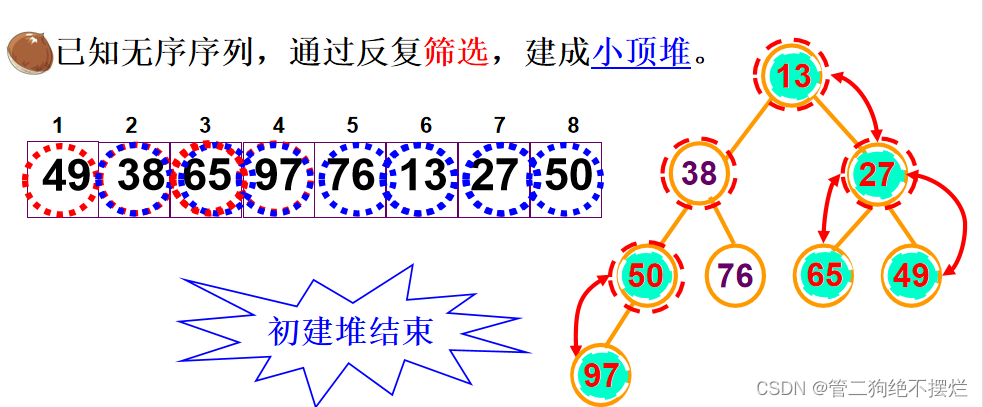
图1.3-4 初建堆
初建堆代码:
void HeapSort(HeapType &H)
{ int i;
for( i=H.length/2; i>0; i-- )
HeapAdjust ( H, i , H.length);
for( i=H.length; i>1; i-- )
{ Swap( H.r[1], H.r[i]);
HeapAdjust ( H, 1, i-1);
}
}
算法评价:

图1.3-5 算法评价
稳定性:为不稳定排序
二、二路归并排序(重点)
通过“归并”两个或两个以上的记录有序子序列,逐步增加记录有序序列的长度。
归并:将两个或两个以上的有序表组合成一个新的有序表。
排序过程
- 设初始序列含有n个记录,则可看成n个有序的子序列,每个子序列长度为1
- 两两合并,得到n/2向上取整个长度为2或1的有序子序列
- 再两两合并,……如此重复,直至得到一个长度为n的有序序列为止
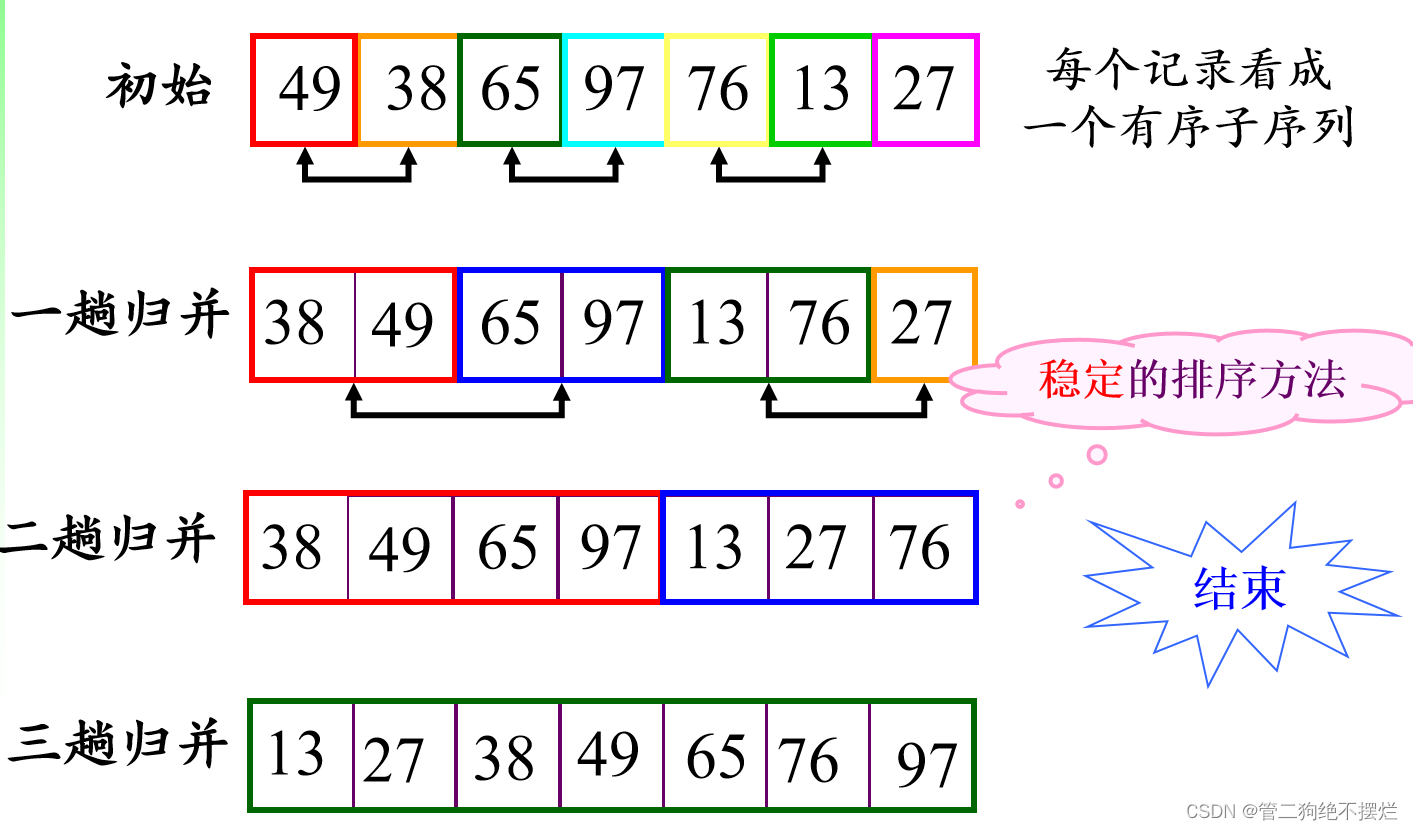
图2-1 算法演示
代码实现:
将两个子序列合并成一个完整序列:
int merge(int r[],int s[],int left,int mid,int right)
{
int i,j,k;
i=left;
j=mid+1;
k=left;
while((i<=mid)&&(j<=right))
if(r[i]<=r[j])
{
s[k] = r[i];
i++;
k++;
}
else
{
s[k]=r[j];
j++;
k++;
}
while(i<=mid)
s[k++]=r[i++];
while(j<=right)
s[k++]=r[j++];
return 0;
}
对一个序列进行归并:
int merge_sort(int r[],int s[],int left,int right)
{
int mid;
int t[20];
if(left==right)
s[left]=r[right];
else
{
mid=(left+right)/2;
merge_sort(r,t,left,mid);
merge_sort(r,t,mid+1,right);
merge(t,s,left,mid,right);
}
return 0;
}
算法评价:

图2-2 算法评价
稳定性:为稳定排序
三、基数排序
基数排序是一种借助“多关键字排序”的思想来实现“单逻辑关键字排序”的内部排序算法。


图3-1 多关键字的思想
3.1 多关键字的排序
排序方法:
最高位优先法(MSD):
必须将序列逐层分割成若干子序列,再对各子序列分别排序
- 先对最高位关键字k1排序,将序列分成若干子序列,每个子序列有相同的k1值;
- 然后分别就每个子序列对次关键字k2排序,又分成若干更小的子序列;依次重复,直至对关键字kd-1排序;
- 分别就每个子序列对最低位关键字kd排序;
- 最后将所有子序列依次连接在一起成为一个有序序列。
最低位优先法(LSD):
不必逐层分割成子序列,并且可不通过关键字比较,而通过若干次分配与收集实现排序。
- 从最低位关键字kd起进行排序,再对高一位关键字排序;
- 依次重复,直至对最高位关键字k1排序后,成为一个有序序列。
算法演示:

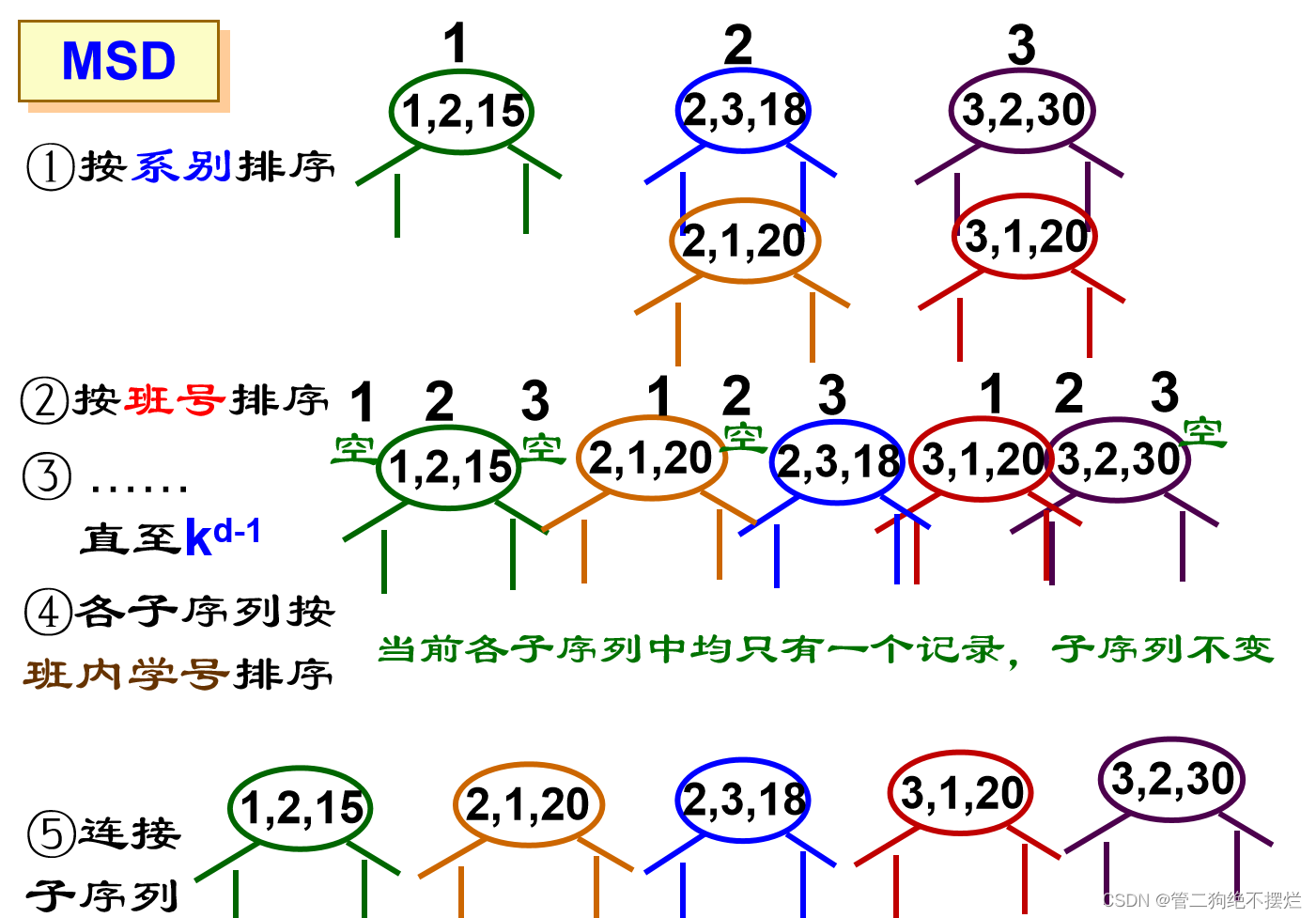
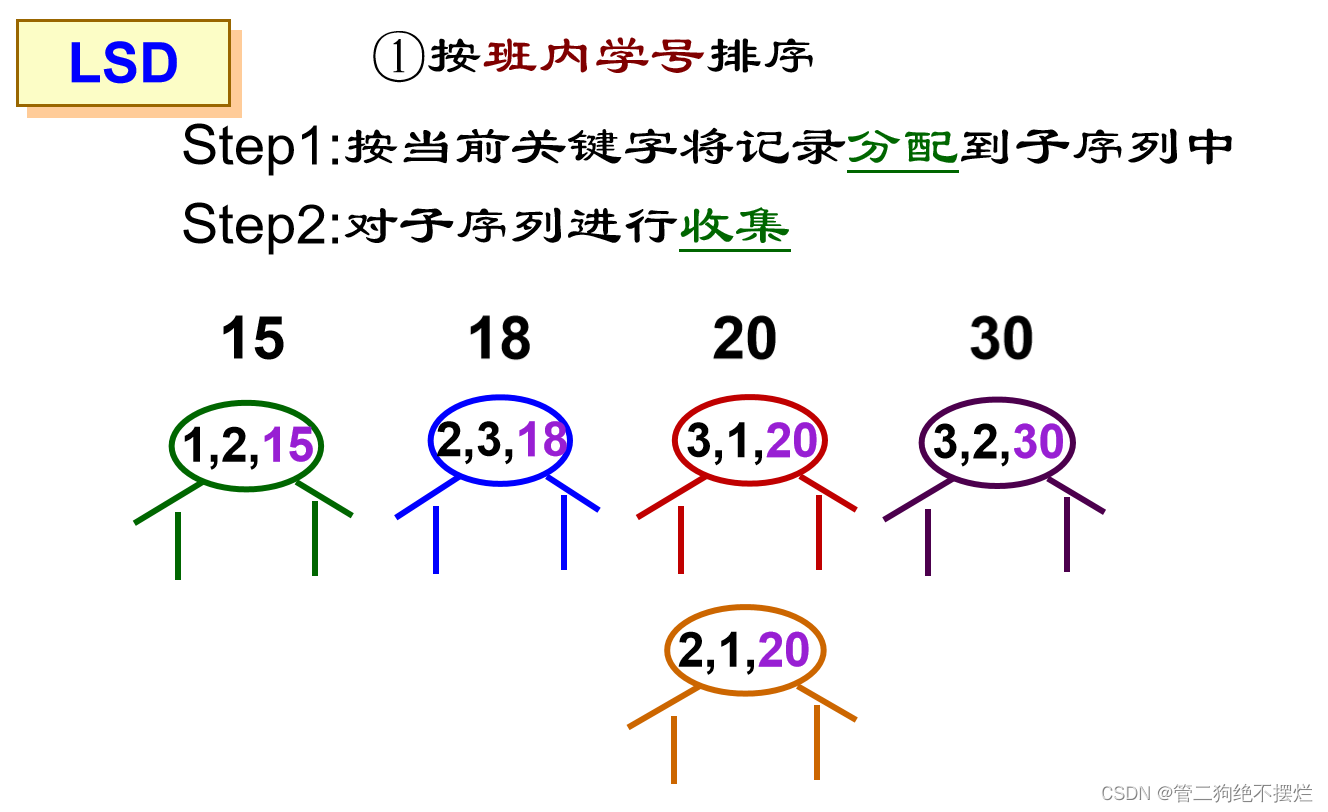
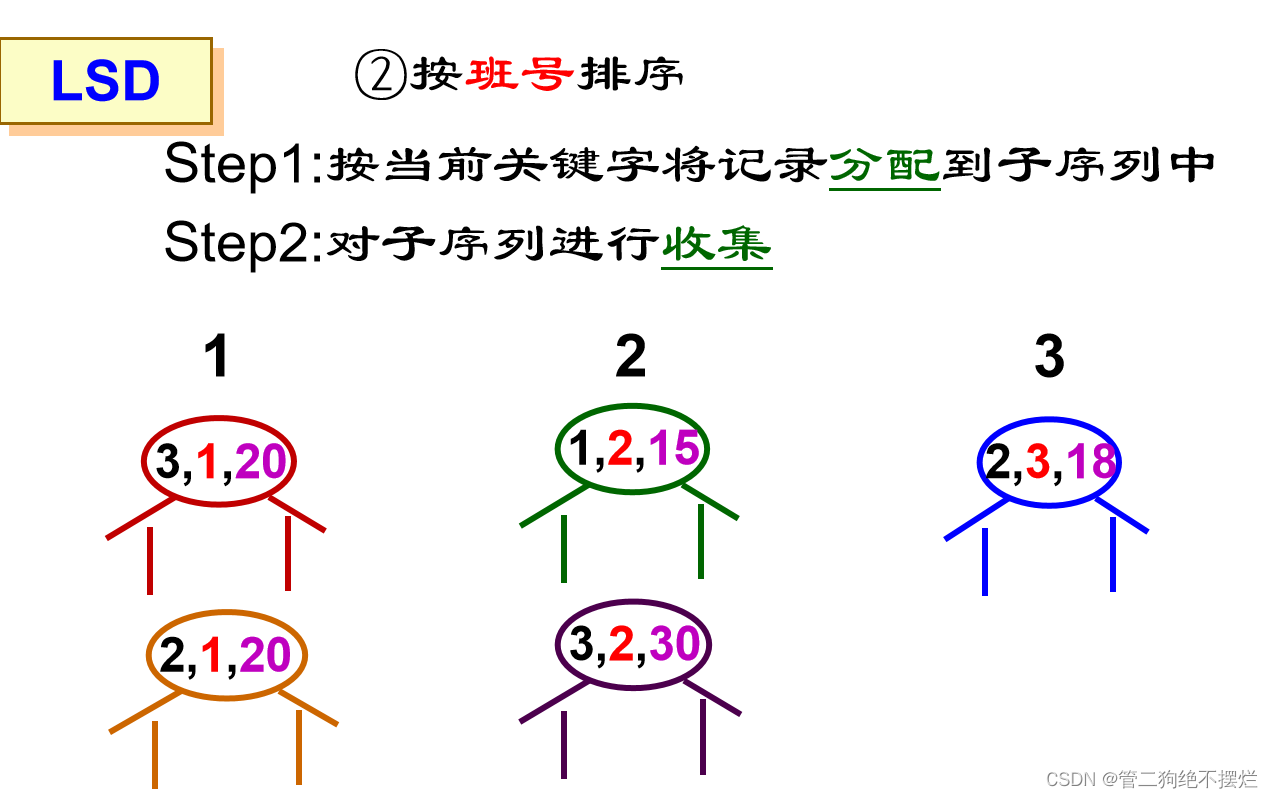
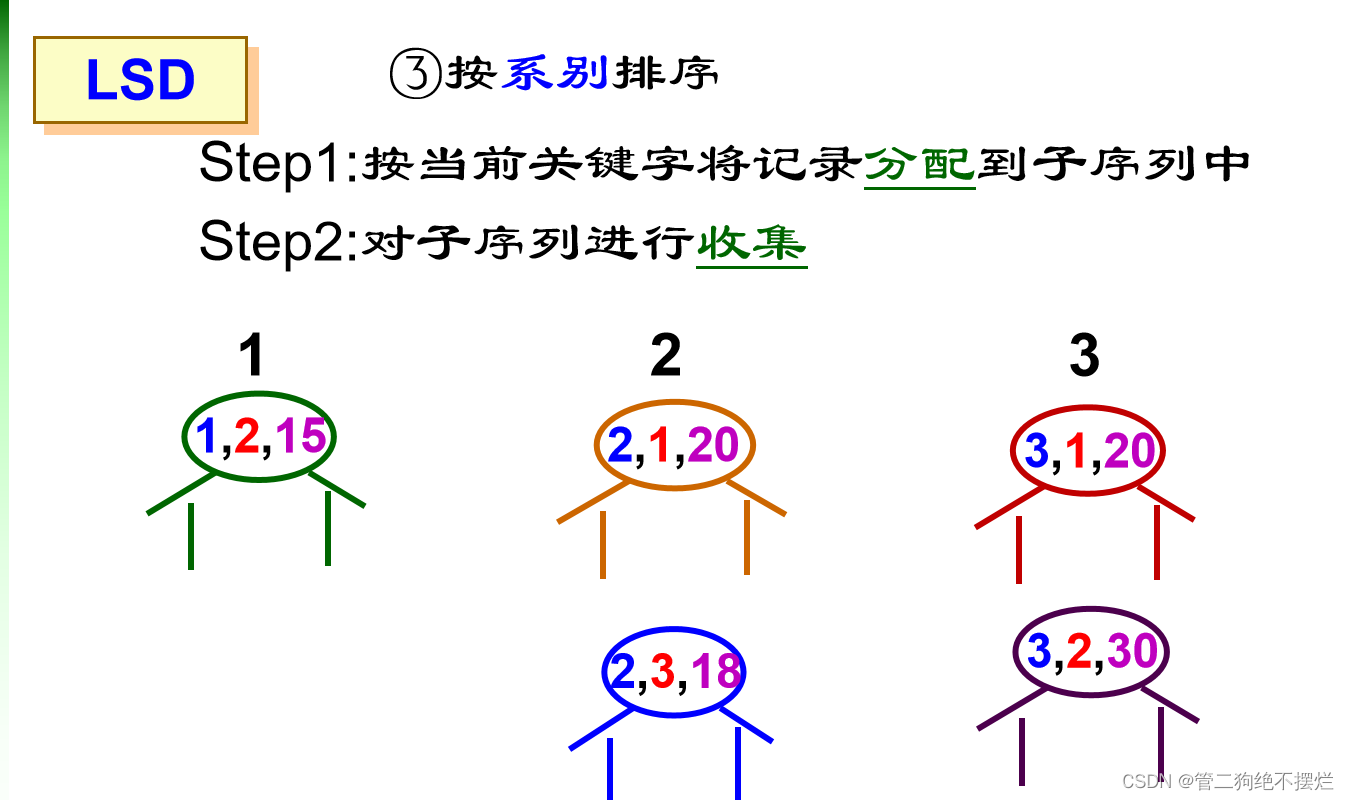
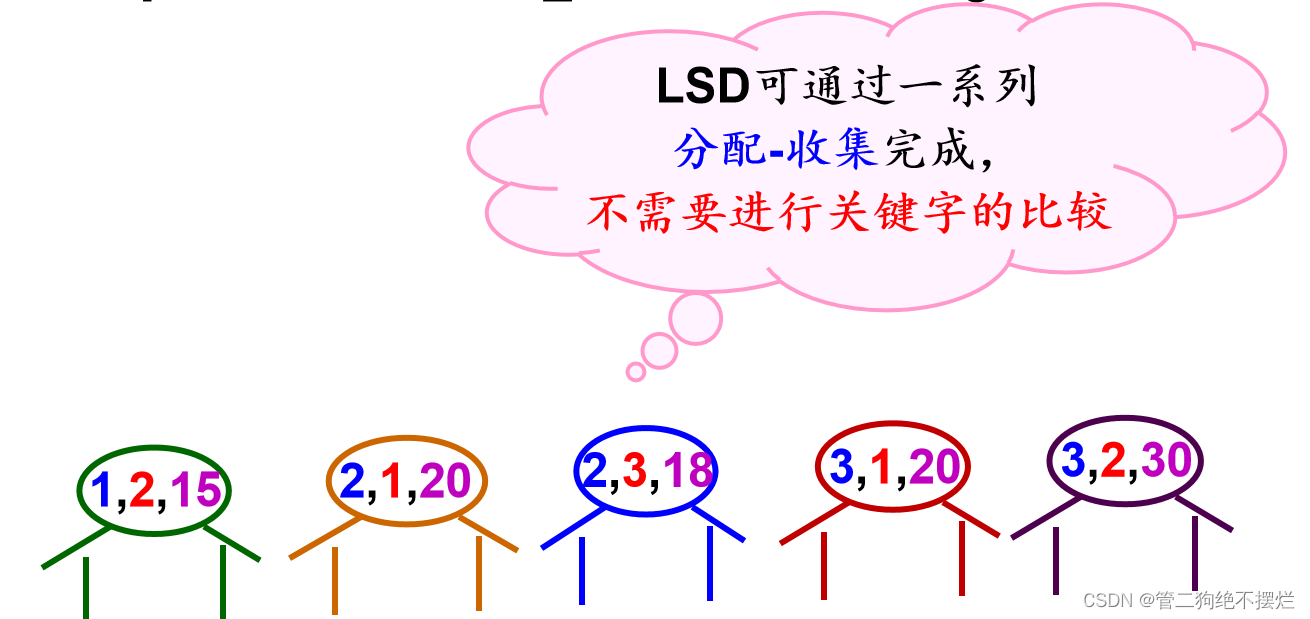
图3.1-1 - 图3.1-6 算法演示
3.2 链式基数排序
对于多关键字的记录序列,通常利用LSD法借助“分配-收集”进行排序。
对于数字型或字符型的单逻辑关键字,可以看成是由多个数位或多个字符构成的多关键字,也可以采用“分配-收集”的排序方法。
链式基数排序:用链表作存储结构的基数排序。
链式基数排序步骤
- 设置10个队列,f[i]和e[i]分别为第i个队列的头指针和尾指针
- 第一趟分配对最低位关键字(个位)进行,将链表中记录分配至10个链队列中,每个队列记录的关键字的个位相同
- 第一趟收集是改变非空队列的队尾记录指针域,令其指向下一个非空队列的队头记录,将10个队列连成一个链表
- 重复上述两步,进行第二趟、第三趟分配和收集,分别对十位、百位进行,最后得到一个有序序列
基数排序算法的性能分析如下。
空间效率:一趟排序需要的辅助存储空间为 3 个队列:r个队头指针和r个队尾指针),但 以后的排序中会重复使用这些队列,所以基数排序的空间复杂度为O(r)o
时间效率:基数排序需要进行d趟分配和收集,一趟分配需要。(〃),一趟收集需要。(尸),所 以基数排序的时间复杂度为O(d(n + r)),它与序列的初始状态无关。
稳定性:为稳定排序
四、内部排序比较
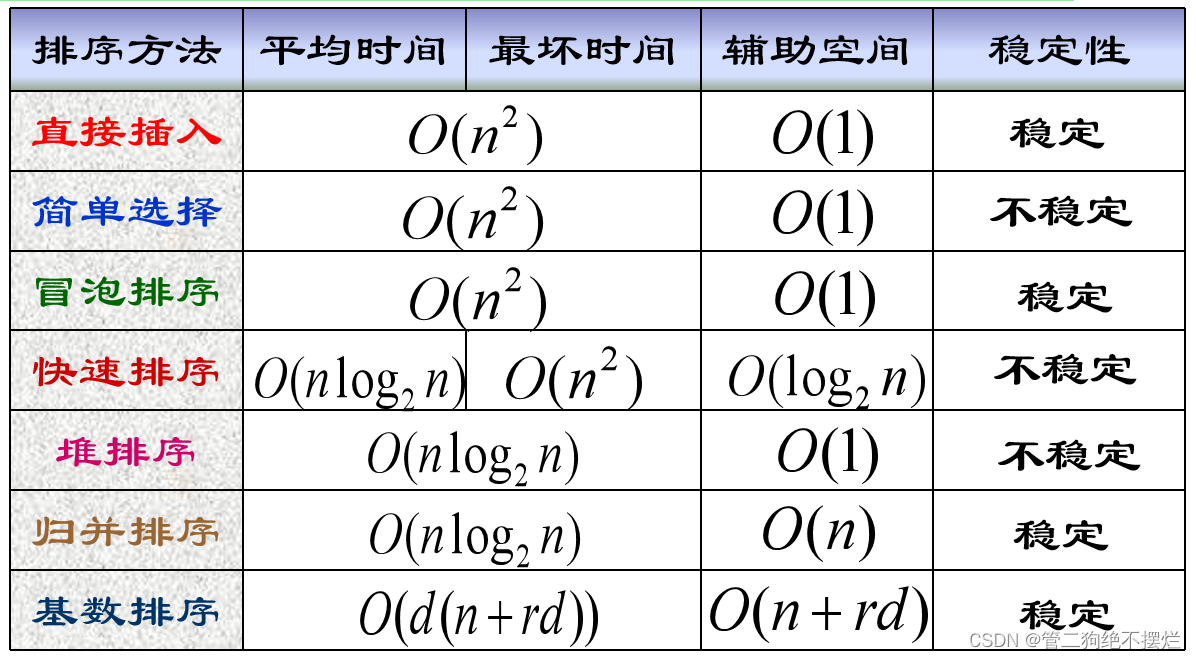
(1)n较小时,可采用简单排序方法(直接插入、简单选择和冒泡排序);
(2)n较大时,应采用快速或堆排序。要求稳定性时,可采用归并排序;
(3)若待排序记录已基本有序时,应采用冒泡排序;
(4)多关键字时(或关键字可分解时),可采用基数排序;
(5)多种排序方法可结合使用。

















 1154
1154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











