






作业day-1
1、学习数学表达式的困难
(1) 下标混用,以及不够用,下标表示出现逻辑问题;
min
M
(
∑
j
=
1
n
−
1
α
j
y
j
−
y
i
)
2
\min _{M}\left(\sum_{j=1}^{n-1} \alpha_{j} y_{j}-y_{i}\right)^{2}
Mmin(j=1∑n−1αjyj−yi)2
该式中
∑
\sum
∑部分想描述n个预测中除第
i
i
i个预测外其他预测的加权和,而该式表达不清晰,可能存在着
i
=
=
j
i==j
i==j的情况.
(2)向量数值不分;
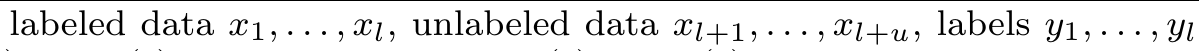
此处x应为
x
\mathbf{x}
x
(3)表达式全篇未统一。
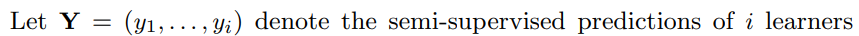
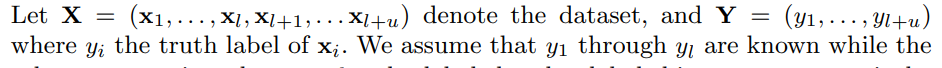
同一个符号两个不同的定义。
2、 令
A
=
{
3
,
5
}
\mathbf{A}=\{3,5\}
A={3,5},写出
2
A
2^{\mathbf{A}}
2A
2 A = { ∅ , { 3 } , { 5 } , { 3 , 5 } } 2^{\mathbf{A}}=\{\emptyset, \{3\}, \{5\}, \{3,5\} \} 2A={∅,{3},{5},{3,5}}.
3、展开 2 ∅ 2^{\emptyset} 2∅
2 ∅ = { ∅ } 2^{\emptyset}=\{\emptyset\} 2∅={∅}.
4、令
A
=
{
5
,
6
,
7
,
8
,
9
}
\mathbf{A}=\{5,6,7,8,9\}
A={5,6,7,8,9}写出另外两种表达式
方法1-枚举法:
A
=
{
5
,
…
,
9
}
\mathbf{A} =\{5,\dots,9\}
A={5,…,9}. code:\mathbf{A} = {5, \dots, 9}
方法2-谓词法:
A
=
{
x
∈
N
∣
4
<
x
<
10
}
\mathbf{A} = \{x \in \mathbb{N}| 4< x < 10 \}
A={x∈N∣4<x<10}. code:\mathbf{A} = {x \in \mathbb{N}| 4< x < 10 }
7、Deep multi-view的符号错误
(1)自变量x可能是
x
\mathbf{x}
x;
X
(
m
)
=
[
x
1
(
m
)
,
⋯
,
x
N
(
m
)
]
\mathbf{X}^{(m)}=\left[x_{1}^{(m)}, \cdots, x_{N}^{(m)}\right]
X(m)=[x1(m),⋯,xN(m)]
(2) 该用数学模式时并未使用;
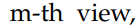
(3) m与M混用;
X
(
m
)
=
[
x
1
(
m
)
,
⋯
,
x
N
(
m
)
]
F
1
(
X
(
1
)
)
,
⋯
,
F
M
(
X
(
M
)
)
\mathbf{X}^{(m)}=\left[x_{1}^{(m)}, \cdots, x_{N}^{(m)}\right] \\ F_{1}\left(\mathbf{X}^{(1)}\right), \cdots, F_{M}\left(\mathbf{X}^{(M)}\right)
X(m)=[x1(m),⋯,xN(m)]F1(X(1)),⋯,FM(X(M))
(4)
∑
\sum
∑ 没有上界;
L
p
(
x
,
i
)
=
−
log
exp
(
x
[
i
]
)
∑
j
exp
(
x
[
j
]
)
\mathcal{L}^{p}(x, i)=-\log \frac{\exp (x[i])}{\sum_{j} \exp (x[j])}
Lp(x,i)=−log∑jexp(x[j])exp(x[i])
(5)
Y
i
j
\mathbf{Y}_{ij}
Yij前后均未给出明确定义.
L
(
I
,
Y
)
=
Y
i
j
⋅
log
{
E
m
(
F
(
I
)
}
⋅
(
ρ
(
I
)
+
α
∥
φ
(
I
)
′
−
1
K
N
∗
q
∥
)
)
\mathcal{L}(\mathbf{I}, \mathbf{Y})= \mathbf{Y}_{i j} \cdot \log \left\{\mathcal{E}_{m}(\mathcal{F}(\mathbf{I})\} \cdot\left(\rho(\mathbf{I})+\alpha\left\|\varphi(\mathbf{I})^{\prime}-\mathbf{1}_{K_{N * q}}\right\|\right)\right)
L(I,Y)=Yij⋅log{Em(F(I)}⋅(ρ(I)+α∥∥φ(I)′−1KN∗q∥∥))
作业day-2
1、令
A
=
{
1
,
2
,
5
,
8
,
9
}
\mathbf{A}=\{1,2,5,8,9\}
A={1,2,5,8,9},写出
A
\mathbf{A}
A 上的 “模 2 同余” 关系及相应的划分
R
=
{
(
1
,
1
)
,
(
1
,
5
)
,
(
1
,
9
)
,
(
2
,
2
)
,
(
2
,
8
)
,
(
5
,
1
)
,
(
5
,
5
)
,
(
5
,
9
)
,
(
8
,
2
)
,
(
8
,
8
)
,
(
9
,
1
)
,
(
9
,
5
)
,
(
9
,
9
)
}
\mathbf{R}=\{(1,1),(1,5),(1,9),(2,2),(2,8),(5,1),(5,5),(5,9),(8,2),(8,8),(9,1),(9,5),(9,9)\}
R={(1,1),(1,5),(1,9),(2,2),(2,8),(5,1),(5,5),(5,9),(8,2),(8,8),(9,1),(9,5),(9,9)}
P
=
{
{
1
,
5
,
9
}
,
{
2
,
8
}
}
\mathcal{P}=\{\{1,5,9\},\{2,8\}\}
P={{1,5,9},{2,8}}
2、令
A
=
{
1
,
2
,
5
,
8
,
9
}
\mathbf{A}=\{1,2,5,8,9\}
A={1,2,5,8,9}, 自己给定两个关系
R
1
\mathbf{R}_1
R1和
R
2
\mathbf{R}_2
R2
并计算
R
1
∘
R
2
\mathbf{R}_1∘\mathbf{R}_2
R1∘R2,
R
1
+
\mathbf{R}_1^+
R1+与
R
1
∗
\mathbf{R}_1^*
R1∗
R
1
=
{
(
a
,
b
)
∈
A
×
A
∣
a
/
2
=
b
/
2
}
=
{
(
2
,
2
)
,
(
2
,
8
)
,
(
8
,
2
)
,
(
8
,
8
)
}
\mathbf{R}_1=\{(a, b) \in \mathbf{A} \times \mathbf{A} \mid a / 2=b / 2\}=\{(2,2),(2,8),(8,2),(8,8)\}
R1={(a,b)∈A×A∣a/2=b/2}={(2,2),(2,8),(8,2),(8,8)}
R
1
=
{
(
a
,
b
)
∈
A
×
A
∣
a
m
o
d
3
=
b
m
o
d
3
}
=
{
(
2
,
2
)
,
(
2
,
5
)
,
(
2
,
8
)
,
(
5
,
2
)
,
(
5
,
5
)
,
(
5
,
8
)
,
(
8
,
2
)
,
(
8
,
5
)
,
(
8
,
8
)
}
\mathbf{R}_1=\{(a, b) \in \mathbf{A} \times \mathbf{A} \mid a \mod 3 =b \mod 3\}=\{(2,2),(2,5),(2,8),(5,2),(5,5),(5,8),(8,2),(8,5),(8,8)\}
R1={(a,b)∈A×A∣amod3=bmod3}={(2,2),(2,5),(2,8),(5,2),(5,5),(5,8),(8,2),(8,5),(8,8)}
R
1
+
=
⋃
i
=
1
∣
A
∣
R
i
=
R
1
∪
R
2
∪
R
3
∪
R
4
∪
R
5
=
{
(
2
,
2
)
,
(
2
,
8
)
,
(
8
,
8
)
}
\mathbf{R}_1^+=\bigcup_{i=1}^{|\mathbf{A}|} \mathbf{R}^{i}=\mathbf{R}^{1} \cup \mathbf{R}^{2} \cup \mathbf{R}^{3} \cup \mathbf{R}^{4} \cup \mathbf{R}^{5}=\{(2,2),(2,8),(8,8)\}
R1+=⋃i=1∣A∣Ri=R1∪R2∪R3∪R4∪R5={(2,2),(2,8),(8,8)}
R
1
∗
=
R
1
+
∪
R
0
=
{
(
2
,
2
)
,
(
2
,
8
)
,
(
8
,
8
)
}
\mathbf{R}_1^*=\mathbf{R}_1^+\cup \mathbf{R}^0=\{(2,2),(2,8),(8,8)\}
R1∗=R1+∪R0={(2,2),(2,8),(8,8)}
4、给定一个矩阵并计算其各种范数
给定矩阵
X
=
[
1
2
3
4
]
\mathbf{X}=\begin{bmatrix} 1&2\\ 3&4\\ \end{bmatrix}
X=[1324]
l
0
=
∣
∣
X
∣
∣
0
=
4
l_0=||\mathbf{X}||_0=4
l0=∣∣X∣∣0=4;
l
1
=
∣
∣
X
∣
∣
1
=
1
+
2
+
3
+
4
=
10
l_1=||\mathbf{X}||_1=1+2+3+4=10
l1=∣∣X∣∣1=1+2+3+4=10;
l
2
=
∣
∣
X
∣
∣
2
=
1
2
+
2
2
+
3
2
+
4
2
=
30
l_2=||\mathbf{X}||_2=\sqrt{1^2+2^2+3^2+4^2}=\sqrt{30}
l2=∣∣X∣∣2=12+22+32+42=30;
l
∞
=
∣
∣
X
∣
∣
∞
=
4
l_\infin=||\mathbf{X}||_\infin=4
l∞=∣∣X∣∣∞=4;
4、解释优化目标式子:
min
∑
(
i
,
j
)
∈
Ω
(
f
(
x
i
,
t
j
)
−
r
i
j
)
(1)
\min \sum_{(i,j)\in\Omega}(f(\mathbf{x}_i,\mathbf{t}_j)-r_{ij})\tag{1}
min(i,j)∈Ω∑(f(xi,tj)−rij)(1)
式中:
X
=
[
x
1
,
…
,
x
n
]
\mathbf{X}=[\mathbf{x}_1,\dots,\mathbf{x}_n]
X=[x1,…,xn]表示用户信息;
T
=
[
t
1
,
…
,
t
n
]
\mathbf{T}=[\mathbf{t}_1,\dots,\mathbf{t}_n]
T=[t1,…,tn]表示商品信息;
r
i
j
r_{ij}
rij表示评分矩阵
R
=
(
r
i
j
)
n
×
m
\mathbf{R} = (r_{ij})_{n×m}
R=(rij)n×m中具体的某个评分;
Ω
Ω
Ω 为评分矩阵
R
\mathbf{R}
R中非零元素对应位置的集合;
f
f
f目标函数分别通过用户和商品的属性生成一个评分结果;
该式要学习一个
f
f
f 用于商品的推荐,使得预测结果
f
(
x
i
,
t
j
)
f(\mathbf{x}_i,\mathbf{t}_j)
f(xi,tj)与真实值
r
i
j
r_{ij}
rij均方误差MSE最小。
作业day-3
1、将向量
(
x
2
,
x
4
,
…
)
(x_2, x_4, \dots)
(x2,x4,…)累加写出表达式
y
=
∑
i
=
1
⌊
n
/
2
⌋
x
2
i
y=\sum_{i=1}^{\lfloor n/2 \rfloor}x_{2i}
y=∑i=1⌊n/2⌋x2i; code:y=\sum_{i=1}^{n}x_{2i}
2、各出一道累加、累乘、积分表达式的习题, 并给出标准答案
累加:
y
=
∑
i
=
1
100
i
=
5050
y=\sum_{i=1}^{100} i=5050
y=∑i=1100i=5050
累乘:
y
=
∏
i
=
1
5
0.5
×
x
i
=
3.75
y=\prod_{i=1}^{5}0.5\times x_i =3.75
y=∏i=150.5×xi=3.75
定积分:
y
=
∫
2
5
2
x
d
x
=
21
y=\int_{2}^{5}2x\mathrm{d}x=21
y=∫252xdx=21
3、你使用过三重累加吗? 描述一下其应用
弗洛伊德算法,寻找两点之间最短路径,其时间复杂度为
O
(
n
3
)
O{(n^3)}
O(n3)
(4)给一个常用的定积分, 将手算结果与程序结果对比.
给定定积分:
y
=
∫
2
5
2
x
d
x
y=\int_{2}^{5}2x\mathrm{d}x
y=∫252xdx
手算:
y
=
∫
2
5
2
x
d
x
=
x
2
∣
2
5
=
25
−
4
=
21
y=\int_{2}^{5}2x\mathrm{d}x=x^2|_2^5=25-4=21
y=∫252xdx=x2∣25=25−4=21
代码:
import numpy as np
delta=0.01
sumValue=0.0
for i in np.arange(2.0,5.0,delta):
sumValue+=2*i*delta
print (sumValue)
运算结果:20.96999999999981
4、自己写一个小例子
(
n
=
3
,
m
=
1
)
(n = 3, m = 1)
(n=3,m=1)来验证最小二乘法
样例:
X
=
[
1
2
3
]
\mathbf{X}= \begin{bmatrix} 1&2&3\\ \end{bmatrix}
X=[123]
Y
=
[
−
1
3
4
]
\mathbf{Y}=\begin{bmatrix} -1&3&4\\ \end{bmatrix}
Y=[−134]
w
=
(
X
T
X
)
−
1
X
T
Y
=
(
[
1
2
3
1
1
1
]
[
1
1
2
1
3
1
]
)
−
1
[
1
2
3
1
1
1
]
[
−
1
3
4
]
=
[
2.5
−
3
]
\mathbf{w}=(\mathbf{X}^\mathrm{T}\mathbf{X})^{-1}\mathbf{X}^\mathrm{T}\mathbf{Y}=\left(\begin{bmatrix} 1&2&3\\ 1&1&1\\ \end{bmatrix} \begin{bmatrix} 1&1\\ 2&1\\ 3&1\\ \end{bmatrix}\right)^{-1} \begin{bmatrix} 1&2&3\\ 1&1&1\\ \end{bmatrix} \begin{bmatrix} -1\\ 3\\ 4\\ \end{bmatrix}=\begin{bmatrix} 2.5\\ -3\\ \end{bmatrix}
w=(XTX)−1XTY=⎝⎛[112131]⎣⎡123111⎦⎤⎠⎞−1[112131]⎣⎡−134⎦⎤=[2.5−3]
最终答案:
y
=
2.5
x
−
3
y=2.5x-3
y=2.5x−3
5、岭回归推导
L
(
w
)
=
arg
min
w
∥
X
w
−
Y
∥
2
2
+
λ
∥
w
∥
2
2
=
=
(
X
w
−
Y
)
T
(
X
w
−
Y
)
+
λ
w
T
w
=
(
w
T
X
T
−
Y
T
)
(
X
w
−
Y
)
+
λ
w
T
w
=
w
T
X
T
X
w
−
w
T
X
T
Y
−
Y
T
X
w
+
Y
T
Y
+
λ
w
T
w
L(\mathbf{w})=\underset{\mathbf{w}}{\arg \min }\|\mathbf{X} \mathbf{w}-\mathbf{Y}\|_{2}^{2}+\lambda\|\mathbf{w}\|_{2}^{2}==(\mathbf{X} \mathbf{w}-\mathbf{Y})^{\mathrm{T}}(\mathbf{X} \mathbf{w}-\mathbf{Y})+\lambda\mathbf{w}^{\mathrm{T}}\mathbf{w} \\ =\left(\mathbf{w}^{\mathrm{T}} \mathbf{X}^{\mathrm{T}}-\mathbf{Y}^{\mathrm{T}}\right)(\mathbf{X} \mathbf{w}-\mathbf{Y}) +\lambda\mathbf{w}^{\mathrm{T}}\mathbf{w}\\ =\mathbf{w}^{\mathrm{T}} \mathbf{X}^{\mathrm{T}} \mathbf{X} \mathbf{w}-\mathbf{w}^{\mathrm{T}} \mathbf{X}^{\mathrm{T}} \mathbf{Y}-\mathbf{Y}^{\mathrm{T}} \mathbf{X} \mathbf{w}+\mathbf{Y}^{\mathrm{T}} \mathbf{Y}+\lambda\mathbf{w}^{\mathrm{T}}\mathbf{w}
L(w)=wargmin∥Xw−Y∥22+λ∥w∥22==(Xw−Y)T(Xw−Y)+λwTw=(wTXT−YT)(Xw−Y)+λwTw=wTXTXw−wTXTY−YTXw+YTY+λwTw
对
w
\mathbf{w}
w求导有:
∂
L
(
w
)
∂
w
=
2
X
T
X
w
−
X
T
Y
−
X
T
Y
+
2
λ
w
\frac{\partial L(w)}{\partial w}=2 \mathbf{X}^{\mathrm{T}} \mathbf{X} \mathbf{w}- \mathbf{X}^{\mathrm{T}} \mathbf{Y}- \mathbf{X}^{\mathrm{T}} \mathbf{Y}+2 \lambda \mathbf{w}
∂w∂L(w)=2XTXw−XTY−XTY+2λw
令
∂
L
(
w
)
∂
w
=
0
\frac{\partial L(w)}{\partial w}=0
∂w∂L(w)=0可得:
X
T
X
w
−
X
T
Y
+
λ
w
=
0
\mathbf{X}^{\mathrm{T}} \mathbf{X} \mathbf{w}-\mathbf{X}^{\mathrm{T}} \mathbf{Y}+\lambda \mathbf{w}=0
XTXw−XTY+λw=0
作业3 逻辑回归推导
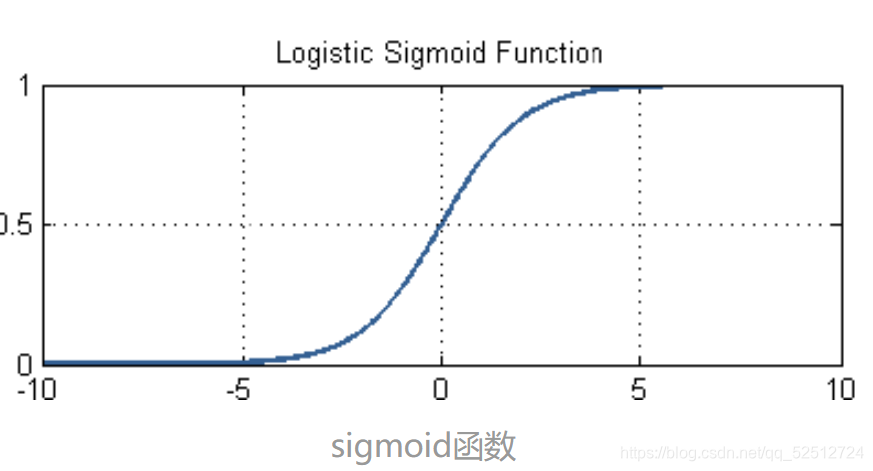
技术1:将线性回归映射到
[
0
,
1
]
[0,1]
[0,1]——sigmoid函数
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x)=\frac{1}{1+e^{-x}}
σ(x)=1+e−x1
令
x
=
w
T
x
\mathbf{x}=\mathbf{w}^\mathrm{T}\mathbf{x}
x=wTx,则逻辑回归模型为:
y
=
σ
(
f
(
x
)
)
=
σ
(
w
T
x
)
=
1
1
+
e
−
w
T
x
(1)
y=\sigma(f(\mathbf{x}))=\sigma\left(\mathbf{w}^\mathrm{T} \mathbf{x}\right)=\frac{1}{1+e^{-\mathbf{w}^\mathrm{T} \mathbf{x}}} \tag{1}
y=σ(f(x))=σ(wTx)=1+e−wTx1(1)
技术2:利用对数对数降低损失函数的计算难度
令标签为1的概率为p:
P
y
=
1
=
1
1
+
e
−
w
T
x
=
p
(2)
P_{y=1}=\frac{1}{1+e^{-\mathbf{w}^\mathrm{T} \mathbf{x}}}=p \tag{2}
Py=1=1+e−wTx1=p(2)
标签为0的概率为
P
y
=
0
=
1
−
p
P_{y=0}=1-p
Py=0=1−p,则第i个样本的概率为:
P
(
y
i
∣
x
i
)
=
p
y
i
(
1
−
p
)
1
−
y
i
(3)
P\left(y_{i} \mid \mathbf{x}_{i}\right)=p^{y_{i}}(1-p)^{1-y_{i}} \tag{3}
P(yi∣xi)=pyi(1−p)1−yi(3)
对于n个样本
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
(
x
3
,
y
3
)
…
(
x
n
,
y
n
)
}
\left\{\left(\mathbf{x}_{1}, y_{1}\right),\left(\mathbf{x}_{2}, y_{2}\right),\left(\mathbf{x}_{3}, y_{3}\right) \ldots\left(\mathbf{x}_{n}, y_{n}\right)\right\}
{(x1,y1),(x2,y2),(x3,y3)…(xn,yn)}其概率为:
P
总
=
P
(
y
1
∣
x
1
)
P
(
y
2
∣
x
2
)
P
(
y
3
∣
x
3
)
…
P
(
y
n
∣
x
n
)
=
∏
i
=
1
n
p
y
i
(
1
−
p
)
1
−
y
i
(4)
\begin{aligned} P_{\text {总 }} &=P\left(y_{1} \mid \mathbf{x}_{1}\right) P\left(y_{2} \mid \mathbf{x}_{2}\right) P\left(y_{3} \mid \mathbf{x}_{3}\right) \ldots P\left(y_{n} \mid \mathbf{x}_{n}\right) \\ &=\prod_{i=1}^{n} p^{y_{i}}(1-p)^{1-y_{i}}\tag{4} \end{aligned}
P总 =P(y1∣x1)P(y2∣x2)P(y3∣x3)…P(yn∣xn)=i=1∏npyi(1−p)1−yi(4)
对其求对数不改变其单调性,有损失函数:
L
(
w
)
=
ln
(
P
总
)
=
ln
(
∏
n
=
1
N
p
y
n
(
1
−
p
)
1
−
y
n
)
=
∑
n
=
1
N
ln
(
p
y
n
(
1
−
p
)
1
−
y
n
)
=
∑
n
=
1
N
(
y
n
ln
(
p
)
+
(
1
−
y
n
)
ln
(
1
−
p
)
)
(5)
\begin{aligned} L(\mathbf{w})=\ln \left(P_{\text {总 }}\right) &=\ln \left(\prod_{n=1}^{N} p^{y_{n}}(1-p)^{1-y_{n}}\right) \\ &=\sum_{n=1}^{N} \ln \left(p^{y_{n}}(1-p)^{1-y_{n}}\right) \\ &=\sum_{n=1}^{N}\left(y_{n} \ln (p)+\left(1-y_{n}\right) \ln (1-p)\right)\tag{5} \end{aligned}
L(w)=ln(P总 )=ln(n=1∏Npyn(1−p)1−yn)=n=1∑Nln(pyn(1−p)1−yn)=n=1∑N(ynln(p)+(1−yn)ln(1−p))(5)
此刻,只需要找到一个
w
∗
\mathbf{w}^*
w∗使概率最大,则有:
w
∗
=
arg
max
w
L
(
w
)
=
−
arg
min
w
L
(
w
)
(6)
\mathbf{w}^*=\arg \max _{\mathbf{w}} L(\mathbf{w})=-\arg \min _{\mathbf{w}} L(\mathbf{w})\tag{6}
w∗=argwmaxL(w)=−argwminL(w)(6)
技术3:梯度下降求解无解析解的情况
式(2)对p求导,可得
p
′
=
f
′
(
w
)
=
(
1
1
+
e
−
w
T
w
)
′
=
1
1
+
e
−
w
T
x
⋅
e
−
w
T
x
1
+
e
−
w
T
x
⋅
x
=
p
(
1
−
p
)
x
(7)
\begin{aligned} p^{\prime}=f^{\prime}(\mathbf{w}) &=\left(\frac{1}{1+e^{-\mathbf{w}^{\mathrm{T}} \mathbf{w}}}\right)^{\prime} \\ &=\frac{1}{1+e^{-\mathbf{w}^{\mathrm{T}} \mathbf{x}}} \cdot \frac{e^{-\mathbf{w}^{\mathrm{T}} \mathbf{x}}}{1+e^{-\mathbf{w}^{\mathrm{T}} \mathbf{x}}} \cdot \mathbf{x} \\ &=p(1-p) \mathbf{x}\tag{7} \end{aligned}
p′=f′(w)=(1+e−wTw1)′=1+e−wTx1⋅1+e−wTxe−wTx⋅x=p(1−p)x(7)
对(5)关于
w
\mathbf{w}
w 求导有:
∂
L
(
w
)
∂
w
=
=
∑
i
=
1
n
(
y
i
ln
′
(
p
)
+
(
1
−
y
i
)
ln
′
(
1
−
p
)
)
=
∑
i
=
1
n
(
(
y
i
1
p
p
′
)
+
(
1
−
y
i
)
1
1
−
p
(
1
−
p
)
′
)
=
∑
i
=
1
n
(
y
i
(
1
−
p
)
x
i
−
(
1
−
y
i
)
p
x
i
)
=
∑
i
=
1
n
(
y
i
−
p
)
x
i
(8)
\begin{aligned} \frac{\partial L(\mathbf{w})}{\partial \mathbf{w}}=&=\sum_{i=1}^{n}\left(y_{i} \ln^{\prime}(p)+\left(1-y_{i}\right) \ln^{\prime}(1-p)\right) \\ &=\sum_{i=1}^{n}\left(\left(y_{i} \frac{1}{p} p^{\prime}\right)+\left(1-y_{i}\right) \frac{1}{1-p}(1-p)^{\prime}\right) \\ &=\sum_{i=1}^{n}\left(y_{i}(1-p) \mathbf{x}_{i}-\left(1-y_{i}\right) p \mathbf{x}_{i}\right) \\ &=\sum_{i=1}^{n}\left(y_{i}-p\right) \mathbf{x}_{i}\tag{8} \end{aligned}
∂w∂L(w)==i=1∑n(yiln′(p)+(1−yi)ln′(1−p))=i=1∑n((yip1p′)+(1−yi)1−p1(1−p)′)=i=1∑n(yi(1−p)xi−(1−yi)pxi)=i=1∑n(yi−p)xi(8)
令(8)偏导为0由于无法获得解析式,则借助梯度下降可得模型参数
w
\mathbf{w}
w更新式子:
w
t
+
1
=
w
T
−
α
∂
L
(
w
)
∂
w
(9)
\mathbf{w}^{t+1}=\mathbf{w}^\mathrm{T} -\alpha \frac{\partial L(\mathbf{w})}{\partial \mathbf{w}} \tag{9}
wt+1=wT−α∂w∂L(w)(9)
逻辑回归的特点:
(1)使用sigmoid函数映射线性回归到
[
0
,
1
]
[0,1]
[0,1]区间;
(2)使用概率将回归问题变成分类问题;
(3)使用对数函数降低计算难度;
(4)使用梯度下降在无法获得解析式的情况下求解模型参数;
(5)不能用Logistic回归去解决非线性问题,因为Logistic的决策面为线性面。
作业day-4
1、无向图定义
Definition :An undirected network is a tuple
N
=
(
V
,
E
,
W
)
N = (\mathbf{V}, \mathbf{E}, \mathbf{W})
N=(V,E,W),where
V
\mathbf{V}
V is the set of nodes,
E
⊆
V
×
V
\mathbf{E} \subseteq V \times V
E⊆V×V where
(
v
i
,
v
j
)
∈
E
⇔
(
v
j
,
v
i
)
∈
E
(v_i,v_j) \in \mathbf{E} \Leftrightarrow (v_j,v_i) \in \mathbf{E}
(vi,vj)∈E⇔(vj,vi)∈E is the set of nodes,
w
∈
W
w \in \mathbf{W}
w∈W is the weighted of
(
v
i
,
v
j
)
(v_i, v_j)
(vi,vj).
2、树的定义

(1)自己画一棵树, 将其元组各部分写出来 (特别是函数
p
p
p).
Let
ϕ
\phi
ϕ be the empty node, a tree is a triple
T
=
(
A
,
A
0
,
p
)
T=(\mathbf{A},\rm A_0, p)
T=(A,A0,p) where
∙
A
=
{
A
0
,
A
1
,
…
,
A
6
}
≠
ϕ
\bull \mathbf{A} =\{\rm A_0, \rm A_1, \dots, \rm A_6\}\neq\phi
∙A={A0,A1,…,A6}=ϕ is the set of nodes;
∙
A
0
∈
A
\bull \rm A_0\in \mathbf{A}
∙A0∈A is the root node;
∙
p
:
A
→
A
∪
{
ϕ
}
\bull p: \mathbf{A} \to\mathbf{A} \cup\{\phi\}
∙p:A→A∪{ϕ} is the parent mapping satisfying;
:
p
(
A
0
)
=
ϕ
:p(A_0)=\phi
:p(A0)=ϕ
:
∀
A
∈
A
,
∃
1
n
≥
0
,
s.t.
p
(
n
)
(
A
)
=
A
0
:\forall \rm A \in \mathbf{A}, \exists 1 n \geq 0, \text { s.t. } p^{(n)}(A)=A_0
:∀A∈A,∃1n≥0, s.t. p(n)(A)=A0
(2)针对该树, 将代码中的变量值写出来
code:
public class Tree {
/**
* 节点数. 表示节点 v_0 至 v_{n-1}.
*/
int n;
/**
* 根节点. 0 至 n-1.
*/
int root;
/**
* 父节点.
*/
int[] parent;
/**
* 构造一棵树, 第一个节点为根节点, 其余节点均为其直接子节点, 也均为叶节点.
*/
public Tree(int paraN) {
n = paraN;
parent = new int[n];
parent[0] = -1; // -1 即 \phi
}// Of the constructor
}//Of class Tree
其中:
n=6;root=0;
parent[0]=-1; parent[1]=0; parent[2]=0; parent[3]=1; parent[4]=1; parent[5]=2; parent[6]=2;
3、画一棵三叉树, 并写出它的 child 数组

child:
{
(
1
,
2
,
3
)
;
(
4
,
−
1
,
5
)
;
(
−
1
,
−
1
,
6
)
;
(
−
1
,
−
1
,
−
1
)
;
(
−
1
,
−
1
,
−
1
)
;
(
−
1
,
−
1
,
−
1
)
;
(
−
1
,
−
1
,
−
1
)
}
\{(1, 2, 3) ;(4, -1, 5) ;(-1, -1, 6) ;(-1, -1,-1) ;(-1,-1,-1) ;(-1,-1,-1) ;(-1,-1,-1)\}
{(1,2,3);(4,−1,5);(−1,−1,6);(−1,−1,−1);(−1,−1,−1);(−1,−1,−1);(−1,−1,−1)}
4、重新定义树
Let
ϕ
\phi
ϕ be the empty node, a tree is a triple
T
=
(
A
,
A
0
,
Σ
,
c
)
T=(\mathbf{A}, \rm A_0, \Sigma, c)
T=(A,A0,Σ,c) where
∙
A
=
{
A
0
,
A
1
,
…
,
A
6
}
≠
ϕ
\bull \mathbf{A} =\{ \rm A_0, \rm A_1, \dots,\rm A_6\}\neq\phi
∙A={A0,A1,…,A6}=ϕ is the set of nodes;
∙
A
0
∈
A
\bull \rm A_0\in \mathbf{A}
∙A0∈A is the root node;
∙
Σ
=
{
0
,
…
,
6
}
\bull \Sigma =\{0,\dots,6\}
∙Σ={0,…,6} is the alphabet;
∙
c
:
(
A
∪
{
ϕ
}
)
×
Σ
∗
→
A
∪
{
ϕ
}
\bull c:(\mathbf{A} \cup\{\phi\}) \times \Sigma^{*} \rightarrow \mathbf{A} \cup\{\phi\}
∙c:(A∪{ϕ})×Σ∗→A∪{ϕ} satisfying ;
∙
∀
A
∈
A
,
∃
1
s
∈
Σ
∗
s.t.
c
(
r
,
s
)
=
A
\bull \forall \rm A \in \mathbf{A}, \exists 1 s \in \Sigma^{*} \text { s.t. } c(r, s)=A
∙∀A∈A,∃1s∈Σ∗ s.t. c(r,s)=A
作业day-5
1、定义一个标签分布系统, 即各标签的值不是 0/1,而是
[
0
,
1
]
[0,1]
[0,1] 区间的实数,且同一对象的标签和为1
A label distribution learning is a tuple
S
=
(
X
,
Y
)
S = (\mathbf{X}, \mathbf{Y})
S=(X,Y) where
X
=
[
x
i
j
]
n
×
m
∈
R
n
×
m
\mathbf{X} = [x_{ij}]_{n \times m} \in \mathbb{R}^{n \times m}
X=[xij]n×m∈Rn×m is the data matrix,
Y
=
[
y
i
k
]
n
×
l
∈
[
0
,
1
]
n
×
l
\mathbf{Y} = [y_{ik}]_{n \times l} \in [0, 1]^{n \times l}
Y=[yik]n×l∈[0,1]n×l is the label matrix, s.t.
∑
t
=
1
k
y
i
k
=
1
\sum_{t=1}^k y_{ik} = 1
∑t=1kyik=1,
n
n
n is the number of instances,
m
m
m is the number of features, and
l
l
l is the number of labels.
2、 找一篇你们小组的论文来详细分析数学表达式, 包括其涵义, 规范, 优点和缺点.
数学表达式:
min
v
(
j
)
E
(
v
(
j
)
)
=
∑
i
=
1
l
L
(
y
i
,
g
(
j
)
(
x
i
)
)
+
∑
i
=
l
+
1
l
+
u
v
i
(
j
)
L
(
g
‾
(
j
−
1
)
(
x
i
)
,
g
(
j
)
(
x
i
)
)
(10)
\min_{ \mathbf{v}^{(j)}} E\left( \mathbf{v}^{(j)}\right)= \sum_{i = 1}^{l} L\left(y_{i}, g^{(j)}(\mathbf{x}_{i})\right) + \sum_{i=l+1}^{l+u}v_{i}^{(j)}L\left(\overline{g}^{(j-1)}{(\mathbf{x}_i)}, g^{(j)}(\mathbf{x}_{i})\right)\tag{10}
v(j)minE(v(j))=i=1∑lL(yi,g(j)(xi))+i=l+1∑l+uvi(j)L(g(j−1)(xi),g(j)(xi))(10)
涵义:在第
j
j
j个视角上,在输入为
v
(
j
)
\mathbf{v}^{(j)}
v(j)的情况下,使模型在标记数据与伪标记数据上的预测损失最小。
优点:简介明了,变量名未出现混用的情况。
缺点:无法一次性讲整个多个视角之间的优化情况写出。















 6874
6874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









