






用到的依赖
<!-- Apache ShardingSphere-jdbc -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
<!-- uid-generator -->
<dependency>
<groupId>com.xfvape.uid</groupId>
<artifactId>uid-generator</artifactId>
<version>0.0.4-RELEASE</version>
<exclusions>
<!-- 避免依赖冲突 -->
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
</exclusion>
<exclusion>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
</exclusion>
<exclusion>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
</exclusion>
</exclusions>
</dependency>shardingsphere-jdbc5.1.1版本自定义id生成配置
参考链接:https://blog.csdn.net/liaomingwu/article/details/121643050
需要继承KeyGenerateAlgorithm接口
package com.aaa.stock.utils;
import org.apache.shardingsphere.sharding.spi.KeyGenerateAlgorithm;
public class KeyGenerator implements KeyGenerateAlgorithm {
@Override
public String getType() {
// 返回算法类型表示
return "uidGenerator";
}
@Override
public void init() {
// 这里可以进行必要的初始化
}
@Override
public Comparable<?> generateKey() {
// 这里自定义生成KEY的算法
Long lKey = 123456l;
return lKey;
}
}具体的算法根据业务需要自定义实现。
最后还需要添加一个SPI配置,resource下面的META-INF/services生成一个文件org.apache.shardingsphere.sharding.spi.KeyGenerateAlgorithm,配置算法类的全路径。

文件里边内容:com.aaa.stock.utils.KeyGenerator
更改yml配置文件中的算法名称
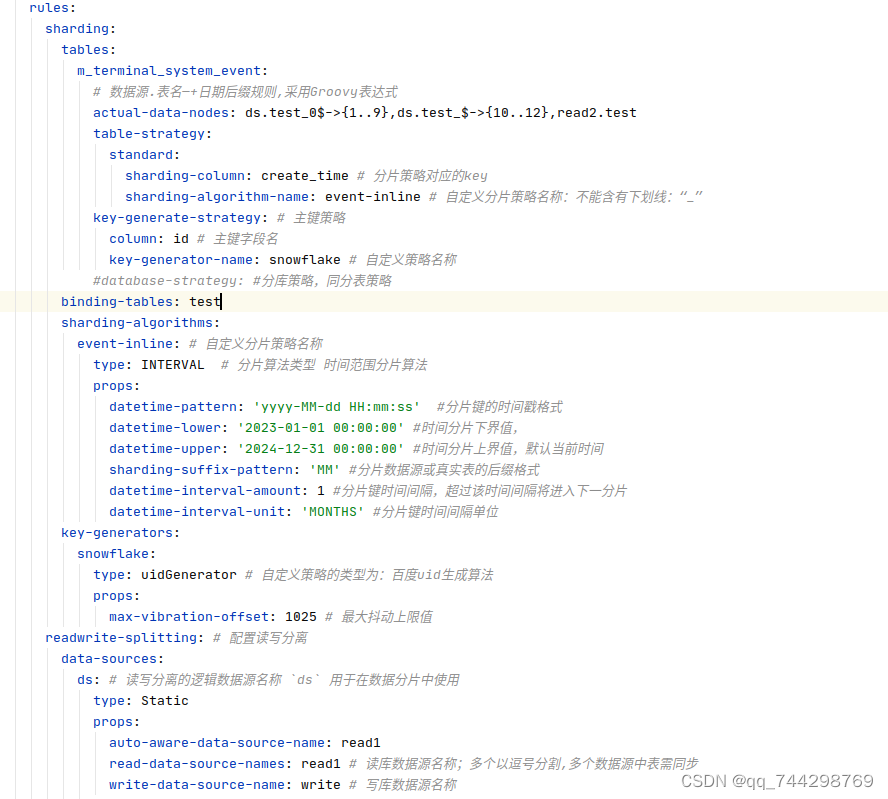
引入百度uidGenerator
官网链接:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
参考链接:https://blog.csdn.net/qidasheng2012/article/details/117512327
创建数据库表
create table worker_node
(
ID bigint auto_increment comment 'auto increment id'
primary key,
HOST_NAME varchar(64) not null comment 'host name',
PORT varchar(64) not null comment 'port',
TYPE int not null comment 'node type: ACTUAL or CONTAINER',
LAUNCH_DATE date not null comment 'launch date',
MODIFIED timestamp not null comment 'modified time',
CREATED timestamp not null comment 'created time'
)
comment 'DB WorkerID Assigner for UID Generator';实体类
@Data
public class WorkerNode {
private Long id;
private String hostName;
private String port;
private Integer type;
private Date launchDate;
private Date modified;
private Date created;
}mapper类
@Mapper
public interface WorkerNodeMapper {
/**
* Get {@link WorkerNode} by node host
*
* @param host
* @param port
* @return
*/
WorkerNode getWorkerNodeByHostPort(@Param("host") String host, @Param("port") String port);
/**
* Add {@link WorkerNode}
*
* @param workerNode
*/
void addWorkerNode(WorkerNode workerNode);
}重写WorkerIdAssigner接口
public class DisposableWorkerIdAssigner implements WorkerIdAssigner {
@Resource
private WorkerNodeMapper workerNodeMapper;
@Override
@Transactional(rollbackFor = Exception.class)
public long assignWorkerId() {
WorkerNode workerNode = buildWorkerNode();
workerNodeMapper.addWorkerNode(workerNode);
return workerNode.getId();
}
private WorkerNode buildWorkerNode() {
WorkerNode workNode = new WorkerNode();
if (DockerUtils.isDocker()) {
workNode.setType(WorkerNodeType.CONTAINER.value());
workNode.setHostName(DockerUtils.getDockerHost());
workNode.setPort(DockerUtils.getDockerPort());
} else {
workNode.setType(WorkerNodeType.ACTUAL.value());
workNode.setHostName(NetUtils.getLocalAddress());
workNode.setPort(System.currentTimeMillis() + "-" + RandomUtils.nextInt(100000));
}
workNode.setLaunchDate(new Date());
return workNode;
}
}将uid-generator核心对象装配为spring的bean
@Configuration
public class WorkerNodeConfig {
@Bean("disposableWorkerIdAssigner")
public DisposableWorkerIdAssigner disposableWorkerIdAssigner(){
// 这里注意DisposableWorkerIdAssigner引用本地路径
return new DisposableWorkerIdAssigner();
}
@Bean("cachedUidGenerator")
public UidGenerator uidGenerator(DisposableWorkerIdAssigner disposableWorkerIdAssigner){
CachedUidGenerator cachedUidGenerator = new CachedUidGenerator();
cachedUidGenerator.setWorkerIdAssigner(disposableWorkerIdAssigner);
return cachedUidGenerator;
}
}resource目录下对应的mapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.aaa.stock.mapper.WorkerNodeMapper">
<resultMap id="workerNodeRes"
type="com.aaa.stock.entity.WorkerNode">
<id column="ID" jdbcType="BIGINT" property="id" />
<result column="HOST_NAME" jdbcType="VARCHAR" property="hostName" />
<result column="PORT" jdbcType="VARCHAR" property="port" />
<result column="TYPE" jdbcType="INTEGER" property="type" />
<result column="LAUNCH_DATE" jdbcType="DATE" property="launchDate" />
<result column="MODIFIED" jdbcType="TIMESTAMP" property="modified" />
<result column="CREATED" jdbcType="TIMESTAMP" property="created" />
</resultMap>
<insert id="addWorkerNode" useGeneratedKeys="true" keyProperty="id"
parameterType="com.aaa.stock.entity.WorkerNode">
INSERT INTO WORKER_NODE
(HOST_NAME,
PORT,
TYPE,
LAUNCH_DATE,
MODIFIED,
CREATED)
VALUES (
#{hostName},
#{port},
#{type},
#{launchDate},
NOW(),
NOW())
</insert>
<select id="getWorkerNodeByHostPort" resultMap="workerNodeRes">
SELECT
ID,
HOST_NAME,
PORT,
TYPE,
LAUNCH_DATE,
MODIFIED,
CREATED
FROM
WORKER_NODE
WHERE
HOST_NAME = #{host} AND PORT = #{port}
</select>
</mapper>启动类更改,扫描com.xfvape.uid.worker.dao
@MapperScan({"com.aaa.stock.mapper","com.xfvape.uid.worker.dao"})
@EnableAsync
@SpringBootApplication
public class StockApplication{
public static void main(String[] args) {
SpringApplication springApplication = new SpringApplication(StockApplication.class);
// 关闭打印启动图案
springApplication.setBannerMode(Banner.Mode.OFF);
springApplication.run(args);
}
}将uidGenerator集成到shardingsphere-jdbc的自定义id配置类中
public class KeyGenerator implements KeyGenerateAlgorithm {
private static UidGenerator uidGenerator;
/**
* 避免uidGenerator和shardingsphere-jdbc初始化时循环依赖,使用@Lazy注解后加载uidGenerator.
* 使用@Lazy注解后,调用uidGenerator方法为null,所以使用set赋值的方式而不是直接在uidGenerator上使用@Autowired.
* @param uidGenerator
*/
@Lazy
@Autowired
public void setUidGenerator(UidGenerator uidGenerator) {
KeyGenerator.uidGenerator = uidGenerator;
}
@Override
public Comparable<?> generateKey() {
// 生成id
return uidGenerator.getUID();
}
@Override
public void init() {
}
@Override
public String getType() {
// id生成名称对应yml文件中keyGenerator-xxx-type
return "uidGenerator";
}
}













 989
989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









