







channel有什么特点
channel有2种类型:无缓冲、有缓冲
channel有3种模式:写操作模式(单向通道)、读操作模式(单向通道)、读写操作模式(双向通道)

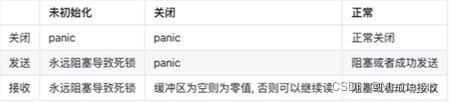
channel有3种状态:未初始化、正常、关闭
注意点:
1.一个channel不能多次关闭,会导致painc
2.如果多个goroutine都监听同一个channel,那么 channel 上的数据都可能随机被某一个goroutine取走进行消费
3.如果多个goroutine监听同一个channel,如果这个channel被关闭,则所有goroutine都能收到退出信号
channel的底层实现原理
概念:
Go中的channel是一个队列,遵循先进先出的原则,负责协程之间的通信(Go语言提倡不要通过共享内存来通信,而要通过通信来实现内存共享,CSP(CommunicatingSequentiall Process)并发模型,就是通过goroutine和channel来实现的)
使用场景
停止信号监听
定时任务
生产方和消费方解耦
控制并发数
底层数据结构:
通过var声明或者make函数创建的channel变量是一个存储在函数栈帧上的指针,占用8个字节,指向堆上的hchan结构体
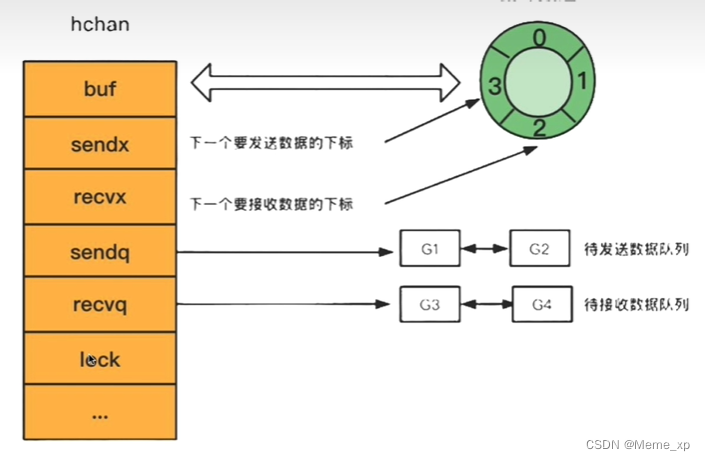

等待队列:
双向链表,包含一个头结点和一个尾结点
每个节点是一个sudog结构体变量,记录哪个协程在等待,等待的是哪个channel,等待发送/接收的数据在哪里

总结hchan结构体的主要组成部分有四个:
1.用来保存goroutine之间传递数据的循环数组:buf
2.用来记录此循环数组当前发送或接收数据的下标值:sendx和recvx
3.用于保存向该chan发送和从该chan接收数据被阻塞的goroutine队列: sendq和recvq
4.保证channel写入和读取数据时线程安全的锁:lock
有缓存channel和无缓存channel的区别
无缓冲:一个送信人去你家送信,你不在家他不走,你一定要接下信,他才会走。
有缓冲:一个送信人去你家送信,扔到你家的信箱转身就走,除非你的信箱满了,他必须等信箱有多余空间才会走。
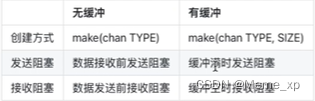
无缓存的channel有发送者必须有接收者,否则会报错,发生阻塞
channel为什么是线程安全
为什么设计成线程安全?
不同协程通过channel进行递信,本身的使用场景就是多线程,为了保证数据的一致性,必须实现线程安全
如何实现线程安全的?
channel的底层实现中, hchan结构体中采用Mutex锁来保证数据读写安全。在对循环数组buf中的数据进行入队和出队操作时,必须先获取互斥锁,才能操作chrnel数据
channel如何控制groutine并发执行顺序
多个goroutine并发执行时,每一个goroutine抢到处理器的时间点不一致,gorouine的执行本身不能保证顺序。"即代码中先写的gorouine并不能保证先执行
思路:使用channel进行通信通知,用channel去传递信息,从而控制并发执行顺序

输出:
groutine1
groutine2
groutine3
duration:1//证明了我们是并行的,否则应该是三秒
channel的共享内存有什么优劣?
大部分语言通过共享内存来通信,go是通过通信来共享内存(csp)
优点:
帮助解耦生产者和消费者
缺点:
容易出现死锁
channel什么时候容易死锁
死锁:
1.单个协程永久阻塞
2.两个或两个以上的协程的执行过程中,由于竞争资源或由于彼此通信而造成的一种阻塞的现象。
channel死锁场景:
1.非缓存channel只写不读
2.非缓存channel读在写后面
3.缓存channel写入超过缓冲区数量
4.空读
- 多个协程互相等待
创建,发送,接受,关闭
创建
//带缓冲
ch := make( chan int,3)
//不带缓冲
ch := make(chan int)
创建时会做一些检查:
·元素大小不能超过64K ·
元素的对齐大小不能超过maxAlign也就是8字节。
计算出来的内存是否超过限制
创建时的策略:
如果是无缓冲的channel,会直接给hchan分配内存 ·
如果是有缓冲的channel,并且元素不包含指针,那么会为hchan和底层数组分配一段连续的地址·
如果是有缓冲的channel,并且元素包含指针,那么会为hchan和底层数组分别分配地址
发送
阻塞式:
调用chansend函数,并且block=true
ch <- 10
非阻塞式:
调用chansend函数,并且block=false
select {
case ch c<-10:
...
default
}
向channel中发送数据时大概分为两大块:检查和数据发送,数据发送流程如下
1.如果channel的读等待队列存在接收者goroutine
。将数据直接发送给第一个等待的goroutine,唤醒接收的goroutine
2.如果channel的读等待队列不存在接收者goroutine
。如果循环数组buf未满,那么将会把数据发送到循环数组buf的队尾
。如果循环数组buf已满,这个时候就会走阻塞发送的流程,将当前goroutine加入写等待队列,并挂起等待唤醒
接收
阻塞式四种:
非阻塞式:

向channel中接收数据时大概分为两大块,检查和数据发送,而数据接收流程如下:
1.如果channel的写等待队列存在发送者goroutine
。如果是无缓冲channel,直接从第一个发送者goroutine那里把数据拷贝给接收变量,唤醒发送的goroutine
。如果是有缓冲channel(已满),将循环数组buf的队首元素拷贝给接收变量,将第一个发送者goroutine的数据拷贝到buf循环数组队尾,唤醒发送的goroutine
2.如果channel的写等待队列不存在发送者goroutine:
。如果循环数组buf非空,将循环数组buf的队首元素拷贝给接收变量
。如果循环数组buf为空,这个时候就会走阻塞接收的流程,将当前goroutine加入读等待队列,并挂起等待唤醒
关闭
close(ch)















 1315
1315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









