一、Scala 2.12.13安装
1、下载Scala,并查看其路径
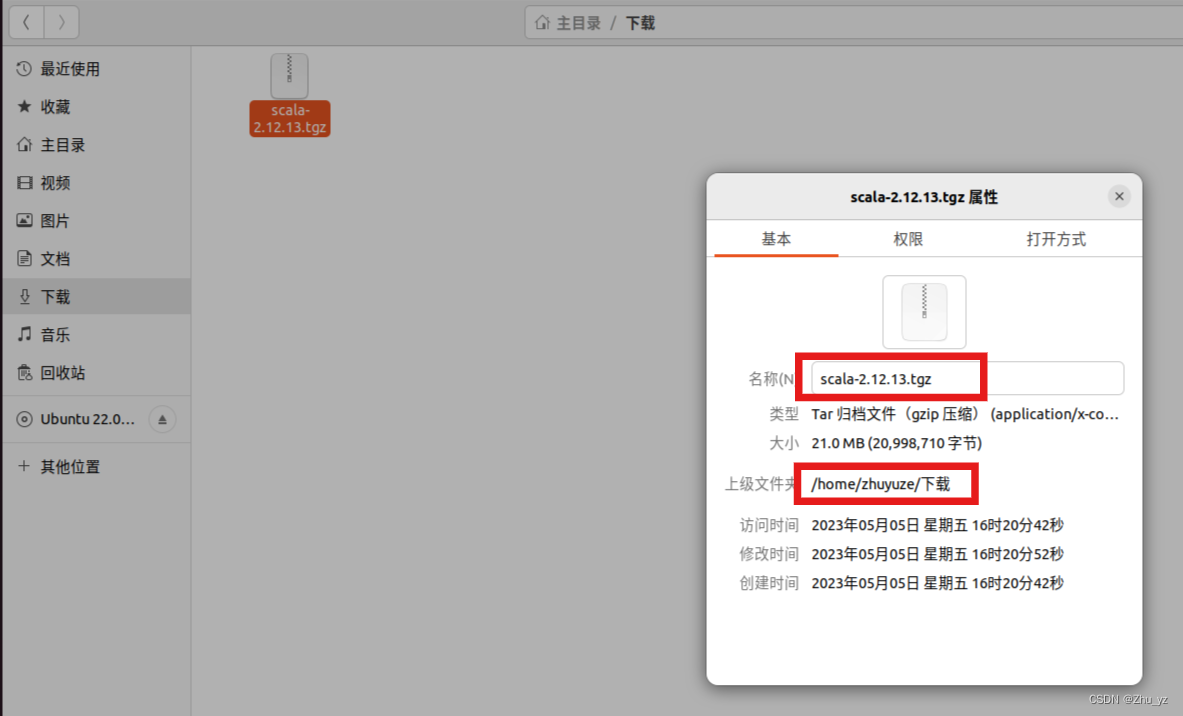
2、安装Scala并配置环境
(1)将下载的scala文件解压到/usr/local目录下并修改文件名为scala
sudo tar -zxf /home/zhuyuze/下载/scala-2.12.13.tgz -C /usr/local
cd /usr/local
sudo mv ./scala-2.12.13/ ./scala
(2)配置环境变量
vim ~/.bashrc
在文件最后输入以下代码(输入前先输入i)并保存后退出(Esc+:wq)
export SCALA_HOME=/usr/local/scala
export PATH=$SCALA_HOME/bin:$PATH
使环境变量生效
source ~/.bashrc
3、查看Scala版本
scala -version

4、Scala编程
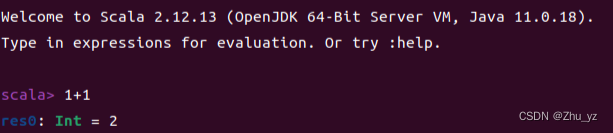
(1)使用scala
scala
(2)退出scala
:quit
二、spark安装并配置环境
1、下载安装spark,并查看路径
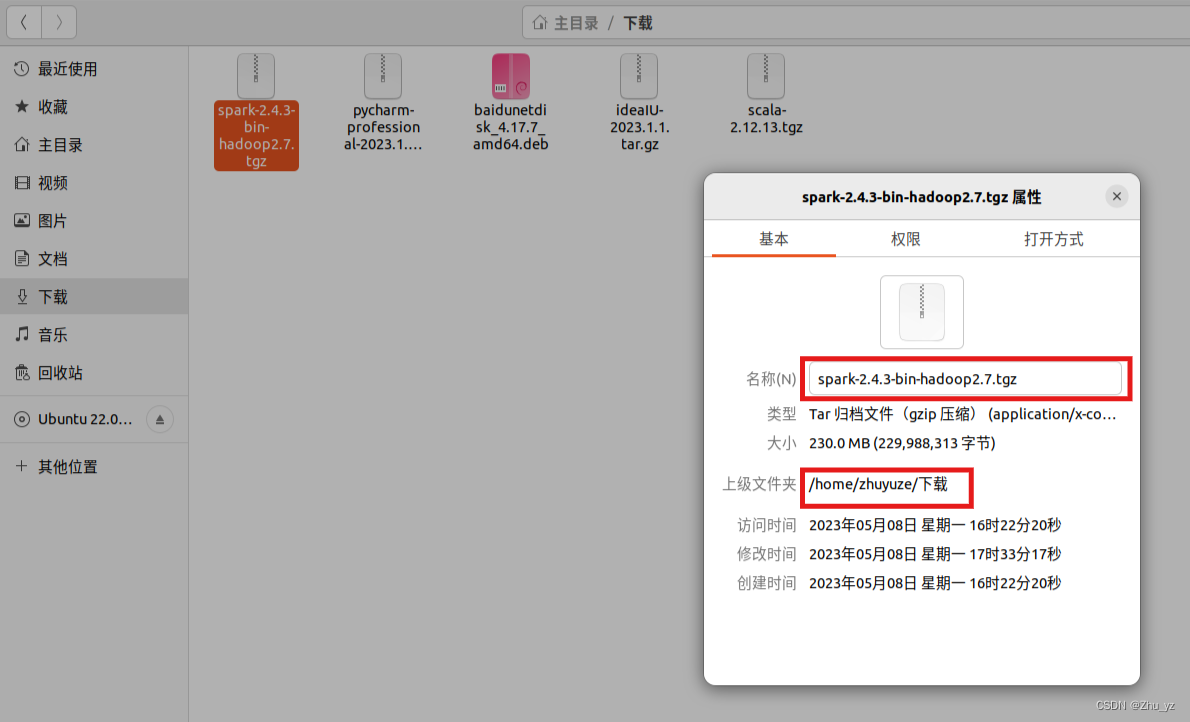
2、将spark解压到/usr/local路径下,并将文件名改为spark
sudo tar -zxf /home/zhuyuze/下载/spark-2.4.3-bin-hadoop2.7.tgz -C /usr/local
sudo mv ./spark-2.4.3-bin-hadoop2.7/ ./spark
3、为解压包创建一个软连接
cd /usr/local
ln -s spark/ spark
4、修改配置文件
cd spark/conf/
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
在文件最后添加配置内容,配置内容如下(根据自己的具体路径进行修改)
export JAVA_HOME=/usr/lib/jvm/default-java
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SCALA_HOME=/usr/local/scala
export SPARK_MASTER_IP=计算机名
export SPARK_MASTER_PORT=7077
计算机名一定要修改为自己的计算机名,以下图为例(命令行模式)

翻译一下:用户名@计算机名:当前路径$…
zhuyuze@hadoop:/usr/local$…
此计算机名为hadoop
5、配置环境变量
vim ~/.bashrc
在文件最后添加以下代码
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
保存使其生效
source ~/.bashrc
6、启动spark
/usr/local/spark/sbin/start-all.sh

7、查看进程
jps

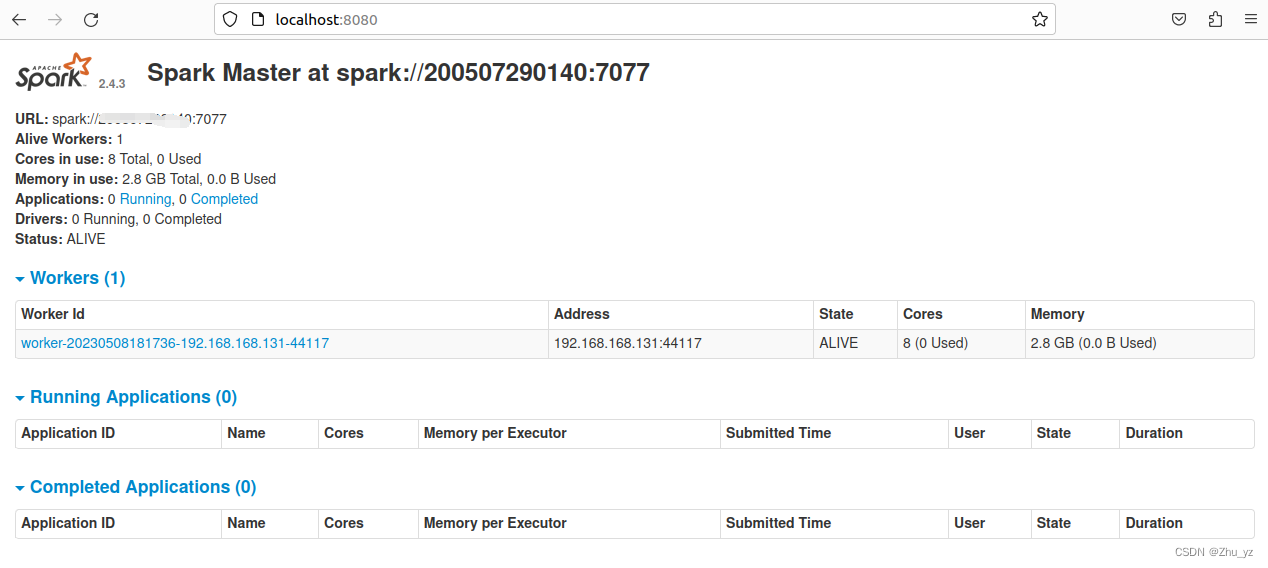
8、查看web界面
http://localhost:8080





















 1254
1254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









