







排序算法:冒泡、选择、插入、希尔、计数、桶排、基排、归并、快排(主要学的是归并和快排)、堆排序(我们 单独 放到一个帖子里 去讲解)。
二分算法:整数二分、浮点二分(整数二分是竞赛题目最喜欢考察的知识点)
1. 排序算法
排序算法:常常作为算法基础入门的 开篇学习内容。无论是 项目业务 还是 算法竞赛 都是必须要掌握的一个算法!排序往往 是 我们 在处理数据时 最常用的一个算法。
1.1 冒泡排序(Bubble Sort)
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法名字的由来 是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
时间复杂度:O(n^2) 空间复杂度:O(1)
1.1.1 算法描述
比较相邻的元素。如果第一个比第二个大,就交换它们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
重复步骤1~3,直到排序完成。
1.1.2 动图演示

1.1.3 代码实现
#include <iostream>
#include <vector>
using namespace std;
vector<int> arr = {5,4,3,2,1,-1,0};
void bubbleSort(){
int length = (int)arr.size();
for(int i = 0; i < length - 1; ++i){
for(int j = 0; j < length - 1 - i; ++j){
if(arr[j] > arr[j + 1]){
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
int main(void){
bubbleSort();
for(auto x : arr){
cout << x << " ";
}
}

1.2 选择排序(Selection Sort)
选择排序(Selection Sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。 在早些年间!它也是业务代码中低效率排序使用最多的一种。
时间复杂度:O(n^2) 空间复杂度:O(1)
1.2.1 算法描述
n个记录的直接选择排序可经过n-1趟直接选择排序得到有序结果。具体算法描述如下:
初始状态:无序区为R[1…n],有序区为空。
第i趟排序(i=1,2,3…n-1)开始时,当前有序区和无序区分别为R[1…i-1]和R(i…n)。该趟排序从当前无序区中-选出关键字最小的记录 R[k],将它与无序区的第1个记录R交换,使R[1…i]和R[i+1…n)分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区。
n-1 趟结束,数组则变为整体序化。
1.2.2 动图演示

1.2.3 代码实现
#include <iostream>
#include <vector>
using namespace std;
vector<int> arr = {5,4,3,2,1,-1,0};
void selectionSort(){
int length = (int)arr.size();
for(int i = 0; i < length - 1; ++i){
int minSub = i;
for(int j = i + 1; j < length; ++j){
if(arr[minSub] > arr[j]){
minSub = j; // 更新 最小元素的位置
}
}
if(minSub != i){
int temp = arr[minSub];
arr[minSub] = arr[i];
arr[i] = temp;
}
}
}
int main(void){
selectionSort();
for(auto x : arr){
cout << x << " ";
}
}

1.2.4 算法分析
表现最稳定的排序算法之一,因为无论什么数据进去都是O(n2)的时间复杂度,所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。理论上讲,选择排序可能也是平时排序一般人想到的最多的排序方法了吧。
1.3 插入排序(Insertion Sort)
插入排序(Insertion Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
in-palce:在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。使得额外空间仅仅只有O(1) 的程度!
时间复杂度:O(n^2) 空间复杂度:O(1)
1.3.1 算法描述
一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:
从第一个元素开始,该元素可以认为已经被排序。
取出下一个元素,在已经排序的元素序列中从后向前扫描。
如果该元素(已排序)大于新元素,将该元素移到下一位置。
重复步骤3,直到找到已排序的元素小于或者等于新元素的位置。
将新元素插入到该位置后。
重复步骤 2 ~ 5。
1.3.2 动图演示

1.3.3 代码实现
#include <iostream>
#include <vector>
using namespace std;
vector<int> arr = {5,4,3,2,1,-1,0};
void InsertionSort(){
int length = (int)arr.size();
for(int i = 1; i < length; ++i){
int preIndex = i - 1;// 当前有序区的最后一个元素
int current = arr[i];// 当前要插入的元素
while(preIndex >= 0 && arr[preIndex] > current){
// 所以要把 preIndex 往后移动一位
arr[preIndex + 1] = arr[preIndex];
preIndex--;// 然后 往前再看看 有没有 比 cureent 大的元素
}
arr[preIndex + 1] = current;
}
}
int main(void){
InsertionSort();
for(auto x : arr){
cout << x << " ";
}
}

1.3.4 算法分析
插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
1.4 希尔排序(Shell Sort)
1959 年 Shell 在其 插入排序的基础上 又发明了一种排序。即 第一个突破O(n2) 的排序算法 “希尔排序”,是简单插入排序的改进版。它与插入排序的不同之处在于,它会优先比较距离较远的元素。所以 希尔排序又叫 缩小增量排序。
时间复杂度:O(n^1.3 ~ n^2) 空间复杂度:O(1)
1.4.1 算法描述
先将整个待排序的记录序列分割成为若干子序列。再分别进行直接插入排序,具体算法描述:
选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1。
按增量序列个数k,对序列进行k 趟排序。
每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。

1.4.3 代码实现
#include <iostream>
#include <vector>
#include <math.h>
using namespace std;
vector<int> arr = {5,4,3,2,1,-1,0};
void ShellSort(){
int length = (int)arr.size();
for(int gap = floor(length / 2); gap > 0; gap = floor(gap / 2)){
// 第一个 for 循环 进行 增量的 分组
for(int i = gap; i < length; ++i){
// 此时 被插入的 元素 也就是下标 gap 的位置
int j = i;
int current = arr[i];
while(j - gap >= 0 && current < arr[j - gap]){
// 此时的 有序区第一个 元素 也就是 下标 j - gap 的位置
arr[j] = arr[j - gap];
j = j - gap;
}
arr[j] = current;
}
}
}
int main(void){
ShellSort();
for(auto x : arr){
cout << x << " ";
}
}

1.4.4 算法分析
希尔排序的核心在于间隔序列的设定。既可以提前设定好间隔序列,也可以动态的定义间隔序列。动态定义间隔序列的算法是《算法(第4版)》的合著者Robert Sedgewick提出的。
1.5 计数排序(Counting Sort)
计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。 就好像提前有个排好序的数组一般,然后你直接遍历就可以了!作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
时间复杂度:O(n+k) 空间复杂度:O(n+k)
1.5.1 算法描述
找出待排序的数组中最大和最小的元素。
统计数组中每个值为i的元素出现的次数,存入数组C的第i项。
对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)。
反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。

1.5.3 代码实现
#include <iostream>
#include <vector>
using namespace std;
const int maxNum = 5;
vector<int> arr = {5,5,5,4,4,2,3,1,2,0,1};
void countingSort(){
vector<int> brr;
brr.resize(maxNum + 1);
for(int i = 0; i < arr.size(); ++i){
brr[arr[i]]++;// 直接 计数就可以
}
for(int i = 0,j = 0; i < maxNum + 1; ++i){
while(brr[i] > 0){
arr[j++] = i;
brr[i]--;
}
}
}
int main(void){
countingSort();
for(auto x : arr){
cout << x << " ";
}
return 0;
}
1.5.4 算法分析
计数排序是一个稳定的排序算法。当输入的元素是 n 个 0到 k 之间的整数时,时间复杂度是O(n+k),空间复杂度也是O(n+k),其排序速度快于任何比较排序算法。当k不是很大并且序列比较集中时,计数排序是一个很有效的排序算法。
1.6 桶排序(Bucket Sort)
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。桶排序 (Bucket sort)的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排)。
时间复杂度:O(N + C),C=N*(logN-logM) 空间复杂度:O(N + M)
1.6.1 算法描述
设置一个定量的数组当作空桶。
遍历输入数据,并且把数据一个一个放到对应的桶里去。
对每个不是空的桶进行排序。
从不是空的桶里把排好序的数据拼接起来。
1.6.2 动图演示

1.6.3 代码实现
#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath>
using namespace std;
vector<int> arr= {1,45,32,23,22,31,47,24,4,15};
void bucketSort(){
vector<vector<int>> bucket;
bucket.resize(5);
int maxNum = arr[0];
for(int i = 1; i < arr.size(); ++i){
if(maxNum < arr[i]){
maxNum = arr[i];
}
}
for(int i = 0; i < arr.size(); ++i){
// 这里 指针对 我们 提供的 数据 做了 一个 简单的映射
int index = arr[i] / (maxNum / 5 + 1) ; // 确定元素存放的 桶号
cout << "arr[i]:" << arr[i] << " index:" << index << endl;
bucket[index].push_back(arr[i]);
}
int k = 0;
for(int i = 0; i < bucket.size(); ++i){
sort(bucket[i].begin(),bucket[i].end());
for(int j = 0; j < bucket[i].size(); ++j){
arr[k++] = bucket[i][j];
}
}
}
int main(void){
bucketSort();
for(auto x : arr){
cout << x << " ";
}
return 0;
}
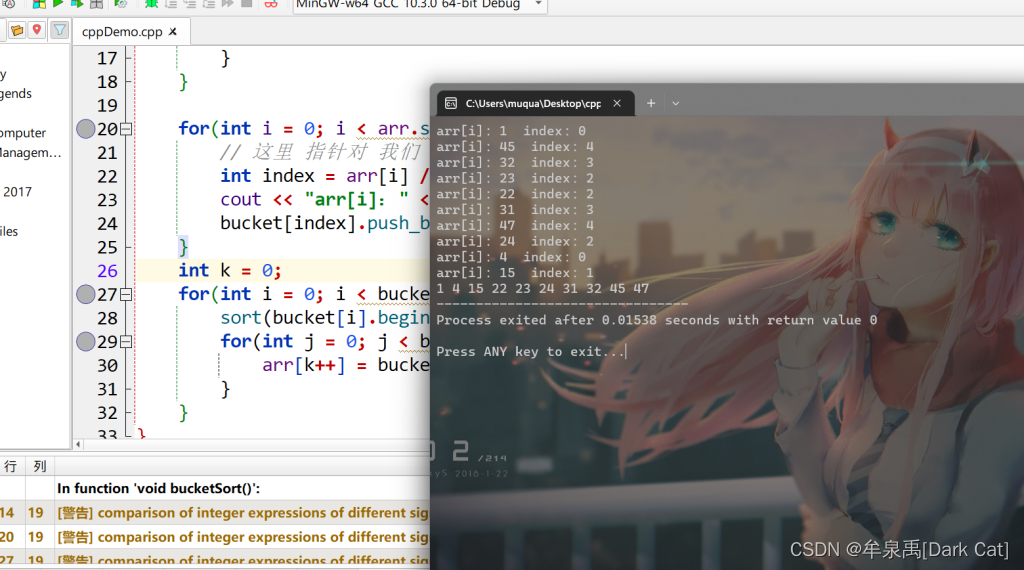
1.6.4 算法分析
**桶排序最好情况下使用线性时间O(n),桶排序的时间复杂度,取决与对各个桶之间数据进行排序的时间复杂度,因为其它部分的时间复杂度都为O(n)。很显然,桶划分的越小,各个桶之间的数据越少,排序所用的时间也会越少。但相应的空间消耗就会增大。 **
1.7 基数排序(Radix Sort)
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。
时间复杂度:O(d*2n) 空间复杂度:O(n+k)
1.7.1 算法描述
取得数组中的最大数,并取得位数。
arr为原始数组,从最低位开始取每个位组成radix数组。
对radix进行计数排序(利用计数排序适用于小范围数的特点)。

1.7.3 代码实现
#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath>
using namespace std;
vector<int> arr= {3,44,38,5,47,15,36,26,27,2,46,4,19,50,48};
void radixSort(){
vector<vector<int>> Radix;
Radix.resize(10);// 0 ~ 9 九个 基础数
for(int i = 0; i < arr.size(); ++i){// 先 个位
Radix[arr[i] % 10].push_back(arr[i]);// 然后 把它 放进 Radix 数组里
}
int k = 0;
for(int i = 0; i < Radix.size(); i++){
for(int j = 0; j < Radix[i].size(); ++j){
arr[k++] = Radix[i][j];
}
}
k = 0;
Radix.clear();
Radix.resize(10);// 0 ~ 9 九个 基础数
for(int i = 0; i < arr.size(); ++i){// 然后 十位
Radix[arr[i] / 10].push_back(arr[i]);// 然后 把它 放进 Radix 数组里
}
for(int i = 0; i < Radix.size(); i++){
for(int j = 0; j < Radix[i].size(); ++j){
arr[k++] = Radix[i][j];
}
}
}
int main(void){
radixSort();
for(auto x : arr){
cout << x << " ";
}
return 0;
}

1.7.4 算法分析
基数排序基于分别排序,分别收集,所以是稳定的。但基数排序的性能比桶排序要略差,每一次关键字的桶分配都需要O(n)的时间复杂度,而且分配之后得到新的关键字序列又需要O(n)的时间复杂度。假如待排数据可以分为d个关键字,则基数排序的时间复杂度将是O(d*2n) ,当然d要远远小于n,因此基本上还是线性级别的。
基数排序的空间复杂度为O(n+k),其中k为桶的数量。一般来说n>>k,因此额外空间需要大概n个左右。
1.8 归并排序(Merge Sort)
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为 二路归并。
时间复杂度:O(nlogn) 空间复杂度:O(N)
1.8.1 动图演示

1.8.2 算法描述
归并思想 也可以说是 分治法的思想
1. 现在 我以 整个数组的 中间为基准 分为 两个部分,左区间 和 右区间
2. 不断地 进行 这样的 分区间操作,直到 当前区间 只有 一个元素为止,我们就可以归并了
3. 归并的意思是 把两个区间的 元素 进行比较,看看 哪个元素 应该放到 第 n 个位置。这时候要有个辅助空间,来进行存储该元素。
归并:合二为一 !!!(两个 有序的序列 合并为一个 有序的序列,这个其实 也是 双指针算法!)
比如 3 4 和 1 2。
3 > 1 所以 1 肯定 是放在 第一个位置的,然后 第二个序列 指针往后移动一位,到 2 这个值。
3 > 2 所以 2 又是 第二个 位置,然后 第二个序列 指针往后移动 一位,
正好超过了 第二个序列的长度。
此时,第二个序列的 区间 已经 没有元素可以扫描,那么 就按照 另一个区间原本的顺序
直接把剩余元素 插入到 辅助空间的后面。
因为 每个区间 不断的 分成两个区间,那么 整个过程 很好计算得到 log2n 次的分区操作。
而 每次 归并的操作 都是 O(n) 的 时间复杂度,所以整体是 真正的 nlogn 复杂度!
1.8.3 代码实现
#include <iostream>
using namespace std;
const int maxN = 1e6 + 5;
int tmp[maxN];
void merge_sort(int *q, int l, int r){
if(l >= r)return;
int mid = l + r >> 1;
merge_sort(q,l,mid);
merge_sort(q,mid + 1,r);
int k = 0, i = l, j = mid + 1;
while(i <= mid && j <= r){
if(q[i] <= q[j]) tmp[k++] = q[i++];
else tmp[k++] = q[j++];
}
while(i <= mid) tmp[k++] = q[i++];
while(j <= r) tmp[k++] = q[j++];
for(i = l,j = 0; i <= r; i++,j++)q[i] = tmp[j];
}
int q[maxN];
int main(void){
int n;
cin >> n;
for(int i = 0; i < n; ++i){
scanf("%d", &q[i]);
}
merge_sort(q,0,n-1);
for(int i = 0; i < n; ++i){
printf("%d ", q[i]);
}
return 0;
}
1.8.4 算法分析
归并排序是一种稳定的排序方法。而且时间复杂度也十分的稳点!这与选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(nlogn)的时间复杂度。代价是需要额外的内存空间。
1.9 快速排序(Quick Sort)
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
时间复杂度:O(nlogn ~ n^2) 空间复杂度:O(1)
1.9.1 算法描述
快排 的主要思想 也是 分治法
原理思想如下:
① 确定分界点(中间点)有大体四种选择:q[l],q[r],q[(l+r)/2],q[随机sub]
② 重点在于 调整区间:分界点会 把区间分为两块,左边要保证 小于等于 分界点的数值 右边要保证 大于等于 分界点的数值
③ 递归 反复的 给 左右区间 取分界点,然后在此基础上 反复再分为两个区间,进行 调整区间操作。即可排序!
快排实现方法 还是很多的,有一种实现方法 很简单 需要开辟额外的空间(有点儿 像 归并的其中一步操作)
首先开辟 三个 数组 a[] b[] q[]
q[l - r] 如果 q[i] <= x 就放到 a[]里,如果 q[i] >= x 就放到 b[]里
先把 a[] 的数 放到 q[] 里,再把 b[] 的数 放到 q[] 里
然后 也是 递归 要 反复的 分区间,进行 这样的操作,也可以实现 快排。
这里再介绍的一个方法 是 利用 双指针 扫一个数组的方法
代码思想如下:
1. 先弄两个 指针i,j 来记录 两侧被扫元素 的位置,两个指针 都类似于 检察员,再选一个分界点的数值 存起来
2. 左侧指针 如果扫到 >= x 的就代表着 这个元素不该在 左区间,那么就停下来 让右侧指针开始扫,看看是否 扫到了可以交换的元素
3. 右侧指针 如果扫到 <= x 的就代表着 这个元素不该在 右区间,那么就停下来 看左侧指针是否 扫到了可以交换的元素
4. 如果扫来扫去,i >= j了,就代表着相遇了,或者说 扫过头了,那么 其实 也就代表着 左右区间处理完了。
5. 那么此时此刻,我们 选择 j 作为 分界点,正好是 分为正确的 两个区间
当然也有更好理解,更好写的 双指针 扫一个数组的方法。
1. 先弄两个 指针i,j 来记录 两侧被扫元素 的位置,两个指针 都类似于 检察员
2. 选一个 分界点,在扫的时候 不要去 扫描这个分界点的数值。
3. 比如 分界点是 q[l],那么 左侧指针 i 就应该 从 l+1 开始。
4. 左侧指针 如果扫到 >= x 的就代表着 这个元素不该在 左区间,那么就停下来 让右侧指针开始扫,看看是否 扫到了可以交换的元素
5. 右侧指针 如果扫到 <= x 的就代表着 这个元素不该在 右区间,那么就停下来 看左侧指针是否 扫到了可以交换的元素
6. 两个指针 可以扫描的 前提是 i必须 < 数组的右边界,j 必须 大于 0
7. 并且 我们 扫完后,判断一下 i 是否 >= j ,如果是的话,那么 就把 q[i] 和 分界点 q[l] 进行交换,让分界点 来到最适合的位置
8. 如果 i < j 的话,那么 我们就正常 进行 q[i] 和 q[j] 的交换即可。交换完事后,i++,j-- 两个指针 往下再扫一个。以便于下次判断
1.9.2 动图演示

1.9.3 代码实现
#include <bits/stdc++.h>
using namespace std;
// 一定要 熟练的 用 scanf() 输入 和 printf() 输出
// 因为 要比 cin 和 cout 快了 不老少
const int N = 1e6 + 10;
int q[N];
void quick_sortA(int q[],int l,int r){
if(l >= r)return;// 那就代表着 不需要分区间,也不需要排序了
int x = q[l],i = l - 1,j = r + 1;
while(i < j){
do i++; while(q[i] < x);
do j--; while(q[j] > x);
if(i < j) swap(q[i],q[j]);
}
quick_sortA(q,l,j);
quick_sortA(q,j + 1,r);
}
void quick_sortB(int q[],int l,int r){
if(l >= r)return;
int x = q[r], i = l - 1, j = r -1;
while(i < j){
do i++; while(q[i] < x);
do j--; while(q[j] > x);
if(i < j) swap(q[i],q[j]);
}
quick_sortB(q,l,i - 1);
quick_sortB(q,i,r);
}
void quick_sortC(int q[],int l,int r){
if(l >= r)return;
int x = q[r],i = l,j = r - 1;
while(true){
while(i < r && q[i] < x){
i++;
}
while(j > l && q[j] > x){
j--;
}
if( i < j)swap(q[i++],q[j--]);
else break;
}
swap(q[r],q[i]);
quick_sortC(q,l, i - 1);
quick_sortC(q,i + 1,r);
}
int main(void){
int n;
scanf("%d",&n);
for(int i = 0; i < n; ++i){
scanf("%d",&q[i]);
}
quick_sortC(q,0,n-1);
for(int i = 0; i < n; ++i){
printf("%d ",q[i]);
}
return 0;
}
















 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









