







数据结构第二章——开启数据结构的正文内容
第一章那个 绪论在这里:数据结构总结一
写得挺详细的(数据,数据项,数据元素,数据对象,数据结构,逻辑结构,存储结构,操作,算法和算法优劣性的评价(常考算法的性质,算法的评价标准))。
前话
数据结构的章节结构:
总复习的时候 ,可以参考这个博主画的数据结构知识结构总图—— 大话数据结构
第二章线性表
一、线性表的定义
■ 线性表是n个具有相同类型数据元素的有限序列。
属于线性结构,如果是非空表(n>0),只有一个表首元素,一个表尾元素。并且除表首元素以外,每一个元素都有一个直接前驱,除表尾元素以外,每一个元素都有一个直接后继。
■ 线性表具有三个特征:
1.同一性: 线性表由相同类型的数据元素组成,每个元素属于同一数据对象。
2.有限性:线性表是由有限个数据元素组成,表中数据元素的个数就是表的长度。
3.有序性:线性 表中相邻的数据元素间存在序偶关系<a;, a:+1>。
■ 线性表抽象数据类型定义:ADT List
元素关系:序偶组成的有穷序列。
ADT List{
数据对象: D={a|a.EElemSet; 1sisn,n20;}
数据关系: R={<a,a+1>| a, anED,i=1,2…n-1}
基本操作:
InitList(&L) 建立空表 DestroyList(&L) 销毁表
ClearList(&L) ListEmpty(L)
ListLength(L) GetElem(L,i,&e)
LocateElem(L,e) ListInsert(&L,i,e)
} ADT List ;
二、顺序表表示和实现
■ 物理相邻表示逻辑相邻。
■ .随机存取
动态数组来定义它的表示。
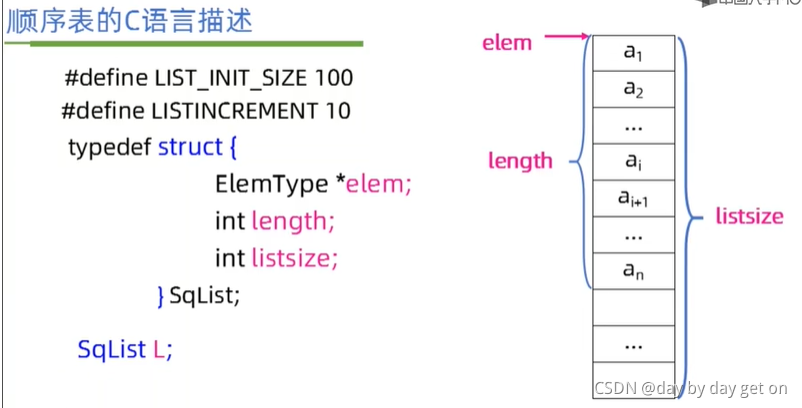
typdef struct{
}XXXX; 即给{}这个结构体类型 一个别名 如上,即为声明一个名为SqList的结构体类型
主要操作函数
#define LIST_INIT_SIZE 100
#define LISTINCREMENT 10
#define OK 1
#define ERROR 0
#define OVERFLOW -2
#define ElemType int
#include<bits/stdc++.h>
using namespace std;
typedef int Status;
typedef struct{
ElemType *elem;
int length; //长度
int listsize; //空间大小
}SqList;
SqList L;
int n;
//创建空表 注意哪些地方需要引用
Status InitList(SqList &L)
{
//用malloc分配一段这么LIST_INIT_SIZE*sizeof(ElemType)多个字节的内存段
//Elemtype这个结构体的LIST_INIT_SIZE的乘积这么大
//它返回一个指向该内存段首字节的指针变量(viod*),然后把这个指针变量强制转换为ElemType*类型
//再把这个经转换的指针变量赋给L的elem成员
L.elem = (ElemType*)malloc(LIST_INIT_SIZE*sizeof(ElemType));
if(!L.elem) exit(OVERFLOW);
L.length = 0;
L.listsize = LIST_INIT_SIZE;
return OK;
}
//创建非空表
Status NInitList(SqList &L)
{
L.elem = (ElemType*)malloc(LIST_INIT_SIZE*sizeof(ElemType));
if(!L.elem) exit(OVERFLOW);
cin>>n;
for(int i=0;i<n;i++) cin>>L.elem[i];
L.length = n;
L.listsize = LIST_INIT_SIZE;
return OK;
}
//输出
void OutPutList(SqList L){
for(int i = 0; i <L.length ;i++){
cout<<L.elem [i]<<" ";
}
cout<<endl;
}
//求表长
Status GetlenList(SqList L){
return L.length;
}
//查找对应值 所在的位置 复杂度O(n)
int LocateElem(SqList L,ElemType e){
int i = 0;
for(; i<L.length&&L.elem[i]!=e; i++);
if(i<=L.length) return i;
else return 0;
}
//按位置查找 用e把第i位置的值带出来
int GetElem(SqList L,int i,ElemType &e){
if(i<1||i>L.length +1) return ERROR; //判断i位置是否合理
e = L.elem[i-1];
return OK;
}
//顺序表的插入 复杂度 O(n)
Status LIstInsert(SqList &L,int i,ElemType e){
if(i<1||i>L.length +1) return ERROR; //判断i位置是否合理
//空间的继续分配问题 空间还够吗?的问题
ElemType *newbase,*p,*q;
if(L.length >= L.listsize )
newbase = (ElemType*)realloc(L.elem ,(L.listsize+LISTINCREMENT)*sizeof(ElemType));
if(!newbase) exit(OVERFLOW);
L.elem = newbase; L.listsize += LISTINCREMENT;
//移动元素 完成插入 (用指针是实现版本)
q = &(L.elem[i-1]) ; //q指向第i个元素
for(p = &(L.elem[L.length-1]);p>=q;p--) *(p+1) = *p;
*q = e;
++L.length ;
return OK;
}
//删除元素 将删除值 用e带出来
//复杂度 O(n)
Status ListDelete(SqList &L,int i,ElemType &e){
if(i<1||i>L.length +1) return ERROR; //判断删除位置的合理性
//获得 被删元素值
//移动元素
ElemType *p,*q;
p = &(L.elem[i-1]);
e =*p;
q = L.elem + L.length -1;
for(++p;p<=q;p++) *(p-1)= *(p) ;
--L.length; //易忘记
return OK;
}
//销毁表
void SL_Free(SqList &L)
// 释放/删除 顺序表
{
free(L.elem );
}
//清空表
void claerList(SqList &L)
{
L.length = 0;
}
int main(){
return 0;
}
三、链式表示和实现

单链表 结点和结点指针的声明与定义 
LNode 为结点类型
LinkList 为结构指针类型
四、顺序存储和链式存储各自的优缺点及其比较和选择
顺序存储:
顺序存储的优点:
1、逻辑结构与物理结构是统一的,其中的元素都是顺序存储的;
2、方法简单,好理解,各种语言中都有数组,易实现;
3、不用为结点间的逻辑关系而增加额外的存储空间;
4、表中数据元素可随机存取,顺序表具有按元素序号随机访问的特点;
5、 存储密度大,存储密度为1(存储密度是指一个结点中数据元素所占的存储单元和整个结点所占的存储单元之比)。
顺序存储的缺点:
1、做插入、删除操作时,要移动大量元素,因此对很长的顺序表操作效率低,插入和删除操作不方便;
2、要预先分配存储空间,预先估计过大,会导致存储空间浪费,估计过小,会造成数据溢出。
链式存储:
链式存储的优点:
1、做插入、删除操作时很方便,不需要移动数据元素,动态性强;
2、不用预先估计存储空间的规模。
链式存储的缺点:
1、链式存储的操作是基于指针的,但不是所有的语言中都有指针类型;
2、对每个数据元素而言,除了自身信息外,还需要一起存放其后继存储单元的地址,这两部分共同组成一个结点;
3、存储密度小,存储密度小于1;
4、表中数据元素不可随机存取。
顺序存储和链式存储的比较和选择:
1、基于存储空间:
顺序表的存储空间是静态分配的,在程序执行之前必须明确规定它的存储规模。链表不用事先估计存储规模,但链表的存储密度较低。顺序存储结构的存储密度是1,而链式存储结构的存储密度小于1。
2、基于运算:
在顺序表中按序号访问aiai的时间复杂度为O(1),而链表中按序号访问的时间复杂度为O(n)。
3、基于环境:
顺序表容易实现,在任何高级语言中都有数组类型,链表的操作是基于指针的,相对来讲顺序表简单些。
一般来讲,较稳定的线性表选择顺序存储,而频繁的做插入、删除操作的动态性较强的线性表选择链式存储更为合适。
五、some易错问题
1.在单链表中设置头结点的作用:
主要是使插入和删除等操作统一,在插入或删除第一个结点时不需另作判断。另外,不论链表是否为空,链表指针不变
2.消除递归不一定需要用到栈
如:

3.已知循环队列Q.base[0…m-1],队首和队尾指针分别为Q.front和Q.rear,队列满的条件是 。队列空的条件 。
(Q.rear+1)%m = Q.front ; Q.front = Q.rear
3.判断: 数据元素可以由类型互不相同的数据项构成。 对!
数据元素(data element)是计算机科学术语。它是数据的基本单位,数据元素也叫做结点或记录。在计算机程序中通常作为一个整体进行考虑和处理。有时,一个数据元素可由若干个数据项组成,例如,一本书的书目信息为一个数据元素,而书目信息的每一项(如书名、作者名等)为一个数据项。数据项是数据的不可分割的最小单位。
而数据对象 才是具有相同性质的数据元素的集合
这个人身上的东西和他 总是臭味相同
4.(neuDS)算法必须有输出,但可以没有输入。
算法可以不要输入,算法按照自身的初始状态执行下去就可以了算法必须要有输出,不然没有输出的话算法还有什么用呢
5.线性表中的所有数据元素的数据类型必须相同。
6.循环队列的引入,目的是为了 。
克服假溢出时大量移动数据元素














 783
783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









