







目录
一、矩阵超级基础的内容
1.创建一个1行6列的矩阵
a =[1 2 3 8 7 4]
2.对矩阵中每个元素都加3
(线代里面只有和规格的才能加减)
在Matlab里面,如果一个操作数是标量,而另一个操作数不是标量,MATLAB会将该标量隐式扩展到与另一个操作数具有相同的大小
b=a+3
结果:
a =
1 2 3 8 7 4
b =
4 5 6 11 10 7
3.plot函数作图。
以索引为横坐标。索引就是该数字在矩阵里是"第几个"
plot(b)
grid on
grid on 是添加网格线的意思
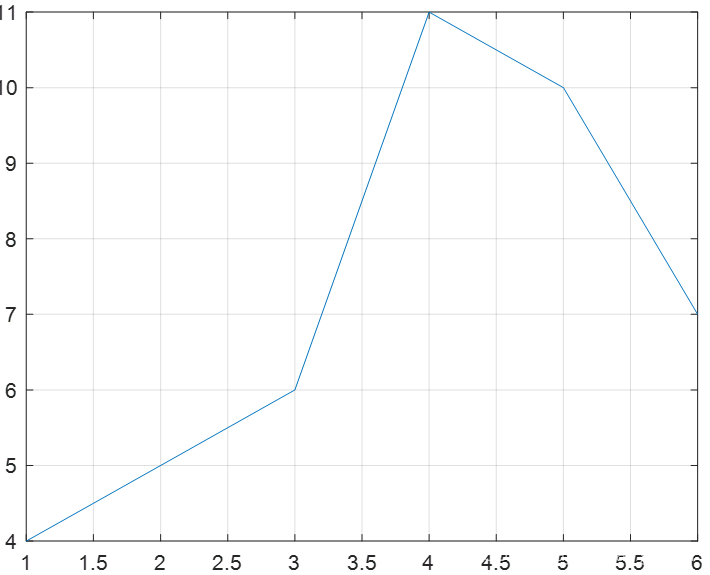
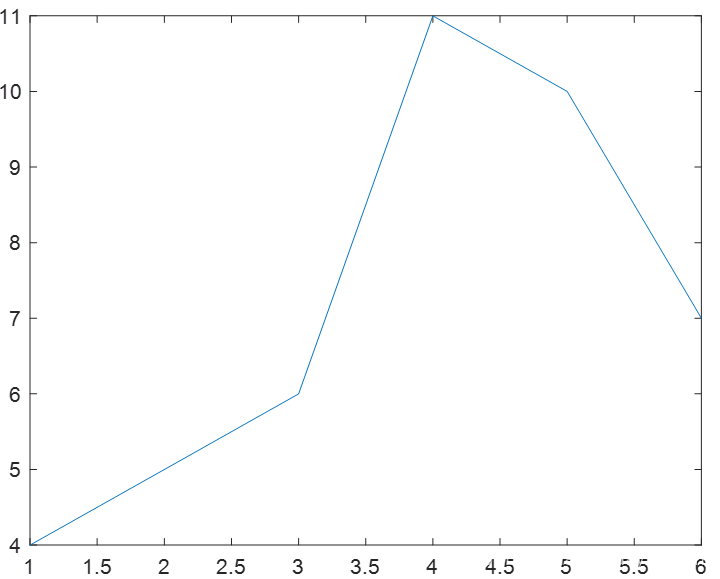
索引为横坐标,数组的值就是函数的纵坐标值
4.多维矩阵与常见运算
以空格或逗号分隔同一行元素, 分号分隔各行
常见运算:转置、取逆、求特征值和特征向量
A = [3 2 1;2 4 1;3 9 2]
B = A' %求转置矩阵
[D,V] = eig(A) %特征值 特征向量
E = inv(A) %求逆矩阵
F = A*E %验证结果是否为单位矩阵
结果:
A =
3 2 1
2 4 1
3 9 2
B =
3 2 3
2 4 9
1 1 2
D =
-0.3534 -0.5691 -0.2508
-0.4152 0.1144 -0.1181
-0.8383 0.8143 0.9608
V =
7.7217 0 0
0 1.1673 0
0 0 0.1109
E =
-1.0000 5.0000 -2.0000
-1.0000 3.0000 -1.0000
6.0000 -21.0000 8.0000
F =
1 0 0
0 1 0
0 0 1
5.矩阵乘法,和矩阵点乘
C =A*B %矩阵乘法
D = A.*B %矩阵点乘,即对应元素相乘
结果:
C =
14 15 29
15 21 44
29 44 94
D =
9 4 3
4 16 9
3 9 4
6.使用矩阵A对方程A*x= b求解
方法是使用\ (反斜杠)运算符,即A的逆矩阵乘以矩阵b
b =[1;3;5]
x = A\b
A
%验证一下
t = A*x-b %结果应该为0
结果如下:
b =
1
3
5
x =
4
3
-17
A =
3 2 1
2 4 1
3 9 2
t =
0
0
0
7.Matlab的迁就补全(标量非标量,不同维度)
在Matlab里面,如果一个操作数是标量,而另一个操作数不是标量,MATLAB会将该标量隐式扩展到与另一个操作数具有相同的大小
H = [1 1 1; 2 2 2;3 3 3]
K = 4
L = K*H %运算时,K变为3X3的对角矩阵,对角线上都是4
M = K+H %运算时,K编程3X3的矩阵,每个元素都是4
结果:1.得到 4乘以每一个元素;2得到4加上每一个元素
L =
4 4 4
8 8 8
12 12 12
M =
5 5 5
6 6 6
7 7 7
不同维度的行向量和列向量相加
N = [1 2 3 4]
P =[5;6;7]
Q = N+P
结果:
N =
1 2 3 4
P =
5
6
7
Q =
6 7 8 9
7 8 9 10
8 9 10 11
一般不要进行这种不同维度的矩阵运算!
二、Matlab四种常见二维图
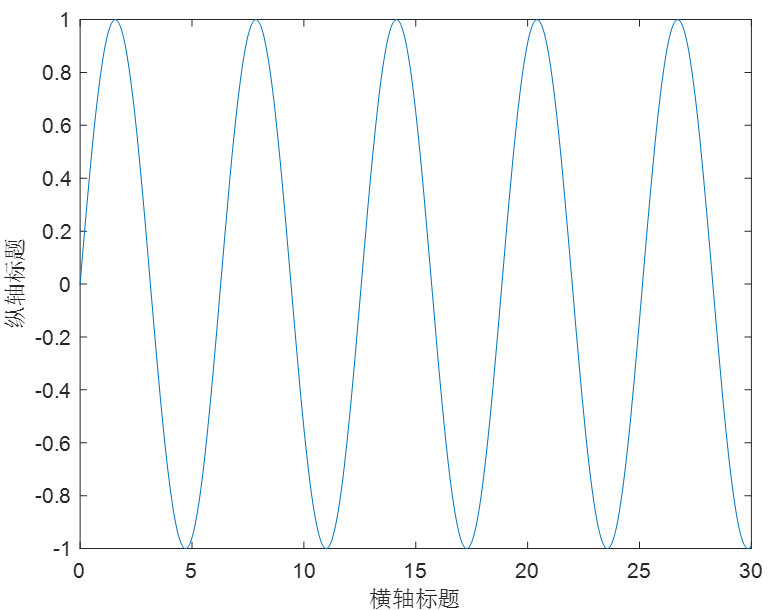
1.线图
🎄plot函数用来创建x和y值的简单线图。
x = 0:0.05:30; %从0到30,每隔0,05取一次值
y = sin(x);
plot(x,y); %以x的值为横坐标 以y为纵坐标做线性图
% 若(x,y,'LineWidth',2)可变粗
xlabel("横轴标题") %横轴标签
ylabel("纵轴标题")
%grid on %显示网格
%axis([0,20,-1.5,1.5]) %设置横纵坐标范围
原始图:
改变范围前后对比图:
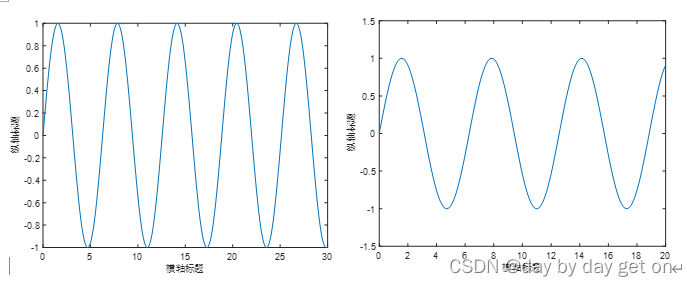
如果增大间距: 一般的画图间距是:0.05
间距变大的话,直接变得有棱有角的,对于函数图来说,不精细。但是如果只是折线图的话,就完全可以。
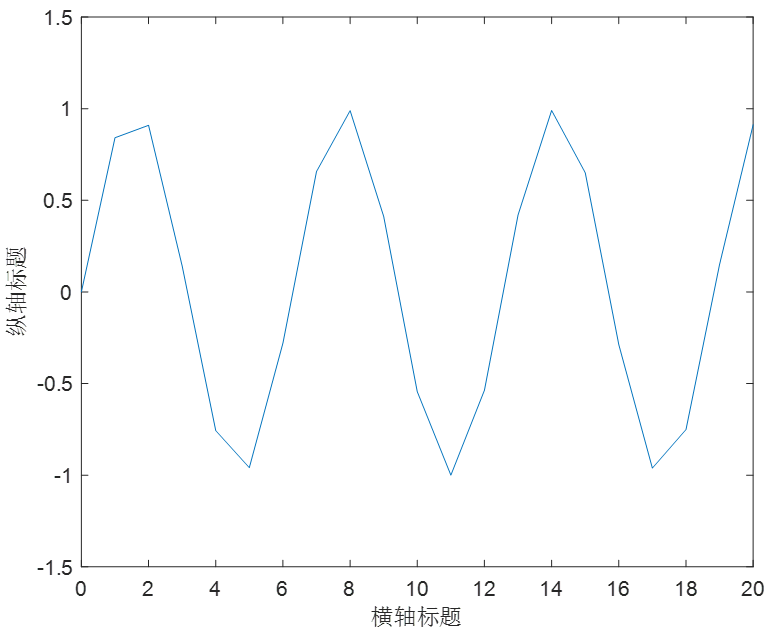
plot函数改颜色粗细合集:
改粗细:
plot(x,y,'LineWidth',2); %要再改大就把2变为3
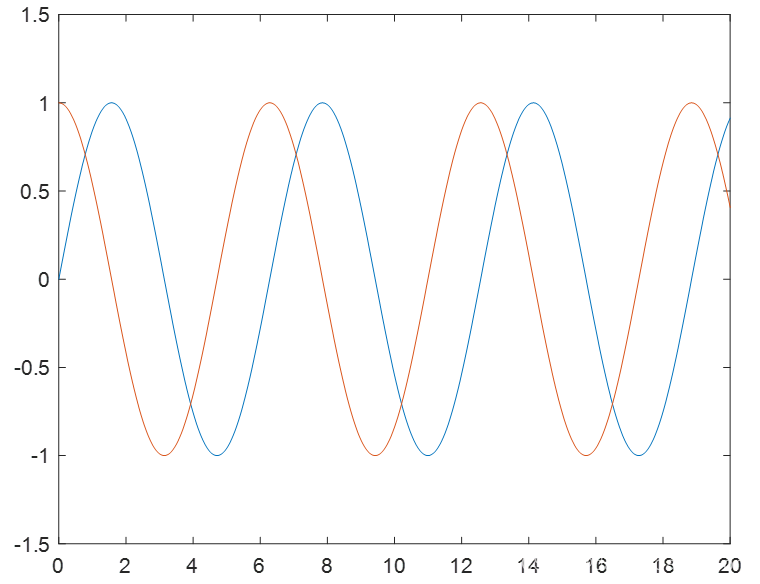
🎄多组函数显示在同一张图
y1 = sin(x)
y2 = cos(x)
plot(x,y1,x,y2)
axis([0,20,-1.5,1.5]) %X,Y的取值范围 可调节
2.条形图
bar函数创建重直条形图
barh函数用来创建水平条形图
t = -3:0.5:3;
p = exp(-t.*t); %函数 exp 就是自然对数e 底数是e 指数就是负t方
bar(t,p)
barh(t,P)
运行结果:
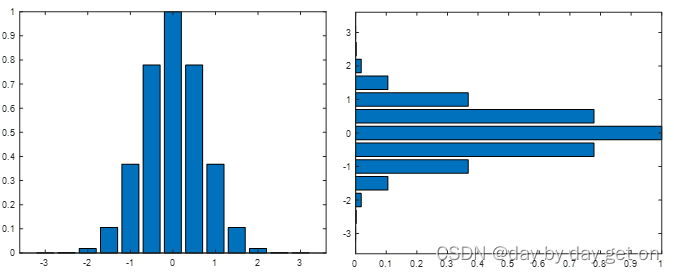
这两张图在我电脑上是 一张一张出来的,有点儿不方便,得取找找之前数学实验,婷姐的做法
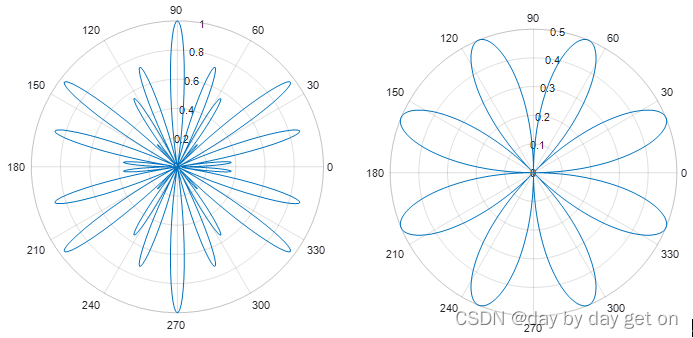
3.极坐标图
polarplot函数用来绘制极坐标图
th = 0:0.01:2*pi;
%abs 求绝对值或复数的模
radi = abs(sin(7*th).*cos(10*th));
%radi = abs(sin(2*th).*cos(2*th));
polarplot(th,radi)
运行结果:
4.散点图
scatter函数用来绘制x和y值的散图
Height = randn(1000,1); %生成符合正态分布的随机数
Weight = randn(1000,1);
scatter(Height,Weight)
xlabel( 'Height')
ylabel( 'Wesght')
注意:
✨自己给数据作图
Height = randn(1000,1); %把这个改为自己的数据 矩阵形式存储数据 再调用画图函数就行
✨随机数函数
randn(1000,1); %生成符合正态分布的随机数 最大为1000 最小为1
备战 数学建模:https://blog.csdn.net/nuist_NJUPT/article/details/123945181
三、Matlab三维图
1.三维曲面图
surf函数可用来做三维曲面图。
常见用法:surf(X,Y,Z)或者surf(X)
首先需要用meshgrid创建好空间上(x,y)点
[X,Y] = meshgrid(-2:0. 2:2); %设置不同的步长(间距)影响观感
%Z = X.^2+Y.^2
Z = X.*exp(-X.^2-Y.^2);
surf(X,Y,Z);
%colormap hsv
% colormap %设置颜色,可跟winter、 summer等 hsv默认色
%colorbar
结果:左边经典色,右边是冷色系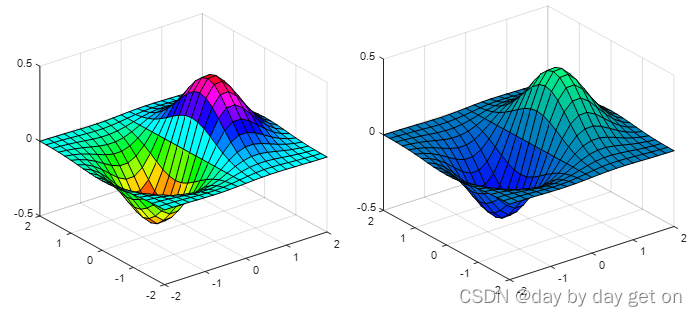
介绍一下surf函数的用法:
✨ surf(X,Y,Z)
创建一个三维曲面图,它是一个具有实色边和实色面的三维曲面。该函数将矩阵 Z 中的值绘制为由 X 和 Y 定义的 x-y 平面中的网格上方的高度。曲面的颜色根据 Z 指定的高度而变化。
✨surf(X,Y,Z,C) 指定曲面的颜色。
✨surf(Z)
创建一个曲面图,并将 Z 中元素的列索引和行索引用作 x 坐标和 y 坐标。
✨surf(Z,C) 指定曲面的颜色。
meshgrid函数用来生成网格矩阵,既可以是二维网格矩阵,又可以是三维网格矩阵。
1、[X,Y] = meshgrid(x,y) :基于向量x和y中包含的坐标返回二维网格坐标。X是一个矩阵,每一行是x的一个副本,Y也是一个矩阵,每一列是y的一个副本。坐标X和Y表示的网格有length(y)个行和length(x)个列。
2 、[X,Y] = meshgrid(x) 与 [X,Y] = meshgrid(x,x)相同,返回网格大小为length(x)*length(x)的方形网格矩阵。
3、 [X,Y,Z] = meshgrid(x,y,z),返回由向量x,y,z定义的三维网格坐标,X,Y和Z表示的网格大小为length(x)*length(y)*length(z)。
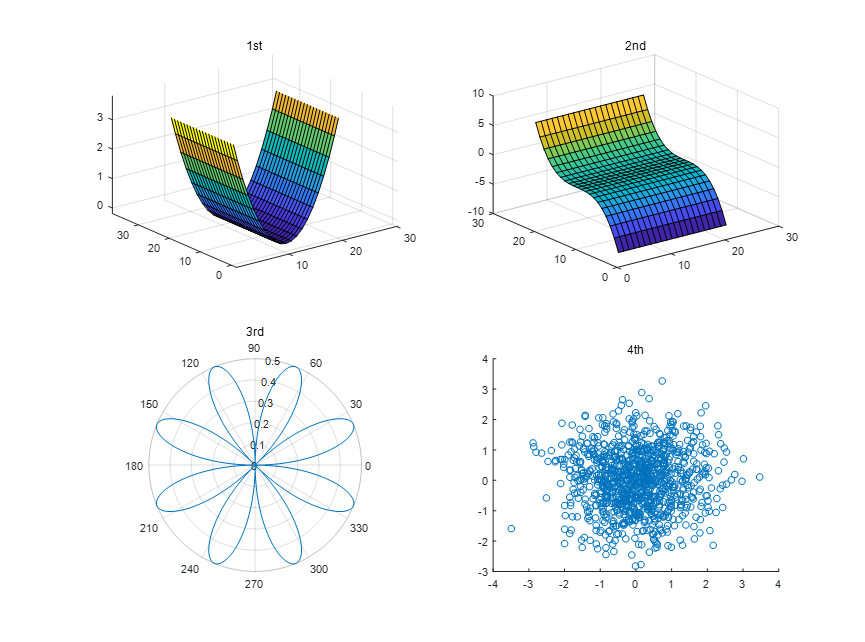
2.画子图(几个图画在一张画布上)
使用subplot函数可以在同一窗口的不同子区域显示多个绘图
subplot(a,b,c) a行b列的布局,c表示这是第几张图
th = 0:0.01:2*pi;
radi = abs(sin(2*th).*cos(2*th));
Height = randn(1000,1); %生成符合正态分布的随机数
Weight = randn(1000,1);
subplot(2,2,1);surf(X.^2);title('1st')
subplot(2,2,2);surf(Y.^3);title('2nd')
subplot(2,2,3);polarplot(th,radi);title('3rd')
subplot(2,2,4);scatter(Height,Weight);title('4th')
结果:















 1123
1123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









