






目前大多数python脚本提取odb文件数据所用的语法为for循环与列表扩展,当提取数据不多,或模型较少时基本能满足需求;但当我们需要一次性提取全空间所有位置的温度,应变,位移,应力等响应数据时(几十万甚至大几百万的节点数量),或者构建代理模型需要进行大量的重复提取时,for循环与列表扩展的提取效率会十分低下,所需时间甚至是仿真模型运行时间的几十倍!!!使得代理模型构建根本无法开展下去!!!
耗时一周!!!,研修abaqus联合python内置odb文件逻辑结构模块,编写提取全空间全物理场响应数据的python脚本:所有结点(也可指定所需节点集)的温度、位移、应力、应变...响应数据(全时间域任意所需时间步)。效率对比所用模型如下:
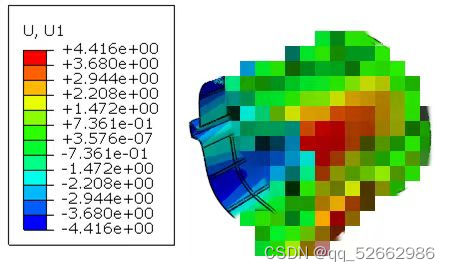
对上述进行热力耦合计算的仿真模型,提取其全场96525个节点位置的温度、位移(xyz)、应力(mises)、应变(三个方向的主应变)等响应数据(约100万,数据再多其实也影响不大,提取逻辑是整体集合式提取,没有一个循环与扩展逻辑),耗时从3个小时(传统循环提取)缩短至3秒!!!
需要py脚本的童靴请私聊我哦,(不是免费的偶,毕竟花费了小编师兄一周的心血,渍渍渍)。















 4093
4093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









