






Framework Overview
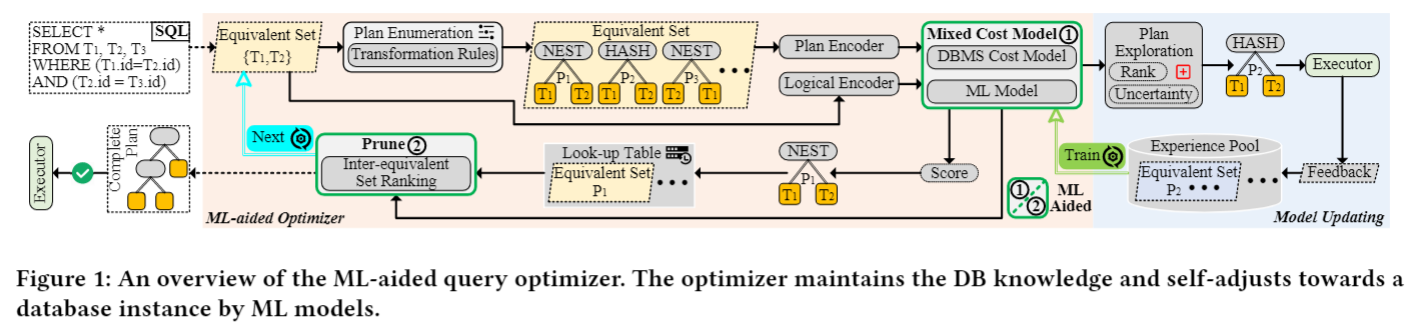
ML-aided Query Optimizer
ML模型在以下两个方面影响标准查询优化器的优化决策(图1中的green box①和②)。
①第一个方面是等价集内优化决策(2.1节中的成本计算和成本比较)。与依赖专家成本模型不同,LEON学习了一个分数函数:
![]()
将一个(逻辑特征(LF)、物理特征(PF))对映射到一个标量值(分数),对同一等价集S中的计划进行排序。LF = (Q, q)由完整的查询Q与当前逻辑表达式q定义,并且PF = (ω, p)由物理性质ω和当前计划p定义。因此,一个计划在等价集S中的排名位置由分数重新排序。通过从
中选择估计得分最低的计划来选择等价集内的最优计划。注意,
还计算得分的不确定性。不确定性表示模型
对预测的排序位置的置信度,该置信度是针对规划探索的。
可以很容易地在在线推理期间禁用探索模式。
②第二个方面是等价集间剪枝。LEON学习了第二个分数函数:
![]()
给定LF = (Q, q)和PF = (ω, p),当(子)计划p用作部分步骤时,预测执行完整查询Q的总体排名。然后,从查找表中删除排名较低的等价集S。
学习的分数函数是非平凡的构建。它将专家成本模型作为初始化。这种方法解决了冷启动问题,避免了在ML模型不稳定时需要收集大量数据,降低了学习过程中出现意外性能回归的风险。我们称
为混合成本模型。此外,它利用收集到的执行反馈,使专家成本模型适合目标数据库实例。如果最优排序可以通过分数函数排序,则查询优化器可以搜索最优计划。我们如下讨论分数函数的配置和训练。
ML Model
LEON训练一个参数为𝜃的神经网络来近似最优分数函数和
。注意,
和
使用相同的backbone network ,只是prediction heads不同。神经网络的输入被编码为逻辑和物理特征向量:逻辑特征向量以Q和q编码信息,物理特征向量以ω和p编码信息(详见4.2节)。
Model Updating
对于更新ML模型的任务,LEON收集经验并使用它来训练ML模型。具体来说,在每次迭代中,LEON都会利用当前的ml辅助查询优化器来搜索训练工作量的计划。在计划搜索过程中,LEON会收集额外的经验。在计划搜索之后,LEON利用收集到的经验训练ML模型。以下两个步骤(a)经验收集(详见第5.1节)和(b)模型训练(详见第5.2节)交替进行,直至达到预定的停止条件。模型更新工作流程如图1所示。
(a)经验收集。LEON维护一个经验池来收集执行反馈,包括逻辑表达式q、完整查询Q、q对应的计划p、物理性质ω、成本C(p)、即时延迟L(p)和总延迟
。对于训练工作负载中的每个查询,LEON在查询优化器中使用一个标准计划枚举器。具体来说,LEON使用ml辅助查询优化器来搜索计划。对于每个等价集,LEON都有一个计划探索策略来选择有价值的(子)计划。计划探索基于两个标准:排名和从当前
中得出的不确定性,以发现潜在的更好的计划。选择的计划将用于收集保存在E中的执行反馈。
(b)模型训练。模型训练的目的是让两个ML模型从收集到的经验E中学习。首先,LEON从专家成本模型开始初始化混合成本模型。LEON借鉴了专家系统的思想,将查询优化形式化为上下文配对计划排序问题,以训练针对目标定制的两个模型(详见4.1节)。对于每次迭代,LEON在特定上下文下为ML模型从经验池E中挑选几批计划对(p1, p2)。然后,LEON以我们提出的上下文排序目标和安全正则化作为损失函数,以标准监督学习方式训练两个ML模型
。ML模型在收集到的经验上进行迭代训练,以近似最优得分函数。
PLAN RANKING MODEL
Problem Formulation
定义1(上下文计划排序)。
给定由三个方面的限制定义的上下文:完整查询Q、逻辑表达式q和物理属性ω,对来自同一上下文的枚举物理计划进行排序。顺序遵从目标优化目标的相对位置(例如,延迟)不需要实际执行计划。
我们的搜索策略是基于DP的,我们主要关心的是在相同的上下文中计划的排名。对于内部等价集优化,上下文被定义为对相同Q、q和ω的限制。对于等价集间剪枝,上下文定义为相同Q上不同等价集(S = (q,ω))上的约束。上下文限制有助于LEON减少不必要的计划比较。
计划排序自然具有传递性,即给定分数函数,从同一上下文中枚举∀p1, p2, p3: M(p1) > M(p2) n M(p2) > M(p3)→M(pi) > M(p3),其中M(·)表示一般的分数函数,我们省略了相同的上下文输入。因此,我们可以将计划排序问题形式化为成对排序/分类问题。
定义2(上下文配对分类)。
给定来自相同上下文的一对物理计划∀p1, p2,在不实际执行计划的情况下,根据上下文计划排名预测哪个计划具有更高的顺序。
学习排序(LTR)在推荐系统中得到了研究。研究表明,与预测绝对值相比,预测相对顺序与排序的性质更密切相关,因此两两方法在实践中比点法表现得更好[8,48]。此外,两两分类公式是一种更可行的训练ML模型的方法,因为我们只需要两个标签来训练模型,而不是整个排名表。
ML Model
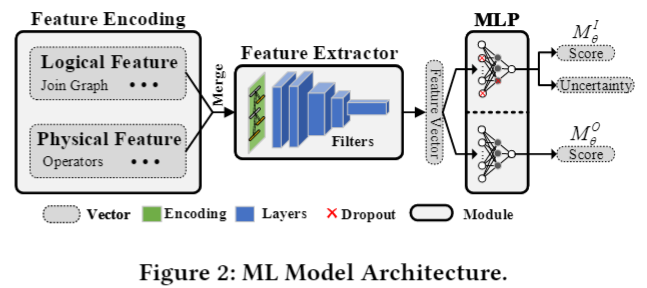
feature extractor (特征提取器)的输入包含两个方面:逻辑特征和物理特征。逻辑特征由一个单热向量编码,表示逻辑属性,包括(子)查询q和完整查询Q的输出基数和连接图。物理特征维护一个树结构来表示计划树p和物理属性ω,其中每个树节点由一个单热向量表示,表示物理操作符和排序顺序。然后,逻辑单热编码与每个树节点向量合并作为最终编码。计划树的模式匹配是一种常用的方法,并得到了前人的经验验证[21,22,42]。LEON构建了两个ML模型来学习这些模式。
和
共享同一个骨干网络,称为特征提取器。特征提取器的选择不是我们的贡献,它与LEON的技术是正交的。用户可以使用其他网络架构。在我们的实现中,我们在Neo[22]中使用了包含卷积和池化操作的树卷积网络(在图2中表示为过滤器)。在特征提取器之后,有两个输出头。每个头部是一个多层感知器(MLP),它以特征向量作为输入来预测期望的输出。
虽然两个模型共享部分参数,但它们是在不同的环境下以两两的方式由不同的信号进行训练的。我们将成对训练的细节推迟到第5.2节。接下来,我们介绍两种模型之间的区别。
Intra-equivalent set Model
LEON训练一个内部等价集ML模型来影响等价集合内的优化决策。基于定义2,内部等效集ML模型的训练由来自相同S的计划对的即时延迟性能来监督。然而,考虑到
必须评估大量的计划,特别是当训练数据是瓶颈时,从头开始学习参数化成本模型
可能很困难。为此,我们提出将参数化的校准函数
应用于传统的成本估计C(·)来表示混合成本模型
:
,其中
将逻辑和物理特征映射到校准比率。一开始,我们会将分类比初始化为接近1 (
),这是一个更简单的初始化,便于实践。对于不确定度的测量,我们在
的MLP中加入dropout层,引入随机性(图2中的红叉)。因此,
可以基于多个预测来测量不确定度。其基本原理将在5.1节中说明。
Inter-equivalent set Model
LEON训练另一个ML模型进行等价集间排序。与
不同的是,
用于精简冗余搜索空间。因此,
需要识别劣质的计划。当使用当前(子)计划p作为部分步骤时,
受到执行完整查询Q的总延迟信号的监督。请注意,
是以成对的方式训练的,然而,是来自不同等价集的计划对。
UsingLEONto Aid Query Optimizer
ML Model Integration into DP
LEON将ML模型集成到DP搜索中,包括两部分:等价集内部模型和等价集间模型
。
用于改变查询优化器在等价集(∀p1, p2, S1 = S2, Q1 = Q2)中的优化决策。本文重点讨论了等价间集模型
的使用,该模型通过对等价集间决策进行剪枝来提高规划效率。
用于修剪具有相同数目的连接表(在相同的DP level)的次等价集。具体而言,同一层次的成本比较完成后,所有等价集记忆相应的最优方案。我们使用
来评估一个level(∀p1, p2, S1 # S2, Q1 = Q2)的所有最优计划,并修剪L%最后排名的等价集。这些被修剪过的计划在下一级计划枚举中不再被考虑,从而极大地提高了推理效率。
用于剪枝,因为它直观地表示该子计划的总体性能。因此,我们可以根据整体性能对其进行贪心的修剪。
MODEL UPDATING
模型更新包括两个步骤:经验收集和模型训练。迭代地训练两个ML模型。对于每一次迭代,当前的ml辅助优化器都会通过我们的计划探索策略收集执行反馈到经验池E。通过从经验池中的成对样本中学习来训练两个模型,以提高当前ml辅助优化器的性能。
Experience Collection
计划探索与DP中的计划枚举有着内在的紧密联系,因为混合成本模型的任务是从枚举计划中找到最优计划,即从等价集S中找到最优计划,我们不仅从S中选择最优计划,还从经验E中选择次最优计划,然后执行收集到的训练数据,收集相应的执行反馈,表示为
,
代表
,
代表
计划探索策略规定了如何从S中选择有价值的训练数据到经验E中。
查询优化的一个独特挑战是获取执行反馈非常耗时[21,42]。LEON旨在通过我们的探索技术收集有限数量的额外执行反馈。这里我们有两个重要的考虑因素作为勘探标准:
(1) Top-k计划更重要通常,随着更多的计划收集到E中,校准模型将执行得更好,并为查询优化器带来更好的校准成本模型,因为ML模型可以在大量数据中执行得很好。然而,收集不良计划对混合成本M的最终决策贡献不大,因为它们几乎不能影响前k个候选计划的排名。这在直觉上是正确的,因为排名较高的计划比排名较低的计划对当前模型的排名性能的影响更大。
(2)此外,机器学习辅助优化器应该纠正导致次优查询计划的错误。根据定义2,错误是指从s中枚举的计划对p1, p2的错误排序/分类。理想情况下,如果我们知道M对其估计的置信度,则低置信度的预测更容易出错。
Model Uncertainty
贝叶斯神经网络(BNN)[14]提供了一个框架来测量预测模型的不确定性。与点估计不同的是,给定模型参数P(θ)的先验分布,BNN从经验E中学习后验分布P(θ′| E)。当使用BNN进行预测时,概率分布P(score | LF, PF, E)可以被每一个θ的后验分布P(θ′| E)边缘化:
![]()
根据Eq.(1),模型输出可以近似为,预测(LF,PF)的不确定性u(LF,PF)定义为
。N是从后验分布中采样参数的次数。bnn是数据高效的,因为它可以从有限的数据中学习而不会过度拟合[27]。
我们深入挖掘计划对,并测量正确和错误分类计划对的不确定性。我们对不确定度与错误样本之间的关系进行了实证研究。从图3可以看出,不确定性在训练阶段开始时是不稳定的。随着训练次数的增加,错误样本的不确定度明显大于正确样本,与估计误差呈正相关。
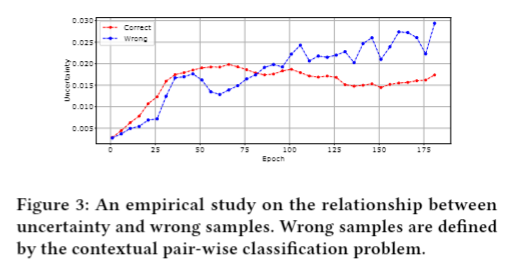
最近在推荐系统中的研究[8,48]提供了理论证明和经验证据,表明具有较大不确定性的高排名样本有助于模型训练。为此,提出了top-k勘探和基于不确定性的勘探两阶段计划勘探策略。
阶段1:Top-k探索。在第一阶段,我们从相同的等效集S中选择top [k% × IS|]个潜在计划,其中k%是基于训练时间预算的可调参数。
阶段2:基于不确定性的探索。在第二阶段,对于我们从第一阶段得到的每个计划,我们选择最不确定或几个不确定的计划。我们将模型的不确定性度量为一个计划,记为u(LF, PF)作为收集计划的标准。当ML模型从有限的经验E中学习时,它会将不确定性更新给它们,并征求更多不确定的数据样本。为了测量深度神经网络中的u(LF, PF),我们采用蒙特卡罗dropout[14],将dropout层插入中。基于Eq(1),我们运行
N次。我们计算其方差作为不确定性的近似值,并计算其均值作为其混合成本估计的近似值。实际的勘探数量取决于训练时间预算。注意,通过禁用退出层可以很容易地禁用探索模式。
Model Training
如定义2所述,我们在不同的语境下以监督分类的方式训练分数函数和
。为了训练模型
,我们首先选择几批满足Q1= Q1和S1 = S2的计划对(p1,p2),然后分配正确的训练标签。当L(p1) < L(p2)时,我们给这对赋正标号。否则,将被贴上负面标签。同样,为了训练模型
,我们选择几批满足Q1 = Q2和S1 ≠ S2的计划对(p1, p2)。我们用
代替
来分配正确的标签。接下来,我们描述损失函数来训练两个ML模型。注意,我们使用分类损失和正则化来训练
,我们只使用分类损失来训练
。
Classification Loss
我们采用softmax二值交叉熵损失[6]如下:

σ是从得分到选择计划pi的概率的softmax投影,y是根据延迟顺序在计划对(p1, p2)中对一个更好的计划进行分类的真标签。然后交叉熵损失将惩罚错误的分类。因此,学习损失
![]()
将使校正后的代价模型秩计划对正确。在保持混合成本模型的先验知识的同时训练混合成本模型并不是一件容易的事情。过度学习会导致性能不稳定,因为学习到的模型倾向于在有限的数据上过拟合[45]。在机器学习术语中,研究人员经常对目标函数进行正则化以避免过拟合。在实践中,我们通过测量参数更新前后的intra-equivalent set ranking的差异来添加KL散度,作为目标函数的软约束,类似于TRPO[33]。
















 8776
8776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









