







目录
摘要
SegNet是在FCN网络模型的基础上,修改VGG-16网络得到的语义分割网络,通过存储最大池化索引以保留边界信息、去掉全连接层并使用批量归一化等手段,解决了边界划分不清、计算量大等问题,降低了内存和存储需求,加快了推理速度,提升了像素级分类精度,实现了高内存效率、轻量模型、高分割精度和快速推理。在CamVid数据集上准确率超83%,在遥感图像建筑物分割等任务中性能更优,满足实时性检测需求。
Abstract
SegNet is a semantic segmentation network derived from the VGG-16 network based on the FCN network model. By storing the max-pooling indices to retain boundary information, removing the fully connected layers, and using batch normalization, it addresses issues such as unclear boundary division and high computational load. It reduces memory and storage requirements, accelerates inference speed, and improves pixel-level classification accuracy, achieving high memory efficiency, a lightweight model, high segmentation accuracy, and fast inference. It has an accuracy rate of over 83% on the CamVid dataset and performs better in tasks such as building segmentation in remote sensing images, meeting the requirements for real-time detection.
SegNet
论文链接:[1511.00561] SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
项目地址:CV/Semantic_Segmentation/SegNet at main · codecat0/CV · GitHub
网络模型
SegNet网络模型,如下图所示:
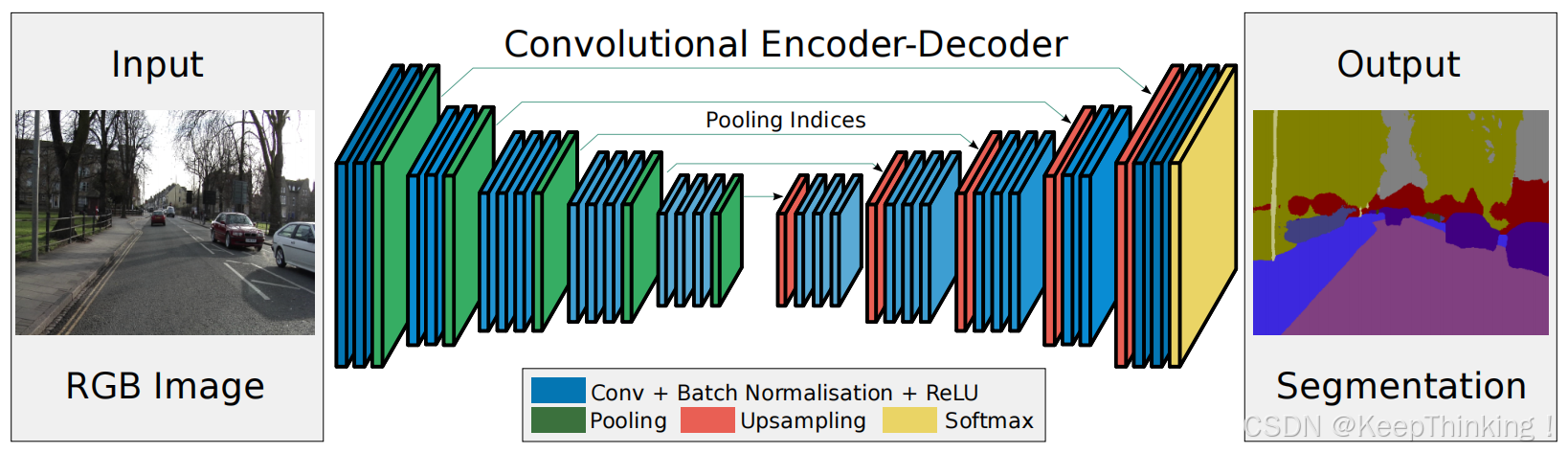
SegNet与U-Net网络结构有相似之处,都是对称型。SegNet采用VGG-16作为骨干网络提取图像特征,去掉了FCN中全连接操作,节省了计算开销。同时,SegNet为了更好的保留边界特征信息,采用了索引的方式进行上采样。不再进行拼接操作,直接进行反卷积。即在进行池化操作时,记录池化所取值的位置,在上采样时直接用当时记录的位置进行反池化。
创新点
编码器结构优化
FCN的编码器部分通常采用VGG等预训练模型,SegNet同样以VGG-16为基础构建编码器,但去掉了VGG-16中的全连接层,减少了大量参数,降低了模型复杂度和计算量。FCN的池化和下采样过程降低了特征图的分辨率,损失了一定信息,会得到较为粗糙的结果,且模型较大,编码层有134M参数,但解码层只有0.5M参数,在上采样上表现不佳,得到的图像较为粗糙,以及会出现边界模糊的情况。
解码器结构创新
FCN的解码器通过反卷积操作进行上采样,而SegNet利用编码器阶段存储的最大池化索引来实现上采样。在编码器的每个最大池化层,SegNet会记录下每个最大值元素的位置索引。在解码器的上采样过程中,根据这些索引将编码器阶段的特征图映射回原始分辨率,从而能够更准确地恢复出物体的边界细节,解决了FCN上采样过程中边界模糊的问题。
Pooling在CNN中是使得图片缩小的手段,通常有Max与Mean两种Pooling方式,我们以Max Pooling为例:
如上图所示,Max Pooling使用一个 2x2 的filter,取出4个权重中最大的一个,原图大小为4x4 ,Max Pooling之后大小为2x2。
SegNet中的Pooling多了一个index功能,每次Pooling都会保存通过Max选出的权值在 2x2 filter中的相对位置,对于上图的6来说,6在白色 2x2 filter中的相对位置为(1,1),蓝色的 3 的坐标为(0,0)。
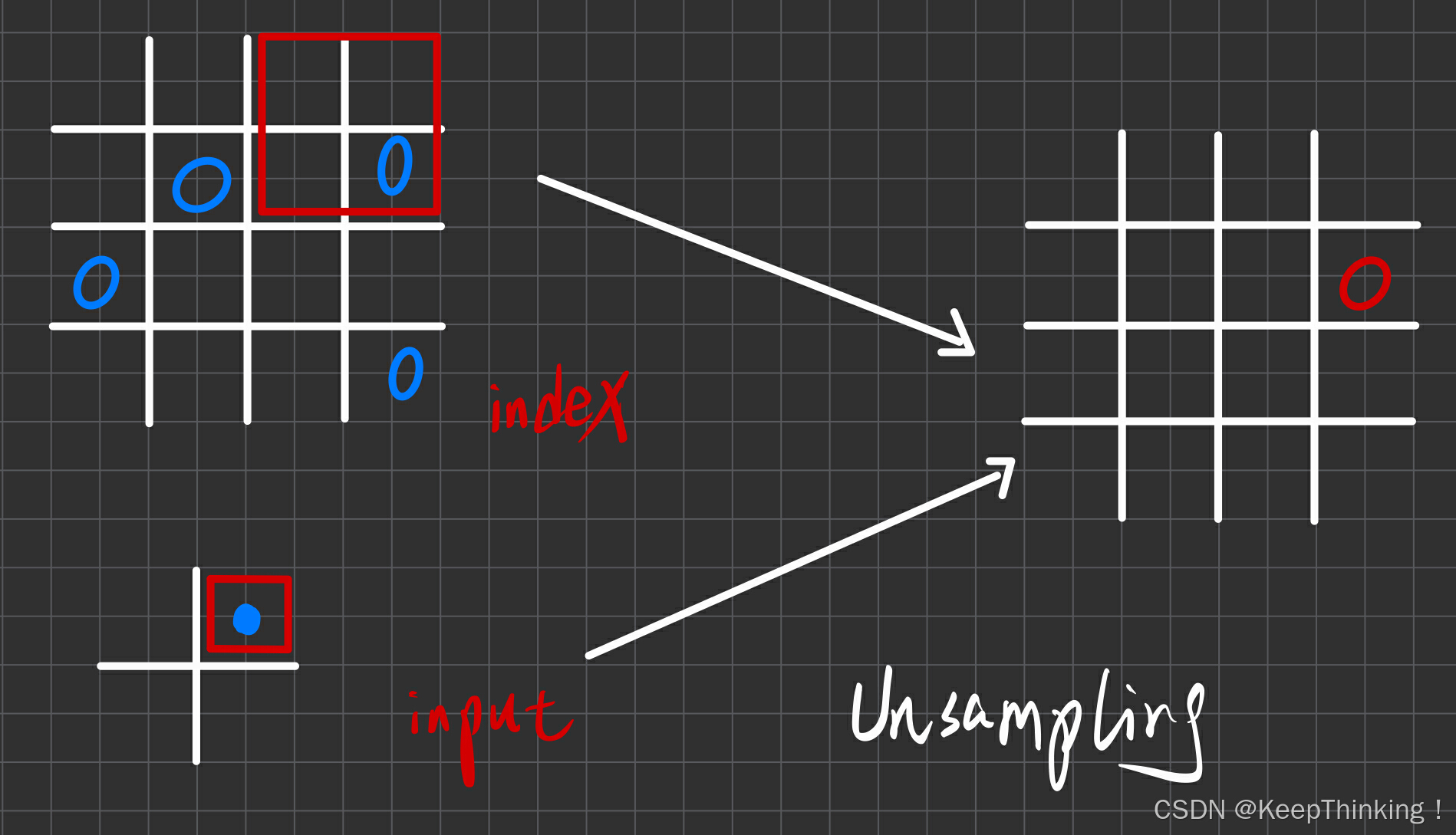
Upsamping是Pooling的逆过程,Upsamping使得图片放大为对应Pooling之前的大小,因为SegNet是对称的,所以最后一次Pooling对应第一次Upsamping。上图Pooling之后,每个filter会丢失了 3 个权重,这些权重是无法复原的。但是在Upsamping层中可以知道在Pooling中相对Pooling filter的位置。所以Upsampling中先对输入的特征图放大两倍,然后把输入特征图的数据根据Pooling indices放入,下图所示:
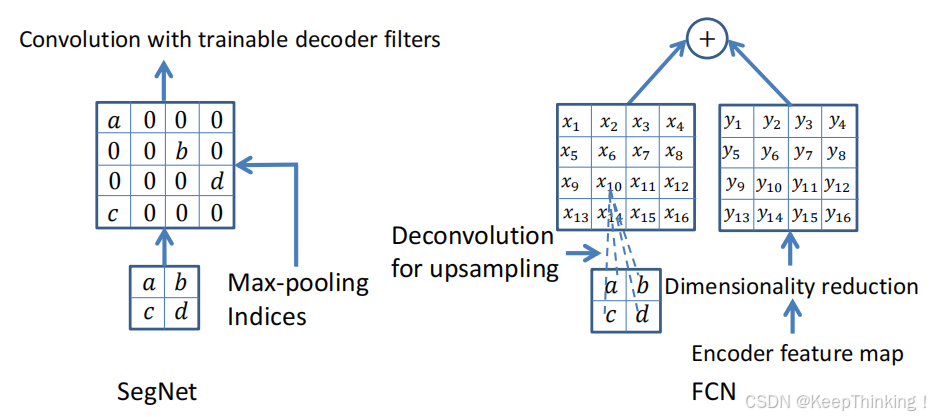
对比FCN可以发现SegNet在Unsamping时用index信息,直接将数据放回对应位置,后面再接卷积训练学习,上采样时不需要学习,这样节省了计算开销。反观FCN则是用反卷积策略,将特征图像反卷积后得到Upsampling,这一过程需要学习。对比图如下所示:
同时SegNet将编码器阶段对应的特征图像做通道降维,使得通道维度和Upsampling相同,这样就能做像素相加得到最终的解码器输出。
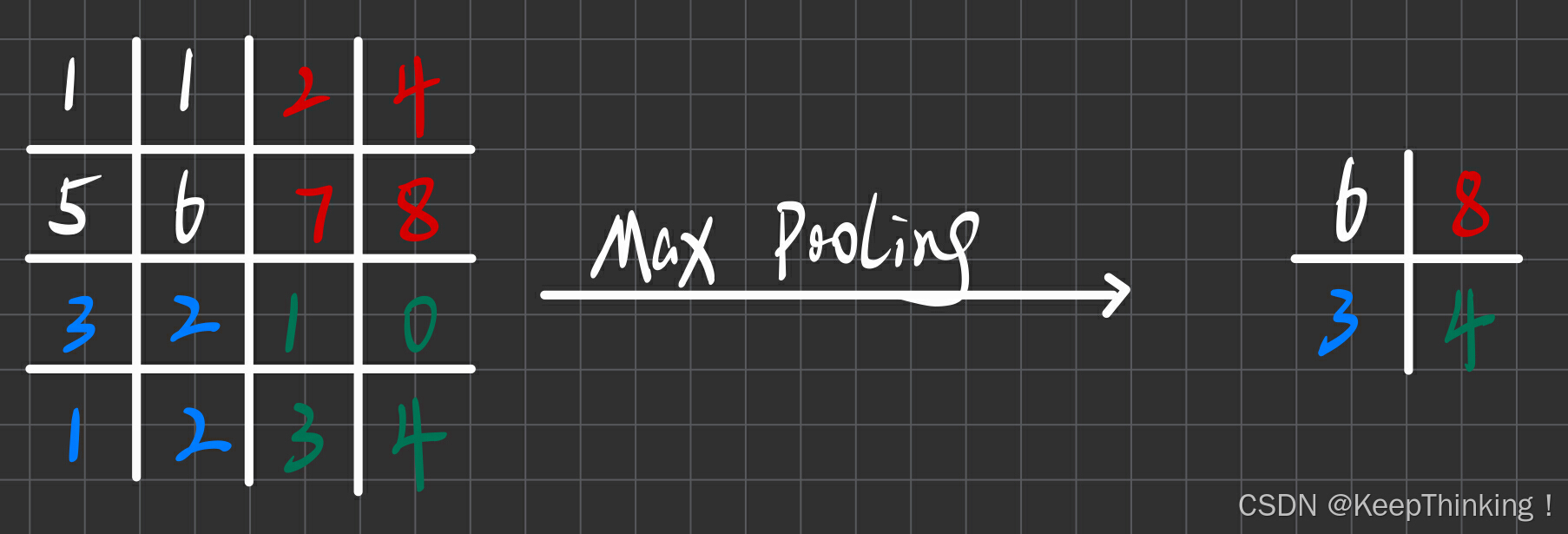
训练与损失函数
SegNet在编码器和解码器的卷积层后添加了Batch Normalization。批量归一化可以加速网络的收敛速度,提高训练的稳定性,同时还能起到一定的正则化作用,有助于缓解过拟合现象,使模型在训练过程中更加稳定,最终获得更好的分割性能。
SegNet和FCN都采用像素级的交叉熵损失函数来训练模型,但SegNet在损失函数的计算上做了一些优化。它对不同类别的像素权重进行了调整,为了解决类别不平衡问题,给不同类别分配不同的权重,使得模型在训练过程中更加关注那些数量较少但重要的类别,从而提高了模型对所有类别的分割精度。
具体实现
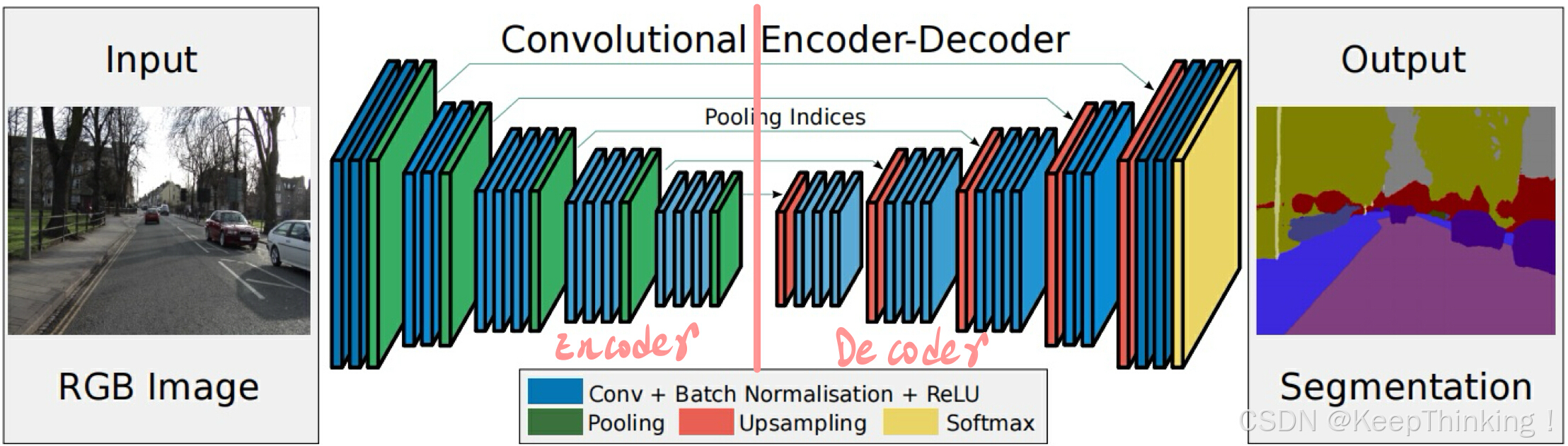
SegNet的Encoder过程中,通过same卷积提取特征,即卷积后保持图像原始尺寸;在Decoder过程中,同样使用same卷积,不过卷积的作用是为Upsampling变大的图像填充缺失的内容,使得在Pooling过程丢失的信息可以通过在Decoder中学习得到。BN层对训练图像进行批量标准化,加速模型的收敛。Decoder对缩小后的特征图进行上采样,然后对上采样后的图像进行卷积处理,来完善图像中物体的几何形状,将Encoder中获得的特征还原到原图像的具体像素点上。
最后一个卷积层会将特征图像的通道数变为类别数,再将其传入一个Softmax层,输出所有像素点在所有类别最大的概率,即为该像素的label,最终完成图像像素级别的分类。
代码
SegNet网络构建
- Encoder部分
Encoder类定义了编码器部分,包含5个编码块,每个块由多个卷积层、批量归一化层和ReLU激活函数组成。前向传播中,输入 x 依次通过每个编码块,然后进行最大池化操作,并记录池化索引idx,这些索引将用于解码器中的上采样操作。
class Encoder(nn.Module):
def __init__(self, in_channels):
super(Encoder, self).__init__()
self.encode1 = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.encode2 = nn.Sequential(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3409
3409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









