







文章目录
1 摘要
本文提出一种可用于端到端训练的语义分割网络结构——SegNet,它是一种编码器—解码器结构。编码器结构类似于VGG16的前13层,而本文的重点介绍在于解码器部分,其创新性地使用了一种池化索引的上采样方法,不仅消耗更小的内存,而且在上采样部分避免了学习。该网络主要运用于道路场景分割任务和室内场景分割任务,并且在CamVid数据集和SUN RGB-D数据集中达到了SOTA。
2 亮点
2.1 网络结构
2.1.1 编码器结构
编码器结构是在VGG16的基础上进行的改进:去掉了后3层的全连接层,只取前13层。这样大大地减少了全连接层带来的参数的增加(从134M到14.7M),另外,在编码器阶段,进行最大池化操作时候把滑动窗口时最大特征的位置记录下来(作用后面在解码器结构会讲),只需要2个bit。总体来说,编码器结构在跟语义分割中的变化不是非常大,本文重点介绍解码器结构。
2.1.2 解码器结构
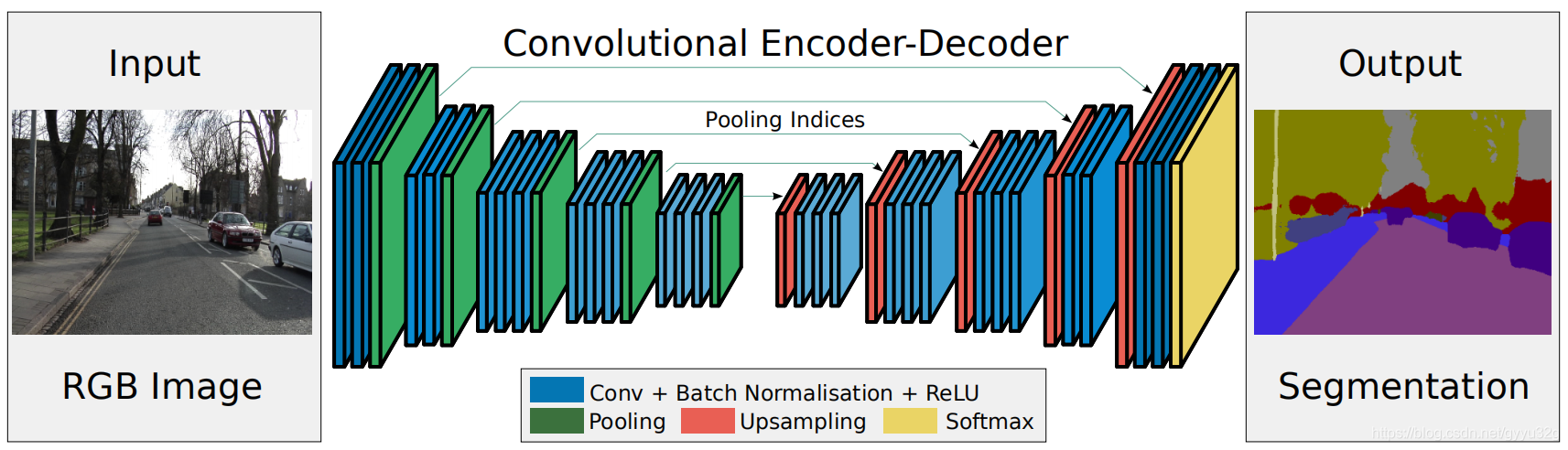
在解码器结构中,需要对图像的大小进行恢复,在FCN网络和SegNet网络中,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4381
4381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









