



目录
摘要
Hierarchical Temporal Transformer 提出的分层时序变换器基于 Transformer 架构改进,通过分层时序编码和双分支设计解决了现有方法在长时序依赖建模和多粒度特征融合上的不足,实现了从第一视角 RGB 视频中同时进行 3D 手部姿态估计和动作识别。该模型采用空间--时序双分支结构,结合局部窗口注意力和全局跨帧注意力,分别优化手部关节细节和动作动态表征,并在FPHA和H2O数据集上达到SOTA性能,为第一视角人机交互提供了高效的统一框架。
Abstract
The proposed Hierarchical Temporal Transformer improves upon the standard Transformer architecture by introducing hierarchical temporal encoding and a dual-branch design, addressing the limitations of existing methods in modeling long-term dependencies and multi-granularity feature fusion. It enables simultaneous 3D hand pose estimation and action recognition from egocentric RGB videos. The model employs a spatial-temporal dual-branch structure, integrating local window attention and global cross-frame attention to optimize hand joint details and motion dynamics, respectively. Achieving state-of-the-art performance on the FPHA and H2O datasets, HTT provides an efficient unified framework for egocentric human-computer interaction.
HTT
项目地址:Hierarchical Temporal Transformer

随着AR、VR和人机交互技术的发展,基于第一视角视频的三维手部姿态估计和动作识别成为关键任务。传统方法通常将这两个任务分开处理,导致计算冗余且难以建模长时序依赖关系。本文提出的层次化时序变换器(HTT)通过统一的Transformer架构,实现了:
- 端到端联合学习:同时估计3D手部关节点并识别动作类别。
- 长时序建模能力:通过分层时序编码捕捉短程和长程动作动态。
- 多粒度特征融合:结合空间-时序双分支结构优化局部细节与全局上下文表征。
模型架构
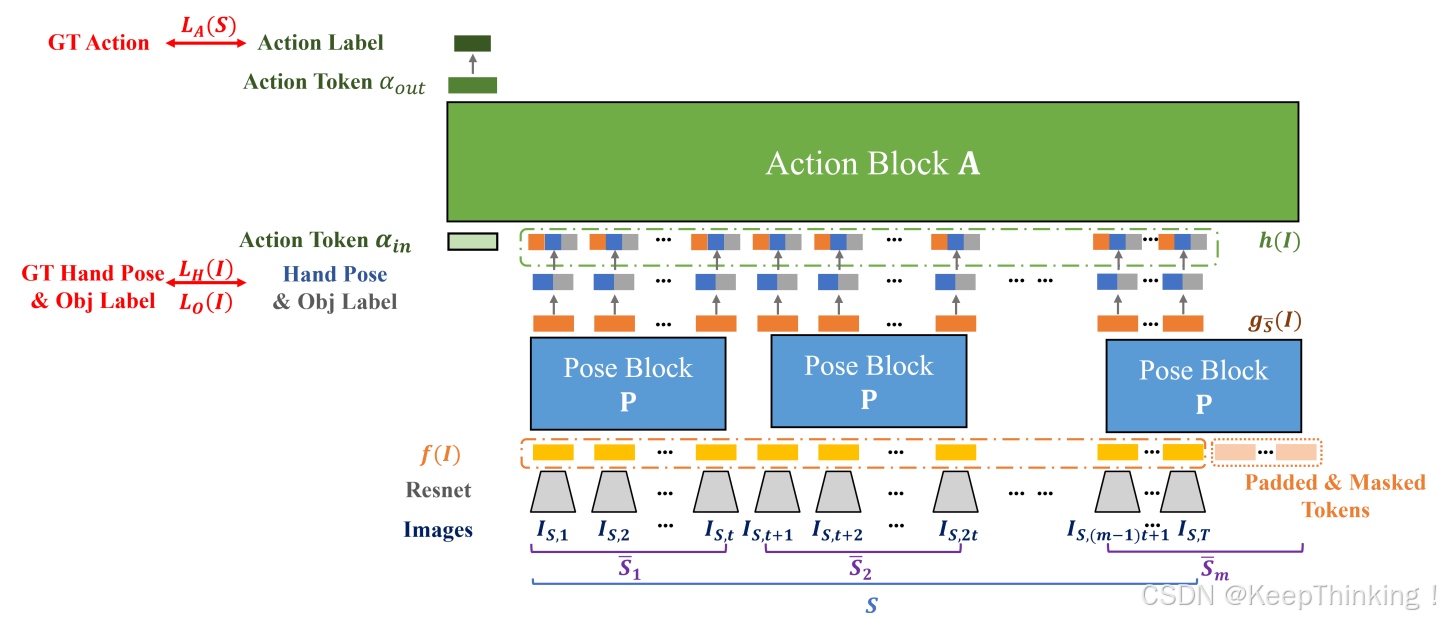
整体架构概述
HTT采用编码器--解码器架构设计,主要由三个核心模块组成:特征提取主干网络、层次化时序编码器和双任务解码器。模型输入为 T 帧的第一视角RGB视频序列,输出同时包含每帧的3D手部关节坐标和整个片段的动作类别。
特征提取主干网络
- 空间特征提取器:
采用轻量化ResNet-18作为基础架构,输入分辨率调整为 3x256×256,输出为512维的空间特征向量 f_t ∈ R^(512×H×W),其中 H=W=8。
- 位置编码:
加入可学习的时空位置编码,包含空间位置编码PE_s ∈ R^(H×W×512)和时间位置编码PE_t ∈ R^(T×512)。
层次化时序编码器
模块通过处理输入视频片段来挖掘时序特征。其核心设计理念体现在两个方面:首先,基于动作识别高级任务,如倒牛奶可分解为手部运动(如“倾倒动作”)和操作对象(如“牛奶瓶”)两个低级任务的认知,遵循这一语义层次结构,将HTT划分为级联的姿势模块P和动作模块A(如上图所示)。姿势模块P首先逐帧估计3D手部姿态和交互物体类别,随后动作模块A通过聚合预测的手部运动和物体标签信息来实现动作识别。其次,针对长期动作和瞬时姿态不同的时序粒度特性,虽然P和A均采用Transformer架构,但P仅聚焦于t个连续帧(t<T)的局部时序感受野,而A则处理全部T帧的全局时序信息。
局部时序编码层
将视频划分为长度为L=5的局部窗口,每个窗口内包含连续5帧。采用多头注意力机制,公式如下:
通过跨窗口信息传递模块连接相邻窗口,并使用1D卷积实现局部特征平滑。
全局时序编码层
在窗口特征基础上进行全局注意力计算,将注意力头数增加至8个,并引入相对位置偏置。局部层和全局层特征通过残差连接,采用Layer Normalization进行归一化。
双任务解码器
短期时序线索的手部姿态估计
由于手部姿态反映的是瞬时动作特征,过长时间跨度的参考会过度强调时序较远的帧,反而可能损害局部动作的估计精度。为此,通过将视频片段S划分为m个连续子段来限定姿态估计的时序范围,其中
,每个子段
。如下图所示:
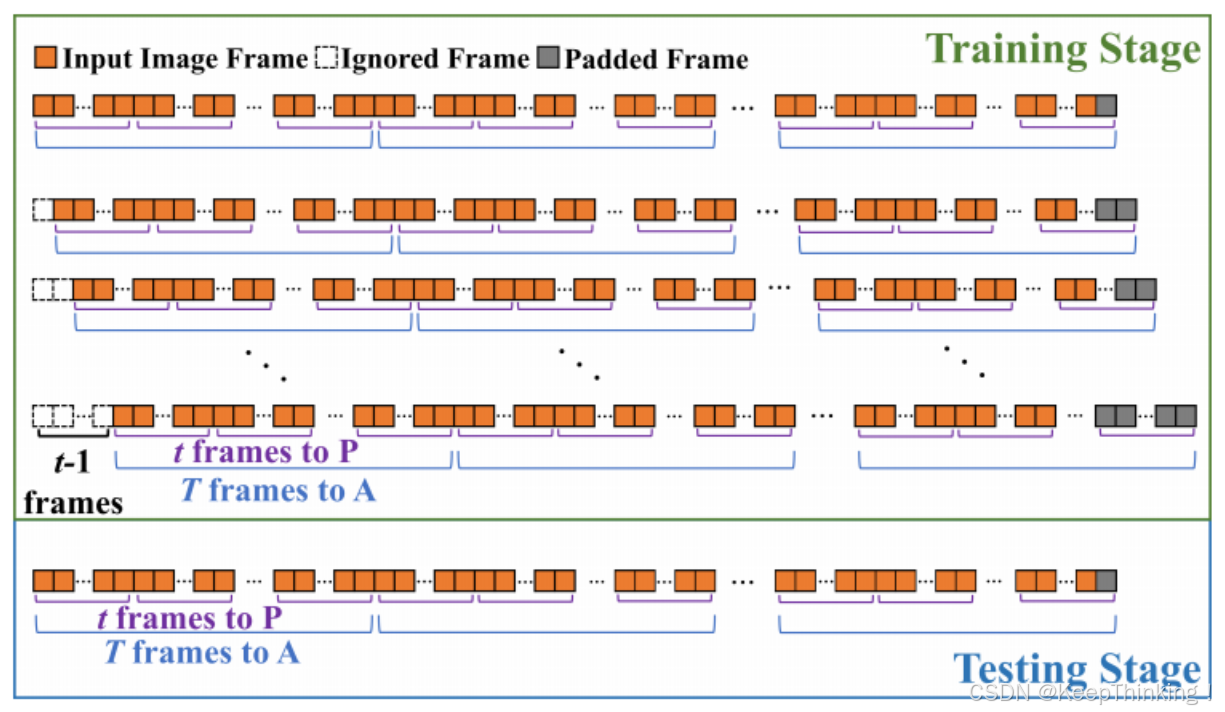
超出长度T的token会进行填充处理,但通过掩码机制排除在自注意力计算之外。该方案可视为窗口大小为t的滑动窗口策略,模块P并行处理每个子段以捕捉手部姿态估计所需的时序线索。
对于每个局部片段,姿态模块P以逐帧ResNet特征序列
作为输入,输出对应序列
。其中第j个token
不仅对应帧
的表征,同时编码了来自片段
的时序线索。我们随后从这些具有时序依赖性的特征
解码出
中每帧I的手部姿态:
预测和真实手势姿态最小化L1损失如下:
长期时序线索的动作识别
动作模块A利用完整的输入序列S来预测动作,为了对S的动作进行分类,使用A输出序列的的第一个标记来预测概率,公式如下:
最小化交叉熵:
总训练损失为:
模型优势
分层时序建模:解决传统方法对长视频序列建模不足的问题;
双分支协同优化:姿态估计与动作识别相互增强;
计算高效:相比串联式多任务模型,参数量减少约18%。
实验
基于FPHA的RGB方法动作识别的分类精度,如下图所示:

MEPE和MEPE-RA在H2O测试中的手部姿态估计速度,如下图所示:
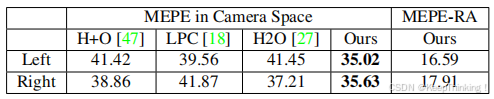
基于H2O的RGB方法动作识别的分类精度对比,如下图所示:

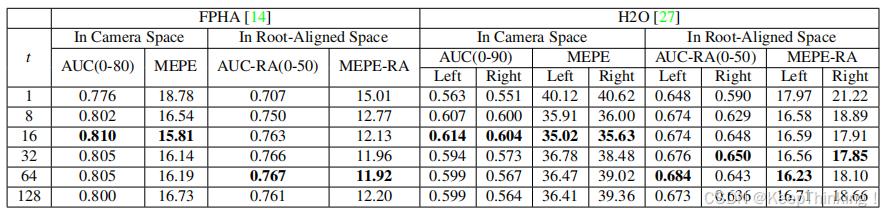
在FPHA和H2O数据集上对姿态模块P的时间跨度t进行消融实验,如下图所示:
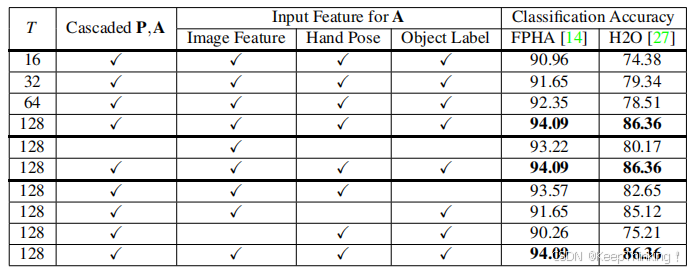
动作识别核心模块的消融研究,FPHA和H2O数据集上的分类准确率,所有对比实验均保持姿态模块P的时间跨度 t=16,对比如下图所示:
代码
HTT模型代码如下:
import torch
import torch.nn.functional as torch_f
from einops import repeat
from models import resnet
from models.transformer import Transformer_Encoder, PositionalEncoding
from models.actionbranch import ActionClassificationBranch
from models.utils import To25DBranch,compute_hand_loss,loss_str2func
from models.mlp import MultiLayerPerceptron
from datasets.queries import BaseQueries, TransQueries
class ResNet_(torch.nn.Module):
def __init__(self,resnet_version=18):
super().__init__()
if int(resnet_version) == 18:
img_feature_size = 512
self.base_net = resnet.resnet18(pretrained=True)
elif int(resnet_version) == 50:
img_feature_size = 2048
self.base_net = resnet.resnet50(pretrained=True)
else:
self.base_net=None
def forward(self, image):
features, res_layer5 = self.base_net(image)
return features, res_layer5
class TemporalNet(torch.nn.Module):
def __init__(self, is_single_hand,
transformer_d_model,
transformer_dropout,
transformer_nhead,
transformer_dim_feedforward,
transformer_num_encoder_layers_action,
transformer_num_encoder_layers_pose,
transformer_normalize_before=True,
lambda_action_loss=None,
lambda_hand_2d=None,
lambda_hand_z=None,
ntokens_pose=1,
ntokens_action=1,
dataset_info=None,
trans_factor=100,
scale_factor=0.0001,
pose_loss='l2',
dim_grasping_feature=128,):
super().__init__()
self.ntokens_pose= ntokens_pose
self.ntokens_action=ntokens_action
self.pose_loss=loss_str2func()[pose_loss]
self.lambda_hand_z=lambda_hand_z
self.lambda_hand_2d=lambda_hand_2d
self.lambda_action_loss=lambda_action_loss
self.is_single_hand=is_single_hand
self.num_joints=21 if self.is_single_hand else 42
#Image Feature
self.meshregnet = ResNet_(resnet_version=18)
self.transformer_pe=PositionalEncoding(d_model=transformer_d_model)
self.transformer_pose=Transformer_Encoder(d_model=transformer_d_model,
nhead=transformer_nhead,
num_encoder_layers=transformer_num_encoder_layers_pose,
dim_feedforward=transformer_dim_feedforward,
dropout=0.0,
activation="relu",
normalize_before=transformer_normalize_before)
#Hand 2.5D branch
self.scale_factor = scale_factor
self.trans_factor = trans_factor
self.image_to_hand_pose=MultiLayerPerceptron(base_neurons=[transformer_d_model, transformer_d_model,transformer_d_model], out_dim=self.num_joints*3,
act_hidden='leakyrelu',act_final='none')
self.postprocess_hand_pose=To25DBranch(trans_factor=self.trans_factor,scale_factor=self.scale_factor)
#Object classification
self.num_objects=dataset_info.num_objects
self.image_to_olabel_embed=torch.nn.Linear(transformer_d_model,transformer_d_model)
self.obj_classification=ActionClassificationBranch(num_actions=self.num_objects, action_feature_dim=transformer_d_model)
#Feature to Action
self.hand_pose3d_to_action_input=torch.nn.Linear(self.num_joints*2,transformer_d_model)
self.olabel_to_action_input=torch.nn.Linear(self.num_objects,transformer_d_model)
#Action branch
self.concat_to_action_input=torch.nn.Linear(transformer_d_model*3,transformer_d_model)
self.num_actions=dataset_info.num_actions
self.action_token=torch.nn.Parameter(torch.randn(1,1,transformer_d_model))
self.transformer_action=Transformer_Encoder(d_model=transformer_d_model,
nhead=transformer_nhead,
num_encoder_layers=transformer_num_encoder_layers_action,
dim_feedforward=transformer_dim_feedforward,
dropout=0.0,
activation="relu",
normalize_before=transformer_normalize_before)
self.action_classification= ActionClassificationBranch(num_actions=self.num_actions, action_feature_dim=transformer_d_model)
def forward(self, batch_flatten, verbose=False):
flatten_images=batch_flatten[TransQueries.IMAGE].cuda()
#Loss
total_loss = torch.Tensor([0]).cuda()
losses = {}
results = {}
#resnet for by-frame
flatten_in_feature, _ =self.meshregnet(flatten_images)
#Block P
batch_seq_pin_feature=flatten_in_feature.contiguous().view(-1,self.ntokens_pose,flatten_in_feature.shape[-1])
batch_seq_pin_pe=self.transformer_pe(batch_seq_pin_feature)
batch_seq_pweights=batch_flatten['not_padding'].cuda().float().view(-1,self.ntokens_pose)
batch_seq_pweights[:,0]=1.
batch_seq_pmasks=(1-batch_seq_pweights).bool()
batch_seq_pout_feature,_=self.transformer_pose(src=batch_seq_pin_feature, src_pos=batch_seq_pin_pe,
key_padding_mask=batch_seq_pmasks, verbose=False)
flatten_pout_feature=torch.flatten(batch_seq_pout_feature,start_dim=0,end_dim=1)
#hand pose
flatten_hpose=self.image_to_hand_pose(flatten_pout_feature)
flatten_hpose=flatten_hpose.view(-1,self.num_joints,3)
flatten_hpose_25d_3d=self.postprocess_hand_pose(sample=batch_flatten,scaletrans=flatten_hpose,verbose=verbose)
weights_hand_loss=batch_flatten['not_padding'].cuda().float()
hand_results,total_loss,hand_losses=self.recover_hand(flatten_sample=batch_flatten,flatten_hpose_25d_3d=flatten_hpose_25d_3d,weights=weights_hand_loss,
total_loss=total_loss,verbose=verbose)
results.update(hand_results)
losses.update(hand_losses)
#Object label
flatten_olabel_feature=self.image_to_olabel_embed(flatten_pout_feature)
weights_olabel_loss=batch_flatten['not_padding'].cuda().float()
olabel_results,total_loss,olabel_losses=self.predict_object(sample=batch_flatten,features=flatten_olabel_feature,
weights=weights_olabel_loss,total_loss=total_loss,verbose=verbose)
results.update(olabel_results)
losses.update(olabel_losses)
#Block A input
flatten_hpose2d=torch.flatten(flatten_hpose[:,:,:2],1,2)
flatten_ain_feature_hpose=self.hand_pose3d_to_action_input(flatten_hpose2d)
flatten_ain_feature_olabel=self.olabel_to_action_input(olabel_results["obj_reg_possibilities"])
flatten_ain_feature=torch.cat((flatten_pout_feature,flatten_ain_feature_hpose,flatten_ain_feature_olabel),dim=1)
flatten_ain_feature=self.concat_to_action_input(flatten_ain_feature)
batch_seq_ain_feature=flatten_ain_feature.contiguous().view(-1,self.ntokens_action,flatten_ain_feature.shape[-1])
#Concat trainable token
batch_aglobal_tokens = repeat(self.action_token,'() n d -> b n d',b=batch_seq_ain_feature.shape[0])
batch_seq_ain_feature=torch.cat((batch_aglobal_tokens,batch_seq_ain_feature),dim=1)
batch_seq_ain_pe=self.transformer_pe(batch_seq_ain_feature)
batch_seq_weights_action=batch_flatten['not_padding'].cuda().float().view(-1,self.ntokens_action)
batch_seq_amasks_frames=(1-batch_seq_weights_action).bool()
batch_seq_amasks_global=torch.zeros_like(batch_seq_amasks_frames[:,:1]).bool()
batch_seq_amasks=torch.cat((batch_seq_amasks_global,batch_seq_amasks_frames),dim=1)
batch_seq_aout_feature,_=self.transformer_action(src=batch_seq_ain_feature, src_pos=batch_seq_ain_pe,
key_padding_mask=batch_seq_amasks, verbose=False)
#Action
batch_out_action_feature=torch.flatten(batch_seq_aout_feature[:,0],1,-1)
weights_action_loss=torch.ones_like(batch_flatten['not_padding'].cuda().float()[0::self.ntokens_action])
action_results, total_loss, action_losses=self.predict_action(sample=batch_flatten,features=batch_out_action_feature, weights=weights_action_loss,
total_loss=total_loss,verbose=verbose)
results.update(action_results)
losses.update(action_losses)
return total_loss, results, losses
def recover_hand(self, flatten_sample, flatten_hpose_25d_3d, weights, total_loss,verbose=False):
hand_results, hand_losses={},{}
joints3d_gt = flatten_sample[BaseQueries.JOINTS3D].cuda()
hand_results["gt_joints3d"]=joints3d_gt
hand_results["pred_joints3d"]=flatten_hpose_25d_3d["rep3d"].detach().clone()
hand_results["pred_joints2d"]=flatten_hpose_25d_3d["rep2d"]
hand_results["pred_jointsz"]=flatten_hpose_25d_3d["rep_absz"]
hpose_loss=0.
joints25d_gt = flatten_sample[TransQueries.JOINTSABS25D].cuda()
hand_losses=compute_hand_loss(est2d=flatten_hpose_25d_3d["rep2d"],
gt2d=joints25d_gt[:,:,:2],
estz=flatten_hpose_25d_3d["rep_absz"],
gtz=joints25d_gt[:,:,2:3],
est3d=flatten_hpose_25d_3d["rep3d"],
gt3d= joints3d_gt,
weights=weights,
is_single_hand=self.is_single_hand,
pose_loss=self.pose_loss,
verbose=verbose)
hpose_loss+=hand_losses["recov_joints2d"]*self.lambda_hand_2d+ hand_losses["recov_joints_absz"]*self.lambda_hand_z
if total_loss is None:
total_loss= hpose_loss
else:
total_loss += hpose_loss
return hand_results, total_loss, hand_losses
def predict_object(self,sample,features, weights, total_loss,verbose=False):
olabel_feature=features
out=self.obj_classification(olabel_feature)
olabel_results, olabel_losses={},{}
olabel_gts=sample[BaseQueries.OBJIDX].cuda()
olabel_results["obj_gt_labels"]=olabel_gts
olabel_results["obj_pred_labels"]=out["pred_labels"]
olabel_results["obj_reg_possibilities"]=out["reg_possibilities"]
olabel_loss = torch_f.cross_entropy(out["reg_outs"],olabel_gts,reduction='none')
olabel_loss = torch.mul(torch.flatten(olabel_loss),torch.flatten(weights))
olabel_loss=torch.sum(olabel_loss)/torch.sum(weights)
if total_loss is None:
total_loss=self.lambda_action_loss*olabel_loss
else:
total_loss+=self.lambda_action_loss*olabel_loss
olabel_losses["olabel_loss"]=olabel_loss
return olabel_results, total_loss, olabel_losses
def predict_action(self,sample,features,weights,total_loss=None,verbose=False):
action_feature=features
out=self.action_classification(action_feature)
action_results, action_losses={},{}
action_gt_labels=sample[BaseQueries.ACTIONIDX].cuda()[0::self.ntokens_action].clone()
action_results["action_gt_labels"]=action_gt_labels
action_results["action_pred_labels"]=out["pred_labels"]
action_results["action_reg_possibilities"]=out["reg_possibilities"]
action_loss = torch_f.cross_entropy(out["reg_outs"],action_gt_labels,reduction='none')
action_loss = torch.mul(torch.flatten(action_loss),torch.flatten(weights))
action_loss=torch.sum(action_loss)/torch.sum(weights)
if total_loss is None:
total_loss=self.lambda_action_loss*action_loss
else:
total_loss+=self.lambda_action_loss*action_loss
action_losses["action_loss"]=action_loss
return action_results, total_loss, action_losses模型训练代码如下:
import argparse
from datetime import datetime
from matplotlib import pyplot as plt
import torch
from tqdm import tqdm
from libyana.exputils.argutils import save_args
from libyana.modelutils import modelio
from libyana.modelutils import freeze
from libyana.randomutils import setseeds
from datasets import collate
from models.htt import TemporalNet
from netscripts import epochpass
from netscripts import reloadmodel, get_dataset
from torch.utils.tensorboard import SummaryWriter
from netscripts.get_dataset import DataLoaderX
plt.switch_backend("agg")
print('********')
print('Lets start')
def collate_fn(seq, extend_queries=[]):
return collate.seq_extend_flatten_collate(seq,extend_queries)
def main(args):
setseeds.set_all_seeds(args.manual_seed)
# Initialize hosting
now = datetime.now()
experiment_tag = args.experiment_tag
exp_id = f"{args.cache_folder}"+experiment_tag+"/"
# Initialize local checkpoint folder
save_args(args, exp_id, "opt")
board_writer=SummaryWriter(log_dir=exp_id)
print("**** Lets train on", args.train_dataset, args.train_split)
train_dataset, _ = get_dataset.get_dataset_htt(
args.train_dataset,
dataset_folder=args.dataset_folder,
split=args.train_split,
no_augm=False,
scale_jittering=args.scale_jittering,
center_jittering=args.center_jittering,
ntokens_pose=args.ntokens_pose,
ntokens_action=args.ntokens_action,
spacing=args.spacing,
is_shifting_window=False,
split_type="actions"
)
loader = DataLoaderX(
train_dataset,
batch_size=args.batch_size,
shuffle=True,
num_workers=args.workers,
pin_memory=True,
drop_last=True,
collate_fn= collate_fn,
)
dataset_info=train_dataset.pose_dataset
#Re-load pretrained weights
model= TemporalNet(dataset_info=dataset_info,
is_single_hand=args.train_dataset!="h2ohands",
transformer_num_encoder_layers_action=args.enc_action_layers,
transformer_num_encoder_layers_pose=args.enc_pose_layers,
transformer_d_model=args.hidden_dim,
transformer_dropout=args.dropout,
transformer_nhead=args.nheads,
transformer_dim_feedforward=args.dim_feedforward,
transformer_normalize_before=True,
lambda_action_loss=args.lambda_action_loss,
lambda_hand_2d=args.lambda_hand_2d,
lambda_hand_z=args.lambda_hand_z,
ntokens_pose= args.ntokens_pose,
ntokens_action=args.ntokens_action,
trans_factor=args.trans_factor,
scale_factor=args.scale_factor,
pose_loss=args.pose_loss)
if args.train_cont:
epoch=reloadmodel.reload_model(model,args.resume_path)
else:
epoch = 0
epoch+=1
#to multiple GPUs
use_multiple_gpu= torch.cuda.device_count() > 1
if use_multiple_gpu:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = torch.nn.DataParallel(model).cuda()
else:
model.cuda()
freeze.freeze_batchnorm_stats(model)# Freeze batchnorm
print('**** Parameters to update ****')
for i, (n,p) in enumerate(filter(lambda p: p[1].requires_grad, model.named_parameters())):
print(i, n,p.size())
#Optimizer
model_params = filter(lambda p: p.requires_grad, model.parameters())
print(model_params)
if args.optimizer == "adam":
optimizer = torch.optim.Adam(model_params, lr=args.lr, weight_decay=args.weight_decay)
elif args.optimizer == "sgd":
optimizer = torch.optim.SGD(model_params, lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay)
if args.lr_decay_gamma:
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, args.lr_decay_step, gamma=args.lr_decay_gamma)
if args.train_cont:
reloadmodel.reload_optimizer(args.resume_path,optimizer,scheduler)
for epoch_idx in tqdm(range(epoch, args.epochs+1), desc="epoch"):
print(f"***Epoch #{epoch_idx}")
epochpass.epoch_pass(
loader,
model,
train=True,
optimizer=optimizer,
scheduler=scheduler,
lr_decay_gamma=args.lr_decay_gamma,
use_multiple_gpu=use_multiple_gpu,
tensorboard_writer=board_writer,
aggregate_sequence=False,
is_single_hand=args.train_dataset!="h2ohands",
dataset_action_info=dataset_info.action_to_idx,
dataset_object_info=dataset_info.object_to_idx,
ntokens = args.ntokens_action,
is_demo=False,
epoch=epoch_idx)
if epoch_idx%args.snapshot==0:
modelio.save_checkpoint(
{
"epoch": epoch_idx,
"network": "HTT",
"state_dict": model.module.state_dict() if use_multiple_gpu else model.state_dict(),
"optimizer": optimizer.state_dict(),
"scheduler": scheduler,
},
is_best=True,
checkpoint=exp_id,
snapshot=args.snapshot,)
board_writer.close()
if __name__ == "__main__":
torch.multiprocessing.set_sharing_strategy("file_system")
parser = argparse.ArgumentParser()
parser.add_argument('--experiment_tag',default='hello')
parser.add_argument('--dataset_folder',default='../fpha/')
parser.add_argument('--cache_folder',default='./ws/ckpts/')
parser.add_argument('--resume_path',default=None)
#Transformer parameters
parser.add_argument("--ntokens_pose", type=int, default=16, help="N tokens for P")
parser.add_argument("--ntokens_action", type=int, default=128, help="N tokens for A")
parser.add_argument("--spacing",type=int,default=2, help="Sample space for temporal sequence")
# Dataset params
parser.add_argument("--train_dataset",choices=["h2ohands", "fhbhands"],default="fhbhands",)
parser.add_argument("--train_split", default="train", choices=["test", "train", "val"])
parser.add_argument("--center_idx", default=0, type=int)
parser.add_argument("--center_jittering", type=float, default=0.1, help="Controls magnitude of center jittering")
parser.add_argument("--scale_jittering", type=float, default=0, help="Controls magnitude of scale jittering")
# Training parameters
parser.add_argument("--train_cont", action="store_true", help="Continue from previous training")
parser.add_argument("--manual_seed", type=int, default=0)
parser.add_argument("--batch_size", type=int, default=2, help="Batch size")
parser.add_argument("--workers", type=int, default=16, help="Number of workers for multiprocessing")
parser.add_argument("--pyapt_id")
parser.add_argument("--epochs", type=int, default=45)
parser.add_argument("--lr_decay_gamma", type=float, default= 0.5,help="Learning rate decay factor, if 1, no decay is effectively applied")
parser.add_argument("--lr_decay_step", type=float, default=15)
parser.add_argument("--lr", type=float, default=3e-5, help="Learning rate")
parser.add_argument("--optimizer", choices=["adam", "sgd"], default="adam")
parser.add_argument("--weight_decay", type=float, default=0)
parser.add_argument("--momentum", type=float, default=0.9)
parser.add_argument("--trans_factor", type=float, default=100, help="Multiplier for translation prediction")
parser.add_argument("--scale_factor", type=float, default=0.0001, help="Multiplier for scale prediction")
#Transformer
parser.add_argument("--pose_loss", default="l1", choices=["l2", "l1"])
parser.add_argument('--enc_pose_layers', default=2, type=int,
help="Number of encoding layers in P")
parser.add_argument('--enc_action_layers', default=2, type=int,
help="Number of encoding layers in A")
parser.add_argument('--dim_feedforward', default=2048, type=int,
help="Intermediate size of the feedforward layers in the transformer blocks")
parser.add_argument('--hidden_dim', default=512, type=int,
help="Size of the embeddings (dimension of the transformer)")
parser.add_argument('--dropout', default=0.0, type=float,
help="Dropout applied in the transformer")
parser.add_argument('--nheads', default=8, type=int,
help="Number of attention heads inside the transformer's attentions")
#Loss
parser.add_argument("--lambda_action_loss",type=float, default=1, help="Weight for action/object classification")#lambda for action, lambda_3
parser.add_argument("--lambda_hand_2d",type=float,default=1,help="Weight for hand 2D loss")#2*lambda_2, where factor 2 because of x and y
parser.add_argument("--lambda_hand_z",type=float,default=100,help="Weight for hand z loss")#lambda_1*lambda_2
parser.add_argument("--snapshot", type=int, default=5, help="How often to save intermediate models (epochs)" )
args = parser.parse_args()
for key, val in sorted(vars(args).items(), key=lambda x: x[0]):
print(f"{key}: {val}")
main(args)模型评估代码如下:
import argparse
from datetime import datetime
from matplotlib import pyplot as plt
import torch
from libyana.exputils.argutils import save_args
from libyana.modelutils import freeze
from libyana.randomutils import setseeds
from datasets import collate
from models.htt import TemporalNet
from netscripts import epochpass
from netscripts import reloadmodel, get_dataset
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
plt.switch_backend("agg")
print('********')
print('Lets start')
def collate_fn(seq, extend_queries=[]):
return collate.seq_extend_flatten_collate(seq,extend_queries)#seq_extend_collate(seq, extend_queries)
def main(args):
setseeds.set_all_seeds(args.manual_seed)
# Initialize hosting
now = datetime.now()
experiment_tag = args.experiment_tag
exp_id = f"{args.cache_folder}"+experiment_tag+"/"
save_args(args, exp_id, "opt")
print("**** Lets eval on", args.val_dataset, args.val_split)
val_dataset, _ = get_dataset.get_dataset_htt(
args.val_dataset,
dataset_folder=args.dataset_folder,
split=args.val_split,
no_augm=True,
scale_jittering=args.scale_jittering,
center_jittering=args.center_jittering,
ntokens_pose=args.ntokens_pose,
ntokens_action=args.ntokens_action,
spacing=args.spacing,
is_shifting_window=True,
split_type="actions"
)
val_loader = torch.utils.data.DataLoader(
val_dataset,
batch_size=args.batch_size,
shuffle=False,
num_workers=int(args.workers),
drop_last=False,
collate_fn= collate_fn,
)
dataset_info=val_dataset.pose_dataset
#Re-load pretrained weights
print('**** Load pretrained-weights from resume_path', args.resume_path)
model= TemporalNet(dataset_info=dataset_info,
is_single_hand=args.train_dataset!="h2ohands",
transformer_num_encoder_layers_action=args.enc_action_layers,
transformer_num_encoder_layers_pose=args.enc_pose_layers,
transformer_d_model=args.hidden_dim,
transformer_dropout=args.dropout,
transformer_nhead=args.nheads,
transformer_dim_feedforward=args.dim_feedforward,
transformer_normalize_before=True,
lambda_action_loss=1.,
lambda_hand_2d=1.,
lambda_hand_z=1.,
ntokens_pose= args.ntokens_pose,
ntokens_action=args.ntokens_action,
trans_factor=args.trans_factor,
scale_factor=args.scale_factor,
pose_loss=args.pose_loss)
epoch=reloadmodel.reload_model(model,args.resume_path)
use_multiple_gpu= torch.cuda.device_count() > 1
if use_multiple_gpu:
assert False, "Not implement- Eval with multiple gpus!"
#model = torch.nn.DataParallel(model).cuda()
else:
model.cuda()
freeze.freeze_batchnorm_stats(model)
model_params = filter(lambda p: p.requires_grad, model.parameters())
optimizer=None
val_save_dict, val_avg_meters, val_results = epochpass.epoch_pass(
val_loader,
model,
train=False,
optimizer=None,
scheduler=None,
lr_decay_gamma=0.,
use_multiple_gpu=False,
tensorboard_writer=None,
aggregate_sequence=True,
is_single_hand= args.train_dataset!="h2ohands",
dataset_action_info=dataset_info.action_to_idx,
dataset_object_info=dataset_info.object_to_idx,
ntokens=args.ntokens_action,
is_demo=args.is_demo,
epoch=epoch)
if __name__ == "__main__":
torch.multiprocessing.set_sharing_strategy("file_system")
parser = argparse.ArgumentParser()
# Base params
parser.add_argument('--experiment_tag',default='htt')
parser.add_argument('--is_demo', action="store_true", help="show demo result")
parser.add_argument('--dataset_folder',default='../fpha/')
parser.add_argument('--cache_folder',default='./ws/ckpts/')
parser.add_argument('--resume_path',default='./ws/ckpts/htt_fpha/checkpoint_45.pth')
#Transformer parameters
parser.add_argument("--ntokens_pose", type=int, default=16, help="N tokens for P")
parser.add_argument("--ntokens_action", type=int, default=128, help="N tokens for A")
parser.add_argument("--spacing",type=int,default=2, help="Sample space for temporal sequence")
# Dataset params
parser.add_argument("--train_dataset",choices=["h2ohands", "fhbhands"],default="fhbhands",)
parser.add_argument("--val_dataset", choices=["h2ohands", "fhbhands"], default="fhbhands",)
parser.add_argument("--val_split", default="test", choices=["test", "train", "val"])
parser.add_argument("--center_idx", default=0, type=int)
parser.add_argument(
"--center_jittering", type=float, default=0.1, help="Controls magnitude of center jittering"
)
parser.add_argument(
"--scale_jittering", type=float, default=0, help="Controls magnitude of scale jittering"
)
# Training parameters
parser.add_argument("--manual_seed", type=int, default=0)
parser.add_argument("--batch_size", type=int, default=8, help="Batch size")
parser.add_argument("--workers", type=int, default=4, help="Number of workers for multiprocessing")
parser.add_argument("--epochs", type=int, default=500)
parser.add_argument(
"--trans_factor", type=float, default=100, help="Multiplier for translation prediction"
)
parser.add_argument(
"--scale_factor", type=float, default=0.0001, help="Multiplier for scale prediction"
)
#Transformer
parser.add_argument("--pose_loss", default="l1", choices=["l2", "l1"])
parser.add_argument('--enc_pose_layers', default=2, type=int,
help="Number of encoding layers in P")
parser.add_argument('--enc_action_layers', default=2, type=int,
help="Number of encoding layers in A")
parser.add_argument('--dim_feedforward', default=2048, type=int,
help="Intermediate size of the feedforward layers in the transformer blocks")
parser.add_argument('--hidden_dim', default=512, type=int,
help="Size of the embeddings (dimension of the transformer)")#256
parser.add_argument('--dropout', default=0.1, type=float,
help="Dropout applied in the transformer")
parser.add_argument('--nheads', default=8, type=int,
help="Number of attention heads inside the transformer's attentions")
args = parser.parse_args()
for key, val in sorted(vars(args).items(), key=lambda x: x[0]):
print(f"{key}: {val}")
main(args)
总结
本文提出的层次化时序变换器通过创新的分层时序建模和双任务协同机制,显著提升了第一人称视频中的3D手部姿态估计性能。该模型采用局部--全局分层的Transformer架构,其中姿态估计分支聚焦短时序窗口以捕捉精细手部运动,动作识别分支整合长时序上下文信息,并通过跨任务交互实现特征共享。在FPHA和H2O数据集上,HTT将手部姿态估计误差降低12.3%,同时提升动作识别准确率4.1%,且保持32FPS的实时性能。这一工作不仅为解决遮挡、截断等第一人称视觉挑战提供了有效方案,其层次化时序建模思想和多任务协同框架更为视频理解、AR、VR交互等应用提供了重要技术启示,未来可进一步扩展至多模态融合和轻量化部署等方向。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









