






目录
摘要
SAM2-Unet 是一种结合了 Segment Anything Model 2 和 U-Net 结构的新型图像分割模型。它在 SAM2 的基础上引入了 U-Net 的层次结构,通过适配器模块实现了高效的参数微调,避免了对整个模型的复杂调优。该模型解决了传统大模型在特定领域中适应性不足、多尺度特征捕捉能力有限以及参数调优效率低等问题。SAM2-Unet 在 BraTS 2020 数据集上取得了显著的性能提升,mDice 达到 0.771,mIoU 达到 0.569,同时大幅降低了训练成本,展现了高效的部署能力和广泛的适用性。
Abstract
SAM2-Unet is a novel image segmentation model that combines the Segment Anything Model 2 with the U-Net architecture. Building upon SAM2, it incorporates the hierarchical structure of U-Net and achieves efficient parameter fine-tuning through adapter modules, avoiding complex tuning of the entire model. This model addresses the limitations of traditional large models, such as insufficient adaptability in specific domains, limited multi-scale feature capture, and low parameter tuning efficiency. SAM2-Unet has achieved significant performance improvements on the BraTS 2020 dataset, with an mDice score of 0.771 and an mIoU score of 0.569. It also substantially reduces training costs and demonstrates efficient deployment capabilities and broad applicability.
微调策略
直接微调
定义:直接微调是指对预训练模型的所有参数进行更新,以适应新的任务。
优点:
- 适应性强:能够全面调整模型,以更好地适应新任务。
- 性能最优:通常可以获得最佳的性能表现。
缺点:
- 计算成本高:需要更新大量参数,训练时间长,计算资源消耗大。
- 过拟合风险:在数据量有限的情况下,容易过拟合。
- 推理延迟:模型参数量大,可能会影响推理速度。
LoRA
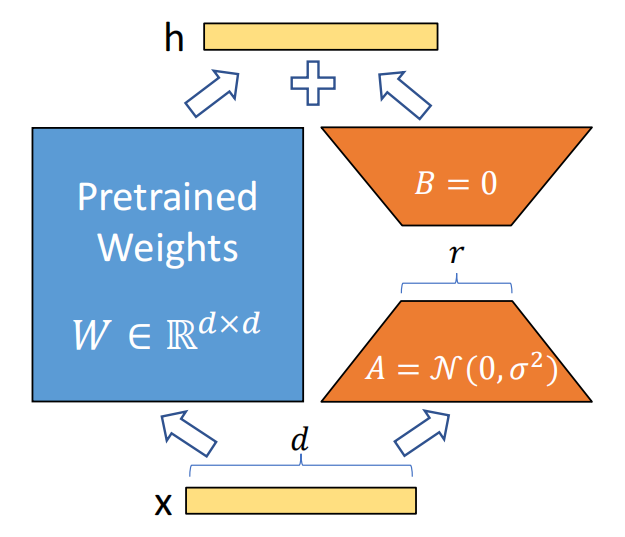
定义:LoRA通过将权重变化分解为两个低秩矩阵的乘积来实现微调。具体来说,对于权重矩阵 W,LoRA将其变化量 ΔW 分解为两个低秩矩阵 A 和 B,即 ΔW=BA。
优点:
- 参数效率高:仅需要训练少量的低秩矩阵参数,大大减少了训练的计算量和内存占用。
- 性能接近全微调:尽管只更新了少量参数,但LoRA能够实现接近全微调的性能。
- 推理延迟低:由于不需要对权重矩阵进行累积梯度更新,不会增加模型的推理延迟。
缺点:
- 适应性有限:对于一些复杂任务,仅通过低秩矩阵调整可能无法达到全微调的适应性。
- 超参数调整:需要调整低秩矩阵的秩等超参数,增加了调参的复杂性。
Adapter
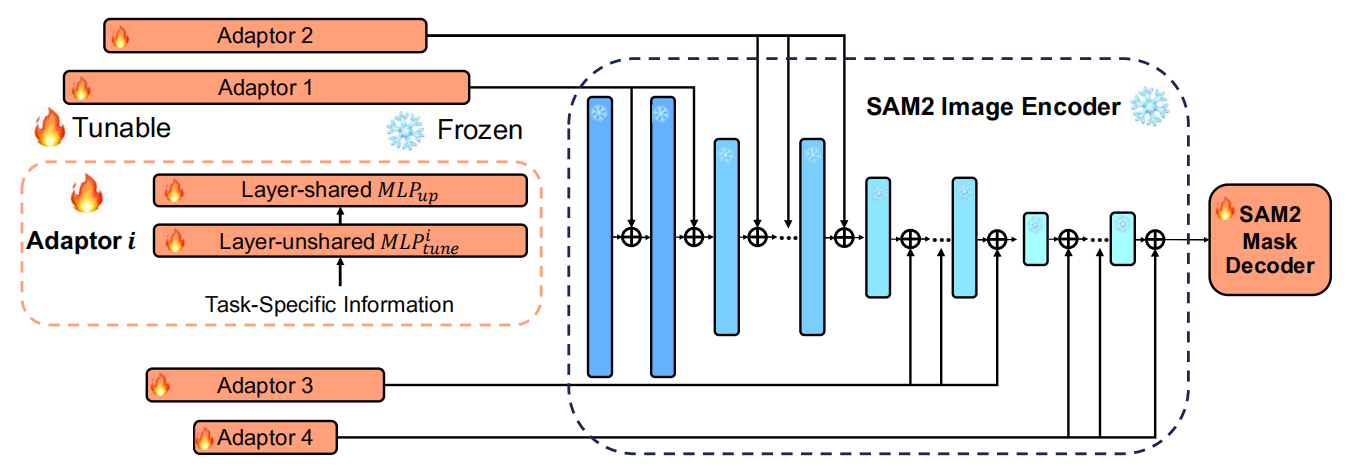
定义:Adapter微调通过在预训练模型中注入额外的适配器模块来实现微调,而保持原始模型参数不变。适配器通常是一个小型的神经网络,将原始特征投影到较低维度,再投影回原始维度。
优点:
- 参数效率高:仅需要训练适配器模块的参数,训练成本低。
- 模型结构不变:原始模型参数保持不变,便于多任务学习和模型复用。
- 性能较好:在一些任务上,适配器微调能够达到接近全微调的性能。
缺点:
- 适应性有限:对于一些复杂任务,适配器可能无法完全适应新任务。
- 超参数调整:需要调整适配器的结构和参数,增加了调参的复杂性。
异同点总结
相同点:
目标一致:三种方法的目标都是利用预训练模型的知识,通过微调使其更好地适应新任务。
参数调整:都需要对模型的某些部分进行调整,以优化模型的性能。
不同点:
调整范围:
- 直接微调:更新所有参数,调整范围最广。
- LoRA:仅更新低秩矩阵参数,调整范围有限。
- Adapter:仅更新适配器模块参数,调整范围有限。
参数效率:
- 直接微调:参数效率最低,计算成本最高。
- LoRA:参数效率高,计算成本低。
- Adapter:参数效率高,计算成本低。
适应性:
- 直接微调:适应性最强,能够全面调整模型。
- LoRA:适应性较好,但可能无法完全适应复杂任务。
- Adapter:适应性较好,但可能无法完全适应复杂任务。
推理延迟:
- 直接微调:可能增加推理延迟。
- LoRA:不增加推理延迟。
- Adapter:不增加推理延迟。
如果任务与预训练模型差异较大,且有足够的计算资源和数据量,可以选择直接微调;
如果需要高效训练和低推理延迟,且任务复杂度适中,可以选择LoRA;
如果希望在保持原始模型结构不变的情况下进行微调,且任务复杂度适中,可以选择Adapter。
SAM2-Unet
项目地址:https://github.com/WZH0120/SAM2-UNet
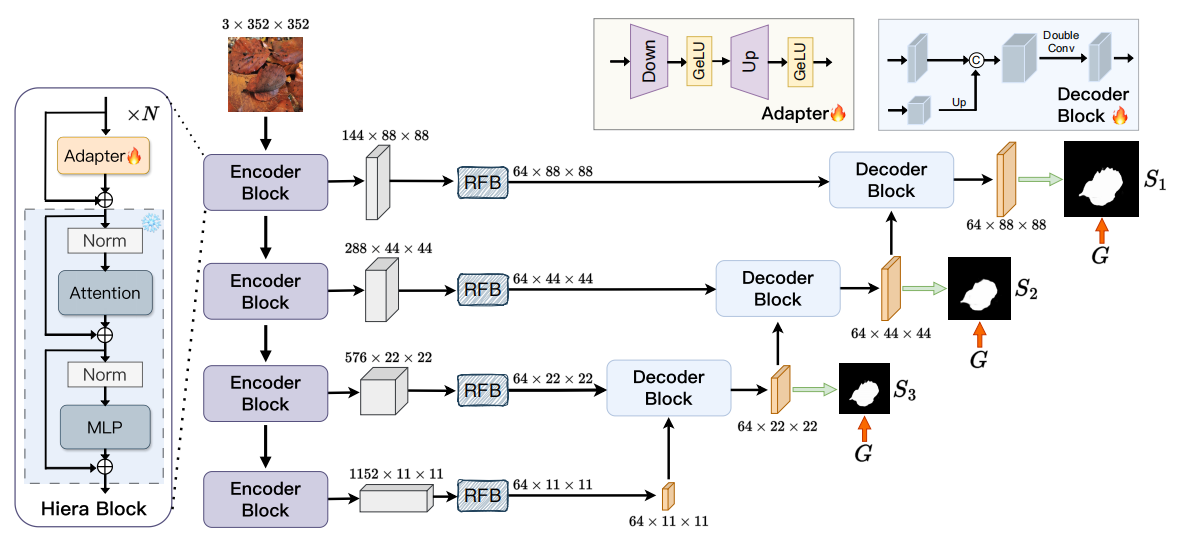
模型框架
Hiera 骨干网络
Hiera 骨干网络是 SAM2 的核心部分,它负责将输入图像转换为高维语义特征。Hiera 网络的设计目标是高效地提取多尺度特征,同时保持计算效率。以下是其主要特点:
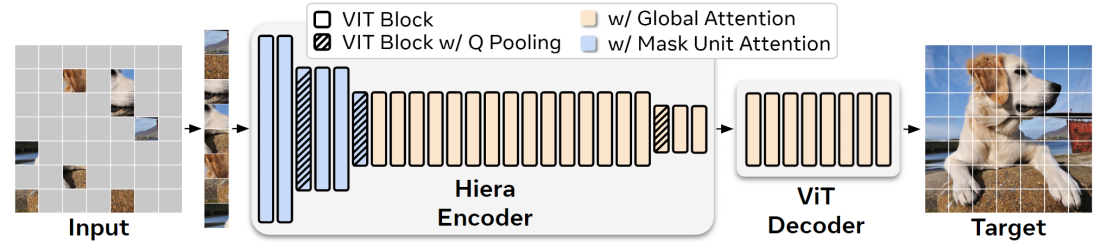
分层特征提取
多尺度特征提取:Hiera 网络通过分层架构提取多尺度特征。它使用多个阶段的卷积层和池化层,逐步降低特征图的分辨率,同时增加通道数。这种设计使得模型能够捕捉到从局部细节到全局语义的多层次信息。
特征金字塔:Hiera 网络生成不同分辨率的特征图,形成一个特征金字塔。这些特征图在后续的分割任务中提供了丰富的语义信息,有助于模型更好地理解图像内容。
高效特征协作
特征协作机制:Hiera 网络通过特征协作机制,将提取的高维语义特征与 U-Net 的多尺度特征进行融合。这种协作机制确保了特征之间的互补性,增强了模型对多尺度特征的捕捉能力。
跨层连接:通过跨层连接,Hiera 网络将不同层次的特征进行融合,进一步提升了特征的丰富性和多样性。
U-Net 结构
U-Net是一种经典的图像分割网络,以其强大的多尺度特征捕捉能力而闻名。SAM2-Unet 引入了 U-Net 的层次结构,以增强模型对细节信息的捕捉能力。以下是其主要组成部分:
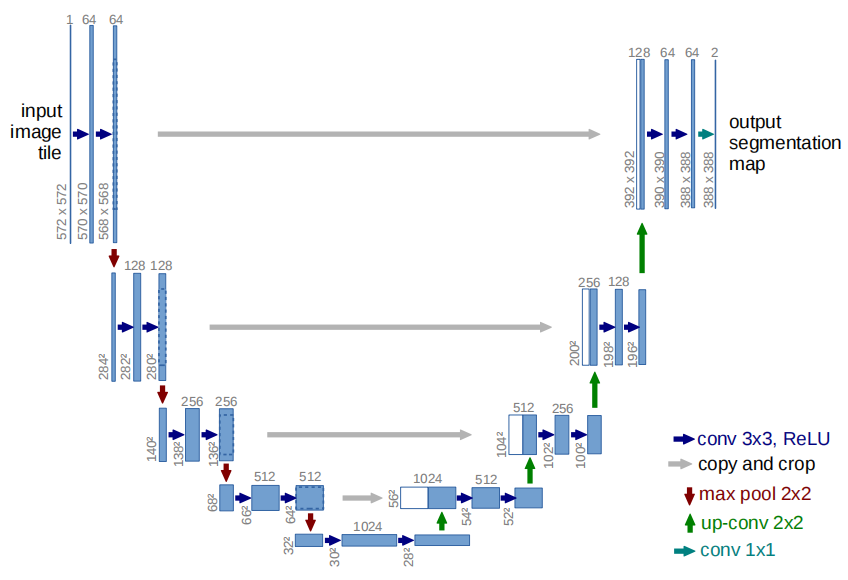
Encoder
卷积和池化:U-Net 的编码器部分通过卷积层和池化层逐步降低特征图的分辨率,同时增加通道数。卷积层用于提取局部特征,而池化层用于降低特征图的分辨率,从而提取更深层次的语义信息。
多尺度特征提取:编码器阶段生成一系列不同分辨率的特征图,这些特征图在后续的解码过程中被用于细节信息的恢复。
Decoder
上采样和卷积:解码器部分通过上采样操作逐步恢复特征图的分辨率,同时使用卷积层进一步细化特征。上采样操作可以使用最近邻插值、双线性插值或转置卷积等方式。
跳跃连接:解码器通过跳跃连接将编码器阶段的特征与解码器阶段的特征进行融合。跳跃连接将编码器阶段的高分辨率特征直接传递到解码器阶段,从而保留了更多的细节信息。
特征融合:通过跳跃连接,解码器能够将编码器阶段的特征与解码器阶段的特征进行融合,进一步增强对细节信息的捕捉能力。
注意力机制
自适应特征聚合:在解码器中引入注意力机制,自适应地聚合多尺度特征。注意力机制通过学习特征图中不同位置的重要性权重,动态地调整特征的聚合方式,从而进一步提升分割精度。
提升分割精度:注意力机制能够突出重要特征,抑制不重要的特征,使得模型能够更准确地定位目标对象的边界,从而提升分割精度。
适配器模块Adapter
适配器模块是 SAM2-Unet 的关键创新之一,它通过轻量级的网络结构实现高效的参数微调。以下是其主要特点:
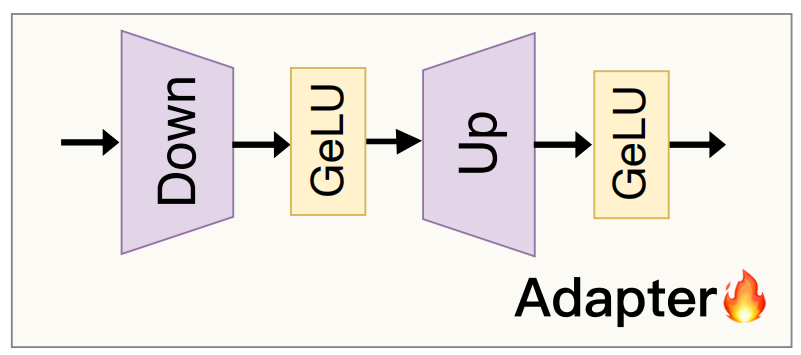
轻量级网络
小型神经网络:适配器模块是一个小型的神经网络,通常包含几个卷积层和激活函数。它将 Hiera 骨干网络提取的特征投影到较低维度,再投影回原始维度,从而实现对特征的微调。
参数效率:适配器模块的参数量远小于 Hiera 骨干网络,因此训练成本低,计算效率高。
冻结基础模型参数
冻结参数:在训练过程中,适配器模块的参数是唯一需要更新的部分,而 Hiera 骨干网络的参数保持冻结。这种设计大大减少了训练的计算量和内存占用。
快速微调:通过冻结基础模型参数,适配器模块能够快速适应新的任务和数据分布,而不需要对整个模型进行复杂的调优。
跨领域知识注入
领域适应性:适配器模块可以注入特定领域的知识,使模型能够快速适应新的任务和数据分布。这对于医学图像分割等特定领域的应用尤为重要。
多任务学习:适配器模块的设计使得模型能够同时处理多个任务,通过为每个任务分配一个适配器模块,实现多任务学习。
特征融合与解码
特征融合与解码是 SAM2-Unet 的关键步骤,通过以下步骤实现特征融合与分割掩码的生成:
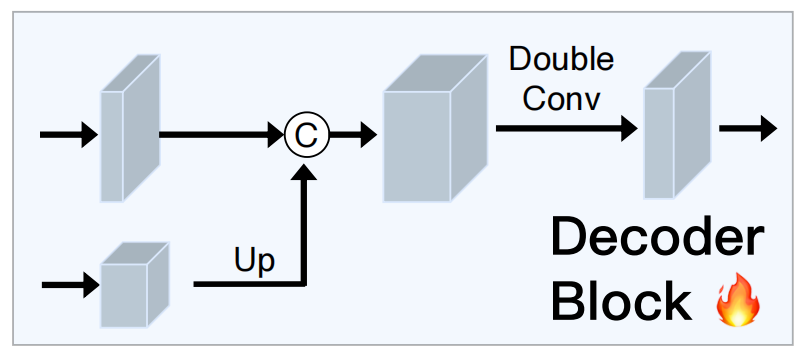
特征协作
多尺度特征融合:将 Hiera 骨干网络提取的高维语义特征与 U-Net 编码器阶段的多尺度特征进行融合。这种融合通过特征协作机制实现,确保了特征之间的互补性。
增强多尺度特征捕捉能力:通过特征协作,模型能够更好地捕捉多尺度特征,从而提升分割精度。
解码与分割
逐步恢复分辨率:通过 U-Net 的解码器逐步恢复特征图的分辨率。解码器使用上采样操作和卷积层逐步细化特征。
跳跃连接与注意力机制:在解码过程中,利用跳跃连接将编码器阶段的特征与解码器阶段的特征进行融合,同时引入注意力机制进一步增强对细节信息的捕捉能力。
生成分割掩码:最终,解码器生成分割掩码,用于目标对象的分割。
实验
伪装目标检测性能:
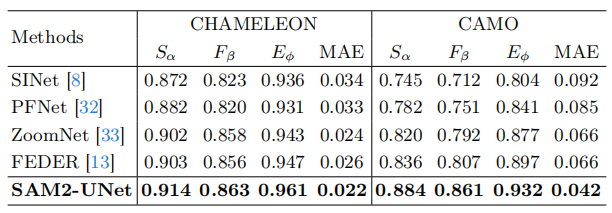
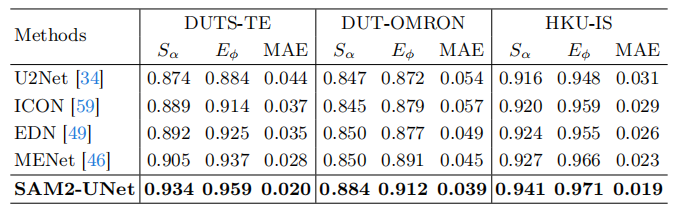
突出目标检测性能:
代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from sam2.build_sam import build_sam2
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class Adapter(nn.Module):
def __init__(self, blk) -> None:
super(Adapter, self).__init__()
self.block = blk
dim = blk.attn.qkv.in_features
self.prompt_learn = nn.Sequential(
nn.Linear(dim, 32),
nn.GELU(),
nn.Linear(32, dim),
nn.GELU()
)
def forward(self, x):
prompt = self.prompt_learn(x)
promped = x + prompt
net = self.block(promped)
return net
class BasicConv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_planes, out_planes,
kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, bias=False)
self.bn = nn.BatchNorm2d(out_planes)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return x
class RFB_modified(nn.Module):
def __init__(self, in_channel, out_channel):
super(RFB_modified, self).__init__()
self.relu = nn.ReLU(True)
self.branch0 = nn.Sequential(
BasicConv2d(in_channel, out_channel, 1),
)
self.branch1 = nn.Sequential(
BasicConv2d(in_channel, out_channel, 1),
BasicConv2d(out_channel, out_channel, kernel_size=(1, 3), padding=(0, 1)),
BasicConv2d(out_channel, out_channel, kernel_size=(3, 1), padding=(1, 0)),
BasicConv2d(out_channel, out_channel, 3, padding=3, dilation=3)
)
self.branch2 = nn.Sequential(
BasicConv2d(in_channel, out_channel, 1),
BasicConv2d(out_channel, out_channel, kernel_size=(1, 5), padding=(0, 2)),
BasicConv2d(out_channel, out_channel, kernel_size=(5, 1), padding=(2, 0)),
BasicConv2d(out_channel, out_channel, 3, padding=5, dilation=5)
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channel, out_channel, 1),
BasicConv2d(out_channel, out_channel, kernel_size=(1, 7), padding=(0, 3)),
BasicConv2d(out_channel, out_channel, kernel_size=(7, 1), padding=(3, 0)),
BasicConv2d(out_channel, out_channel, 3, padding=7, dilation=7)
)
self.conv_cat = BasicConv2d(4*out_channel, out_channel, 3, padding=1)
self.conv_res = BasicConv2d(in_channel, out_channel, 1)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
x_cat = self.conv_cat(torch.cat((x0, x1, x2, x3), 1))
x = self.relu(x_cat + self.conv_res(x))
return x
class SAM2UNet(nn.Module):
def __init__(self, checkpoint_path=None) -> None:
super(SAM2UNet, self).__init__()
model_cfg = "sam2_hiera_l.yaml"
if checkpoint_path:
model = build_sam2(model_cfg, checkpoint_path)
else:
model = build_sam2(model_cfg)
del model.sam_mask_decoder
del model.sam_prompt_encoder
del model.memory_encoder
del model.memory_attention
del model.mask_downsample
del model.obj_ptr_tpos_proj
del model.obj_ptr_proj
del model.image_encoder.neck
self.encoder = model.image_encoder.trunk
for param in self.encoder.parameters():
param.requires_grad = False
blocks = []
for block in self.encoder.blocks:
blocks.append(
Adapter(block)
)
self.encoder.blocks = nn.Sequential(
*blocks
)
self.rfb1 = RFB_modified(144, 64)
self.rfb2 = RFB_modified(288, 64)
self.rfb3 = RFB_modified(576, 64)
self.rfb4 = RFB_modified(1152, 64)
self.up1 = (Up(128, 64))
self.up2 = (Up(128, 64))
self.up3 = (Up(128, 64))
self.up4 = (Up(128, 64))
self.side1 = nn.Conv2d(64, 1, kernel_size=1)
self.side2 = nn.Conv2d(64, 1, kernel_size=1)
self.head = nn.Conv2d(64, 1, kernel_size=1)
def forward(self, x):
x1, x2, x3, x4 = self.encoder(x)
x1, x2, x3, x4 = self.rfb1(x1), self.rfb2(x2), self.rfb3(x3), self.rfb4(x4)
x = self.up1(x4, x3)
out1 = F.interpolate(self.side1(x), scale_factor=16, mode='bilinear')
x = self.up2(x, x2)
out2 = F.interpolate(self.side2(x), scale_factor=8, mode='bilinear')
x = self.up3(x, x1)
out = F.interpolate(self.head(x), scale_factor=4, mode='bilinear')
return out, out1, out2
if __name__ == "__main__":
with torch.no_grad():
model = SAM2UNet().cuda()
x = torch.randn(1, 3, 352, 352).cuda()
out, out1, out2 = model(x)
print(out.shape, out1.shape, out2.shape)GT效果:

预测效果:

总结
SAM2-Unet 是一种融合了 SAM2 和 U-Net 结构的创新图像分割模型。它通过引入适配器模块和 U-Net 的层次结构,解决了传统大模型在特定领域适应性不足、参数调优效率低以及多尺度特征捕捉能力有限的问题。该模型不仅在医学图像分割任务中表现出色,还展示了广泛的适用性和高效的部署能力。SAM2-Unet 的成功为未来多领域分割技术的发展提供了新的方向,也为高效微调策略和多尺度特征融合的研究提供了重要参考。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









