






JVM,JDK,JRE三者的关系
概念
JVM(Java Virtual Machine,Java虚拟机)、JDK(Java Development Kit,Java开发工具包)、JRE(Java Runtime Environment,Java运行环境)
-
JVM (Java Virtual Machine): JVM是Java程序的运行环境核心,它是一个抽象化的计算机,能够执行Java字节码。JVM负责将编译后的字节码转换为特定硬件平台上的机器指令并执行。每个Java应用都是在JVM上运行的,这使得Java具有“一次编写,到处运行”的跨平台能力。
-
JRE (Java Runtime Environment): JRE是运行Java应用程序所必需的环境。它包含了JVM以及Java类库(也就是Java SE API),提供运行Java程序的基础。JRE使用户能够在没有开发需求的计算机上运行Java应用程序,但它不包含开发工具,如编译器或调试器。
-
JDK (Java Development Kit): JDK是面向Java开发者的工具包,它不仅包含了JRE的所有内容(即JVM和运行Java程序所需的类库),还额外提供了编译器(javac)、调试器(jdb)、文档生成工具(javadoc)以及其他开发工具,使得开发者能够编写、编译、调试和部署Java应用程序。简单来说,如果你想编写Java程序,就需要安装JDK。
总结:
- 层次结构上,JDK位于最顶层,它包含了JRE;而JRE又包含了JVM。
- 功能区分上,JDK服务于开发过程,提供编译、调试等开发工具;JRE服务于程序运行,提供运行环境;JVM是运行Java字节码的引擎,是这一切的基础。
- 安装关系上,安装JDK时会自动安装JRE和JVM,因为开发过程中既需要运行环境也需要开发工具。而如果你只需要运行Java程序,则只需安装JRE,此时也会自动包含JVM。
基本数据类型
java的基本数据类型有8种,分别是byte,short ,int,long,float,double,char,boolean.
符号位中,0代表正数,1代表负数。
-
数值型:
-
byte: 8位有符号整数。默认值为0。
-
short: 16位有符号整数。默认值为0。
-
int: 32位有符号整数。默认值为0。
-
long: 64位有符号整数。在数值后加"L"表示长整型。
-
float: 32位单精度浮点数。默认值为0.0f,数值后加"F"。
-
double: 64位双精度浮点数,提供更高的精度。Java中默认的浮点数类型。默认值为0.0,无需后缀。
-
-
字符型:
- char: 16位无符号Unicode字符。可以存储任何字符,包括字母、数字、标点符号等。
-
布尔型:
- boolean: 逻辑类型,只接受两个值:
true或false。默认值未明确指定,但在实际编程中,未初始化的布尔变量应避免使用。
- boolean: 逻辑类型,只接受两个值:
为了能在泛型集合或需要对象的地方使用这些基本类型,Java提供了相应的包装类,比如 Byte, Short, Integer, Long, Float, Double, Character, 和 Boolean。这些包装类作为对象存在,提供了丰富的操作方法,并能与基本类型进行自动装箱和拆箱操作。
类型转换
Java中的类型转换主要分为两种情况:自动类型转换(隐式转换) 和 强制类型转换(显式转换)。
自动类型转换(隐式转换)
自动类型转换发生在两种场景:
1. 小范围类型向大范围类型转换:例如,将`byte`、`short`、`char`类型自动转换为`int`类型,或者将`int`类型转换为`long`、`float`、`double`类型。这是因为大类型能容纳小类型的所有可能值。
2. 从低级原始类型向高级原始类型转换:如`int`转`long`、`float`转`double`等,这不会造成数据丢失。
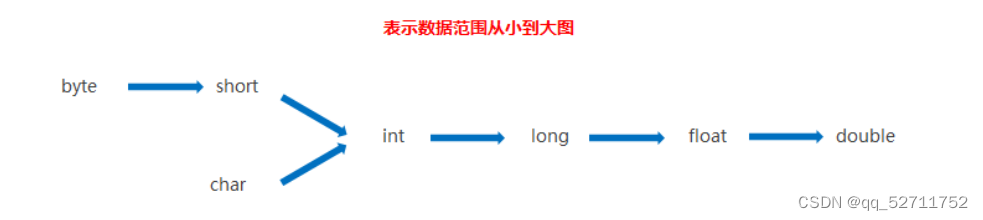
强制类型转换(显式转换)
强制类型转换需要开发人员显式地指明类型转换的方向,通常用于将大范围类型转换为小范围类型,或者将对象转换为其超类或接口类型。这可能导致数据丢失或精度下降。
注意事项:
- 强制类型转换可能导致数据溢出或精度损失。
- 当将一个对象转换为其父类或实现了的接口类型时,这种转换是安全的,不需要显式转换。
- 将父类对象转换为子类类型(向下转型)时,必须确保该对象实际上是目标子类的实例,否则会抛出`ClassCastException`异常。
类型转换与包装类
Java还提供了基本类型与其对应的包装类之间的自动装箱和拆箱操作,这也是类型转换的一种形式:
自动装箱:自动将基本类型转换为对应的包装类实例,如 `int i = 10; Integer num = i;`
自动拆箱:自动将包装类实例转换为基础类型,如 `Integer num = 10; int i = num;`
标识符
标识符是用户编程时使用的名字,用于给类、方法、变量、常量等命名。
Java中标识符的组成规则:
由字母、数字、下划线“_”、美元符号“$”组成,第一个字符不能是数字。
不能使用java中的关键字作为标识符。
标识符对大小写敏感(区分大小写)。
Java中标识符的命名约定:
小驼峰式命名:变量名、方法名
首字母小写,从第二个单词开始每个单词的首字母大写。
大驼峰式命名:类名
每个单词的首字母都大写。
另外,标识符的命名最好可以做到见名知意
例如:username、studentNumber等。
运算符
和别的语言大差不差,就是+-*/自增自减大于小于。
| 符号 | 作用 | 说明 |
|---|---|---|
| & | 逻辑与 | a&b,a和b都是true,结果为true,否则为false |
| | | 逻辑或 | a|b,a和b都是false,结果为false,否则为true |
| ^ | 逻辑异或 | a^b,a和b结果不同为true,相同为false |
| ! | 逻辑非 | !a,结果和a的结果正好相反 |
| && | 短路与 | 作用和&相同,但是有短路效果 |
| || | 短路或 | 作用和\|相同,但是有短路效果 |
具有短路效果。只要有一个表达式的值为false,那么结果就可以判定为false了,没有必要将所有表达式的值都计算出来,短路与操作就有这样的效果,可以提高效率。同理在逻辑或运算中,一旦发现值为true,右边的表达式将不再参与运算。
三元运算符
关系表达式 ? 表达式1 : 表达式2;
解释:问号前面的位置是判断的条件,判断结果为boolean型,为true时调用表达式1,为false时调用表达式2。其逻辑为:如果条件表达式成立或者满足则执行表达式1,否则执行第二个。
int a = 10;
int b = 20;
int c = a > b ? a : b; // 判断 a>b 是否为真,如果为真取a的值,如果为假,取b的值分支结构
if结构
if (关系表达式) {
语句体;
}if (关系表达式) {
语句体1;
} else {
语句体2;
}if (关系表达式1) {
语句体1;
} else if (关系表达式2) {
语句体2;
}
…
else {
语句体n+1;
}括号里判断为真执行。
switch语句
switch (表达式) {
case 1:
语句体1;
break;
case 2:
语句体2;
break;
...
default:
语句体n+1;
break;
}执行流程:
* 首先计算出表达式的值
* 其次,和case依次比较,一旦有对应的值,就会执行相应的语句,在执行的过程中,遇到break就会结 束。
* 最后,如果所有的case都和表达式的值不匹配,就会执行default语句体部分,然后程序结束掉。
case穿透
case穿透是如何产生的?
如果switch语句中,case省略了break语句, 就会开始case穿透.
现象:
当开始case穿透,后续的case就不会具有匹配效果,内部的语句都会执行
直到看见break,或者将整体switch语句执行完毕,才会结束。
class Demo{
public static void main(String[] args){
show(0);
show(1);
}
public static void show(int i){
switch(i){
default:
i+=2;
case 1:
i+=1;
case 4:
i+=8;
case 2:
i+=4;
}
System.out.println("i="+i);
}
}结果是15,14。代码会先执行default,但是没有break,所以会顺序执行完全部代码,第二个数同理,从case 1执行完到结束。
优缺点
if 分支语句 和 switch 语句 都是用来实现条件逻辑控制的结构,但它们有各自的特点、优势和局限性。下面是两者的对比优缺点:
if 分支语句
优点:
1. 灵活性高:if语句可以处理任意布尔表达式,支持复杂的条件逻辑,包括区间判断和逻辑组合。
2. 适应性强:适用于多种条件判断场景,特别是当条件判断不是基于几个离散值时,if语句能够更好地适应。
3. 嵌套使用:可以通过嵌套使用形成多层逻辑判断,实现复杂的决策树结构。
缺点:
1. 可读性差:当条件分支增多时,if语句嵌套可能会导致代码结构混乱,难以阅读和维护。
2. 性能考量:在分支众多且条件判断复杂时,可能不如switch语句高效,因为每次条件判断都需要计算和比较。
switch 语句
优点:
1. 结构清晰:当处理多个基于同一变量的离散值判断时,switch语句能够提供清晰、易于理解的结构。
2. 执行效率高:对于大量分支的情况,尤其是基于常量值的判断,switch语句可能经过编译器优化,生成更高效的代码。
3. 代码精简:相较于if语句的多重嵌套,switch语句通过case直接对应不同的处理逻辑,使得代码更加简洁。
缺点:
1. 限制条件:switch表达式只能处理有限的几个常量值或枚举类型,不支持范围判断或复杂的布尔逻辑。
2. 默认支持:仅有一个default分支来处理所有未匹配的情况,不适用于需要基于区间或复合条件判断的场景。
总结
- 选择依据:如果条件判断基于几个明确的离散值,且逻辑较为简单,switch语句是更好的选择,因为它更高效且易于阅读。而面对复杂的条件逻辑、区间判断或需要灵活的条件组合时,if语句提供了必要的灵活性。
- 性能考虑:在分支较少或逻辑复杂时,if语句的性能差异可能不明显;但当分支增多,特别是处理等值判断时,switch语句通常具有更好的性能表现。
- 编码实践:根据具体情况权衡,选择最适合当前需求的结构。在实际编程中,合理利用这两种结构,可以让代码既高效又易于维护。
循环结构
* 跳转控制语句(break)
* 跳出循环,结束循环
* 跳转控制语句(continue)
* 跳过本次循环,继续下次循环
for循环
for (初始化语句;条件判断语句;条件控制语句) {
循环体语句;
}-
格式解释:
-
初始化语句: 用于表示循环开启时的起始状态,简单说就是循环开始的时候什么样
-
条件判断语句:用于表示循环反复执行的条件,简单说就是判断循环是否能一直执行下去
-
循环体语句: 用于表示循环反复执行的内容,简单说就是循环反复执行的事情
-
条件控制语句:用于表示循环执行中每次变化的内容,简单说就是控制循环是否能执行下去
-
-
执行流程:
①执行初始化语句
②执行条件判断语句,看其结果是true还是false
如果是false,循环结束
如果是true,继续执行
③执行循环体语句
④执行条件控制语句
⑤回到②继续
class Demo{
public static void main(String[] args){
int x = 1;
for(show('a'); show('b') && x<3; show('c')){
show('d');
x++;
}
}
public static boolean show(char ch){
System.out.print(ch);
return true;
}
}结果abdcbdcb 。
解析
1. 初始化:`show('a')`
- 打印 `a`
2. 条件判断:`show('b') && x < 3`
- `show('b')` 打印 `b` 并返回 `true`
- `x < 3` 判断为 `true`,因为此时 `x` 为 1
- 条件为真,进入循环体
3. 循环体:`show('d'); x++;`
- `show('d')` 打印 `d`
- `x++`,此时 `x` 变为 2
4. 更新部分:`show('c')`
- `show('c')` 打印 `c`
现在循环重复:
1. 条件判断:`show('b') && x < 3`
- `show('b')` 打印 `b` 并返回 `true`
- `x < 3` 判断为 `true`,因为此时 `x` 为 2
- 条件为真,进入循环体
2. 循环体:`show('d'); x++;`
- `show('d')` 打印 `d`
- `x++`,此时 `x` 变为 3
3. 更新部分:`show('c')`
- `show('c')` 打印 `c`
再次检查条件:
1. 条件判断:`show('b') && x < 3`
- `show('b')` 打印 `b` 并返回 `true`
- `x < 3` 判断为 `false`,因为此时 `x` 为 3
- 条件为假,循环终止
while循环
初始化语句;
while (条件判断语句) {
循环体语句;
条件控制语句;
}while循环执行流程:
①执行初始化语句
②执行条件判断语句,看其结果是true还是false
如果是false,循环结束
如果是true,继续执行
③执行循环体语句
④执行条件控制语句
⑤回到②继续
dowhile循环
初始化语句;
do {
循环体语句;
条件控制语句;
}while(条件判断语句);
-
执行流程:
① 执行初始化语句
② 执行循环体语句
③ 执行条件控制语句
④ 执行条件判断语句,看其结果是true还是false
如果是false,循环结束
如果是true,继续执行
⑤ 回到②继续
三种循环区别
-
三种循环的区别
-
for循环和while循环先判断条件是否成立,然后决定是否执行循环体(先判断后执行)
-
do...while循环先执行一次循环体,然后判断条件是否成立,是否继续执行循环体(先执行后判断)
-
-
for循环和while的区别
-
条件控制语句所控制的自增变量,因为归属for循环的语法结构中,在for循环结束后,就不能再次被访问到了
-
条件控制语句所控制的自增变量,对于while循环来说不归属其语法结构中,在while循环结束后,该变量还可以继续使用
-
优缺点
`for`循环和`while`循环都是编程中常用的循环结构,它们各有特点和适用场景,下面是它们的一些对比和优缺点:
### for循环
优点:
1. 结构紧凑:`for`循环通常用于已知迭代次数的情况,它的语法结构将初始化、条件检查、迭代更新集中在一行,使得循环结构看起来更为简洁。
2. 易于理解:特别是在处理数组或集合遍历时,`for`循环(特别是增强型`for`循环,如Java中的`for-each`循环)能够清晰地表达遍历意图,提高代码的可读性。
缺点:
1. 灵活性较低:相比`while`循环,`for`循环的结构较为固定,对于一些复杂的循环条件或非线性的迭代过程,可能不如`while`循环灵活。
2. 限制较多:如果迭代逻辑复杂,需要多次更改循环控制变量,`for`循环的自动更新部分可能不够直观或适用。
while循环
优点:
1. 高度灵活:`while`循环提供最大的灵活性,几乎可以用来实现任何类型的循环逻辑,特别适合于循环条件或迭代步骤不那么规律的情况。
2. 条件控制自由:可以在循环体内部任意位置改变控制循环的条件变量,使得循环控制逻辑更加灵活多变。
缺点:
1. 可读性较差:特别是在循环控制复杂时,`while`循环的条件和迭代更新分散在循环体内外,可能使得代码较难理解。
2. 易出错:由于循环控制的自由度高,如果循环条件或迭代更新逻辑设置不当,容易出现无限循环的错误。
总结
选择`for`循环还是`while`循环,通常取决于具体的编程需求:
- 当循环次数在循环开始时就可以确定,或者循环逻辑相对简单且迭代次数与控制变量的更新直接相关时,`for`循环更为合适。
- 对于循环条件不明确、迭代逻辑复杂,或需要在循环过程中动态改变循环条件的情况,`while`循环提供了更大的灵活性。















 7065
7065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









