






1 情感分类概念介绍
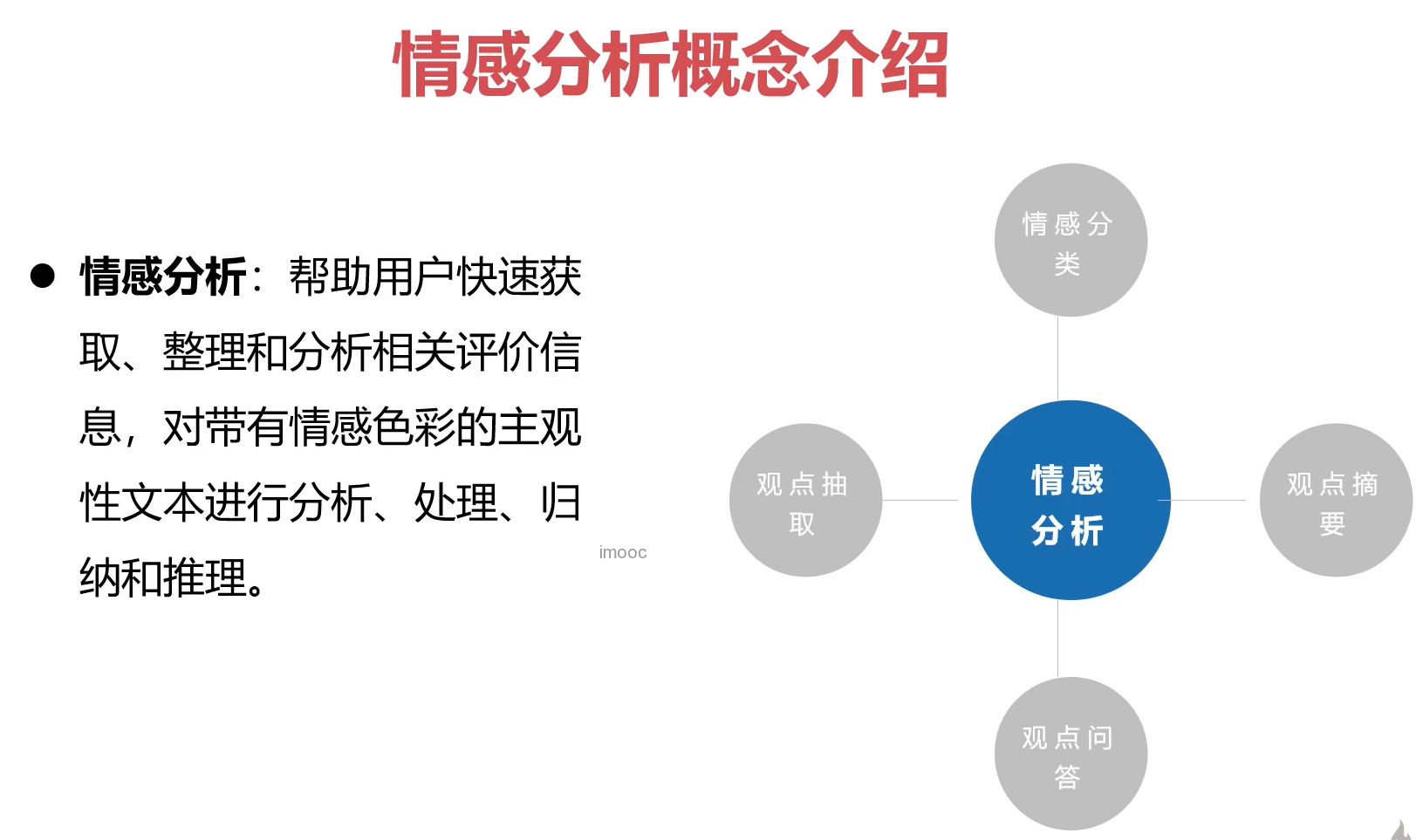

粒度:文章,段落,句子,词组
情感分类(倾向性分析):积极,中性,消极
2 情感分类流程
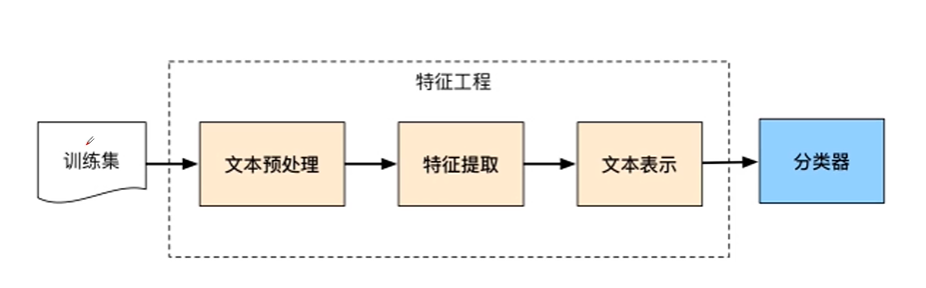
训练集:建立语料库
文本预处理:对语料库进行加工。例如中文进行分词
特征提取:对文本内容进行数据分析挖掘等时,需要对文字重新进行编码。(文本转向量)
文本表示:拿到可以被机器识别的文本信息
分类器:情感分析典型的分类问题。
3 文本预处理-中文分词

分词的同时进行句法,语义分析,利用句法信息和语义信息来处理歧义现象
对于英文就可以之间以空格进行分词。
例:南京长江大桥--南京/长江/大桥--南京/长江大桥 基于理解的分词有歧义

去除停用词,例如的,而,吗,!#等特殊符号
文本特征表示与文字表示

所谓one hot就是当前的这个字对应到的字典中的索引这个值我们将他定义为1,其他的定义为0
例如北京欢迎你 分词为 北京 欢迎 你 编码为北京为100,欢迎为010 你为001

本文采用BERT。
文本分类模型


N-gram 是一种文本表示方法,它将文本分割成连续的字符序列,并对这些序列进行统计分析。具体来说,N-gram 是由 N 个连续的字符组成的子序列,其中 N 是一个整数。
例如,对于一个句子“Hello world”,1-gram 可以是“H”、“e”、“l”、“l”、“o”、“w”、“r”、“l”和“d”等单个字符。2-gram 可以是“He”、“el”、“ll”、“lo”、“ow”、“wr”和“ld”等两个连续字符的组合。3-gram 可以是“Hel”、“ell”、“llo”、“low”、“owl”和“wor”等三个连续字符的组合,依此类推。
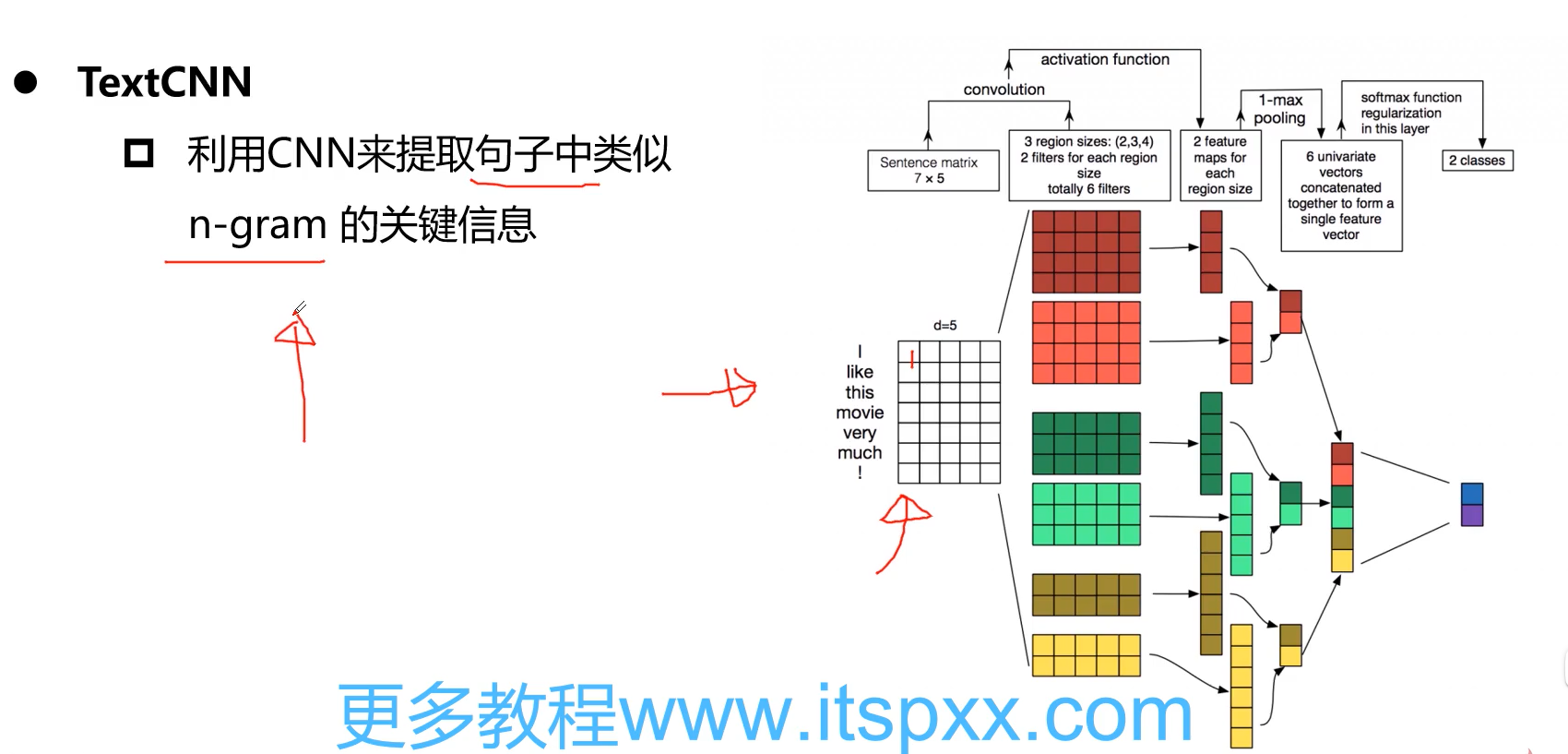
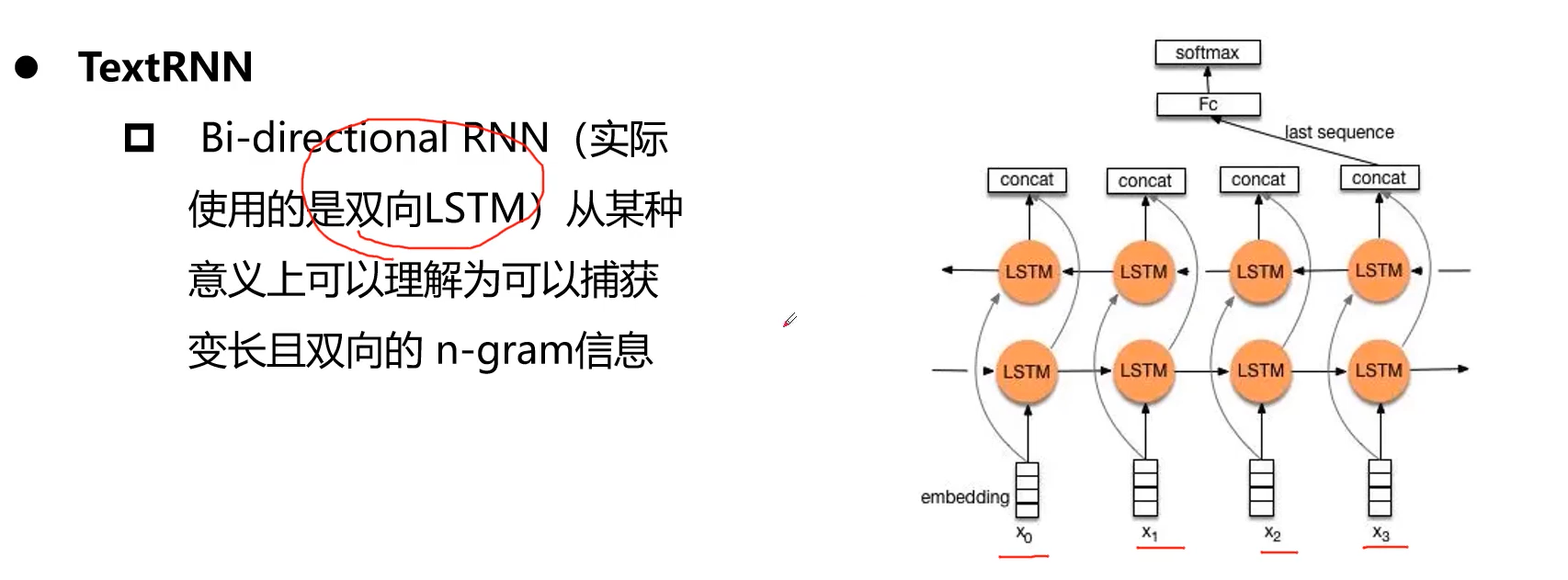
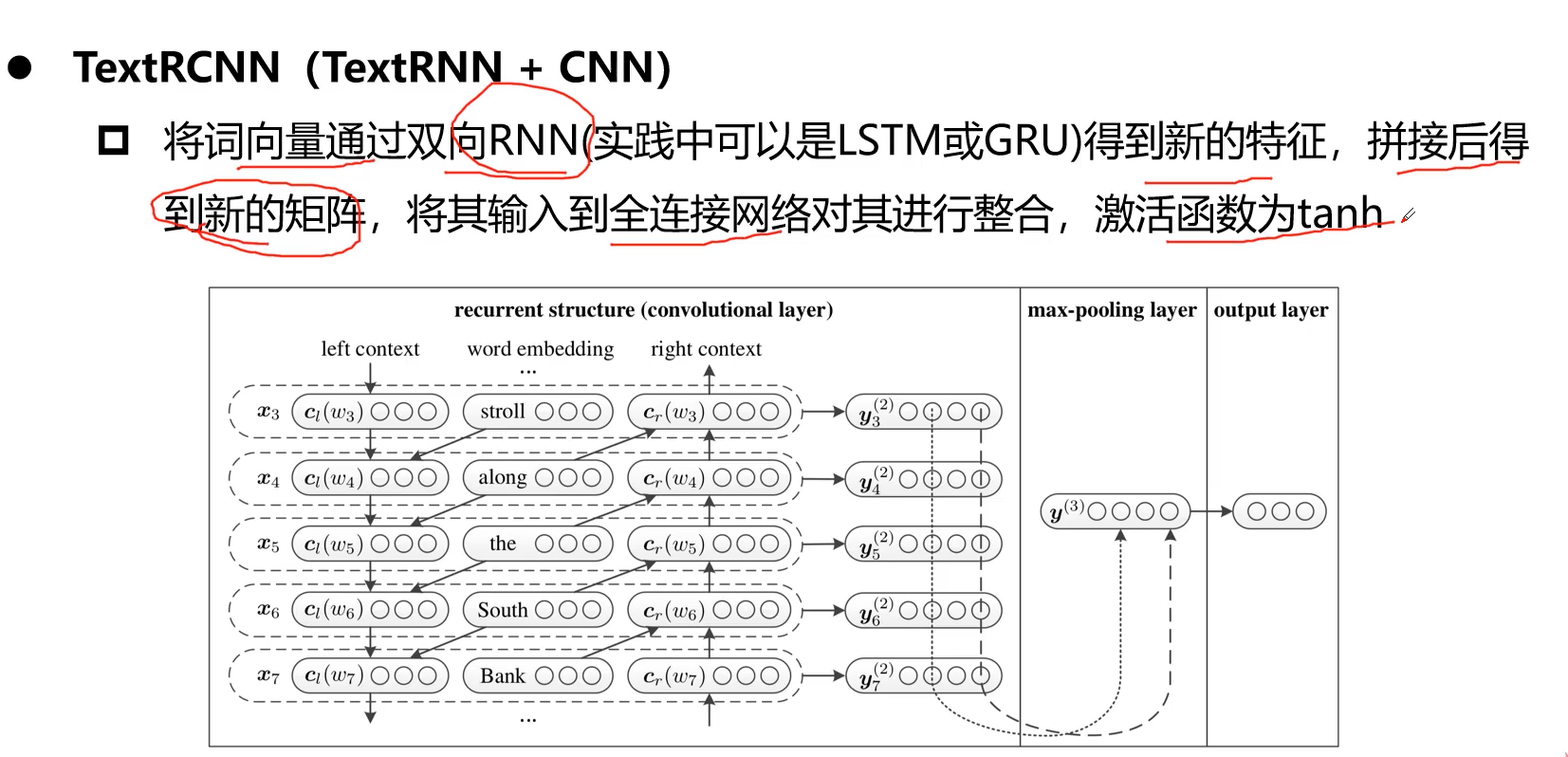
本文采用TextRCNN
















 614
614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









