






问题1:RuntimeError: CUDA error: device-side assert triggeced
先报了一堆这个
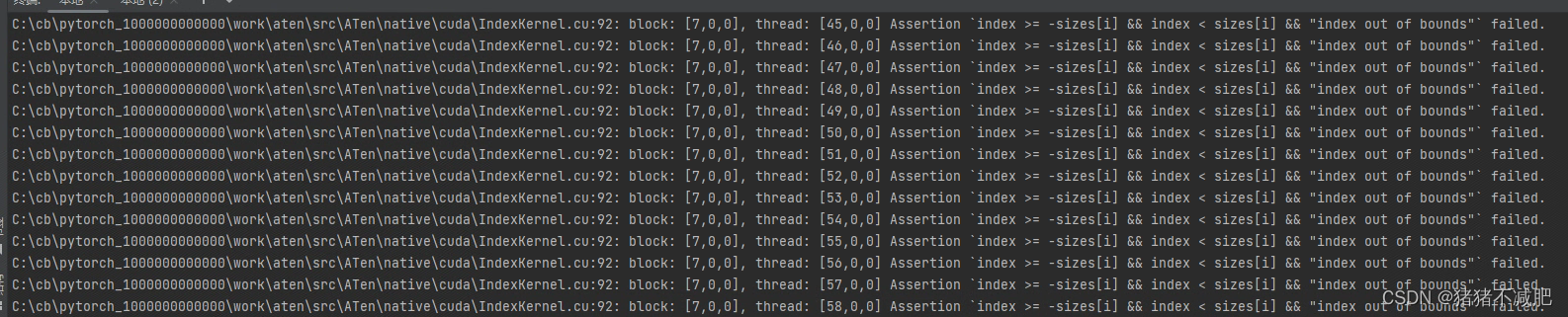
然后:

这里是因为训练的配置文件和实际标签里的类别数量不一致导致的。
我浅训练了5个周期,结果如下(随便加的几个类):
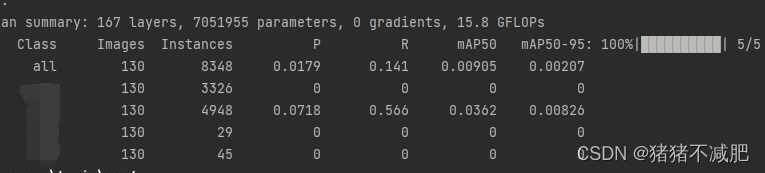
发现有4个类别。
但是我本来在配置文件中只给定了两个类别。
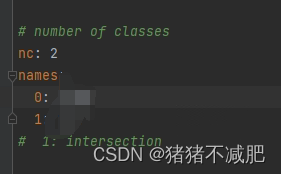
所以我用GPT写了脚本判断:
import os
def count_labels_and_find_invalid_files(folder_path, allowed_labels=[0, 1]):
labels_count = {}
invalid_files = {}
# 遍历文件夹中的每个文件
for filename in os.listdir(folder_path):
if filename.endswith(".txt"): # 假设标注文件的扩展名是.txt
filepath = os.path.join(folder_path, filename)
# 读取标注文件的内容
with open(filepath, 'r') as file:
lines = file.readlines()
# 遍历每行标注信息
for line in lines:
values = line.split()
if values:
label = int(values[0])
# 统计标签个数
labels_count[label] = labels_count.get(label, 0) + 1
# 检查是否有不允许的标签
if label not in allowed_labels:
if filename not in invalid_files:
invalid_files[filename] = []
invalid_files[filename].append(line.strip())
return labels_count, invalid_files
# 用法示例
folder_path = r'txt路径'
labels_count, invalid_files = count_labels_and_find_invalid_files(folder_path)
# 打印结果
print("类别个数:", len(labels_count))
print("每个类别的个数:", labels_count)
if invalid_files:
print("\n出现其他标签的文件:")
for filename, invalid_lines in invalid_files.items():
print(f"{filename}:")
for line in invalid_lines:
print(line)
else:
print("\n所有文件的标签都是合法的。")
这样能帮助找出错误的标签所在文件,我只有0,1标签,所以allowed_labels=[0, 1],如果你有多个标签可以自己改一下这个数组。
找到该文件后,使用以下脚本将标签改成自己想要的
import os
import re
# 路径
# 重写标签里的数字
path = r'D:\datasets\labels\val\\' #一定要有这两条杠在路径最后
# 文件列表
files = []
for file in os.listdir(path):
if file.endswith(".txt"):
files.append(path+file)
# 逐文件读取-修改-重写
for file in files:
with open(file, 'r') as f:
new_data = re.sub('^3', '1', f.read(), flags=re.MULTILINE) # 将列中的3替换为1
with open(file, 'w') as f:
f.write(new_data)
最后,重新训练,注意要把train.cache 和val.cache删除,我之前就是没删除然后一直报错。

重新训练会再生成的新的train.cache 和val.cache。















 326
326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









