









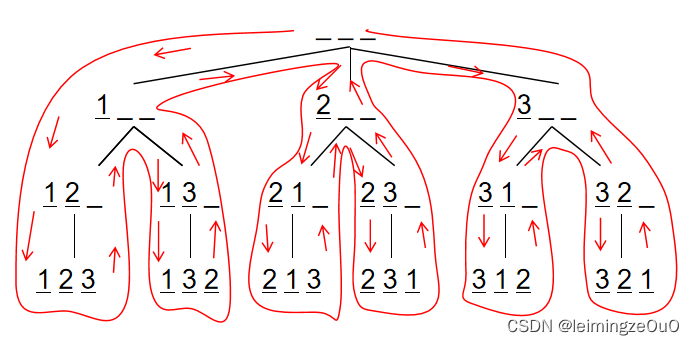
结论
组合是start,排列是0和st[]。
if(i!=x&&c[i]==c[i-1])continue;是防止同一个位置放两个相等的数字(树的同一层)
排列:-->st[]
[1,6]!=[6,1]。-->for(int i=0;i<n;i++)
不重复:同一个位置只能放一个相等的数字-->if(i&&c[i]==c[i-1]&&!st[i-1])continue
组合:
[1.6]==[6,1]--->for(int i=start;i<n;i++)
不重复:if(i!=start&&c[i]==c[i-1])continue;
46. 全排列
首先是最经典的全排列
class Solution {
public:
int n;
vector<vector<int>>res;
vector<bool>st;
vector<int>v;
void dfs(int u,vector<int>&nums)
{
if(u>=n)
{
res.push_back(v);
return;
}
for(int i=0;i<n;i++)
{
if(st[i])continue;
st[i]=true;
v.push_back(nums[i]);
dfs(u+1,nums);
st[i]=false;
v.pop_back();
}
}
vector<vector<int>> permute(vector<int>& nums) {
n=nums.size();
st.resize(n);
dfs(0,nums);
return res;
}
};
39. 组合总和

首先能看出来这个题是一个“完全背包问题”求具体方案,我们用暴力dfs来做。常规的dfs:
void dfs(int u)
这里的u枚举的是位置
但是这个题,如果我们u枚举枚举空位的话,没有办法按照题目的要求进行去重。
所以我们这里转换一个角度,u枚举数组中的每一个数字,然后枚举每一个数字的个数。
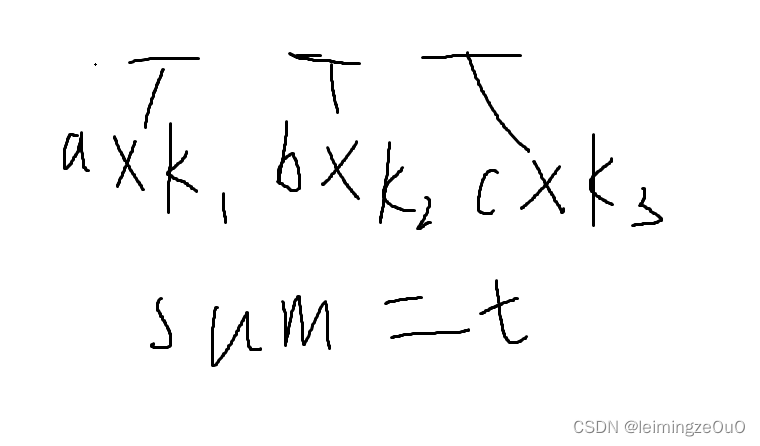
vector<vector<int>>res;
vector<int>v;
void dfs(int u,vector<int>&c,int target)
{
if(!target)
{
res.push_back(v);
return;
}
if(u==c.size())return;
for(int i=0;c[u]*i<=target;i++)//枚举每个数字可以选取的个数
{
for(int j=0;j<i;j++)v.push_back(c[u]);
dfs(u+1,c,target-c[u]*i);
for(int j=0;j<i;j++)v.pop_back();
}
}
40. 组合总和 II

题目要求:
- 每个数字在每个组合中只能使用一次
- 解集不能含有重复的组合
这里划重点了。不能有重复的组合,比如[6,1,1]和[1,1,6]不能同时存在,所以这里有第一个细节,枚举应该从以往的
for(int i=0;i<n;i++)
应当转为
for(int i=start;i<n;i++)
目的是为了防止选取前边的数造成重复
第二个细节:[1,1,6],sum=7,结果只能是[1,6],所以这里还有一个去重
if(i!=start&&c[i]==c[i-1])continue;
这一步是干什么呢?
其实这个题,和第一题不同点主要在于这个题枚举的是空位,如果出现同一个位置可以放相等数字的时候,应当把其删除。
当然前提条件是对其进行sort排序以便我们去重。
class Solution {
public:
vector<vector<int>>res;
vector<int>v;
void dfs(int start,vector<int>&c,int target)
{
if(target<0)return;
if(target==0)
{
res.push_back(v);
return;
}
for(int i=start;i<c.size();i++)
{
if(i!=start&&c[i]==c[i-1])continue;
v.push_back(c[i]);
dfs(i+1,c,target-c[i]);
v.pop_back();
}
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(),candidates.end());
dfs(0,candidates,target);
return res;
}
};
47. 全排列 II
不重复的全排列,[1,2]与[2,1]是不同的,所以这里不需要从start开始枚举,那么去重到底去的是什么呢?
if(st[i])continue;
if(i&&p[i]==p[i-1]&&!st[i-1])continue;
- 首先这里为什么要用判重数组?
因为他每次从i=0开始遍历,防止一个位置上的数字被重复使用。 - 为什么要加上
!st[i-1]?
当枚举到i是,身在同一树层的i-1的状态是被恢复成false,当前位置u其实已经被i-1的数字已经重复过了。
class Solution {
public:
int n;
vector<bool>st;
vector<int>v;
vector<vector<int>>res;
void dfs(int u,vector<int>&p)
{
if(v.size()==n)
{
res.push_back(v);
return;
}
for(int i=0;i<n;i++)
{
if(st[i])continue;
if(i&&p[i]==p[i-1]&&!st[i-1])continue;
st[i]=true;
v.push_back(p[i]);
dfs(u+1,p);
v.pop_back();
st[i]=false;
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
sort(nums.begin(),nums.end());
n=nums.size();
st.resize(nums.size());
dfs(0,nums);
return res;
}
};
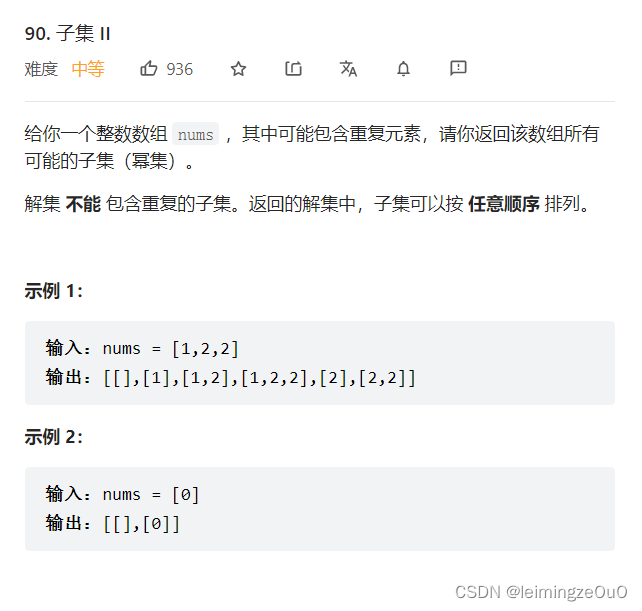
90. 子集 II
class Solution {
public:
vector<vector<int>>res;
vector<int>v;
void dfs(int start,vector<int>&c)
{
res.push_back(v);
for(int i=start;i<c.size();i++)
{
if(i>start&&c[i]==c[i-1])continue;
v.push_back(c[i]);
dfs(i+1,c);
v.pop_back();
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(),nums.end());
dfs(0,nums);
return res;
}
};
















 63
63











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











