







一、MapReduce输入和输出
MapReduce框架运转在<key, value>键值对上,也就是说,框架把作业的输入看成是一组<key, value>键值对,同样也产生一组<key, value>键值对作为作业的输出,这两组键值对可能是不同的。
(一)输入
默认读取数据的组件叫做TextInputFormat。关于输入路径︰
(1)如果指向的是一个文件,处理该文件;
(2)如果指向的是一个文件夹(目录),就处理该目录所有的文件,把所有文件当成整体来处理。输出结果仍然是一个文件
(二) 输出
默认输出数据的组件叫做TextOutputFormat。
(1)输出路径不能提前存在,必须是一个不存在的目录,否则执行报错,因为底层会对输出路径进行检测判断。
(2)可以在程序中编写代码(在最终输出之前)进行判断,如果输出路径存在,先删除,再提交执行。
//配置本次作业的输入数据路径和输出数据路径
Path inputPath = new Path(args[0]);
Path outputPath = new Path(args[1]);
//todo 默认组件 TextInputFormat TextOutputFormat
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job,outputPath);
//todo 判断输出路径是否已经存在,如果已经存在,先删除
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outputPath)){
fs.delete(outputPath,true); //递归删除
}
二、MapReduce流程梳理
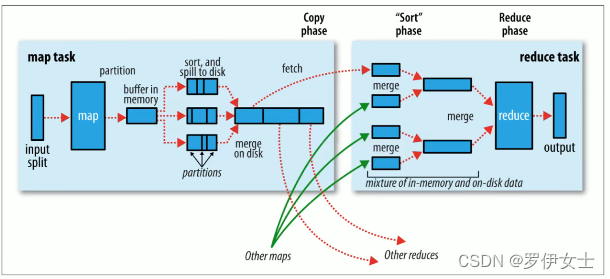
(一)Map阶段执行过程
(1)第一阶段∶把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认Split size = Block size,也就是有多少个数据块就会形成多少个切片,每一个切片由一个MapTask处理。( getSplits )
(2)第二阶段∶对切片中的数据按照一定的规则读取解析返回<key, value>对。默认是按行读取数据。key是每一行的起始位置偏移量,value是本行的文本内容。( TextInputFormat )
(3)第三阶段:调用Mapper类中的map方法处理数据。每读取解析出来的一个<key, value>,调用一次map方法。
(4)第四阶段︰按照一定的规则对Map输出的键值对进行分区partition。默认不分区,因为只有一个reducetask,。分区的数量就是reducetask运行的数量。
(5)第五阶段:︰Map输出数据写入内存缓冲区,达到比例溢出到磁盘上。溢出spill的时候根据key进行排序sort,默认根据key字典序排序。
(6)第六阶段︰对所有溢出文件进行最终的merge合并,成为一个文件。
(二)Reduce阶段执行过程
(1)第一阶段:ReduceTask会主动从MapTask复制拉取其输出的键值对。
(2)第二阶段︰把复制到Reducer本地数据,全部进行合并merge,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
(3)第三阶段是对排序后的键值对调用reduce方法。
键相等的键值对调用一次reduce方法。最后把这些输出的键值对写入到HDFS文件中。
三、MapReduce Partition分区
(一)MapReduce输出结果文件个数探究
1、默认情况下
不管map阶段有多少个并发执行task,到reduce阶段,所有的结果都将有一个task来处理;并且最终结果输出到一个文件中,part-r-00000。
2、改变ReduceTask个数
在MapReduce中,通过Job提供的方法,可以修改reducetask的个数。默认情况下不设置,reducetask个数为1。
//todo 修改reduceTask个数
job.setNumReduceTasks(3);
3、输出结果文件个数和reduceTask个数关系
通过修改不同reducetask个数值,得出输出结果文件的个数和reducetask个数是一种对等关系。也就是说有几个reducetask,最终程序就输出几个文件。
4、 引出数据分区
当MapReduce中有多个reducetask执行的时候,此时maptask的输出就会面临一个问题:
究竟将自己的输出数据交给哪一个reducetask来处理?这就是所谓的数据分区( partition )问题。
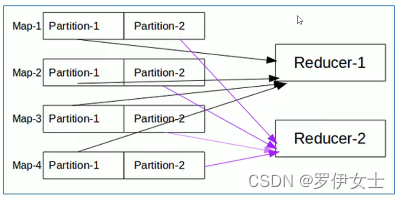
(二)Partition概念
默认情况下,MapReduce是只有一个reducetask来进行数据的处理。这就使得不管输入的数据量多大,最终的结果都是输出到一个文件中。
当改变reducetask个数的时候,作为maptask就会涉及到分区的问题,即:MapTask输出的结果如何分配给各个ReduceTask来处理。
(三)Partition默认规则
MapReduce默认分区规则是HashPartitioner。分区的结果和map输出的key有关。
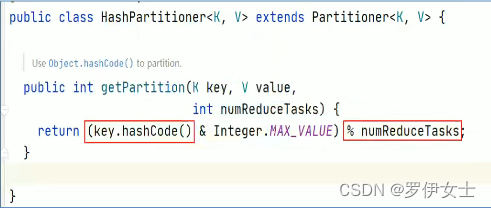
(四)Partition注意事项
1、reducetask个数的改变导致了数据分区的产生,而不是有数据分区导致了reducetask个数改变。
2、数据分区的核心是分区规则。即如何分配数据给各个reducetask。
3、默认的规则可以保证只要map阶段输出的key一样,数据就一定可以分区到同一个reducetask,但是不能保证数据平均分区。
4、reducetask个数的改变还会导致输出结果文件不再是一个整体,而是输出到多个文件中。
四、MapReduce Combiner规约
(一)数据规约的含义
数据归约是指在尽可能保持数据原貌的前提下,最大限度地精简数据量。
(二)MapReduce弊端
1、MapReduce是一种具有两个执行阶段的分布式计算程序,Map阶段和Reduce阶段之间会涉及到跨网络数据传递。·
2、每一个MapTask都可能会产生大量的本地输出,这就导致跨网络传输数据量变大,网络I0O性能低。
比如WordCount单词统计案例,假如文件中有1000个单词,其中999个为hello,这将产生999个<hello,1>的键值对在中传递,性能及其低下。
(三)Combiner组件概念
1、Combiner中文叫做数据规约,是MapReduce的一种优化手段。
2、Combiner的作用就是对map端的输出先做一次局部合并,以减少在map和reduce节点之间的数据传输量。
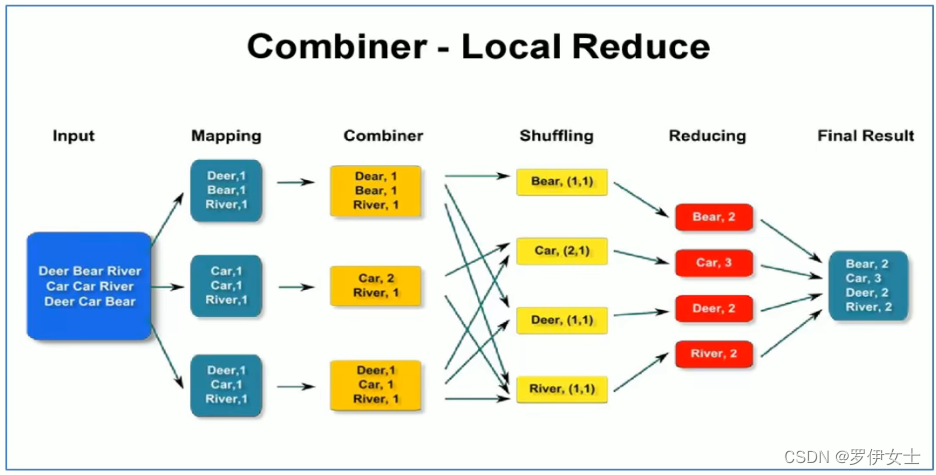
(四)Combiner组件使用
1、Combiner是MapReduce程序中除了Mapper和Reducer之外的一种组件,默认情况下不启用.
2、Combiner本质就是Reducer , combiner和reducer的区别在于运行的位置:
(1)combiner是在每一个maptask所在的节点本地运行,是局部聚合﹔
(2)reducer是对所有maptask的输出结果计算,是全局聚合。
3、具体实现步骤︰
自定义一个CustomCombiner类,继承Reducer,重写reduce方法job.setCombinerClass(CustomCoumbiner.class)
(五)Combiner使用注意事项
1、Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv应该跟reducer的输入kv类型要对应起来。
2、下述场景禁止使用Combiner,因为这样不仅优化了网络传输数据量,还改变了最终的执行结果
- 业务和数据个数相关的。
- 业务和整体排序相关的。
3、Combiner组件不是禁用,而是慎用。用的好提高程序性能,用不好,改变程序结果且不易发现。
局部进行单词统计与整体进行单词统计是一样的,也就是说进行单词统计的combiner与reducer的逻辑是一样的,所以可以直接引用reducer
//todo 设置MapReduce程序Combiner类,谨慎使用!
job.setCombinerClass(WordCountReducer.class);















 2628
2628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









