







存储过程在各类数据计算场景中都非常的常见,因为单一的SQL在一些复杂的计算情况下能力不足,有了存储过程的补充和配合,才可以应付各类计算需求
报表中为什么会有存储过程
报表天天和数据计算打交道,自然在一些情况下就会用到存储过程
报表的制作和呈现,需要针对一个或者多个数据来源,这些数据源,准备起来有的简单,有的复杂,简单的,一句或几句SQL就可以把数据准备好,给到报表来用,复杂的,SQL做不好的,比如涉及多步过程控制的计算,很多就得用存储过程来做了,有的还得用JAVA等高级语言去写才行,但这个不在这里展开讨论了,感兴趣的可以看这篇帖子:报表中总是得写 java 程序怎么办
报表中为什么要减存储过程
存储过程在SQL解决不了的各种复杂计算场景下,有很多的优势,为什么报表中还想着减少使用呢?
因为它的弊端同样很多
耦合性高
存储过程是为报表准备数据,为报表服务的,理论上它应该和报表模板一起独立在外,不影响应用也不影响数据库才对,但实际上它却存在数据库中与数据库紧密耦合,给修改和后续维护带来了很大的困难
而且数据库中的存储过程,有时候会被有相同业务需求的报表或其他应用拿来直接用,被迫共享,共享原本也是一件好事,能节省开发成本,但却也带来了另外的耦合,和其他报表或者应用的耦合,这时候如果其中的某个报表的计算逻辑发生变化,就只能新建而不敢随便修改,否则就会影响其他报表和应用
时间一长,库里的存储过程越来越多,哪个对应那个报表对应什么应用,就成了一团麻了
把数据库本身的管理都影响了
移植困难
存储过程 缺乏 ANSI 2003 那样的统一规范,各数据库厂商的语法基本都不通用,很难在不同数据库间移植,遇到数据源迁移,或者开发商面对不同用户的不同数据库时,,就会面临一个尴尬的问题,报表模板用同一个就可以,但提供数据的存储过程却得重新开发,各用各的,移植不了,还容易导致版本混乱,成本徒增
体系封闭
存储过程只能计算数据库内的数据,无法满足多样性数据源的需求,如果要计算外部的数据,需要先 ETL 到库内完成,不仅浪费时间,也无法保证数据实时性,同时占用非常宝贵的数据库空间
然而,现在的数据来源又恰恰是多种多样的,这点很致命
安全性差
报表原则上只是读数据就行了,开放读权限足够了,但为了写存储过程就要给编译权限,这个太高了,改数删表都有可能,安全性得不到保障,要么就是加强管理,代码上传时要被严格审核,但这样又影响效率,本来报表开发人员一个人能做的事,要一个体系才行,半天能做完的报表,审核一下又不知多久才能上线了
代码难写
存储过程主要在 SQL 的基础上追加了逻辑控制语法,但并没有增强 SQL 的结构化计算能力,这就导致原来用 SQL 难写的代码,现在用存储过程依旧难写,比如有序计算、分组后计算、多级关联、混合计算等
这些弊端的存在,就是开发人员们想减少使用存储过程的原因,只是迫于没有更好的办法,大家只能忍耐了,只能尽量去少用了
怎么解决
有没有什么办法,既可以利用存储过程的优势,又可以规避它的缺点呢
原先没有,现在有了,集成了集算器SPL的润乾报表具备了这样的能力
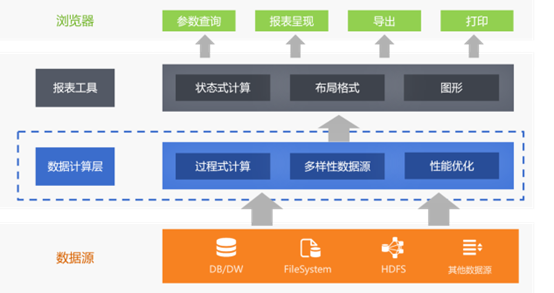
SPL 是一款流行的专业的数据计算处理工具,很多项目开发商都在用,因为它不仅好用,而且还免费,开源,是常年做项目,总需要做数据处理的工程师的好帮手
集成 SPL 后,润乾报表相当于多了一个计算层,这个计算层类似一个“库外的存储过程”,它既可以做到存储过程能做的,还规避了各种弊端,更适合处理各类复杂计算
避免耦合
SPL 作为润乾报表的计算层,它编写的计算脚本是直接存放到报表模板里面解释执行的,不需要单独管理,更不需要放到数据库中,避免了与数据库的耦合问题
随便移植
计算层的脚本本身就具有计算能力,而且是在库外独立运算的,数据源有不同或者要迁移的时候,只需要重新连一下新数据源就可以,不需要改动其中的计算逻辑部分,一个脚本可以应对不同的来源,能做到随便移植
体系开放
SPL计算层支持各类数据源,而且可以在库外进行各类混合计算,体系是开放的,能更好的应对多样性数据源的场景

短短5行代码就可以做到JSON和数据库内数据的混算,远比存储过程要方便快捷的多
| A | ||
|---|---|---|
| 1 | =json(file(“/data/EO.json”).read()) | JSON数据 |
| 2 | =A1.conj(Orders) | |
| 3 | =A2.select(Amount>1000 &&Amount<=3000 && like@c(Client,“s”)) | 条件过滤 |
| 4 | =db.query@x(“select ID,Name,Area from Client”) | 数据库数据 |
| 5 | =join(A3:o,Client;A4:c,ID) | 关联计算 |
安全方便
SPL计算层连接数据源所需要的权限和普通的SQL连接是一样的,不需要更高的存储过程的编译权限,这就不会带来额外的安全问题,也不需要专人审核代码,安全又方便
代码简单
SPL是一种全新的计算体系,有更高效的函数和算法,在SQL里难写的计算,可以在SPL中轻松写出,同样的,存储过程中难写的,SPL也可以轻松写出
比如这个小例:报表中需要呈现连续上涨超过 3 天的股票
这样的报表,制表时候只需要设计几个格子,很简单,但数据准备却不简单,大部分的工作量都得花在这个数据的准备上
用 SQL 来算的话,得写好几层嵌套
SELECT code, MAX(ContinuousDays)
FROM (
SELECT code, NoRisingDays, COUNT(*) ContinuousDays
FROM (
SELECT code,
SUM(RisingFlag) OVER (PARTITION BY code ORDER BY day) NoRisingDays
FROM (
SELECT code, day,
CASE WHEN price>
LAG(price) OVER (PARTITION BY code ORDER BY day)
THEN 0 ELSE 1 END RisingFlag
FROM tbl
)
) GROUP BY NoRisingDays
)
GROUP BY code
HAVING MAX(ContinuousDays)>=3
放到存储过程中,也得这么写,难度不会降低
而用润乾计算层的 SPL,则短短两行就可以搞定,而且逻辑也更清晰易懂
| A | |
|---|---|
| 1 | =mysqlDB.query@x("select * from tbl ") |
| 2 | =A1.sort(day).group(code).select( ~.group@o(price>price\ [-1]).max( ~.len())>3).(code) |
(注释:导入股市数据表,并按日期排序。使用函数 group 的选项 @o,根据股价是否上涨进行分组。分组时只和相邻的对比,当股价是否上涨发生变化时产生新组。计算出每支股票连续上涨的最大天数,最后选出连续上涨超过 3 天的)
总结
存储过程有它的优势所在,但存在的弊端也很明显,放到报表应用中,有些还会被成倍放大到不可忍受,但技术总在进步,润乾报表的SPL计算层,就是存储过程很好的替代技术,它类似“库外存储过程”,有着比存储过程更好的过程控制等复杂计算的能力,还没有它身上的坏毛病,润乾报表本身又是报表行业的头部厂商,专注报表20多年,累积用户数不胜数,价格又很亲民,1W一套,3W一年随便用,有了润乾报表,这些存储过程带来的困扰就都迎刃而解了
润乾报表资料
欢迎对润乾报表有兴趣的加小助手(VX号:RUNQIAN_RAQSOFT),进技术交流群















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











