






学习c++的同时也就顺便更新一下,之前学过的python的知识点吧
一、基础知识
1、注释
注释分为单行注释和多行注释
单行注释以 # 开头
# 后面为注释
多行注释为(’’’ ‘’’)或者(""" “”")中间包含的内容
"""
此处为注释
"""
'''
此处为注释
'''
pycharm中添加注释的快捷键(Ctrl+/)
2、变量的定义和使用
语法:
变量名=数据值
变量名不能和Python中已有的关键词相同
3、数据类型
(1)数字类型
int(有符号整型)、long(长整形)、float(浮点型)、complex(复数)
(2)布尔类型
True 真 、False 假
(3)字符串
String
(4)容器类型
List(列表)、Tuple(元组)、Dictionary(字典)
使用 type() 函数可以得到变量的数据类型
4、标识符和关键字
标识符命名规则:有字母、数字和下划线组成,不能以数字开头
查看系统关键字:
import keyword # 导包, keyword是系统中已经定义好的内容,想要使用就需要导入
print(keyword.kwlist)
5、输出
在 Python 中使用 print() 函数进行输出
print("hello")
print(123)
print('hello world',18) #可同时输出两个内容,中间之间以空格隔开
print(1+2)
#格式化输出
name="world"
print("你是%s" % name) # %d int %s 字符串 %f 小数浮点数float
其他的输出规范
# %.nf 输出时保留n位小数,不写时默认保留6位
a=3.14159226
e= 2.718281828459
print(“π的值为%.6f,e的值为%.6f” % (a, e) #格式化输出多个数字
#使用格式化输出时,想输出一个%,需要使用两个%%
print("及格人数占%% %d", % 50)
python还支持f-string,占位同一使用{}占位,填充的数据写在{}里面
print(f"π的值为{a},e的值为{e}")
注意:print()函数输出之后会默认添加一个换行,不需要可以去掉
print("hello world", end=" ") #最后输出时添加 end=" " 可去掉换行
6、输入
在python 中使用的 是input()函数
语法input("提示信息")
以上可得到输入的内容,遇到回车代表结束,得到的数据都是字符串类型
7、数据类型转换
a=1233456789
print(type(a))
print(float(a))
print(type(a))
python中新添加一种函数 eval() 作用是还原原来的数据类型,去掉字符串的引号
8、运算符
(1)算术运算符+、-、*、/、//(整除,求商)、%(取余数)、**(指数,幂运算)、()(可以改变优先级)
(2)赋值运算符=
(3)比较运算符==、!=、>、<、>=、<=
(4)逻辑运算符(and、or 、not)(与c++相同)
9、PEP8规范
(1)单行注释#后面应该有一个空格
(2)代码文件最后一行是空行
(3)行内注释需要两个空格
二、流程控制语句
1、条件语句
(1)if语句:
语法:
if 判断条件:
判断条件为真,执行的代码
...
注意:在python中用缩进来代替代码的层级关系,if 语句的缩进内属于 if 的执行代码
score=int(input("输入你的成绩"))
if (score>90):
print("成绩优秀")
(2)if…else…语句:
语法:
if 判断条件:
判断条件为真,执行的代码
else:
判断条件为假执行的代码
score=int(input("输入你的成绩"))
if (score>90):
print("成绩优秀")
else:
print("成绩合格")
(3)if…elif…语句:
语法:
if 判断条件1:
判断条件1成立执行的代码
elif 判断条件2:
条件1不成立,而条件2成立执行的代码
else:
所有条件都不成立,执行的代码
score=int(input("输入你的成绩"))
if (score>90):
print("成绩优秀")
elif(score>80):
print("成绩良好")
elif(score>60):
print("成绩及格")
else:
print("成绩不及格")
(4)if嵌套:
语法:
if 判断条件1:
if 判断条件2:
条件1成立且条件2成立执行的代码
else
条件1成立而条件2不成立执行的代码
else
条件1不成立执行的代码
score=int(input("输入你的成绩"))
if (score >= 0) and (score <= 100):
if score>90:
print("优秀")
else:
print("成绩合格")
else:
print("成绩输入有误")
注:
import random # 导⼊随机数模块
#产⽣ [a, b] 之间的随机整数,包含 a 和 b
num = random.randint(a, b)
(5)三目运算:
语法:
变量 = 表达式1 if 判断条件 else 表达式2
2、循环语句
(1)while语句:
语法:
while 判断条件:
判断条件成⽴,执⾏的代码
判断条件成⽴,执⾏的代码
#不在 while 的缩进内,代表和循环没有关系
while 和 if 的区别:
if 的代码块,条件成⽴,只会执⾏⼀次;while 的代码块,只要条件成⽴,就会⼀直执⾏
i = 0
while i<5:
print("hello")
i+=1
(2)while循环嵌套:
语法:
while 判断条件1:
代码1
while 判断条件2:
代码2
(3)for循环遍历:
语法:
for 变量 in 字符串:
代码
for i in range(5,9): #range产生左标到右标的数字,不包含右标
print(i)
(4)break和continue语句:
1、break 和 continue 是 python 两个关键字
2、 break 和 continue 只能⽤在循环中
3. break 是终⽌循环的执⾏, 即循环代码遇到 break,就不再循环了
4、continue 是结束本次循环,继续下⼀次循环, 即本次循环剩下的代码不再执⾏,但会进⾏下⼀次循环
(5)循环else语句:
语法:
for x in xx:
if xxx:
xx # if 判断条件成⽴会执⾏
else:
xxx # if 判断条件不成⽴,会执⾏
else:
xxx # for 循环代码运⾏结束,但是不是被 break终⽌的时候会执⾏
三、容器
1、字符串
定义:带引号的内容就是字符串
python 中,字符串可以乘上⼀个整数,
字符串 * num
示例
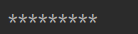
a="***"
print(a*3)
(1)下标:
下标也称为索引,是一个整形数字,可为正数,也可为负数
正数下标从0开始,负数下标从-1开始
示例:
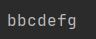
a="abcdefg"
print(a[0])
print(a[2])
print(a[-1])

(2)切片:
语法:
变量[start:end:step] #得到一个新的字符串
#start代表开始位置的下标
#end 代表结束位置的下标,不包含end对应的下标
#step 代表步长,下表之间的间隔,默认为1,也可为负数
a="abcdefg"
print(a[1:3])
print(a[3:6])
print(a[::-1])

(3)查找方法:
find() 或 rfind()
find()在字符串中查找是否存在某个字符串
语法:
#a.find(a,start,end)
#start 开始查找的位置,默认为0
#end 结束查找的位置,默认为len(a)
#如果找到所找的字符,则返回值为该字符所处的正数下标,没有找到返回值为-1
a="abcdefg"
print(a.find("c",0,len(a)))

注: rfind() 表示查找时从右边开始,rindex()也一样
index() 或 rindex():
index() 在字符串中查找是否存在某个字符串
语法:
#a.find(a,start,end)
#start 开始查找的位置,默认为0
#end 结束查找的位置,默认为len(a)
#如果找到所找的字符,则返回值为该字符所处的正数下标,没有找到则会报错
count():
语法:
a.cout(a,start,end)
#统计某字符出现的次数
(4)字符串替换方法replace:
语法:
a.replace(old,new,count) #字符串的替换,old换成new,count为替换的次数,默认是全部替换
a="abcdefg"
print(a.replace("a","b",1))
(5)字符串分割split():
语法:
a.split(b,count)
#将a字符按照b字符进行切割
#b字符默认为空白字符,空格,tab键
#count 切割次数,默认全部切割
#返回值:列表[]
a="a b cd ef g"
print(a.split())

(6)字符串连接join():
语法:
a.join(可迭代对象)
# 可迭代对象:字符串,列表(列表中每个数据都是字符串类型)
# 将a这个字符串添加到可迭代对象的两个元素之间
# 返回值为一个新的字符串
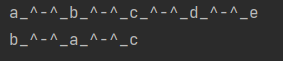
a="_^-^_"
b="abcde"
print(a.join(b))
c=["a","b","c"]
print(a.join(c))
2、列表
(1)列表的定义和使用
列表是python中的一种数据类型,可以存放多个数据,且无类型限制
定义方式:列表名=[数据]
# 定义空列表
list=[]
print(type(list))
#定义列表中的数据,以逗号隔开,列表中元素的个数,即列表的长度
list1=[1,2,True,4,"a"]
# 列表支持下标和切片操作
print(list1[1:3])
print(list1[::-1])
#列表与字符串不同,可以通过下标修改其中的数据,而字符串不行
list[1]=666
print(list)
(2)列表的遍历
list=['a','b','c','d','e']
#for遍历
for i in list:
print(i)
#while遍历
k=0
while k<len(list)
print(list[k])
k += 1
(3)向列表中添加数据
向列表添加数据的方法,都是直接对原列表进行操作,不会产生新列表
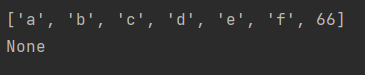
list=['a','b','c','d','e','f']
# 方法一:列表.append(数据)向列表尾部追加数据
list.append(66)
print(list)
list1=list.append('66') #append法不会产生新列表,直接操作原列表,故list1为空
print(list1)
# 方法二:列表.insert(下标,数据),在指定下标添加数据,其他数据后移
list=['a','b','c','d','e','f']
list.insert(0,'abcdef')
print(list)
#错误示例
#list=['a','b','c','d','e','f']
#print(list.insert(0,'abcdef'))
# 输出结果为None

#方法三:列表.extend(可迭代对象)
# 可迭代对象,字符串,列表,将迭代对象中的数据逐个添加到原列表的末尾
list=['a','b','c','d','e','f']
list.extend('hello')
print(list)
list.extend([1,2,3])
print(list)

(4)列表中的数据查询
跟字符串不同,列表中只有 index() 方法,无 find() 方法
# index()法:
list=['a','b','c','d','e','f']
num = list.index("a")
print(num)
# count()法 统计某个数据出现的次数
num1=list.count("a")
print(num1)
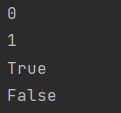
# in / not in 判断某个数据是否存在,存在为True,不存在为False
num2 = 'a' in list
print(num2)
num3 = 'h' in list
print(num3)
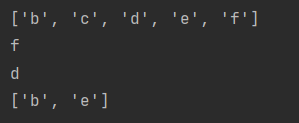
(5)列表中的删除操作
# 方法1:根据元素的数据值删除
#remove(数据值),直接在原列表中操作
list = ['a', 'b', 'c', 'd', 'e', 'f']
list.remove('a')
print(list)
# 方法2:根据下标删除
# pop(下标),默认删除最后一个数据,返回值删除的内容
print(list.pop())
print(list.pop(2))
# del 列表[下标]
del list[1]
print(list)
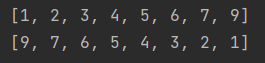
(6)列表排序和逆置
首先要对列表中的数据进行排序,列表中的数据类型必须一致
# 方法1:列表.sort() 直接在原列表进行排序,默认是从小到大,升序排列
# 列表.sort(reverse=True) reverse=True 从大到小排列,True换为False则相反
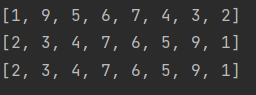
list = [1, 9, 5, 6, 7, 4, 3, 2]
list.sort()
print(list)
list.sort(reverse=True)
print(list)
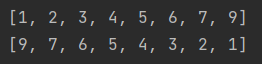
# 方法2:sorted(列表) 排序,会产生一个新的列表
list = [1, 9, 5, 6, 7, 4, 3, 2]
list1 = sorted(list)
print(list1)
list2 = sorted(list, reverse=True)
print(list2)
# 逆置
list = [1, 9, 5, 6, 7, 4, 3, 2]
list1 = list[::-1]
print(list)
print(list1)
list.reverse()
print(list)
(7)二维列表
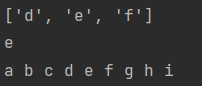
character = [['a', 'b', 'c'], ['d', 'e', 'f'], ['g', 'h', 'i']]
print(character[1])
print(character[1][1])
for i in character:
for k in i:
print(k, end=" ")
3、元组
元组与列表非常相似,都可以存放多个数据,无类型限制
不同的是,列表用 [ ] 定义,元组用 ( ) 定义,并且列表中的数据可以修改,元组不可以修改
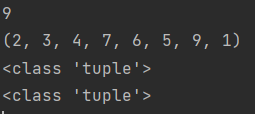
tuple1 = (1, 9, 5, 6, 7, 4, 3, 2)
# 元组支持下标和切片操作
print(tuple1[1])
print(tuple1[::-1])
# 定义空元组
tuple2 = ()
print(type(tuple2))
# 定义一个元素的元组,数据元素后必须有一个逗号
tuple3 = (1,)
print(type(tuple3))
4、字典
(1)字典的定义和访问
字典(dict)用 {} 定义,是由键值对 {key:value}组成
语法:
# 变量 = {key1: value1, key1: value1, ...} 一个键值对是一个元素,字典的长度即键值对的个数
# 字典的key可以是字符串和数字类型(int ,float) 不能是列表
# value可以是任何类型
# 1、定义空类型
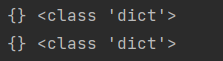
dict1 = {}
dict2 = dict()
print(dict1, type(dict1))
print(dict2, type(dict2))
# 2、定义带数据字典
dict1 = {'name': '小明', 'age': 18, 'hobby': ['饥荒', '空洞', 'ori']}
print(dict1)
# 3、在字典中无下标,可通过key访问value
print(dict1['hobby'])
print(dict1['hobby'][1])

# 4、如果key不存在
dict1 = {'name': '小明', 'age': 18, 'hobby': ['饥荒', '空洞', 'ori']}
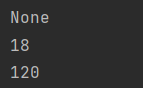
#print(dict1['weight']) #代码报错,key不存在
# 字典.get(key) 如果key不存在,不报错返回值为None
print(dict1.get('weight'))
# dict1.get(key, 数据值) 如果key存在,则返回key对应的value值,否则返回书写的数据值
print(dict1.get('age', 1))
print(dict1.get('weight', 120))
(2)向字典中添加和修改数据
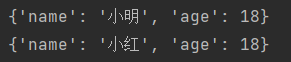
dict1 = {'name': '小明'}
# 字典中添加和修改数据,通过key值进行操作
# 字典[key] = 数据值; 如果key值存在,为修改; 不存在,则为添加
dict1['age'] = 18;
print(dict1)
dict1['name'] = '小红'
print(dict1)
(3)字典中删除数据
dict1 = {'name': '小明', 'age': 18, 'hobby': ['饥荒', '空洞', 'ori']}
# 根据key值删除数据 del 字典名[key]
del dict1['name']
print(dict1)
# 字典.pop(key) 根据key删除,返回值是删除的key对应的value值
print(dict1.pop('age'))
# 字典.clear() 清空字典,删除所有的键对值
dict1.clear()
print(dict1)
# del 字典名 直接将这个字典删除,无法再次使用
del dict1

(4)字典中遍历数据
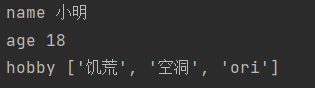
方法一:
for循环直接遍历,遍历的是字典的key值
dict1 = {'name': '小明', 'age': 18, 'hobby': ['饥荒', '空洞', 'ori']}
for key in dict1:
print(key,dict1[key])
方法二:
字典.keys() 可以获取字典中所有的key值,得到的类型是dict_keys,该类型具有以下特点:
可以使用 list() 将其转换为列表类型,也可使用for循环进行遍历
dict1 = {'name': '小明', 'age': 18, 'hobby': ['饥荒', '空洞', 'ori']}
a=dict1.keys()
print(a,type(a))
for key in a:
print(key)

方法三:
字典.values() 可以获取所有的value值,类型为dict_values
可以使用 list() 将其转换为列表类型,也可使用for循环进行遍历
dict1 = {'name': '小明', 'age': 18, 'hobby': ['饥荒', '空洞', 'ori']}
a = dict1.values()
print(a,type(a))
for value in a:
print(value)

方法四:
字典.items() 可以获取所有的键对值,类型是dict_items,key,value组成元组类型
可以使用 list() 将其转换为列表类型,也可使用for循环进行遍历
dict1 = {'name': '小明', 'age': 18, 'hobby': ['饥荒', '空洞', 'ori']}
a = dict1.items()
print(a,type(a))
for item in a:
print(item[0],item[1])
for i,j in a:
print(i,j)

5、enumerate()函数
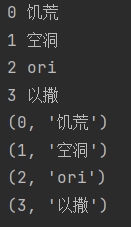
这个函数可以将可迭代序列中元素所在的下标和具体元素数据组合在一起,变成元组
list1 = ['饥荒', '空洞', 'ori','以撒']
for i in list1:
print(list1.index(i),i)
for j in enumerate(list1):
print(j)
6、公共方法
(1) + 支持字符串、列表、元组操作,得到新的容器
(2) * 复制字符串、列表、元组进行操作,得到新的容器
(3) in/not in 判断存在或不存在,支持字符串、列表、元组、字典操作,注意,若为字典判断的是key是否存在
(4)max/min 对于字典来说,比较的是字典key值的大小
四、函数
1、函数的调用
函数,是能够实现一个具体的功能,是多行代码的整合
函数的定义:
# def 函数名(): #函数名要遵循标识符的规则,见名知意
# 函数代码
函数定义,函数中的代码不会执行,只有在函数调用的时候,才执行
使用函数,可以减少重复代码的书写
def func():
print("开始执行")
print("执行结束")
func()
注意python PEP8规则中有函数要与其他代码保持两行间距的规定
2、函数的文档说明
函数的文档说明本质上就是注释,标注该函数的功能及用法
文档说明有特定的位置
查看函数的文档注释可以使用 :
help(函数名)
help(print)
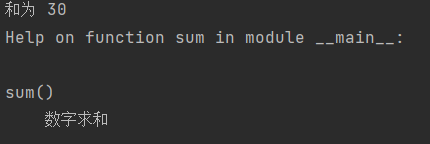
def sum():
"""
数字求和
"""
a = 10
b = 20
c = a + b
print("和为", c)
sum()
help(sum)
3、书写带参数的函数
可以使代码的使用范围更广
def sum(a, b): # 函数定义时,其中a和b被称作形式参数,简称形参
c = a+b
print("和为", c)
sum(1, 2) # 函数调用时,1和2被称为实参,会将实参传给形参
# 两种参数的个数需要一一对应
4、局部变量
局部变量的作用域为被定义函数的内部,在函数调用的时候创建,调用结束后呗销毁,局部变量只能在定义函数内部使用,无法在函数外部使用
def sum():
a = 10
b = 20
c = a+b
print("和为", c)
sum()
# print(a, b) # 报错a,b无定义
5、全局变量
全局变量就是在函数外部定义的变量,在函数内部也可以访问,但如果要进行修改,需要使用关键字 global 声明
# 调用
num = 1
def fun():
print(num)
fun()
# 修改
# 错误做法
num = 1
def fun():
num = 2 # 没有进行修改,仅仅是创建了一个相同名字的局部变量
print(num)
fun()
print(num)
# 正确做法
num = 1
def fun():
global num
num = 2
fun()
print(num)
6、返回值
在函数内部定义的局部变量,或通过计算得出的局部变量,想要在函数外部使用,就需要用到 return 关键字,进行返回
其中 return 必须用在函数中
用法:将return 后边的数据进行返回,程序代码遇到return,会终止执行
def sum(a, b):
c = a+b
return c
print(sum(1, 2))
7、return返回多个数据值
由于代码遇到一个return后会停止执行,有时需要多个返回值
解决办法:
def func(a, b):
c = a+b
d = a-b
# 容器可以存放多个数据,将c和d放到容器中进行返回
# return [c, d]
# return (c,d)
# return {0: c, 1: d}
return c, d # 默认是组成元组进行返回的
result = func(1, 2)
print(result[0], result[1])
#return 关键字后边可以不写数据值, 默认返回 None
def func():
xxx
return # 返回 None,终⽌函数的运⾏的
#函数可以不写 return,返回值默认是 None
def func():
xxx
pass
8、函数的嵌套调用
在一个函数里可以调用另一个函数
def func1():
print("func1正在执行")
print('func1执行结束')
def func2():
print("func2正在执行")
func1()
print('func2执行结束')
func2()
9、函数传参的两种形式
函数传参有两种形式:位置传递和关键词传递
# 位置传递,按照形参的位置顺序把实参的值传递给形参
def func(a, b, c):
print("a=", a)
print("b=", b)
print("c=", c)
func(1, 2, 3)

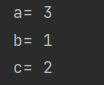
# 关键词传递,指定实参给哪个形参
def func(a, b, c):
print("a=", a)
print("b=", b)
print("c=", c)
func(b=1, c=2, a=3)
# 混合使用,先写位置传参,再写关键词传参
def func(a, b, c):
print("a=", a)
print("b=", b)
print("c=", c)
func(2, 1, c=3)
10、函数形参
(1)缺省参数(默认参数)
缺省参数,形参,在函数定义时,给形参一个默认值,这个参数就是缺省参数,在函数调用时,如果没有给缺省参数传递实参,这个缺省参数的值就为所设定的值
注:缺省参数要写在普通参数后面
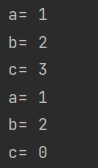
def func(a, b, c=0):
print("a=", a)
print("b=", b)
print("c=", c)
func(1, 2, 3)
func(1, 2)
(2)不定长参数
[1]在形参前加上一个*,该形参变为不定长元组形参,可以接受所有的位置形参,类型为元组
[2]在形参前加上两个**,该形参变为不定长字典形参,可以接受所有的关键词形参,类型为字典
# 普通形参
def func(a, b):
print("a=", a)
print("b=", b)
func(1, 2)
func(a=2, b=1)
# 不定长参数
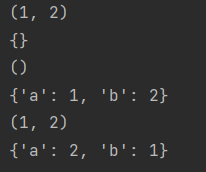
def func(*a, **b):
print(a)
print(b)
func(1, 2)
func(a=1, b=2)
func(1, 2, a=2, b=1)
(3)函数形参的完整格式
参数的顺序:
普通参数 不定长元组参数 缺省参数 不定长字典参数
def func(a, b=1): # 先普通,后缺省
pass
def func1(a, b=1, *c): # 语法上不报错,但缺省参数不能使用默认值
print('a', a)
print('b', b)
print(a)
def func2(a, *c, b=1): # 普通参数 不定长元组形参 缺省参数
print('a', a)
print('b', b)
print(a)
def func3(a, *c, b=1, **d): # 普通参数 不定长元组形参 缺省参数 不定长字典形参
print(a)
print(c)
print(b)
print(d)
func3(1, 2, 3, 4, e=10)

11、拆包
首先,认识组包,即将多个数据,组成元组,赋值给另一个变量
拆包:将容器的数据分别给到多个变量,注意变量的个数要与数据的个数相同
a = 1, 2, 3 # 组包
print(a)
def func():
return 1, 2
b, c, d = a # 拆包
print(b, c, d)
e, f = func()
print(e, f)
list1 = [10, 20]
a, b = list1
print(a, b)
dict1 = {'name': 'ori', 'age': 18}
a, b = dict1
print(a, b)
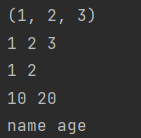
# 交换两个数的值也可用到python的拆包和组包
a = 1
b = 2
a, b = b, a
print(a, b)

12、引用
这部分内容更起来较麻烦,说明白比较麻烦,就不更了
五、文件操作
首先文件操作的相关步骤和 c++ 一样
1、打开文件
2、读写文件
3、关闭文件
1、读文件-r
# 格式:
# 1、打开文件
# open(file, mode = 'r', encoding)
# file 文件名,类型是str
# mode,文件的打开方式r(read)只读方式,w(write)只写打开,a(append)追加打开
# encoding 文件的编码格式, 常接触的有编码格式GBK和utf-8
# 返回值为文件对象,后续所有的操作需要通过这个对象进行
f = open('1.txt', 'r') # 文件需要存在,不存在会报错
re = f.read() # 读文件 文件.read()
print(re)
f.close() # 关闭文件 文件.close()
2、写文件-w
open函数打开文件,window系统,不指定文件的编码方式,默认为gbk,在用 write写入的时候,需要使用相同的编码方式写入,但是使用pycharm打开文件,默认使用 utf-8 编码
f = open('1.txt', 'w', encoding='utf-8') # 使用w方式打开文件,文件不存在会创建文件;存在,则会覆盖清空原文件
f.write('你好世界')
f.close()
3、追加文件-a
# 使用a方式打开文件,会把指针放在文件末尾,在末尾写入数据
# 文件不存在同样会创建文件
# 与w方式相同,写入文件都用write()
f = open('1.txt', 'a', encoding='utf-8')
f.write('你好世界\n')
f.close()
4、文件读操作
(1)read
f = open('1.txt', 'r', encoding='utf-8')
re = f.read() # 读写文件 文件对象.read(n) n一次读取多少字节的内容,默认不写,读取全部内容
f.close()
(2)按行读取
f = open('1.txt', 'r', encoding='utf-8')
re = f.readline() # 一次读取一行的内容,返回值是读取到的内容
print(re)
rea = f.readlines() # 按行读取,一次读取所有行,返回值是列表,列表中的每一项是一个字符串,即一行的内容
print(rea)
f.close()
(3)模拟读取大文件
f = open('1.txt', 'r', encoding='utf-8')
while True:
re = f.read(4)
if re:
print(re, end=' ')
else:
break
f.close()
注意: read 读取时会将 换行 作为一个字节处理
f = open('1.txt', 'r', encoding='utf-8')
while True:
re = f.readline()
if re:
print(re, end=' ')
else:
break
f.close()
5、文件打开方式
对于二进制文件,无论读取和写入都需要使用二进制的数据
rb wb ab
且不能指定 encoding 参数
f = open('a.txt', 'wb')
f.write('你好'.encode()) # encode() 将str转换为二进制格式的字符串
f.close
f1 = open('a.txt', 'rb')
buf = f1.read()
print(buf)
print(buf.decode())
f1.close()
6、应用-文件备份
file_name = input('文件名')
f = open(file_name, 'rb')
buf = f.read()
f.close()
# 用查找找到文件后缀和文件名
index = file_name.rfind('.')
new_file_name = file_name[:index] + '[备份]' + file_name[index:]
print(new_file_name)
# 将原文件内容写入新文件
f_w = open(new_file_name, 'wb')
f_w.write(buf)
f_w.close()
7、文件和文件夹的操作
# 对文件和目录的操作,需要导入os模块
import os
# 1.文件重命名 os.rename(原文件名,新文件名)
# os.rename('1.txt', 'b.txt')
# 2.删除文件 os.remove(文件名)
# os.remove('b.txt')
# 3.创建目录 os.mkdir(目录名) make directory
# os.mkdir('test')
# os.mkdir('test/aa')
# 4.删除空目录 os.rmdir(目录名) remove directory
# os.rmdir('test/aa')
# os.rmdir('test')
# 5.获取当前所在目录 os.getcwd() get current working directory
# f = os.getcwd()
# print(f)
# 6.修改当前所在目录 os.chdir(目录名) change dir
# os.chdir('test')
# f1 = os.getcwd()
# print(f1)
# os.chdir('../') #返回上级目录
# f2 = os.getcwd()
# print(f2)
# 7.获取指定目录中的内容,os.listdir(目录) 默认不写参数 获取当前目录中的内容
# 返回值是列表,列表中的每一项是文件名
f3 = os.listdir()
print(f3)
8、批量修改文件名
import os
def create_files():
for i in range(10):
file_name = 'test/file_' + str(i) + '.txt'
# print(file_name)
f = open(file_name, 'w')
f.close()
create_files()
def create_files():
os.chdir('test')
for i in range(10, 20):
file_name = 'test_' + str(i) + '.txt'
print(file_name)
f = open(file_name, 'w')
f.close()
os.chdir('../')
create_files()
def modify_filename():
os.chdir('test')
buf_list = os.listdir()
print(buf_list)
for file in buf_list:
new_file = 'python_' + file
os.rename(file, new_file)
os.chdir('../')
modify_filename()
def modify_filename_1():
os.chdir('test')
buf_list = os.listdir()
print(buf_list)
for file in buf_list:
num = len('python_')
new_file = file[num:]
os.rename(file, new_file)
os.chdir('../')
modify_filename_1()















 7203
7203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









