







Style Transfer-PyTorch
Content Loss
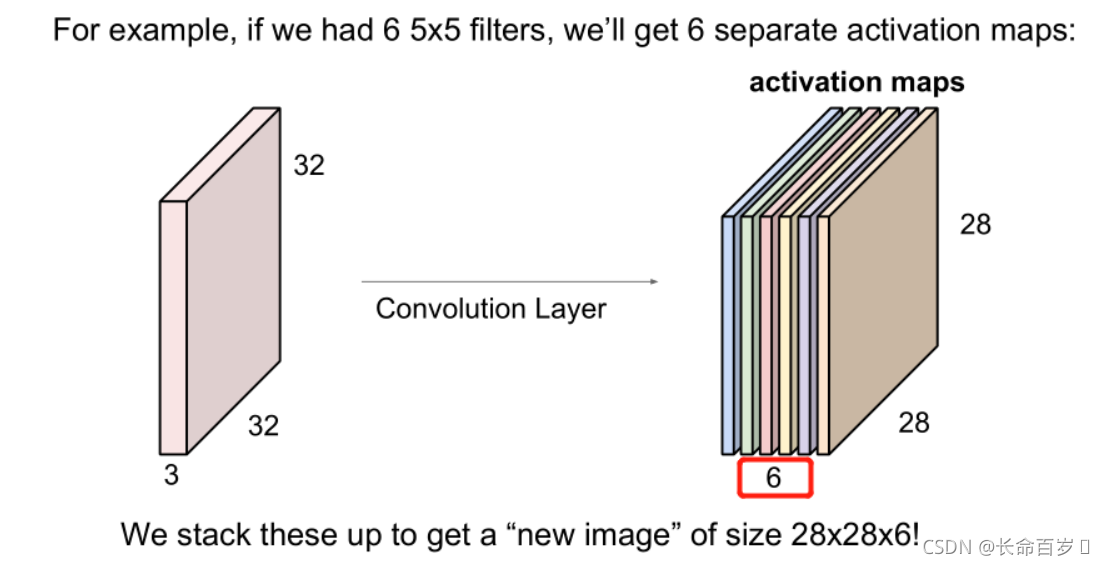
content loss用来计算原图片和生成的图片之间像素的差距,这里用的是卷积层获取的 feature map 之间的差距
通过卷积层,有多少个卷积核就会生成多少个 feature_map(也就是一个卷积核的输出结果)
公式为: L c = w c × ∑ i , j ( F i j ℓ − P i j ℓ ) 2 L_c = w_c \times \sum_{i,j} (F_{ij}^{\ell} - P_{ij}^{\ell})^2 Lc=wc×∑i,j(Fijℓ−Pijℓ)2
- w c w_c wc 是当前层两张照片之间的差距的权重
- F l F^l Fl 是当前图片的 feature_map
- P l P^l Pl 是内容来源图片的 feature_map

def content_loss(content_weight, content_current, content_original):
"""
Compute the content loss for style transfer.
Inputs:
- content_weight: Scalar giving the weighting for the content loss.
- content_current: features of the current image; this is a PyTorch Tensor of shape
(1, C_l, H_l, W_l).
- content_target: features of the content image, Tensor with shape (1, C_l, H_l, W_l).
Returns:
- scalar content loss
"""
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
N,C,H,W = content_current.shape
Fc = content_current.view(C,H*W) # view 相当于 reshape
Pc = content_original.view(C,H*W)
Lc = content_weight * (Fc - Pc).pow(2).sum()
return Lc
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
Style Loss
这里我们使用格拉姆矩阵(Gram matrix G)来表示feature map每个通道(channel)之间的联系(也就是风格)。
-
Gram matrix G : G i j ℓ = ∑ k F i k ℓ F j k ℓ G_{ij}^\ell = \sum_k F^{\ell}_{ik} F^{\ell}_{jk} Gijℓ=∑kFikℓFjkℓ
- F l F^l Fl 是当前图片的 feature_map
-
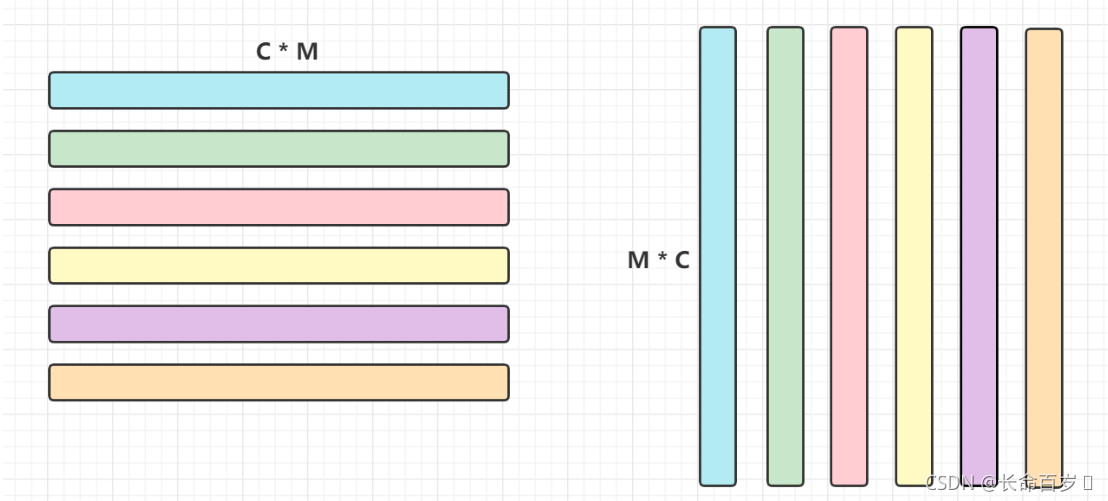
Gram matrix 的核心就是以上两个矩阵进行矩阵乘法
def gram_matrix(features, normalize=True): """ Compute the Gram matrix from features. Inputs: - features: PyTorch Tensor of shape (N, C, H, W) giving features for a batch of N images. - normalize: optional, whether to normalize the Gram matrix If True, divide the Gram matrix by the number of neurons (H * W * C) Returns: - gram: PyTorch Tensor of shape (N, C, C) giving the (optionally normalized) Gram matrices for the N input images. """ # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** N,C,H,W = features.shape F = features.view(N , C , H * W) # N * C * M F_t = F.permute(0 , 2 , 1) # N * M * C permute的作用是交换维度 gram = torch.matmul(F , F_t) # N * C * C if normalize: gram = gram / (C * H * W) return gram # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** -
第 l 层的 Loss: L s ℓ = w ℓ ∑ i , j ( G i j ℓ − A i j ℓ ) 2 L_s^\ell = w_\ell \sum_{i, j} \left(G^\ell_{ij} - A^\ell_{ij}\right)^2 Lsℓ=wℓ∑i,j(Gijℓ−Aijℓ)2
- A l A^l Al 是特征来源图片的 Gram matrix
- 和 G l G^l Gl 的计算方法相同 , 只是换了输入
-
Loss function: L s = ∑ ℓ ∈ L L s ℓ L_s = \sum_{\ell \in \mathcal{L}} L_s^\ell Ls=∑ℓ∈LLsℓ
- 所有层的 loss 相加
-
torch.matmul
- torch.matmul 是tensor的乘法,输入可以是高维的。(超过两维的时候前面的都当做 batch , 最后两维进行矩阵乘法)
- 当输入是都是二维时,就是普通的矩阵乘法,和 tensor.mm 函数用法相同
a = torch.ones(3 , 4)
b = torch.ones(4 , 2)
c = torch.matmul(a , b)
c.shape
>> torch.Szie([3 , 2])
a = torch.ones(5 , 3 , 4)
b = torch.ones(4 , 2)
c = torch.matmul(a , b)
c.shape
>> torch.Size([5 , 3 , 2])
a = torch.ones(2 , 5 , 3)
b = torch.ones(1 , 3 , 4)
c = torch.matmul(a , b)
c.shape
>> torch.Size([2 , 5 , 4])
-
计算 Style Loss
# Now put it together in the style_loss function... def style_loss(feats, style_layers, style_targets, style_weights): """ Computes the style loss at a set of layers. Inputs: - feats: list of the features at every layer of the current image, as produced by the extract_features function. - style_layers: List of layer indices into feats giving the layers to include in the style loss. - style_targets: List of the same length as style_layers, where style_targets[i] is a PyTorch Tensor giving the Gram matrix of the source style image computed at layer style_layers[i]. - style_weights: List of the same length as style_layers, where style_weights[i] is a scalar giving the weight for the style loss at layer style_layers[i]. Returns: - style_loss: A PyTorch Tensor holding a scalar giving the style loss. """ # Hint: you can do this with one for loop over the style layers, and should # not be very much code (~5 lines). You will need to use your gram_matrix function. # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** style_current = [] #style_loss = torch.zeros([1],dtype=float) style_loss = 0 for i,idx in enumerate(style_layers): style_current.append(gram_matrix(feats[idx].clone())) style_loss += (style_current[i] - style_targets[i]).pow(2).sum() * style_weights[i] return style_loss # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
Total-variation regularization
total variation loss可以使图像变得平滑 ,变得更加平滑被证明是有帮助的
具有过多和可能是虚假细节的信号具有高的总变化,即,信号的绝对梯度的积分是高的。根据该原理,减小信号的总变化,使其与原始信号紧密匹配,去除不需要的细节,同时保留诸如边缘的重要细节
- Total Variation(TV)的方程是这样的: R V β ( f ) = ∫ Ω ( ( ∂ f ∂ u ( u , v ) ) 2 + ( ∂ f ∂ v ( u , v ) ) 2 ) β 2 d u d v \mathcal{R}_{V^{\beta}}(f)=\int_{\Omega}\left(\left(\frac{\partial f}{\partial u}(u, v)\right)^{2}+\left(\frac{\partial f}{\partial v}(u, v)\right)^{2}\right)^{\frac{\beta}{2}} d u d v RVβ(f)=∫Ω((∂u∂f(u,v))2+(∂v∂f(u,v))2)2βdudv
- 在图像中,连续域的积分就变成了像素离散域中求和,所以可以这么算: R V β ( x ) = ∑ i , j ( ( x i , j + 1 − x i j ) 2 + ( x i + 1 , j − x i j ) 2 ) β 2 \mathcal{R}_{V^{\beta}}(\mathbf{x})=\sum_{i, j}\left(\left(x_{i, j+1}-x_{i j}\right)^{2}+\left(x_{i+1, j}-x_{i j}\right)^{2}\right)^{\frac{\beta}{2}} RVβ(x)=∑i,j((xi,j+1−xij)2+(xi+1,j−xij)2)2β
- 也就是说,求每一个像素和横向下一个像素的差的平方,加上纵向下一个像素的差的平方。然后开β/2次根
在本次实验中,我们的 Total Variation(TV) 公式为:
L t v = w t × ( ∑ c = 1 3 ∑ i = 1 H − 1 ∑ j = 1 W ( x i + 1 , j , c − x i , j , c ) 2 + ∑ c = 1 3 ∑ i = 1 H ∑ j = 1 W − 1 ( x i , j + 1 , c − x i , j , c ) 2 ) L_{tv} = w_t \times \left(\sum_{c=1}^3\sum_{i=1}^{H-1}\sum_{j=1}^{W} (x_{i+1,j,c} - x_{i,j,c})^2 + \sum_{c=1}^3\sum_{i=1}^{H}\sum_{j=1}^{W - 1} (x_{i,j+1,c} - x_{i,j,c})^2\right) Ltv=wt×(∑c=13∑i=1H−1∑j=1W(xi+1,j,c−xi,j,c)2+∑c=13∑i=1H∑j=1W−1(xi,j+1,c−xi,j,c)2)
- 可以看出,和上面的式子一样,只是计算了三通道像素,并且乘以权重 w t w_t wt
def tv_loss(img, tv_weight):
"""
Compute total variation loss.
Inputs:
- img: PyTorch Variable of shape (1, 3, H, W) holding an input image.
- tv_weight: Scalar giving the weight w_t to use for the TV loss.
Returns:
- loss: PyTorch Variable holding a scalar giving the total variation loss
for img weighted by tv_weight.
"""
# Your implementation should be vectorized and not require any loops!
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
N,C,H,W = img.shape
x1 = img[: , : , 0:H-1 , :]
x2 = img[: , : , 1:H , :] # x1的所有元素的后一个的组合
y1 = img[: , : , : , 0:W-1]
y2 = img[: , : , : , 1:W] # y1的所有元素的后一个的组合
loss = ((x2-x1).pow(2).sum() + (y2-y1).pow(2).sum()) * tv_weight
return loss
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
Generate some pretty pictures
- Example 1

- Example 2

- Example 3

结论分析与体会
本次实验主要学习了利用 PyTorch 进行风格迁移训练(将一张图片的内容与另一张图片的风格相结合)
- 计算 content loss
- 将当前图片的 features map 与 content 原图片的 features map进行比较
- 每一层的 loss 公式为: L c = w c × ∑ i , j ( F i j ℓ − P i j ℓ ) 2 L_c = w_c \times \sum_{i,j} (F_{ij}^{\ell} - P_{ij}^{\ell})^2 Lc=wc×∑i,j(Fijℓ−Pijℓ)2
- 计算 style loss
- 计算当前图片的 features map 对应的 Gram matrix
- Gram matrix G : G i j ℓ = ∑ k F i k ℓ F j k ℓ G_{ij}^\ell = \sum_k F^{\ell}_{ik} F^{\ell}_{jk} Gijℓ=∑kFikℓFjkℓ
- 计算 style 原图片的 features map 对应的 Gram matrix
- Gram matrix A : A i j ℓ = ∑ k P i k ℓ P j k ℓ A_{ij}^\ell = \sum_k P^{\ell}_{ik} P^{\ell}_{jk} Aijℓ=∑kPikℓPjkℓ
- 利用当前图片的 Gram matrix 和 style 原图片的 Gram matrix 计算 loss
- 第 l 层的 Loss: L s ℓ = w ℓ ∑ i , j ( G i j ℓ − A i j ℓ ) 2 L_s^\ell = w_\ell \sum_{i, j} \left(G^\ell_{ij} - A^\ell_{ij}\right)^2 Lsℓ=wℓ∑i,j(Gijℓ−Aijℓ)2
- Loss function: L s = ∑ ℓ ∈ L L s ℓ L_s = \sum_{\ell \in \mathcal{L}} L_s^\ell Ls=∑ℓ∈LLsℓ
- 计算当前图片的 features map 对应的 Gram matrix
- 计算 Total-variation loss
- L t v = w t × ( ∑ c = 1 3 ∑ i = 1 H − 1 ∑ j = 1 W ( x i + 1 , j , c − x i , j , c ) 2 + ∑ c = 1 3 ∑ i = 1 H ∑ j = 1 W − 1 ( x i , j + 1 , c − x i , j , c ) 2 ) L_{tv} = w_t \times \left(\sum_{c=1}^3\sum_{i=1}^{H-1}\sum_{j=1}^{W} (x_{i+1,j,c} - x_{i,j,c})^2 + \sum_{c=1}^3\sum_{i=1}^{H}\sum_{j=1}^{W - 1} (x_{i,j+1,c} - x_{i,j,c})^2\right) Ltv=wt×(∑c=13∑i=1H−1∑j=1W(xi+1,j,c−xi,j,c)2+∑c=13∑i=1H∑j=1W−1(xi,j+1,c−xi,j,c)2)
- 总的 Loss
- l o s s = c o n t e n t L o s s + s t y l e L o s s + t v L o s s loss = contentLoss + styleLoss + tvLoss loss=contentLoss+styleLoss+tvLoss
- 使用梯度下降的方法缩小 loss 对模型进行优化















 2220
2220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











