







今天看《A Modified YOLOv8 Detection Network for UAV Aerial Image Recognition》
目录
一、摘要
1.1 原文
UAV multitarget detection plays a pivotal role in civil and military fields. Although deep learning methods provide a more effective solution to this task, changes in target size, shape change, occlusion, and lighting conditions from the perspective of drones still bring great challenges to research in this field. Based on the above problems, this paper proposes an aerial image detection model with excellent performance and strong robustness. First, in view of the common problem that small targets in aerial images are prone to misdetection and missed detection, the idea of Bi-PAN-FPN is introduced to improve the neck part in YOLOv8-s. By fully considering and reusing multiscale features, a more advanced and complete feature fusion process is achieved while maintaining the parameter cost as much as possible. Second, the GhostblockV2 structure is used in the backbone of the benchmark model to replace part of the C2f module, which suppresses information loss during longdistance feature transmission while significantly reducing the number of model parameters; finally, WiseIoU loss is used as bounding box regression loss, combined with a dynamic nonmonotonic focusing mechanism, and the quality of anchor boxes is evaluated by using “outlier” so that the detector takes into account different quality anchor boxes to improve the overall performance of the detection task. The algorithm’s performance is compared and evaluated on the VisDrone2019 dataset, which is widely used worldwide, and a detailed ablation experiment, contrast experiment, interpretability experiment, and self-built dataset experiment are designed to verify the effectiveness and feasibility of the proposed model. The results show that the proposed aerial image detection model has achieved obvious results and advantages in various experiments, which provides a new idea for the deployment of deep learning in the field of UAV multitarget detection.
1.2 翻译
无人机多目标检测在民用和军用领域都起着重要的作用,尽管深度学习方法为这项任务提供了一个更有效的解决方法,但来自无人机视角的目标尺寸变化、形状变化、遮挡和光照条件仍然给这个领域的研究带来了巨大的挑战。基于上述的问题,这篇文章提出了一种性能和鲁棒性较高的航空图像检测模型。首先,鉴于航空图像中小目标容易导致误检和漏检的问题,我们引入Bi-PAN-FPN来改进YOLOv8-s的Neck部分。通过充分考虑和重用多尺度特征,我们实现了一个更加先进和完整的特征融合过程,同时尽可能保留参数成本。其次,GhostblockV2结构被用在基准模型的backbone部分用以替代C2f模块,该模块会在长距离特征传输时抑制信息损失同时显著降低模型参数数量。最后,我们采用WiseIoU作为边界框回归损失,结合了一种动态非单调聚焦机制,并且锚框的质量使用“异常值”评估,所以检测器会考虑不同质量的锚框以提升检测任务的整体性能。算法的性能在VisDrone2019数据集上进行比较和评估,该数据集在全世界范围广泛应用。并且基于此我们还进行了消融实验,对比实验和可解释性实验。自建数据集上的实验被设计用来验证所提出模型的有效性和可行性。结果显示我们所提出的航空图像检测模型在较多实验中取得了显著的效果和优势,这也为无人机多目标检测领域中深度学习的部署提供了一种新的观点。
二、介绍
本文的主要贡献如下所示:
- 从关注大尺寸特征图和引入Bi-PAN-FPN观点的角度,本工作提高了模型对小目标的检测性能,同时增加了多尺度特征融合获得更好特征工程的概率和时间。这解决了航空图像中小目标易误检和漏检的常见问题
- 优化模型的骨干网络和损失函数。Ghostblock单元和Wise-IoU边界框回归损失被集成以从特征多样性、特征信息长距捕获以及避免几何因素过度惩罚等方面提高模型泛化能力。在提高模型准确性的同时减少模型参数数量。这解决了远程信息损失问题以及预测框平衡问题
- 构建模型的可行性和有效性通过消融实验证明。与基准网络相比较,在国际开源数据集VisDrone上模型MAP性能提升9.06%(测试集),参数量减少13.21%,并且综合能力显著提升
- 我们所提出的模型与现存的六个主流和现金的深度目标检测模型进行对比以证明我们模型的先进性。另外,与三个优秀模型的可解释性相比阐释了这种方法先进的原因
三、改进的航空图像检测模型
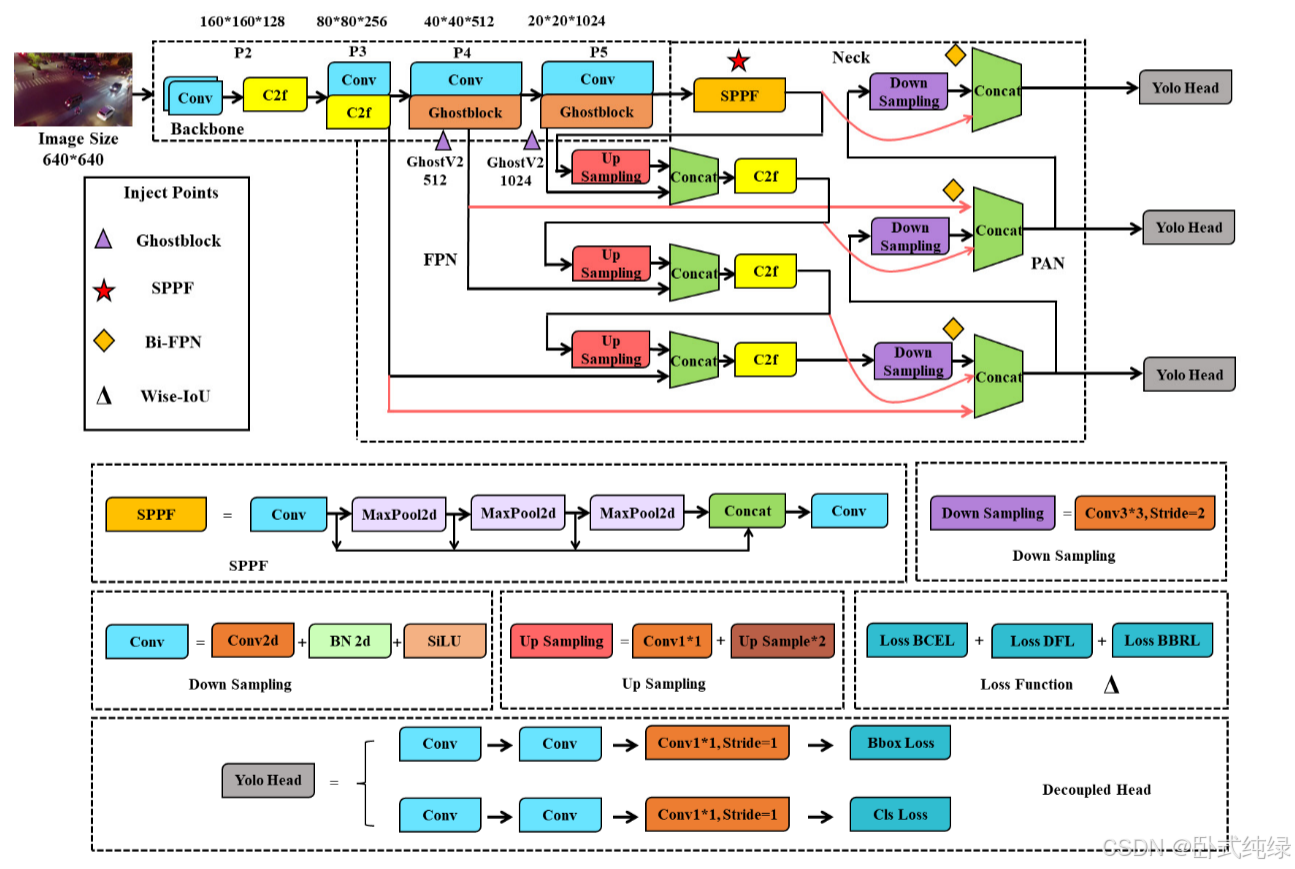
3.1 Neck改进
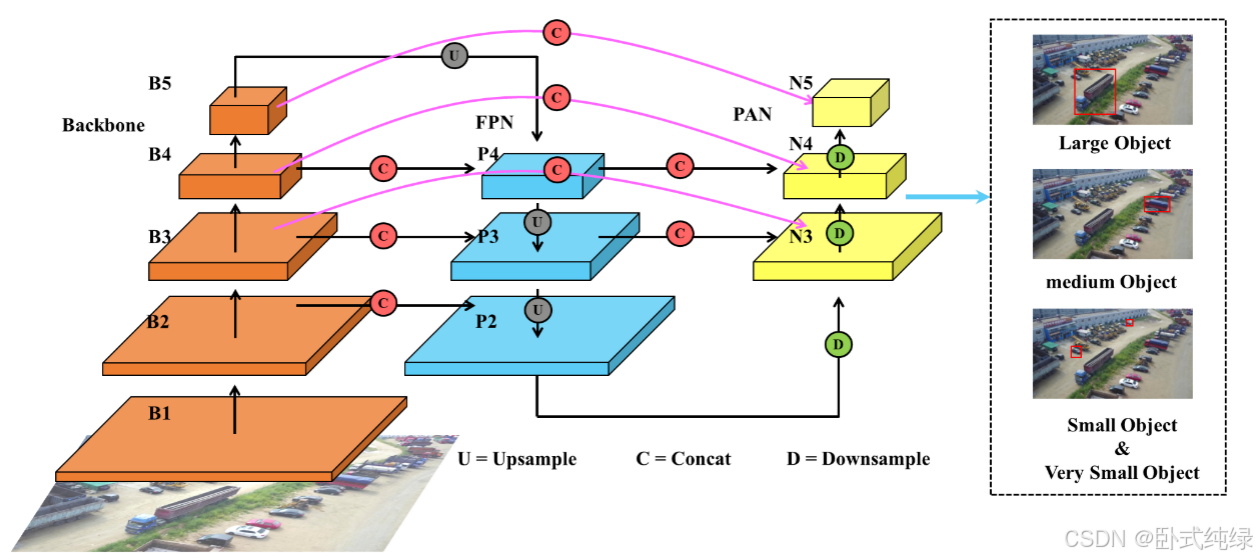
在yolov8中,特征图按降序被分为五种规模特征,分别是骨干网络中的B1-B5,P3-P5以及N4-N5,FPN和PAN结构。虽然该结构已经非常有效,但当这种结构应用于小目标检测中时仍然有改进的空间:一方面,由于对大尺度特征图关注的缺失,检测模型会忽略一些有用的特征并降低检测质量;另一方面,即使考虑到B,P和N特征的融合和互补,特征的重用率仍然很低,并且传统特征经过长时间的上采用和下采样路径后会损失一些信息。
针对上述问题,我们提出了改进:首先,我们重新聚焦于大尺度特征图。一种上采样过程被添加进FPN并且融入骨干B2层特征中以提高小目标检测性能。类似于先前上采样过程,C2f模块被用于深层次提高特征融合后的特征提取质量。C2f模块是对原C3模块的改进,这主要指的是yolov7中ELAN的结构中具有更丰富的梯度信息优势。C2f模块减少了一个标准的卷积层并充分利用瓶颈模块来扩大梯度分支以获得更丰富的梯度流信息同时确保轻量化。其基础结构如下:
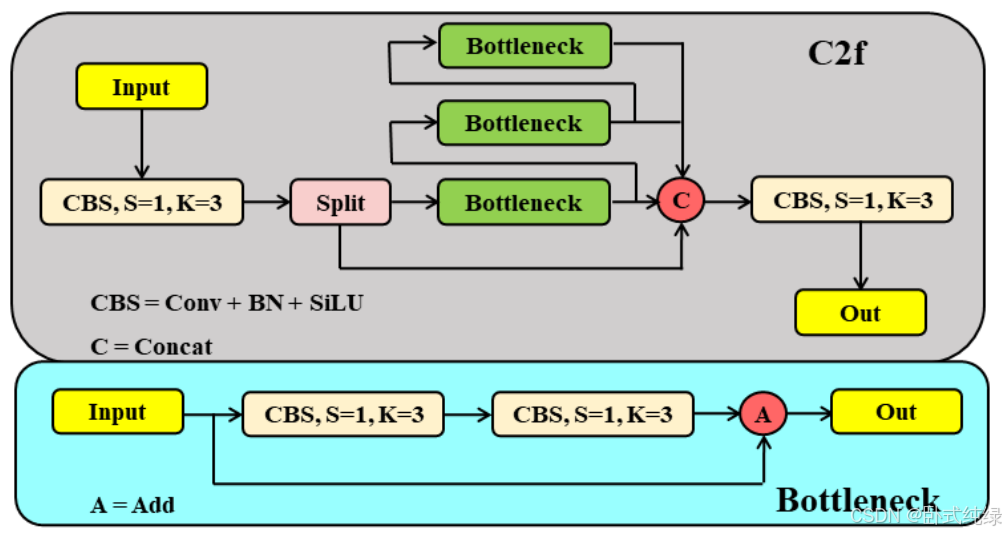
其次,我们引入了Bi-PAN-FPN的观点。这个架构的核心观点就是提高多尺度特征融合的概率和时间以获得更高的检测精度。它的实现步骤如下:对于那些仅有一个输入路径的特征图,不执行其他处理过程。通常而言,这样的特征对特征工程的贡献很低。对于那些有两条输入路径的特征图,如果特征图尺寸大小一致,在骨干中则会新增一条额外的路径,然后PAN中的特征会被融合。这样的处理方法并没有新增额外的参数成本。最后,将每个双向路径(自上向下和自下向上)视作一个单元并重用这个单元数次以改善融合效果。考虑到模型的轻量化,这里只添加了额外的B3-N3和B4-N4路径,并且仅使用一个单元。这个过程可以表示如下:
C2f和Conv是相关操作,B,P和N分别代表骨干网络、FPN和PAN中的特征图;n代表C2f的使用数量;i取值3或4.Neck的整体架构如下所示:
3.2 Backbone改进
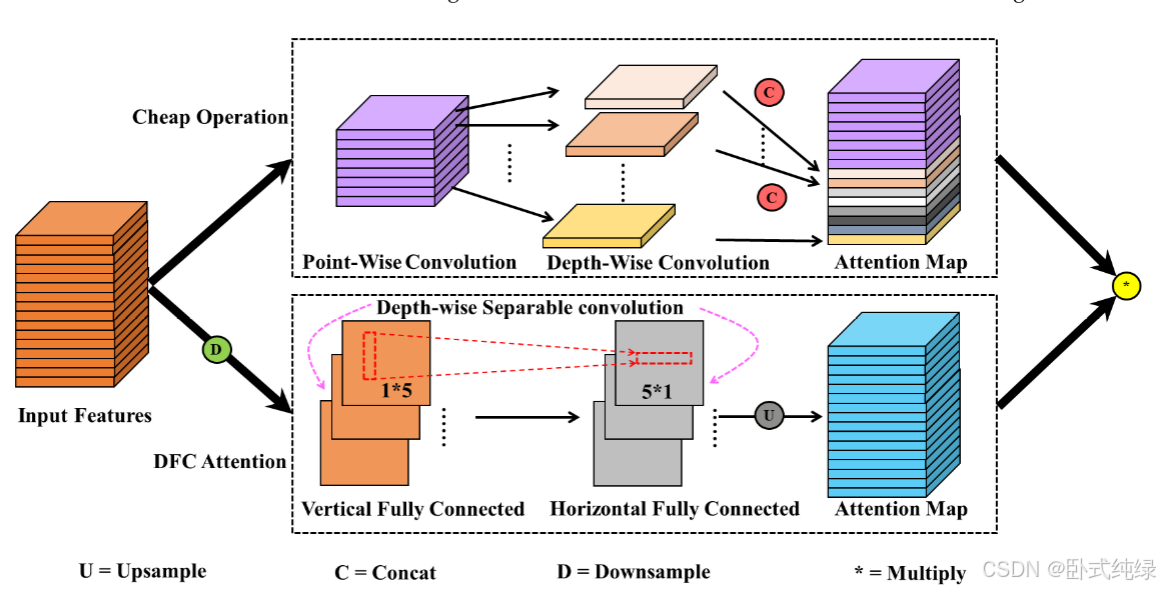
YOLOv8中使用了传统的卷积模块和C2f模块来实现图像的高质量特征提取和下采样。然而,由于在颈部增加了上采样过程并使用了Bi-PAN FPN,模型的参数数量和复杂性在一定程度上增加了。本文将介绍骨干网中的Ghostblock思想,并使用这种结构替换一些C2f模块。Ghostblock是一种轻量级卷积GhostNet的优化方法[32]。其优势主要体现在两个方面。一方面,Ghostblock遵循了GhostNet的精髓。它首先使用传统的卷积来生成原始特征图,然后结合各种线性变换操作来增强特征图的信息。这确保了特征多样性,同时有效地提取特征。另一方面,提出了一种解耦全连接(DFC)注意力机制[33]。通过其特殊性,该机制避免了传统注意力算法在计算复杂性方面的局限性,并在长距离上捕获特征信息。该结构的优点提高了整个结构的特征工程质量。具体来说,GhostNet中使用的卷积形式被称为廉价运算。其实施过程如下面等式所示:
其中X∈RC,H,W,Y∈RCout,H,W;F1*1表示逐点卷积;Fdp表示深度卷积;Cout≤Cout。与传统的卷积不同,在实现廉价操作的开始,只考虑逐点卷积来获得比实际输出标准按比例(默认为一半)更小的特征图,然后深度卷积作用于这些特征图以实现线性变换过程。最后,将两个步骤的特征图拼接在一起,得到输出结果。这种处理方法通过重用特征并丢弃传统卷积中可能存在的冗余信息,显著降低了参数成本和计算成本。然而,这样做的缺点也是显而易见的:逐点卷积失去了与空间中其他像素的交互过程,导致只有使用深度卷积获得的特征图捕获了空间信息。空间信息的表示将被显著削弱,因此会影响模型的检测精度。此外,卷积结构只能关注局部信息,但可以关注全局信息的自关注机制很容易增加模型的复杂性。DFC注意机制可以很好地改善上述问题。其核心思想是直接使用具有简单结构的深度可分结构来获得具有全局信息的注意力图。具体计算过程如方程式所示:
其中X∈RC,H,W,这与方程(3)中的输入一致;F是一个深度可分离的卷积过程,分为水平(KW∗1)和垂直(1∗KH)方向;α是垂直方向上的注意力图;α是基于α在水平方向上的注意力图。两个方向的解耦大大简化了提取特征全局信息的过程。同时,由于使用了1*KH和KW*1等深可分结构,DFC的复杂性大大降低(全连接:O(H2W+HW2);DFC:O(KHHW+KWHW))。Ghostblock将廉价操作与DFC相结合,在考虑特征全局信息的同时大大降低了模型的复杂性。其结构如图3所示。
3.3 损失函数改进
由于使用了无锚思想,YOLOv8的损失函数与YOLOv5系列相比发生了很大变化。其优化方向由分类和回归两部分组成。分类损失仍然使用二进制交叉熵图3。主干使用的Ghostblock结构。3.3. 损失函数的改进由于使用了无锚的想法,YOLOv8的损失函数与YOLOv5系列相比发生了很大变化。其优化方向由分类和回归两部分组成。分类损失仍然使用二元交叉熵损失(BCEL),回归部分使用分布焦损失(DFL)和边界框回归损失(BBRL)。完整的损失函数可以表示为:
其中,预测类别损失本质上是交叉熵损失,表达式为:
其中class是类别的数量;weight[class]表示每个类的权重;x是sigmoid激活后的概率值。DFL是焦损函数的优化,它通过积分将离散的分类结果推广为连续的结果。表达式为:
其中yi,yi+1表示连续标签y附近左右两侧的值,满足yi<y<yi+1,y=∑n i=0 P(yi)yi;在方程中,P可以通过softmax层P(yi)实现,即Si。与YoloV8中使用的CIoU损失不同,这里使用Wise-IoU损失函数作为边界框回归损失[34]。一方面,当训练数据的标记质量较低时,损失函数结合了一种动态非单调聚焦机制,通过使用“离群值”来评估锚帧的质量,以避免对模型的几何因素(如距离和纵横比)造成过度惩罚。另一方面,当预测框与目标框高度一致时,损失函数通过削弱几何因素的惩罚,使模型在较少的训练干预下获得更好的泛化能力。基于此,本文使用具有两层注意机制和动态非单调FM机制的Wise IoU v3。其表达式如下:
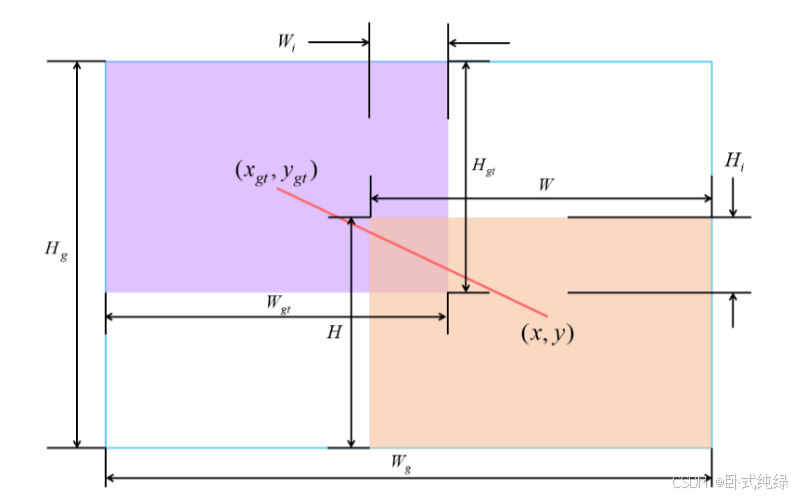
其中β表示预测箱的异常程度,异常程度越小,锚箱的质量越高。因此,使用β构建非单调焦数可以为具有较大异常值的预测框分配较小的梯度增益,有效地减少低质量训练样本的有害梯度;α和δ是超参数。其他参数的含义如图4所示。xp和yp表示预测框的坐标值,而xgt和ygt表示地面真值的坐标值。相应的H和W值分别表示两个框的宽度和高度。可以看出,Su=wh+wgthgt−WiHi。
迄今为止,基于Yolov8的改进航空图像检测模型如下图所示。与最初的YOLOv8相比,颈部、脊椎和损失功能得到了改善。具体更改位于图中的图形标签中:
四、实验结果
4.1 训练参数
数据集展示:

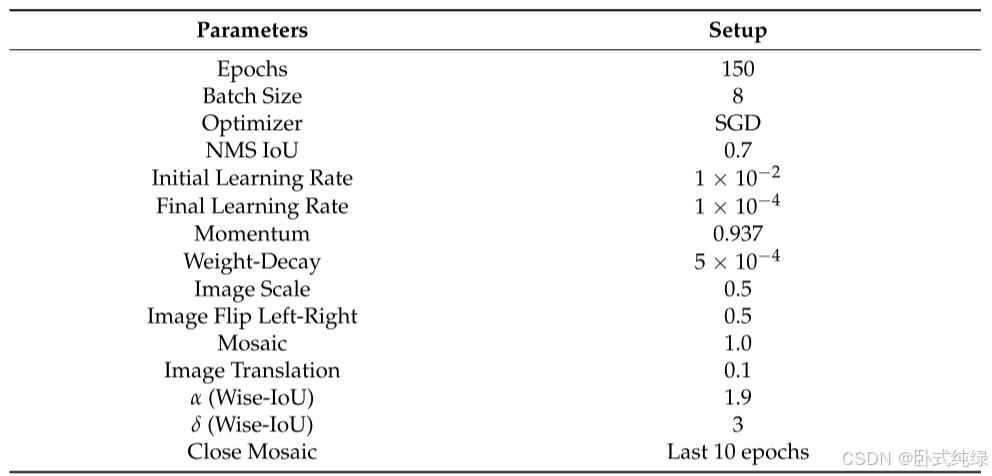
数据集中有10类对象。本文根据VisDrone 2019挑战赛的数据集划分方法,将整个数据集划分为训练集(6471个样本)、验证集(548个样本)和测试集(1610个样本)。考虑到样本图像包含大量小目标,为了使检测过程考虑到实时性和准确性的要求,将样本大小归一化为640×640。这样的尺寸可以使模型真正部署到边缘设备,而不会破坏图像中太多的有用信息。在硬件和软件方面,我们使用了英特尔(R)酷睿(TM)i9-12900K处理器、16核和24线程、主频3.19GHz、32GB运行内存、图形处理器GeForce RTX 3090Ti和24GB视频内存;深度学习模型框架使用Pytorch1.9.1和Torchvision 0.10.1;YOLOV8的基准版本是Ultralytics 8.0.25。
训练参数设置:
4.2 消融实验
本文设计的航空图像检测模型主要改进了基准模型(YOLOv8-s)的颈部和骨干部分,并在最终的损失函数中使用WiseIoU代替CIoU作为边界框回归损失。为了系统分析各单元模型性能的改进情况,依次定义了基准模型A、改进模型A+B(颈部)、改进模型A+B+C(颈部、骨干)和改进模型A+B+C+D(颈部、主干、损失函数),并定量探讨了四种模型评价指标的变化。实验使用精确率(P)、召回率(R)、平均精确率(AP)、平均精度均值(mAP)、每秒帧数(FPS)、参数数量和模型大小作为评价指标。模型在验证集和测试集上的实验结果如表2和表3以及图7所示。
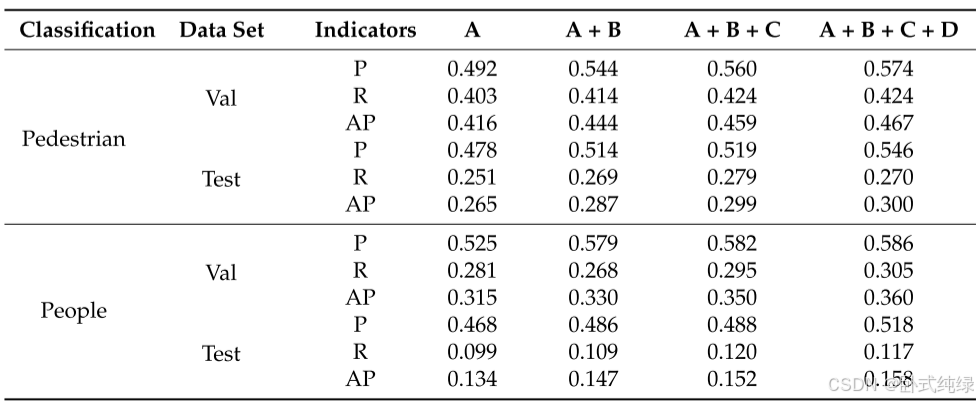
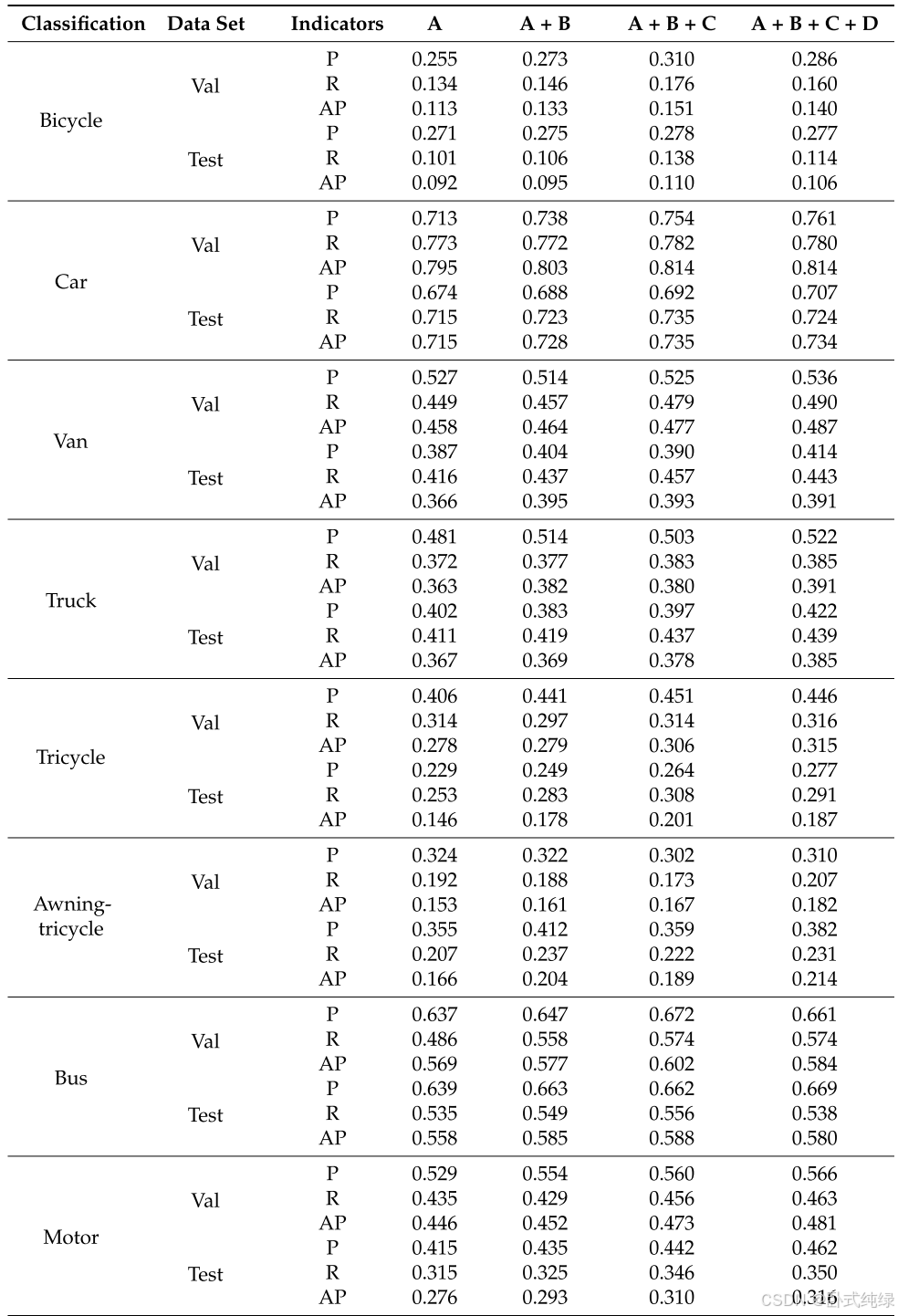
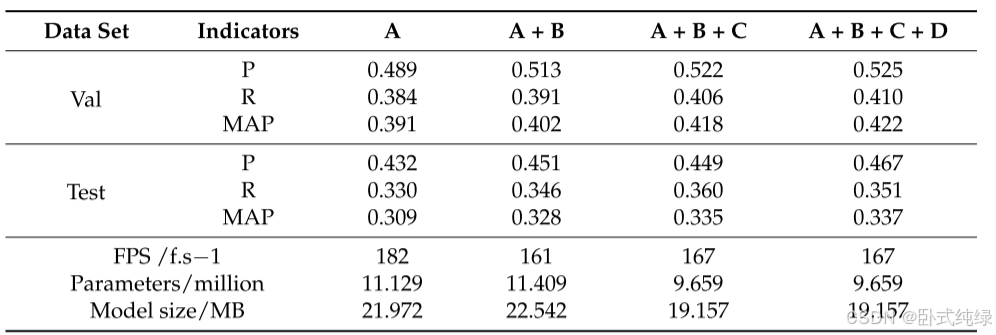
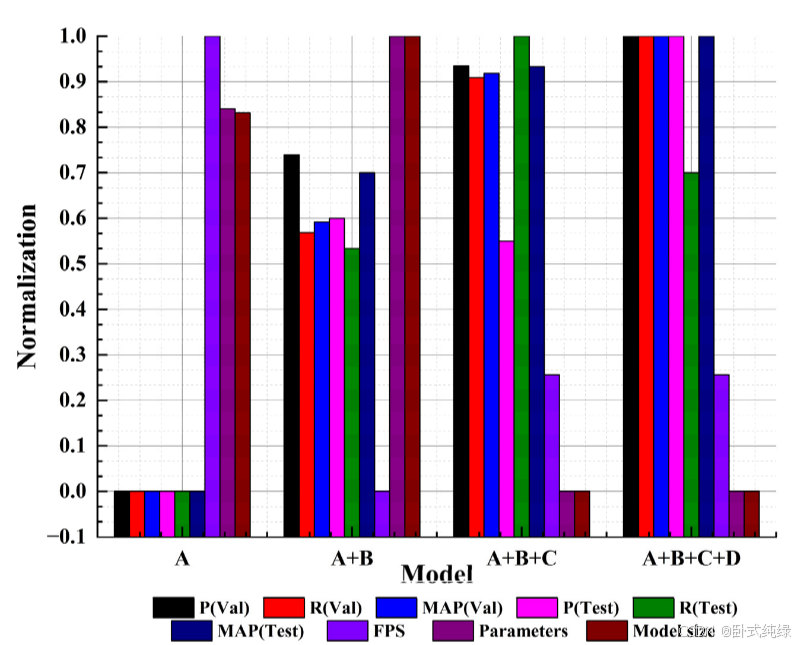
总结表2和表3以及图7中的子类别结果和总体结果,可以得出以下结论:
- A模型(即基准模型)表现不佳。其精度指标处于最低位置,但FPS排名第一,达到182/f.s-1。这表明,即使改进模型中的模型参数数量减少(仅965.9万),也会增加网络层数和一些推理时间。改进模型的FPS指数达到167/f.s-1,也可以保证实际部署中的实时要求。
- 在整合了B、C和D结构后,该模型在几个方面提高了性能——专注于小目标特征、复用多尺度特征、抑制长距离特征传输过程中的信息丢失,并考虑到不同质量的锚箱,特征工程得到了显著加强。这可以从每个单独的类别指标中看出。在大多数情况下,每当添加一个结构时,模型的P、R和AP指标的性能都会在一定程度上得到改善。然而,在纳入D结构后,该模型在某些类别中的指标数据不如以前。也就是说,在某些情况下,A+B+C优于A+B+C+D,但这并没有影响整体趋势。
- 总体而言,三种结构的连续改进使VisDrone数据集中的模型精度不断提高,参数数量逐渐减少,最终模型大小仅为19.157 MB。这表明,考虑到边缘设备检测场景的准确性和速度,对基线模型的改进是可行和有效的。部分场景的检测效果如图8所示。

4.3 深度学习模型的性能比较实验
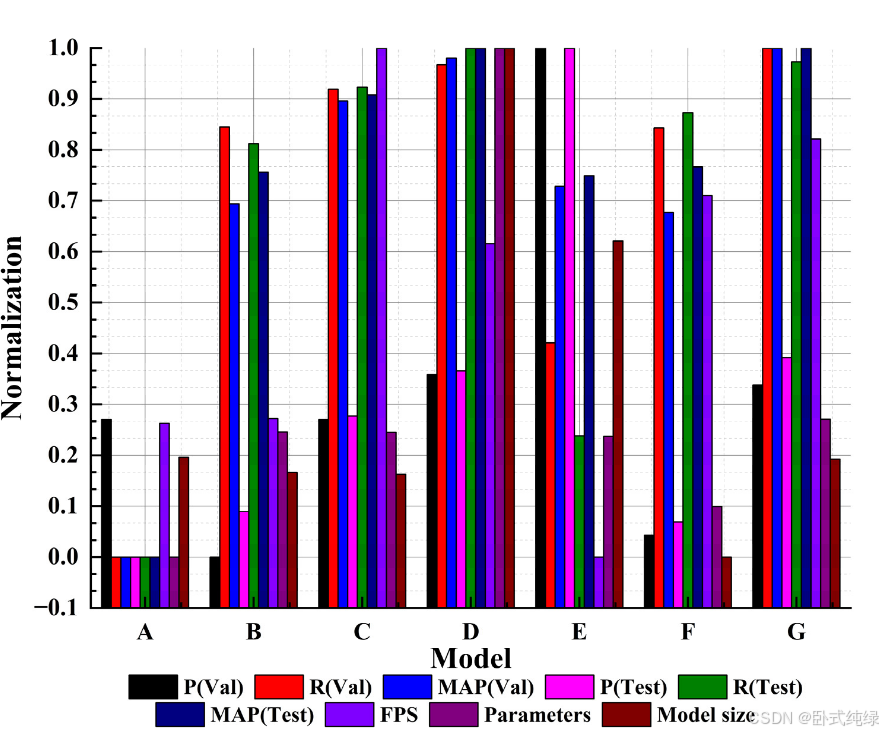
根据锚点生成机制的不同,深度学习方法在目标检测领域主要分为一阶段和两阶段方法。实时处理航空图像更符合实际工程场景。因此,选择硬件依赖性较低且考虑精度的单级目标检测方法更为实用。在实验中,选择了该领域更先进、更通用的YOLO系列和SSD作为比较测试的对象。具体来说,它包括YOLOv4-s[36]、YOLOv5-s[37]、YOLOX-s[38]、YOLOv7-minic[39]和MobilNetv2 SSD[40],它们已被广泛应用于各种嵌入式场景,并发表在许多论文中。为了体现本文模型的优越性,实验中还选择了YOLOv5-m作为比较对象。到目前为止,本文将MobilNetv2 SSD、YOLOv4-s、YOLOv5-s、YOULOv5-m、YOLOX-s、YOLOv7命名为minily,并将本文提出的模型依次命名为A、B、C、D、E、F和G。对比实验的参数按照表1进行,消融实验中的对比指标与表3一致。需要注意的是,YOLOv5是官方版本6.0,其余型号都是官方版本。为了确保公平性,所有模型都没有用预训练的权重进行训练。比较实验的结果如表4所示。
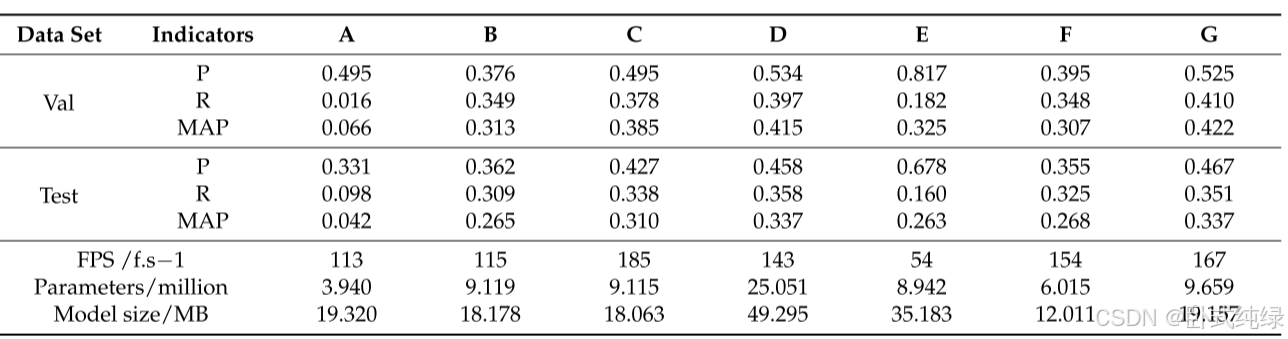
综合分析表4和图9中的相关数据,各模型的性能和比较结果可以总结如下:
- MobilNetv2 SSD的整体性能最差。该模型的参数数量最少,只有394万个。在目标检测任务中,其R指数在验证集和测试集中都是最低的,这意味着该模型有大量漏检。然而,它的p值显示出很高的性能,可以看出,除了遗漏的物体外,模型检测到的物体更容易识别。上述情况主要是因为VisDrone数据集在射击角度、目标大小和环境复杂性方面对目标检测模型有很高的要求。MobilNetv2 SSD通常在更简单的任务中具有很高的适用性,但它不适合这种复杂的任务。YOLOX-s也存在上述问题。该数据集上模型的R值相对较低,漏检率较高。p值在验证集和测试集中都取得了最佳结果,这使得YOLOX-s模型取得了更好的结果(优于YOLOv4-s)。然而,该模型的FPS性能最差。YOLOv4-s的性能相对平庸,在检测任务上仅优于MobilNetv2 SSD,但与前两种模型相比,该模型的R值有了很大提高,漏检率有所降低。
- YOLOv5-s和YOLOv7-minily这两款轻量级型号在测试集中都取得了优异的性能。特别是YOLOv5-s,经过官方迭代多个版本,整体性能大大提高。
- 两种模型的P和R指标处于相对平衡的状态,检出率和正确率相对协调。YOLOv7 minily是最小的型号。YOLOv5-s和YOLOv7-minily在测试集中的性能仅次于本文提出的轻量级模型,它们也适用于无人机航拍图像中的目标检测任务。
- 本文提出的模型的MAP指数在验证集和测试集中都是最优的。与非轻量级模型YOLOv5-m相比,P、R和MAP指标均与YOLOv5-m相当或更好。从FPS、参数和模型大小三个指标来看,模型性能处于第一梯队,这表明该模型具有最佳的综合性能。在本文涉及的无人机航拍图像目标检测任务中,所提出的模型在检测精度和部署难度方面满足了实际生产场景的需求,具有相当的鲁棒性和实用性。
4.4 可解释性实验
深度学习通常被称为“黑匣子”。尽管深度学习模型在各种类型的工程领域得到了广泛的应用,但由于算法缺乏可解释性,深度学习在一些高科技领域并没有取得很大进展。因此,深度学习可解释性是人工智能研究的主流方向。无人机在智能农业、军事等领域发挥着关键作用,对可解释性的深入探讨是建立其深度模型的关键环节。该实验选择了在第4.3节中表现良好的轻量级深度模型作为验证对象(YOLOv5-s、YOLOv7-minily和本文中的模型)。在充分讨论了它们在VisDrone数据集的混淆矩阵中的表现后,我们使用梯度加权类激活映射(Grade CAM)直观地分析了三个模型的注意力区域[41]。图10显示了三个模型的类别之间的混淆。
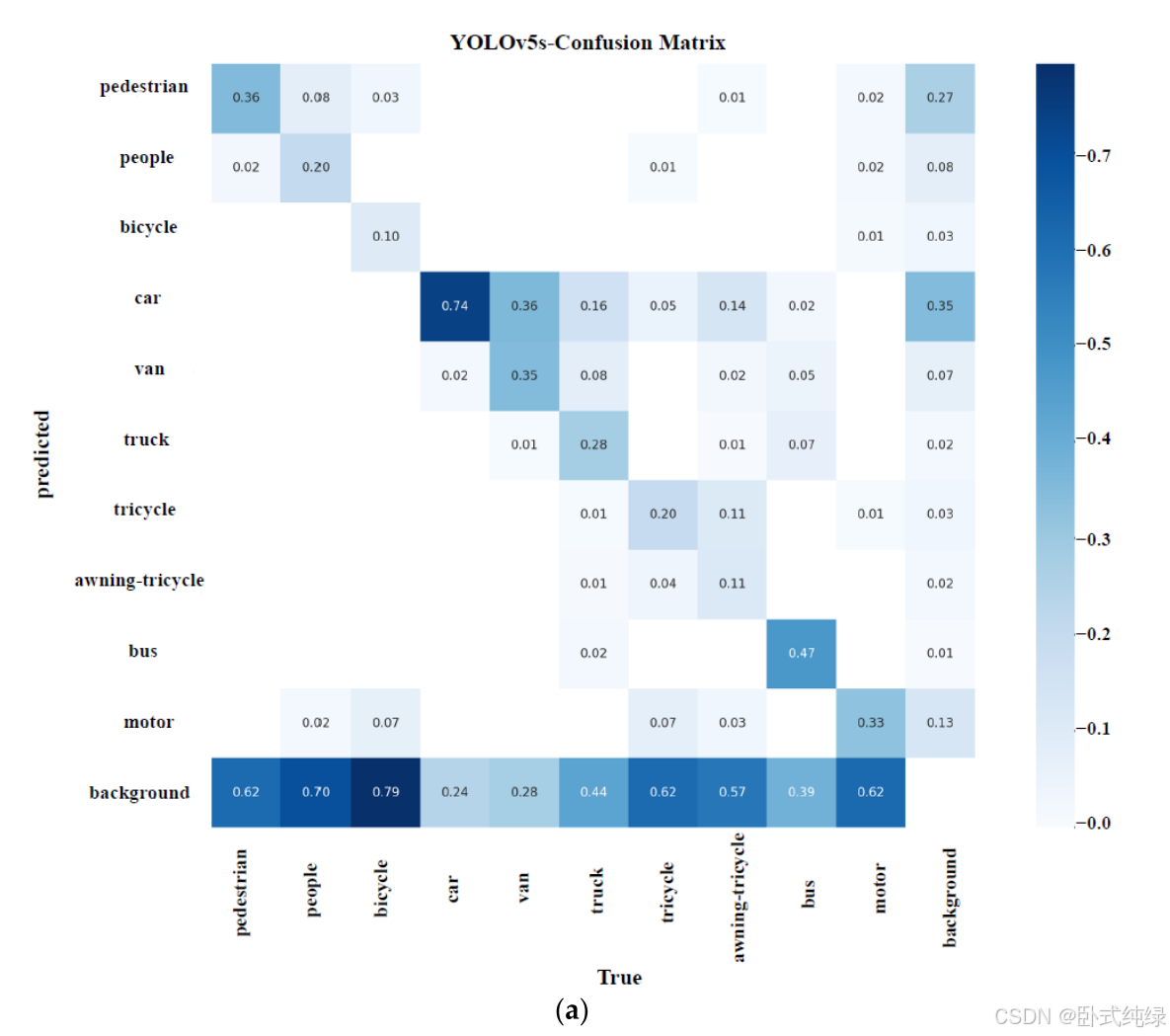
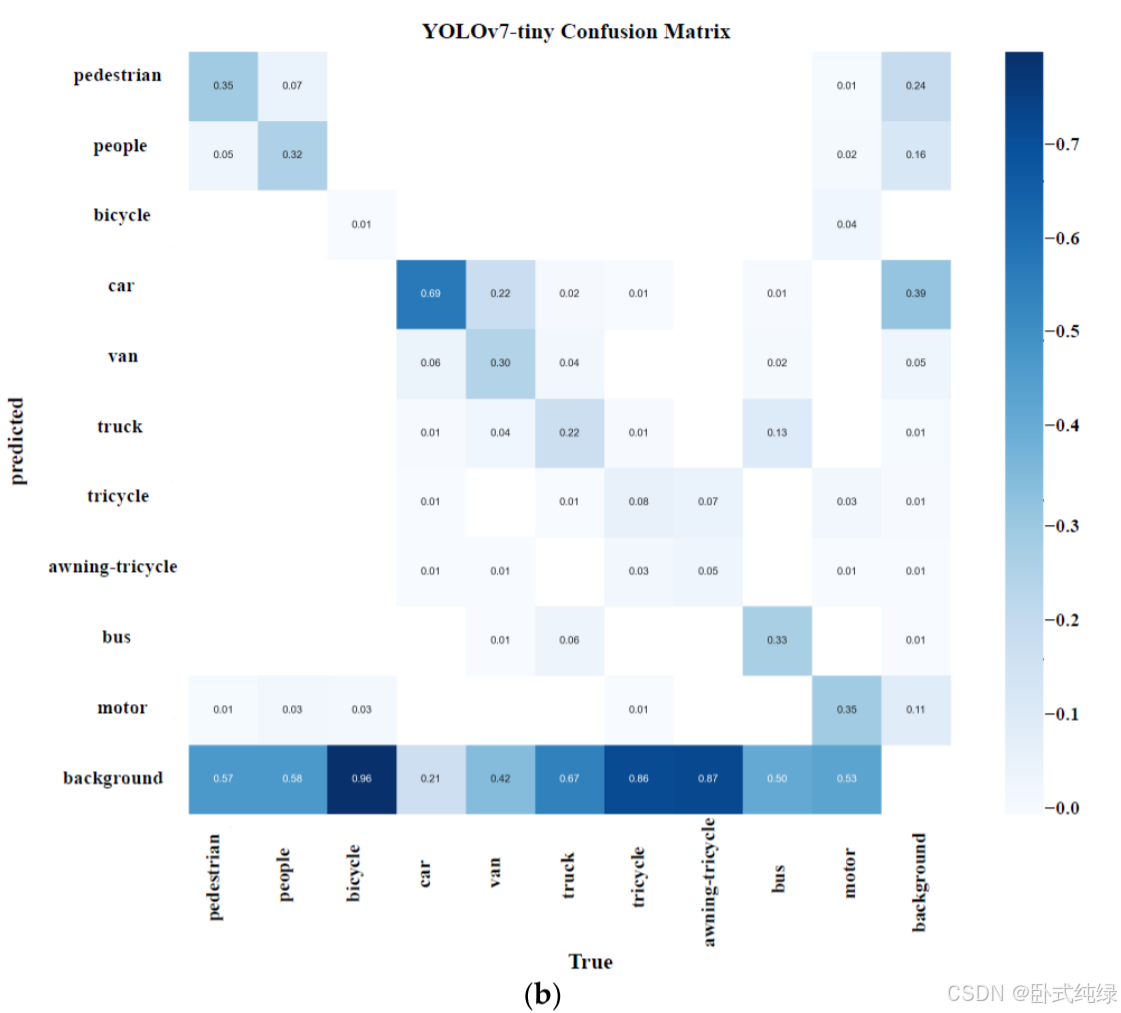
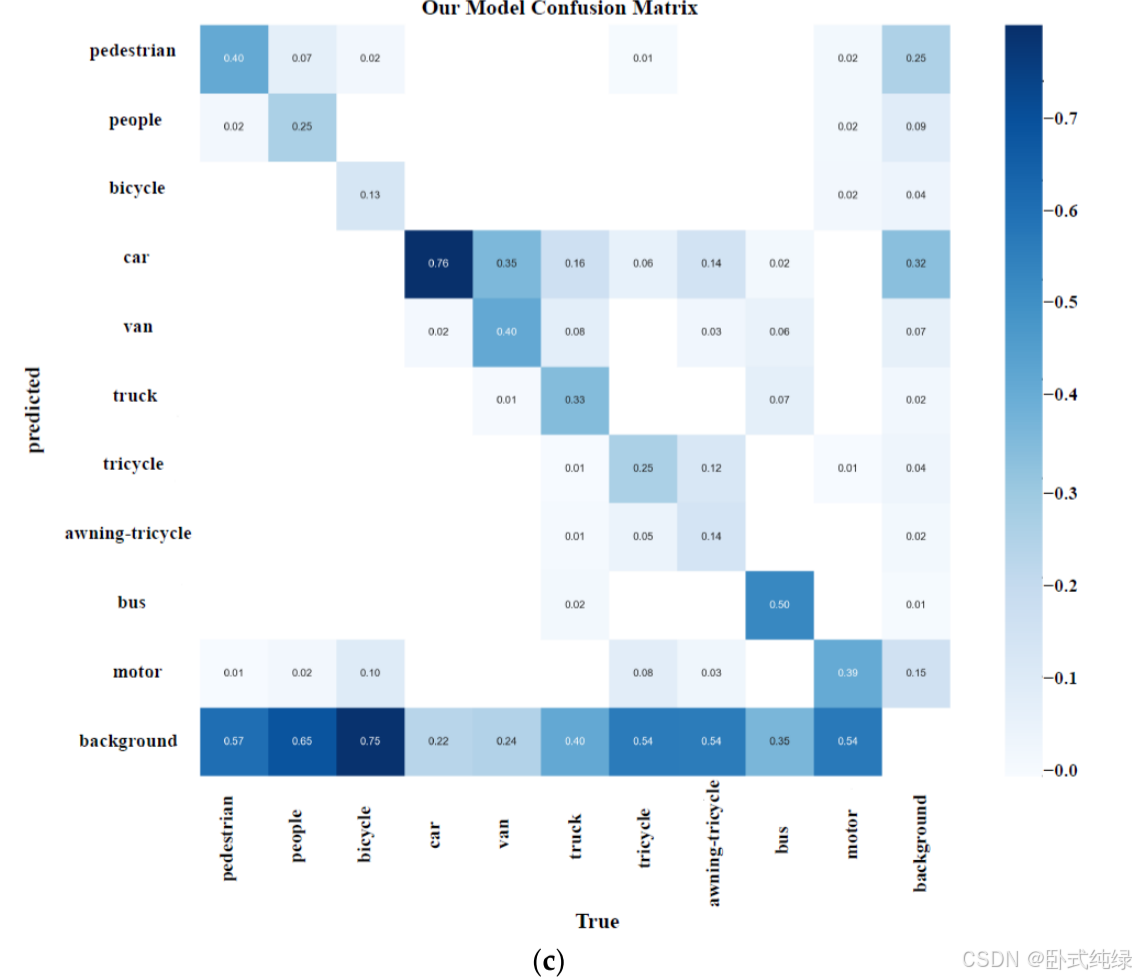
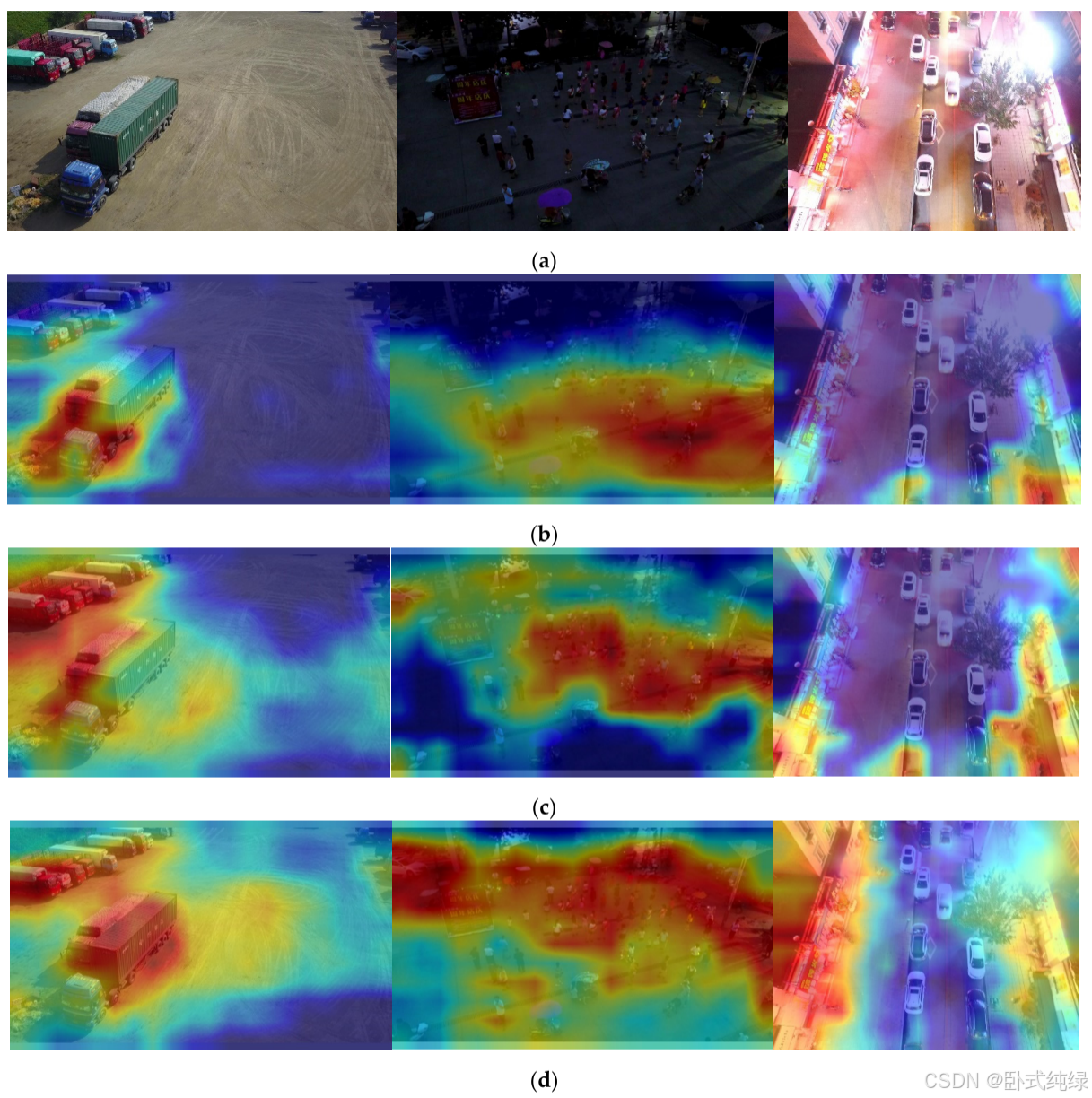
可以看出,这三个模型都有很大的漏检率(即每个类别都被识别为背景类别)。详细分析表明,对小汽车和公共汽车的识别度相对较好;难以识别的类别包括自行车和人;行李箱、三轮车和遮阳三轮车的识别效果最差。鉴于上述特点,实验中选择了Grad CAM来展示一些特殊类别的关注点,并从可解释性的角度解释了查看三个模型性能的原因。Grad CAM基于通过反向传播类置信度得分计算的梯度,并生成相应的权重。由于权重包含类别信息,因此对最终的检测性能具有重大的积极意义。具体来说,我们将重点展示每个模型骨干部分的输出层效果,并在此基础上分析躯干、人和自行车检测中的关注区域。实验结果如图11所示。
4.5 自建数据集实验
为了证明该算法的通用性,本文基于中国贵州省贵阳市的各种场景构建了一个无人机多目标检测数据集。该数据集是使用DJI Mavic 3模型无人机捕获的(如图12所示),无人机的详细参数如表5所示。在视角、等效焦距、光圈和像素这四个属性中,第一个参数与哈苏有关,第二个参数与Telephoto相机有关。


在数据收集过程中,主要考虑了环境(校园和城市)、密度(稀疏和拥挤的场景)、天气(晴天和阴天)以及物体和目标大小等因素。每张照片可能包含几到几十个要检测的物体。该数据集总共包含10000多个手动注释的边界框,有四个检测类别(人、摩托车、汽车和自行车),共906张。部分数据集展示如下:

在实验过程中,整个数据集被分为训练集(725个样本)和测试集(181个样本)。与VisDrone2019数据集一致,样本量被归一化为640×640进行训练和测试,并使用了表1中的训练参数。
第4.3节中验证了MobilNetv2 SSD不适合无人机多目标探测等复杂任务。因此,参考第4.3节,选择YOLOv4、YOLOv5-s、YOLOX-s、YOLOv7-minily和YOLOv8-s作为本节的比较对象。本文将YOLOv4-s、YOLOv5-s、YOLOX-s、YOLOv7-mining、YOLOv8-s命名为A、B、C、D、E和F。比较指标与消融实验表3中的指标一致,所有模型都不使用训练前权重进行训练。实验结果如表6和图14所示。

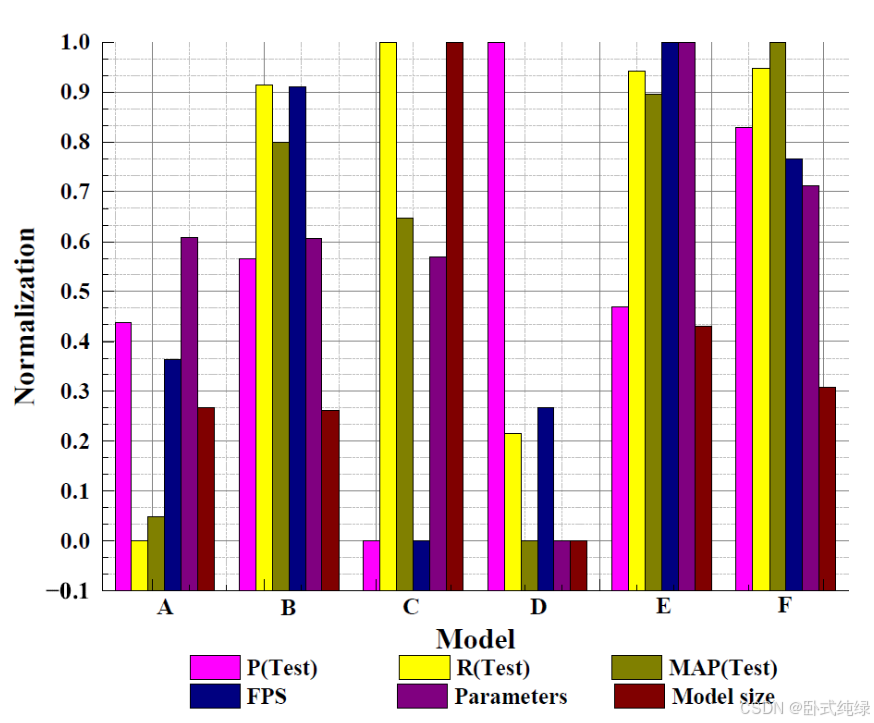
根据表6和图14中相关数据的综合分析,各模型的性能效果和比较结果可以总结如下:
- YOLOv4和YOLOv7-minily在自建数据集上的表现相似,在测试集上都获得了相对较低的映射值。虽然YOLOv7-minily的模型尺寸和参数数量相对最低,但其通用性能并不出色。然而,这两种模型仍然可以在精度要求不严格的情况下使用。两者的FPS都超过了150/f.s-1,并且能够部署在边缘设备中;
- YOLOv5-s、YOLOX-s和YOLOv8-s均取得了优异的结果,检测准确率大致相同,但YOLOv8-2s的准确率最高。在FPS方面,YOLOv5-s和YOLOv8-s均超过300/f.s-1,但YOLOX-s在该指标上未达到100,表明前两者在检测精度和速度方面具有相当大的优势;
- 本文中的模型在测试集的地图上领先原始YOLOv8-s近两个百分点,领先表现最差的YOLOv7微小18.4个百分点。同时,FPS达到294/f.s-1,实现了检测精度和速度之间的良好平衡。这也表明,本文的模型在各种场景和数据集中都取得了最佳的检测性能,具有很强的通用性。该模型在测试集上的部分检测性能如图15所示。可以看出,对于小目标,模型中基本没有漏检现象。然而,在某些情况下,可能会出现冗余的检测框,在少数情况下,类似的背景可能会被误认为目标。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









