







目录
一、视图
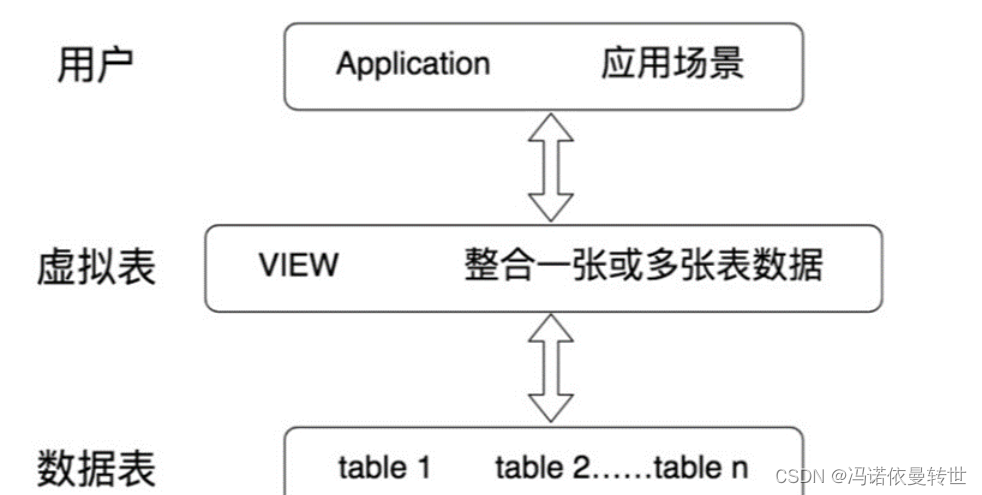
视图是从一个或者几个基本表(或视图)导出的表。它与基本表不同,是一个虚表。
- 视图的创建和删除只影响视图本身,不影响对应的基表。但是当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化,反之亦然。
- 在数据库中,视图不会保存数据,数据真正保存在数据表中。当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化;反之亦然。
- 视图,是向用户提供基表数据的另一种表现形式。通常情况下,小型项目的数据库可以不使用视图,但是在大型项目中,以及数据表比较复杂的情况下,视图的价值就凸显出来了,它可以帮助我们把经常查询的结果集放到虚拟表中,提升使用效率。理解和使用起来都非常方便
1. 为什么要使用视图
视图一方面可以帮我们使用
表的一部分而不是所有的表,另一方面也可以针对不同的用户制定不同的查询视图。比如,针对一个公司的销售人员,我们只想给他看部分数据,而某些特殊的数据,比如采购的价格,则不会提供给他。再比如,人员薪酬是个敏感的字段,那么只给某个级别以上的人员开放,其他
人的查询视图中则不提供这个字段。
刚才讲的只是视图的一个使用场景,实际上视图还有很多作用。最后,我们总结视图的优点。
2. 操作视图
创建视图
语法:
CREATE VIEW view_name as select ... 说明: • view_name 自己定义的视图名; • as 后面是这个视图说用到的查询结果;# 视图 -- 视图只能用来查询 -- 创建视图 -- create view 视图名【view_xxx/ v_xxx】 as select create view v_stu_man as select * from student where ssex = '男';视图的查询
查询所有的视图 select * from information_schema.VIEWS WHERE table_schema = ‘库名'; 视图可以当作一张表来使用,所以用正 常的select查询即可查看视图的建立
SHOW CREATE VIEW view_name删除存储过程
DROP VIEW view_name;使用:
如果修改了基本表的字段 视图的字段也会发生变化
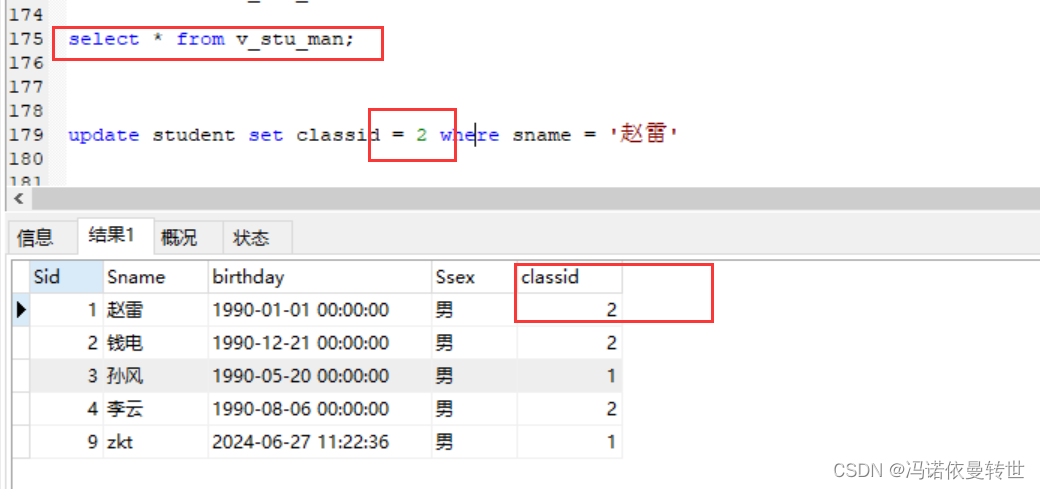
比如修改赵雷的班级为2
-- 视图的使用 当作一张表去用 select * from v_stu_man; update student set classid = 2 where sname = '赵雷'
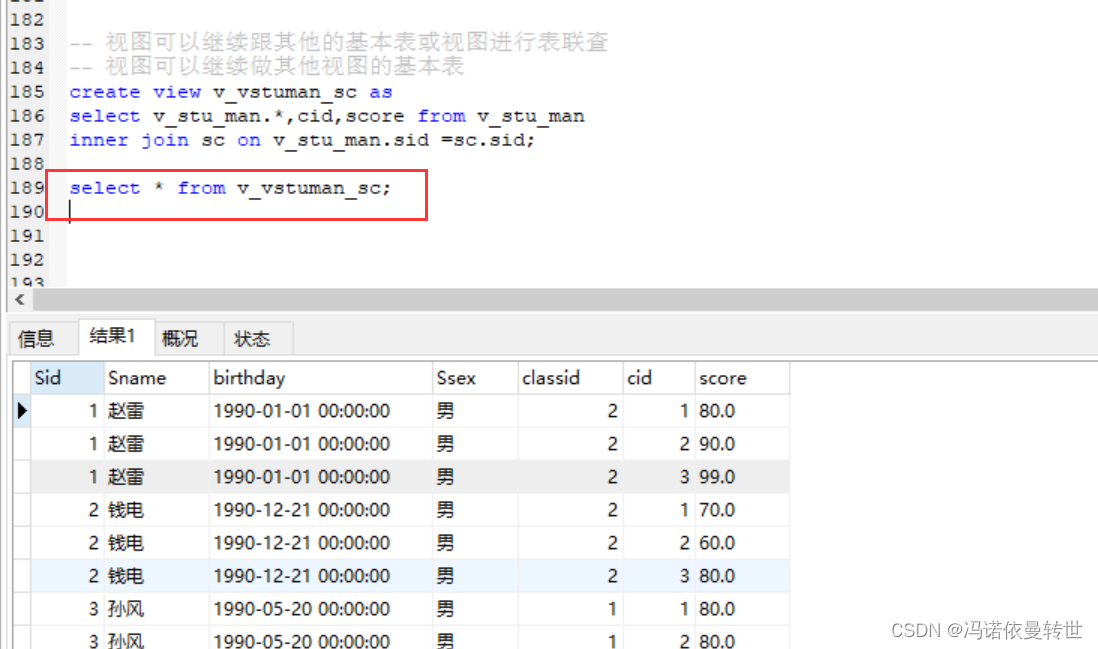
视图可以继续跟其他的基本表或视图进行表联查
视图可以继续做其他视图的基本表
-- 视图可以继续跟其他的基本表或视图进行表联查 -- 视图可以继续做其他视图的基本表 create view v_vstuman_sc as select v_stu_man.*,cid,score from v_stu_man inner join sc on v_stu_man.sid =sc.sid; select * from v_vstuman_sc;
3. 视图的优点
- 简化查询
- 重写格式化数据
- 频繁访问数据库
- 过滤数据
4. 视图的缺点
如果我们在实际数据表的基础上创建了视图,那么,
如果实际数据表的结构变更了,我们就需要及时对相关的视图进行相应的维护。特别是嵌套的视图(就是在视图的基础上创建视图),维护会变得比较复杂,可读性不好,容易变成系统的潜在隐患。因为创建视图的 SQL 查询可能会对字段重命名,也可能包含复杂的逻辑,这些都会增加维护的成本。实际项目中,如果视图过多,会导致数据库维护成本的问题。
所以,在创建视图的时候,你要结合实际项目需求,综合考虑视图的优点和不足,这样才能正确使用视图,使系统整体达到最优。
二、存储过程
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,存 储在数据库中,经过第一次编译后,再次调用不需要重复编译,用户通过指定存储过程的名字并给出参数 (如果该存储过程带有参数)来执行它。就是数据库 SQL 语言层面的代码封装与重用。
作用
- 业务流程复杂:业务复杂时,SQL语句相互依赖, 顺序执行;
- 频繁访问数据库:每条SQL语句都需单独连接和访 问数据库;
- 先编译后执行:SQL语句的执行需要先编译。

1. 用法
存储过程就类似于Java中的方法,需要先定义,使用时需要调用。存储过程可以定义参数,参数分为IN、OUT、INOUT类型三种类型。
- IN类型的参数表示接受调用者传入的数据;
- OUT类型的参数表示向调用者返回数据;
- INOUT类型的参数即可以接受调用者传入的参数,也可以向调用者返回数据。
创建存储过程
语法
CREATE PROCEDURE ( [ [IN |OUT |INOUT ] 参数名 数据类型…]) BEGIN DECLARE 变量 变量类型 END 说明: • '[ ]'内容不是必须的; • in:表示入参; • out:表示返回值; • inout:表示即是入参又是返回值。操作:
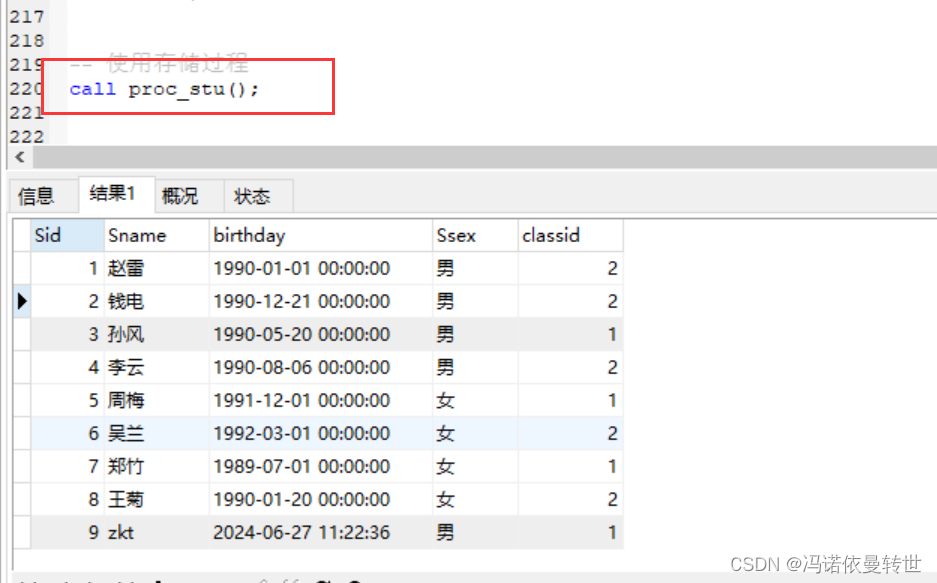
# 存储过程 -- 最简单的存储过程 -- create procedure 存储过程名【p_xxx/ proc_xxx】 -- (形参列表) -- begin -- # sql语句集 -- end -- 定义定界符 delimiter $$ create procedure proc_stu() begin select * from student; -- 失效 end $$ delimiter ; -- 恢复定界符使用存储过程:
-- 使用存储过程 call proc_stu();
带参的存储过程
-- 带参的存储过程 delimiter $$ create procedure proc_canshu( in num1 int, -- 10 in 只入参 out num2 int, -- null out 只出参 inout num3 int -- 1030 inout 出入参 ) begin set num1 = num1 + 1; set num2 = num2 + 100; set num3 = num3 + 1000; end $$ delimiter ; -- 环境变量 @xx 全局环境变量@@xx set @a = 10; -- 10 set @b = 20; -- null set @c = 30; -- 1030 select @a,@b,@c; call proc_canshu(@a,@b,@c); select @a,@b,@c;运行前:
运行后:
查看存储过程
SELECT * FROM information_schema.ROUTINES WHERE routine_schema=‘库名’删除存储过程
DROP PROCEDURE 存储过程名;
2. 存储过程与函数的区别
- 语法:关键字不同,存储过程是procedure, 函数是function;
- 执行:存储过程可以独立执行,函数必须依 赖表达式的调用;
- 返回值:存储过程可以定义多个返回结果, 函数只有一个返回值;
- 功能:函数不易做复杂的业务逻辑,但是存 储过程可以。
3. 面试题
写一个分页的存储过程
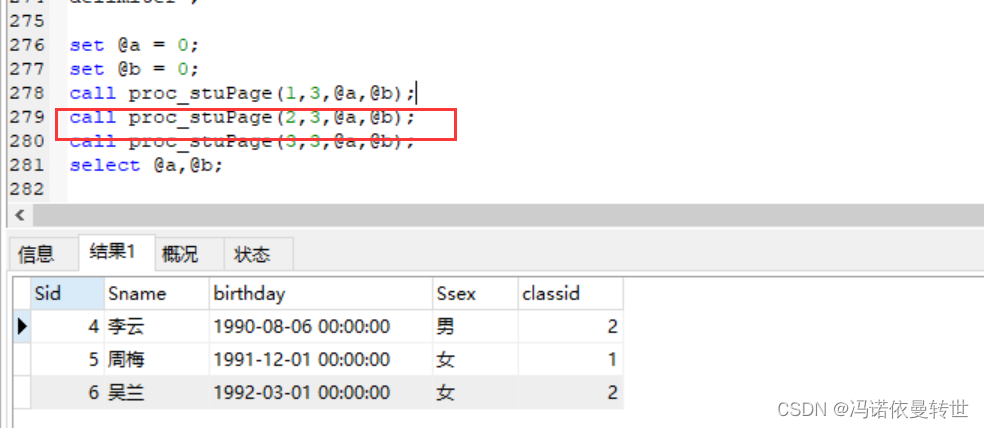
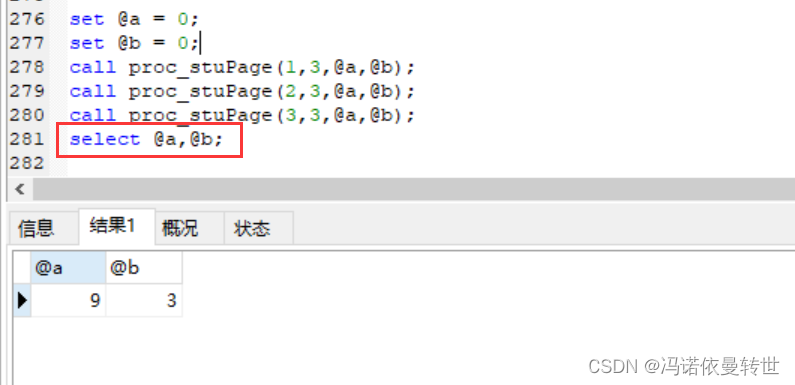
-- 面试题(分页) drop procedure proc_stuPage; delimiter $$ create procedure proc_stuPage( in curpage int, in sizepage int, out csum int, out psum int ) begin -- 定义变量 declare wz int; -- 变量赋值 set wz = (curpage-1)*sizepage; -- 查询出的一个结果赋值给变量 select count(*) from student into csum; -- 业务逻辑 set psum = ceiling(csum/sizepage); -- 分页 select * from student limit wz, sizepage; end $$ delimiter ; set @a = 0; set @b = 0; call proc_stuPage(1,3,@a,@b); call proc_stuPage(2,3,@a,@b); call proc_stuPage(3,3,@a,@b); select @a,@b;

4. 优点
存储过程是通过处理封装在容易使用的单元中,简化了复杂的操作。
简化对变动的管理。如果表名、列名、或业务逻辑有了变化。只需要更改存储过程的代码。使用它的人不用更改自己的代码。
通常存储过程都是有助于提高应用程序的性能。当创建的存储过程被编译之后,就存储在数据库中。
但是,MySQL实现的存储过程略有所不同。
MySQL存储过程是按需编译。在编译存储过程之后,MySQL将其放入缓存中。
MySQL为每个连接维护自己的存储过程高速缓存。如果应用程序在单个连接中多次使用存储过程,则使用编译版本,否则存储过程的工作方式类似于查询。存储过程有助于减少应用程序和数据库服务器之间的流量。
因为应运程序不必发送多个冗长的SQL语句,只用发送存储过程中的名称和参数即可。存储过程度任何应用程序都是可重用的和透明的。存储过程将数据库接口暴露给所有的应用程序,以方便开发人员不必开发存储过程中已支持的功能。
存储的程序是安全的。数据库管理员是可以向访问数据库中存储过程的应用程序授予适当的权限,而不是向基础数据库表提供任何权限。
做金融的公司会用到存储过程
5. 缺点
如果使用大量的存储过程,那么使用这些存储过程的每个连接的内存使用量将大大增加。
此外,如果在存储过程中过度使用大量的逻辑操作,那么CPU的使用率也在增加,因为MySQL数据库最初的设计就侧重于高效的查询,而不是逻辑运算。存储过程的构造使得开发具有了复杂的业务逻辑的存储过程变得困难。
很难调试存储过程。只有少数数据库管理系统允许调试存储过程。不幸的是,MySQL不提供调试存储过程的功能。
开发和维护存储过程都不容易。
开发和维护存储过程通常需要一个不是所有应用程序开发人员拥有的专业技能。这可能导致应用程序开发和维护阶段的问题。对数据库依赖程度较高,移值性差。
- 移植性:大多数关系型数据库的存储过程 存在细微差异。
- 协作性:没有相关的版本控制或者IDE,团 队中对于存储过程的使用大多是 依赖文档。
- 维护性:存储过程的维护成本高,修 改调试较为麻烦。
三、触发器(了解)
触发器是数据库中针对数据库表操作触发的 特殊的存储过程。

使用
语法:
CREATE TRIGGER 数据库名.触发器名 BEFORE/AFTER -- 触发顺序 INSERT/UPDATE/DELETE – 触发事件 ON 数据库.表名 -- 事件表 FOR EACH ROW BEGIN 触发器内容 -- 事件出发后要写的语句 END$$ 说明: • 触发器触发时间分为Before和After两种; • 主要针对表的增删改操作,可单独指定,也可全部指定。 • 查看所有的触发器 SELECT DISTINCT EVENT_OBJECT_TABLE FROM information_schema.`TRIGGERS` WHERE EVENT_OBJECT_SCHEMA=‘数据库名'使用
# 触发器 -- 创建 create trigger 触发器名【trig_xxx】 before/after -- 执行顺序 insert/update/delete -- 触发事件 on 表名 -- 哪张表发生事件 for each row -- 每一条数据都会触发 begin -- 触发后的一组sql语句 end -- 删除学生 , 成绩表 -- 删学生-相关的数据一并删掉 delimiter $$ create trigger trig_delstu_delsc before delete on student for each row begin -- old 已经存在的数据 new 还不存在的数据 delete from sc where sid = old.sid; end $$ delimiter ;-- 隐式执行, 所有的都必须是显示 delete from student where sname = '赵雷'; [SQL] delete from student where sname = '赵雷'; 受影响的行: 1 时间: 0.006ms删除学生 , 成绩表 -- 删学生-相关的数据一并删掉
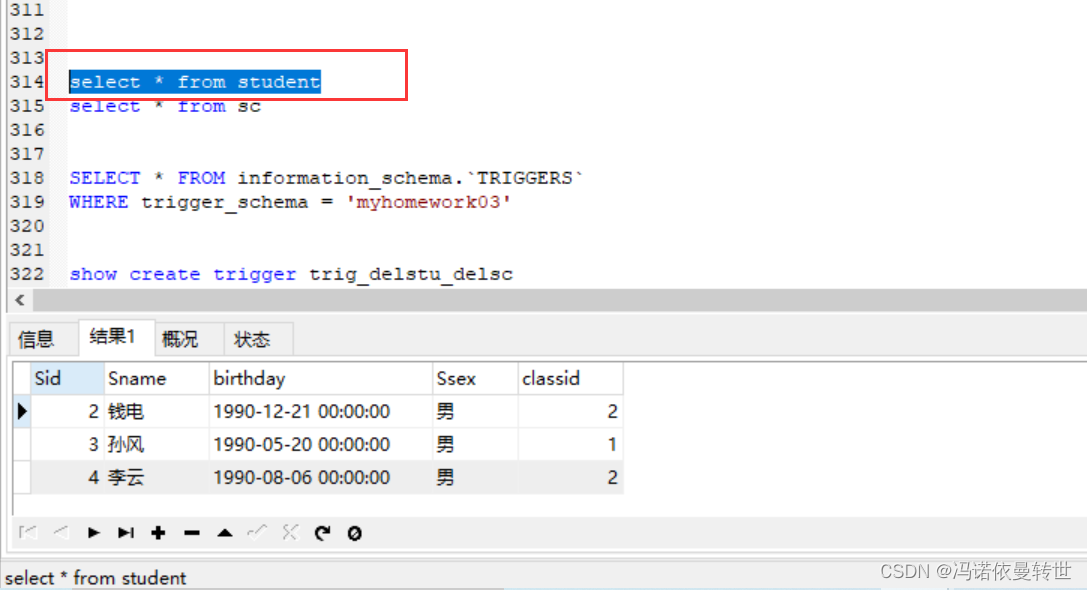
查看所有的触发器:
SELECT * FROM information_schema.`TRIGGERS` WHERE trigger_schema = ‘库名' SELECT * FROM information_schema.`TRIGGERS` WHERE trigger_schema = 'myhomework03'
删除触发器:
DROP TRIGGER 触发器名 drop trigger trig_delstu_delsc


存储过程和触发器的区别
- 语法:关键字不同,存储 过程是procedure, 触发器是trigger;
- 执行:存储过程需要调用才执 行,触发器自动执行;
- 返回值:存储过程可以定义返回值, 但是触发器没有返回值;
- 功能:存储过程是一组特定功能的 SQL语句,触发器则是SQL语 句前后执行,本身不影响原功 能。
















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











