







文章目录
前言
本文的有些概念参考了维基百科,有些图片也是来自于网络,这里贴上维基百科的链接供大家参考二叉搜索树 - 维基百科,自由的百科全书 (wikipedia.org)。
这篇文章的主要内容是介绍二叉搜索树的增删改查,作为平衡树的基础来学习。
需要完整代码的可以去访问我的Gitee仓库数据结构/BST/bst.h - 码云 - 开源中国 (gitee.com)
二叉搜索树
1.1 定义
二叉查找树(英语:Binary Search Tree),也称为二叉搜索树、有序二叉树(ordered binary tree)或排序二叉树(sorted binary tree),是指一棵空树或者具有下列性质的二叉树:
- 若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
- 若任意节点的右子树不空,则右子树上所有节点的值均大于它的根节点的值;
- 任意节点的左、右子树也分别为二叉查找树;
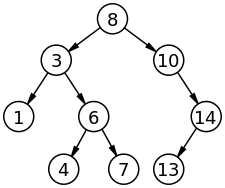
二叉查找树相比于其他数据结构的优势在于查找、插入的时间复杂度较低。为。二叉查找树是基础性数据结构,用于构建更为抽象的数据结构,如集合、多重集、关联数组等。
二、二叉搜索树基本结构
2.1 搜索树的节点
二叉搜索树节点通常采用的是二叉链结构,就是一个指针指向左孩子一个指针指向右孩子。
//树节点
template <class K>
struct BSTNode
{
BSTNode<K> *_left;
BSTNode<K> *_right;
K _key; // 这里也可以使用其他类型
//节点构造函数
BSTNode(const K &key)
: _left(nullptr)
, _right(nullptr)
, _key(key)
{
}
};
2.2 构建树的结构
template <class K>
class BSTree
{
typedef BSTNode<K> Node;
private:
Node *_root = nullptr; // 定义根节点指针
};
三、二叉搜索树的具体实现
3.1 插入节点
结合对二叉搜索树的定义可以有,左孩子是小于父亲,右孩子是大于父亲,所以可以根据这个来快速查询节点的插入位置。下面来看看代码。
插入的步骤:
- 找到插入位置
- 连接节点
//插入节点
bool Insert(const K& key)
{
//如果根节点为空,直接插入
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
//查找插入位置
Node *parent = nullptr; // 需要记录父节点的位置,便于插入
Node *cur = _root;
while (cur)
{
//比父节点小,去左边查找
if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
//比父节点大,去右边查找
else if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else //不允许数据冗余
{
return false;
}
}
//创建新节点
cur = new Node(key);
//找插入位置
//待插入节点的值是小于父亲,就插入在父亲的左边,否则就插入在有右边
if (parent->_key > cur->_key)
parent->_left = cur;
else
parent->_right = cur;
return true;
}
3.2 查询节点
查找的逻辑和上面的寻找插入节点的位置是一样的,根据左孩子比父亲小,右孩子比父亲大。看看代码实现。
Node *Find(const K &key)
{
Node *cur = _root;
while (cur)
{
//key小于父亲,去左孩子查找
if (cur->_key > key)
cur = cur->_left;
//key大于父亲,去右孩子查找
else if (cur->_key < key)
cur = cur->_right;
//找到了返回节点指针
else
return cur;
}
//没找到返返回空
return nullptr;
}
3.3 删除节点(⭐️)
在二叉查找树删去一个结点,分三种情况讨论:
- 若*p结点为叶子结点,即PL(左子树)和PR(右子树)均为空树。由于删去叶子结点不破坏整棵树的结构,则只需修改其双亲结点的指针即可。
- 若p结点只有左子树PL或右子树PR,此时只要令PL或PR直接成为其双亲结点f的左子树(当p是左子树)或右子树(当p是右子树)即可,作此修改也不破坏二叉查找树的特性。
- 若*p结点的左子树和右子树均不空。为了保证二叉搜索树的结构不被破坏,可以通过寻找替代节点的方式来解决,那么如何来寻找替代节点呢?两种选择,左子树的最大值或者右子树的最小值。当取这两个值来替代时,恰好就可以满足搜索树的结构不变。
这里选用右子树的最小值,由二叉搜索树的定义可知,右子树的所有值都是大于左子树的所有值,所以当右子树的最小值放到父节点,也是满足左子树的所有值都是小于右子树的所有值,并且父节点的值为中间值。同理,取左子树的最大值也是一样。
下面的图片是将用左子树的最大值演示的,和右子树的最小值,原理是一样的。

下面来看代码实现
//删除
bool Erase(const K &key) //删除掉节点,并且删除后保证结构不被破坏
{
Node *parent = nullptr;
Node *cur = _root;
//寻找待删除节点
while (cur)
{
if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
//找到了要删除的节点
else
{
// 1.处理只有单个子节点的情况和叶子节点的情况
//1.1 处理左子树为空的情况
if (cur->_left == nullptr)
{
//处理删除根节点的情况
if (cur == _root)
{
_root = cur->_right;
}
else
{
//直接将parent指向cur的孩子,不过要注意指向,保证书的结构不被破坏
if (cur == parent->_left)
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_right;
}
}
//释放节点
delete cur;
}
//1.2 处理右子树为空的情况
else if (cur->_right == nullptr)
{
//处理删除根节点的情况
if (cur == _root)
{
_root = cur->_left;
}
else
{
//直接将parent指向cur的孩子,不过要注意指向,保证书的结构不被破坏
if (cur == parent->_left)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
//释放节点
delete cur;
}
// 2.有两个子节点,
//替代法删除,可以找待删除节点的右子树的最小值或者左子树的最大值来替代待删除节点,然后删除
else
{
Node *minRightParent = cur; //不能给nullptr,防止没进循环,造成空指针访问节点
Node *minRight = cur->_right;
//找到右子树的最小值
while (minRight->_left)
{
minRightParent = minRight;
minRight = minRight->_left;
}
//将右子树的最小值拷贝到cur上
cur->_key = minRight->_key;
// minRight的_left一定为空
// minRight有可能为paernt的左,也有可能为parent的右
//像上面删除掉单个节点一样,删除掉minRight
if (minRight == minRightParent->_left)
minRightParent->_left = minRight->_right;
else
minRightParent->_right = minRight->_right;
//释放掉节点
delete minRight;
}
return true;
}
}
return false;
}
3.4 二叉搜索树的遍历
由二叉搜索树的基本性质来看,可以发现二叉搜索树的中序遍历一定得到的是一个有序的序列。
//中序遍历
void InOrder()
{
//为了防止在外面寻找根节点,造成效率降低,所以直接外包一个就可以
//中序遍历
_InOrder(_root);
cout << endl;
}
//内置中序遍历函数, 建议放到private
void _InOrder(Node *root)
{
if (root != nullptr)
{
_InOrder(root->_left);
cout << root->_key << ' ';
_InOrder(root->_right);
}
}
四、二叉搜索树的性能分析和优化
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,则比较次数越多。但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树。

最优情况下,二叉搜索树为完全二叉树,其平均比较次数为:
l
o
g
2
N
log_2N
log2N。
最差情况下,二叉搜索树退化为单支树,其平均比较次数为:
N
/
2
N/2
N/2。
问题:如果退化成单支树,二叉搜索树的性能就失去了。那能否进行改进,不论按照什么次序插入关键码,都可以是二叉搜索树的性能最佳?
一般的二叉查找树的查询复杂度取决于目标结点到树根的距离(即深度),因此当结点的深度普遍较大时,查询的均摊复杂度会上升。为了实现更高效的查询,产生了平衡树。在这里,平衡指所有叶子的深度趋于平衡,更广义的是指在树上所有可能查找的均摊复杂度偏低。
五、总结
二叉搜索树只是一个平衡树的引子,因为效率的问题,实际上二叉搜索树用的并不多,但是对于学习来说,是具有很大的意义的。二叉搜索树是后面平衡树的一个基础,对二叉搜索树充分了解,后面的平衡树也就可以很好的理解。
后面会出两篇博客专门介绍两种经典的平衡树,AVL树和红黑树,了解平衡树的具体实现和实现重难点在哪里。















 873
873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









