







目录
3.1 ElasticSearch vs Lucene的关系
⼀、搜索引擎介绍
在互联⽹项⽬中,涉及到检索的业务需求很多,我们可以通过对数据库的模糊查询实现
检索功能,但是针对⼤数据量的操作,基于数据库的检索就显得⼒不从⼼了(查询效率
很低)。所需我们要寻求⼀种⾼效的数据检索解决⽅案。
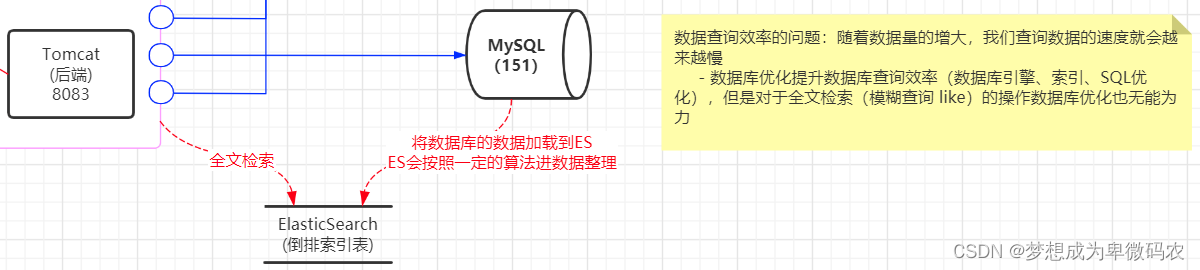
所谓搜索引擎,就是根据⽤户需求与⼀定算法,运⽤特定策略从互联⽹检索出指定的信息反
馈给⽤户的⼀⻔检索技术。搜索引擎依托于多种技术,如⽹络爬⾍技术、检索排序技术、⽹
⻚处理技术、⼤数据处理技术、⾃然语⾔处理技术等,为信息检索⽤户提供快速、⾼相关性
的信息服务。搜索引擎技术的核⼼模块⼀般包括爬⾍、索引、检索和排序等,同时可添加其
他⼀系列辅助模块,以为⽤户创造更好的⽹络使⽤环境
搜索⽅式
搜索⽅式是搜索引擎的⼀个关键环节,⼤致可分为四种:
全⽂搜索引擎
、
元搜索引擎
、
垂直
搜索引擎
和
⽬录搜索引擎
,它们各有特点并适⽤于不同的搜索环境
⼆、Lucene简介
2.1 Doug Cutting
1997
年底,
Cutting
开始以每周两天的时间投⼊,在家⾥试着⽤
Java
把这个想法变成现实,不
久之后,
Lucene
诞⽣了。作为第⼀个提供全⽂⽂本搜索的开源函数库,
Lucene
的伟⼤⾃不必
多⾔。
2.2 Lucene介绍
Lucene
是
Apache Jakarta
家族中的⼀个开源项⽬,是⼀个开放源代码的全⽂检索引擎⼯
具包,但它不是⼀个完整的 全⽂检索引擎,⽽是⼀个全⽂检索引擎的架构,提供了完整
的查询引擎、索引引擎和部分⽂本分析引擎。
Lucene
提供了⼀个简单却强⼤的应⽤程式接⼝,能够做全⽂索引和搜寻。在
Java
开发环
境⾥
Lucene
是⼀个成熟的免费开源⼯具,是⽬前最为流⾏的基于
Java
开源全⽂检索⼯
具包。
- 数据总体分为两种:
- 结构化数据:指具有固定格式或有限⻓度的数据,如数据库、元数据等
- ⾮结构化数据:指不定⻓或⽆固定格式的数据,如邮件、word⽂档等磁盘上的⽂件
- 对于结构化数据的全⽂搜索很简单,因为数据都是有固定格式的,例如搜索数据库中数 据使⽤SQL语句即可
- 对于⾮结构化数据,有以下两种⽅法:
- 顺序扫描法(Serial Scanning)
- 全⽂检索(Full-text Search)
顺序扫描法
:如果要找包含某⼀特定内容的⽂件,对于每⼀个⽂档,从头到尾扫描内容,如
果此⽂档包含此字符串, 则此⽂档为我们要找的⽂件,接着看下⼀个⽂件,直到扫描完所有
的⽂件,因此速度很慢。
全⽂检索
:将⾮结构化数据中的⼀部分信息提取出来,重新组织,使其变得具有⼀定结构,
然后对此有⼀定结构的数 据进⾏搜索,从⽽达到搜索相对较快的⽬的。这部分从⾮结构化数
据中提取出的然后重新组织的信息,我们称之索引。
2.3 Lucene全⽂检索流程

创建索引过程,对要搜索的原始内容进⾏索引构建⼀个索引库。索引过程包括:确定原
始内容即要搜索的内容
→
采集⽂档
→
创建⽂档
→
分析⽂档
→
索引⽂档。
搜索索引过程,从索引库中搜索内容。搜索过程包括:⽤户通过搜索界⾯
→
创建查询
→
执⾏搜索,从索引库搜索
→
渲染搜索结果。
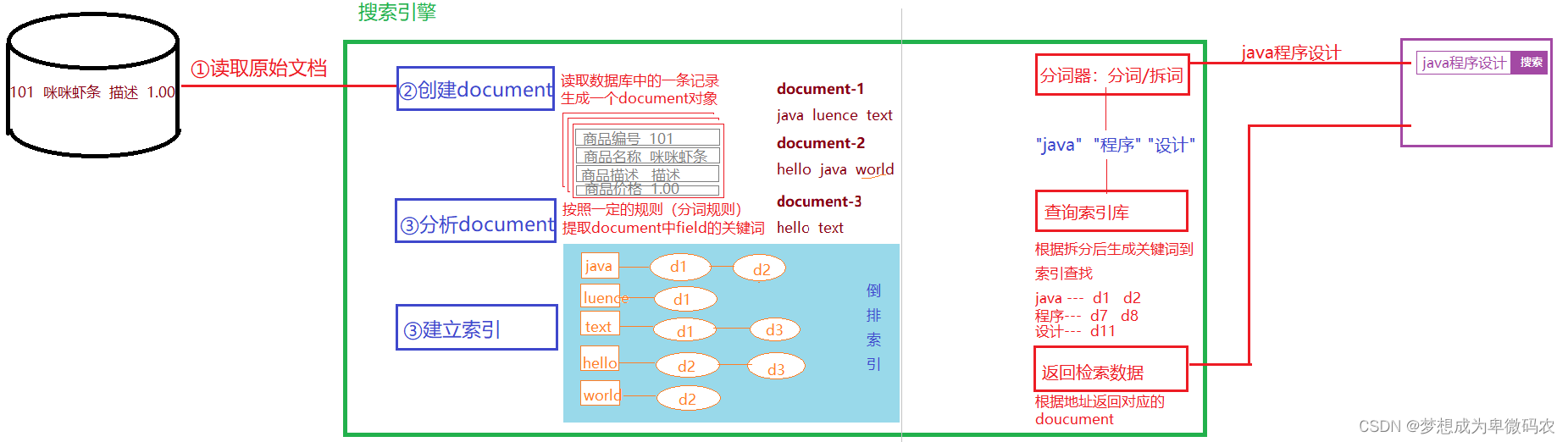
2.3.1 创建索引
对⽂档索引的过程,将⽤户要搜索的⽂档内容进⾏索引,索引存储在索引库(
index
)中。
这⾥我们要搜索的⽂档是 磁盘上的⽂本⽂件,根据案例描述:凡是⽂件名或⽂件内容包括关
键字的⽂件都要找出来,这⾥要对⽂件名和⽂件内 容创建索引。
- 获得原始⽂档
原始⽂档是指要索引和搜索的内容。原始内容包括互联⽹上的⽹⻚、数据库中的数据、
磁盘上的⽂件等。
- 创建⽂档对象
获取原始内容的⽬的是为了索引,在索引前需要将原始内容创建成⽂档(
Document
),
⽂档中包括⼀个⼀个的域 (
Field
),域中存储内容。 这⾥我们可以将磁盘上的⼀个⽂件
当成⼀个
document
,
Document
中包括⼀些
Field
(fifile_name
⽂件名称、
fifi
le_path
⽂件
路径、
fifi
le_size
⽂件⼤⼩、
fifi
le_content
⽂件内容),如下图:

注意:
- 每个Document可以有多个Field,不同的Document可以有不同的Field
- 每个⽂档都有⼀个唯⼀的编号,就是⽂档id。
- 分析⽂档
将原始内容创建为包含域(
Field
)的⽂档(
document
),需要再对域中的内容进⾏分
析,分析的过程是经过对原始⽂档提取单词、将字⺟转为⼩写、去除标点符号、去除停
⽤词等过程⽣成最终的语汇单元,可以将语汇单元理解为⼀ 个⼀个的单词。 ⽐如下边的
⽂档经过分析如下:
原⽂档内容:
Lucene is a Java full-text search engine. Lucene is not a completeapplication, but rather a code library and API that can easily beused to add search capabilities to applications.
分析后得到的语汇单元:
lucene 、 java 、 full 、 search 、 engine...
每个单词叫做⼀个
Term
,不同的域中拆分出来的相同的单词是不同的
term
。
term
中包
含两部分⼀部分是⽂档的域名,另⼀部分是单词的内容。 例如:⽂件名中包含
apache
和
⽂件内容中包含的
apache
是不同的
term
。
- 创建索引—倒排索引
对所有⽂档分析得出的语汇单元进⾏索引,索引的⽬的是为了搜索,最终要实现只搜索
被索引的语汇单元从⽽找到
Document
(⽂档)

注意:创建索引是对语汇单元索引,通过词语找⽂档,这种索引的结构叫倒排索引结
构。 传统⽅法是根据⽂件找到 该⽂件的内容,在⽂件内容中匹配搜索关键字,这种⽅法
是顺序扫描⽅法,数据量⼤、搜索慢。 倒排索引结构是根 据内容(词语)找⽂档,如下
图:
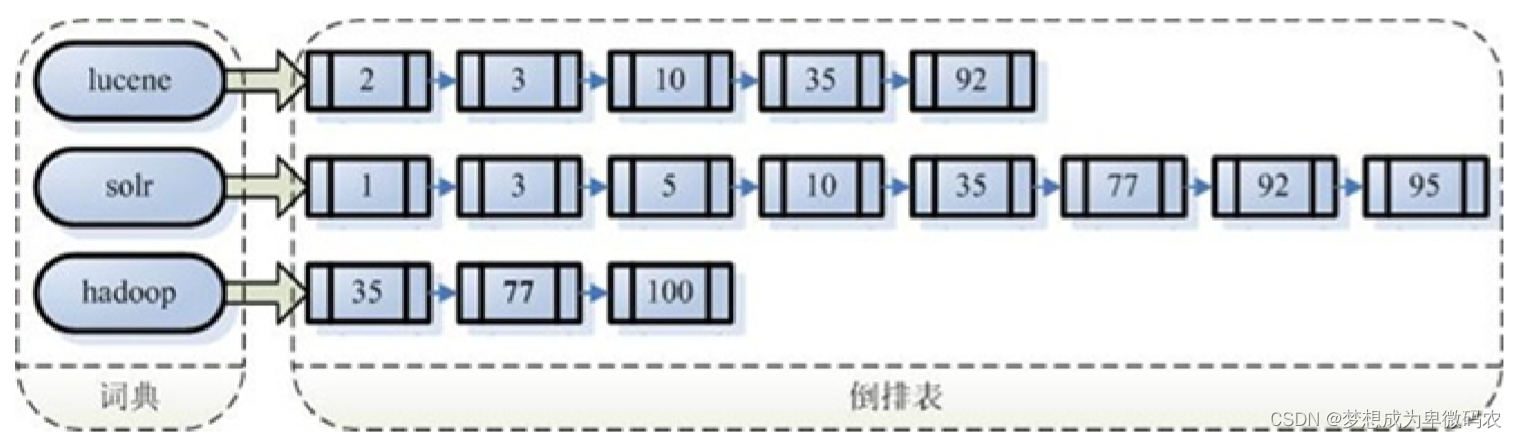
倒排索引结构也叫反向索引结构,包括索引和⽂档两部分,索引即词汇表,它的规模较
⼩,⽽⽂档集合较⼤。
2.3.2 查询索引
查询索引也是搜索的过程。搜索就是⽤户输⼊关键字,从索引(
index
)中进⾏搜索的过程。
根据关键字搜索索引, 根据索引找到对应的⽂档,从⽽找到要搜索的内容(这⾥指磁盘上的
⽂件)。
- ⽤户查询接⼝
全⽂检索系统提供⽤户搜索的界⾯供⽤户提交搜索的关键字,搜索完成展示搜索结果。
Lucene
不提供制作⽤户搜索界⾯的功能,需要根据⾃⼰的需求开发搜索界⾯。
- 创建查询
⽤户输⼊查询关键字执⾏搜索之前需要先构建⼀个查询对象,查询对象中可以指定查询
要搜索的
Field
⽂档域、查询关键字等,查询对象会⽣成具体的查询语法,例如: 语法
“
fifi
leName:lucene”
表示要搜索
Field
域的内容为
“lucene”
的⽂档
- 执⾏查询
搜索索引过程: 根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从⽽找
到索引所链接的⽂档链表。 ⽐如搜索语法为
“
fifi
leName:lucene”
表示搜索出
fifi
leName
域中
包含
Lucene
的⽂档。 搜索过程就是在索引上查找域为
fifi
leName
,并且关键字为
Lucene
的
term
,并根据
term
找到⽂档
id
列表。
- 渲染查询结果
以⼀个友好的界⾯将查询结果展示给⽤户,⽤户根据搜索结果找⾃⼰想要的信息,为了
帮助⽤户很快找到⾃⼰的结 果,提供了很多展示的效果,⽐如搜索结果中将关键字⾼亮
显示,百度提供的快照等。
2.4 分词器
2.4.1 分词器的作⽤
a.
在创建索引的时候需要⽤到分词器,在使⽤字符串搜索的时候也会⽤到分词器,并且这两
个地⽅要使⽤同⼀个 分词器,否则可能会搜索不出来结果。
b.
分词器
(Analyzer)
的作⽤是把⼀段⽂本中的词按规则取出所包含的所有词,对应的是
Analyzer
类,这是⼀个抽 象类
(public abstract class
org.apache.lucene.analysis.Analyzer)
,切分词的具体规则是由⼦类实现的,所以对于不 同
的语⾔规则,要有不同的分词器。
2.4.2 英⽂分词器的原理
a.
英⽂的处理流程为:输⼊⽂本,词汇切分,词汇过滤
(
去除停⽤词
)
,词⼲提取
(
形态还原
)
、
⼤写转⼩写,结果输 出。
b.
何为形态还原,意思是:去除单词词尾的形态变化,将其还原为词的原形,这样做可以搜
索出更多有意义的结 果,⽐如在搜索
student
的时候,同事也可以搜索出
students
的结果。
c.
任何⼀个分词法对英⽂的⽀持都是还可以的。
2.4.3 中⽂分词器的原理
中⽂分词⽐较复杂,并没有英⽂分词那么简单,这主要是因为中⽂的词与词之间并不是像英
⽂那样⽤空格来隔 开,因为不是⼀个字就是⼀个词,⽽且⼀个词在另外⼀个地⽅就可能不是
⼀个词,如:
"
我们是中国⼈
"
,
"
是中
"
就不是⼀ 个词,对于中⽂分词,通常有三种⽅式:单
字分词、⼆分法分词、词典分词。
- 单字分词:就是按照中⽂⼀个字⼀个字的进⾏分词,⽐如:"我们是中国⼈",分词的效果 就是"我","们","是","中","国","⼈",StandardAnalyzer分词法就是单字分词。
- ⼆分法分词:按照两个字进⾏切分,⽐如:"我们是中国⼈",分词的效果就是:"我 们","们是","是 中","中国","国⼈",CJKAnalyzer分词法就是⼆分法分词
- 词库分词:按照某种算法构造词,然后去匹配已建好的词库集合,如果匹配到就切分出 来成为词语,通常词 库分词被认为是最好的中⽂分词算法,如:"我们是中国⼈",分词的效果就是:"我们","中国⼈",极易分词 MMAnalyzer、庖丁分词、IkAnalyzer等分词法 就是属于词库分词。
2.4.4 停⽤词的规
有些词在⽂本中出现的频率⾮常⾼,但是对⽂本所携带的信息基本不产⽣影响,例如英⽂
的
"a
、
an
、
the
、
of"
或中⽂ 的
"
的、了、着、是
"
,以及各种标点符号等,这样的词称为停⽤
词,⽂本经过分词处理后,停⽤词通常会被过滤掉, 不会被进⾏索引,在检索的时候,⽤户
的查询中如果含有停⽤词,检索系统也会将其过滤掉,这是因为⽤户输⼊查询字符串也要进
⾏分词处理,排除停⽤词可以提升建⽴索引的速度,减⼩索引库⽂件的⼤⼩。
2.4.5 常⽤分词器
- WhitespaceAnalyzer
仅仅是去掉了空格,没有其他任何操作,不⽀持中⽂。
- SimpleAnalyzer
将除了字⺟以外的符号全部去除,并且将所有字符变为⼩写,需要注意的是这个分词器
同样把数据也去除了,同样不⽀持中⽂。
- StopAnalyzer
这个和SimpleAnalyzer
类似,不过⽐他增加了⼀个的是,在其基础上还去除了所谓的
stop words,⽐如
the, a, this
这些。这个也是不⽀持中⽂的。
- StandardAnalyzer
英⽂⽅⾯的处理和StopAnalyzer
⼀样的,对中⽂⽀持,使⽤的是单字切割。
- CJKAnalyzer
这个⽀持中⽇韩,前三个字⺟也就是这三个国家的缩写。这个对于中⽂基本上不怎么⽤
吧,对中⽂的⽀持很烂,它是 ⽤每两个字作为分割,分割⽅式个⼈感觉⽐较奇葩,我会
在下⾯⽐较举例。
- SmartChineseAnalyzer
中⽂的分词,
⽐较标准的中⽂分词,对⼀些搜索处理的并不是很好。
- IKAnalyzer
中国⼈⾃⼰开发,对于中⽂分词⽐较精准
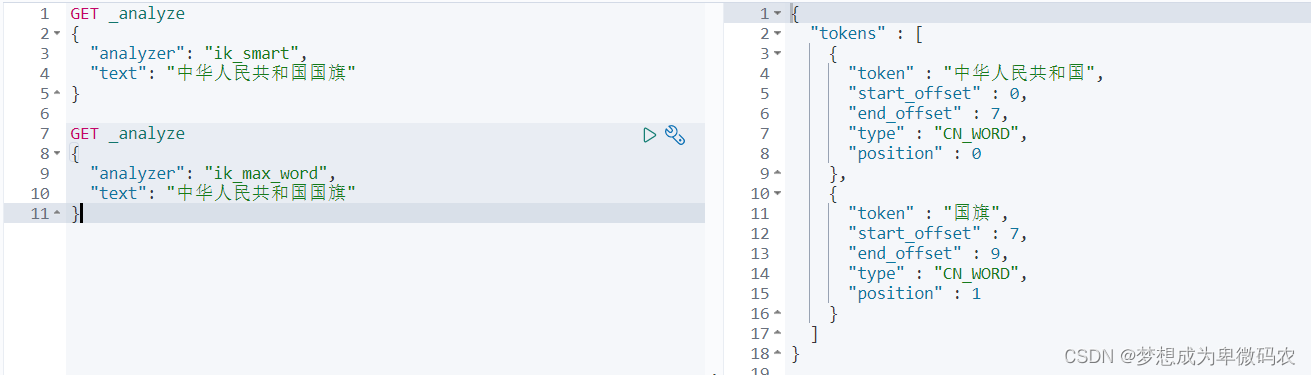
2.4.6 IK 分词器
Elasticsearch
中⽂分词我们采⽤
Ik
分词,
ik
有两种分词模式:
ik_max_word
和
ik_smart
模式
;
ik_max_word
和
ik_smart
什么区别
?
- ik_max_word: 会将⽂本做最细粒度的拆分,⽐如会将“中华⼈⺠共和国国歌”拆分为“中华 ⼈⺠共和国,中华⼈⺠, 中华,华⼈,⼈⺠共和国,⼈⺠,⼈,⺠,共和国,共和,和国,国歌”,会穷尽 各种可能的组合;
- ik_smart: 会做最粗粒度的拆分,⽐如会将“中华⼈⺠共和国国歌”拆分为“中华⼈⺠,共和 国,国歌”。 索引时,为了提供索引的覆盖范围,通常会采⽤ik_max_word分析器,会以 最细粒度分词索引,搜索时为了提⾼搜索准确度,会采⽤ik_smart分析器,会以粗粒度 分词
我们可以使⽤⽹上的⼀些⼯具查看分词的效果,⽐如
https://www.sojson.com/analyzer
2.5 lucene全⽂检索与数据库查询的⽐较
2.5.1 性能上
数据库
:⽐如我要查找某个商品,根据商品名,⽐如
select * from product where
doctname like %keywords%,
这 样查询的话对于数据量少是可以的,可是⼀旦你的数据量巨
⼤⼏万⼏⼗万的时候,你的性能将会极⼤的减弱。
lucene
:
全⽂检索,建⽴⼀个索引库,⼀次建⽴多次使⽤。在索引库⾥⾯会把所有的商品名
根据分词器建⽴索引,就 好⽐新华字典,索引对应
document
,⽐如输⼊衬衫,那么就会根
据索引迅速的翻到衬衫对应的商品名,时间迅速, 性能很好。
2.4.2 相关度排序
数据库
:数据库要实现该功能也是可以的,可是需要改变表的结构,添加⼀个字段,然后该
字段⽤于排名,最后查询 的时候
order by
⼀下
lucene
:
查询出来的
document
都有⼀个算法(得分),根据算法可以计算得分,得分越⾼的
排名越靠前,⽐如百度 搜索⼀个东⻄,⼀般排名靠前的得分越⾼,得分通过算法,可以⼈⼯
控制,⽐如百度推⼴,企业给的钱多得分⾃然 ⾼,因此排名靠前
2.4.3 准确性
数据库
:
select * from product where doctname like %ant%,
搜索出来的可以是
plant,aplant,planting
等等,准确性不⾼
lucene
:通过索引查询的,就好像你查字典⼀样,准确性⽐数据库的模糊查询⾼许多
三、ElasticSearch简介
3.1 ElasticSearch vs Lucene的关系
ElasticSearch vs Lucene
的关系,简单⼀句话就是,成品与半成品的关系。
(1)
Lucene
专注于搜索底层的建设,⽽
ElasticSearch
专注于企业应⽤。
(2)
Luncene
是单节点的
API
,
ElasticSearch
是分布式的
—
为集群⽽⽣。
(3)
Luncene
需要⼆次开发,才能使⽤。不能像百度或⾕歌⼀样,它只是提供⼀个接⼝
需要被实现才能使⽤
, ElasticSearch
直接拿来⽤。
3.2 ElasticSearch与Solr对⽐
- Solr与elasticsearch是当前两⼤最流⾏的搜索应⽤服务器,他们的底层都是基于lucene。 Elasticsearch是分布式的,不需要其他组件,Solr 利⽤ Zookeeper 进⾏分布式管理,⽽ Elasticsearch ⾃身带 有分布式协调管理功能
- Elasticsearch设计⽤于云计算中,处理多租户不需要特殊配置,⽽Solr则需要更多的⾼级 设置。
- 当单纯的对已有数据进⾏搜索时,Solr更快,实时建⽴索引时, Solr会产⽣io阻塞,查询 性能较差, Elasticsearch 具有明显的优势,随着数据量的增加,Solr的搜索效率会变得更 低,⽽Elasticsearch却没有明显的变化
Elasticsearch
与
Solr
的性能测试⽐较
:
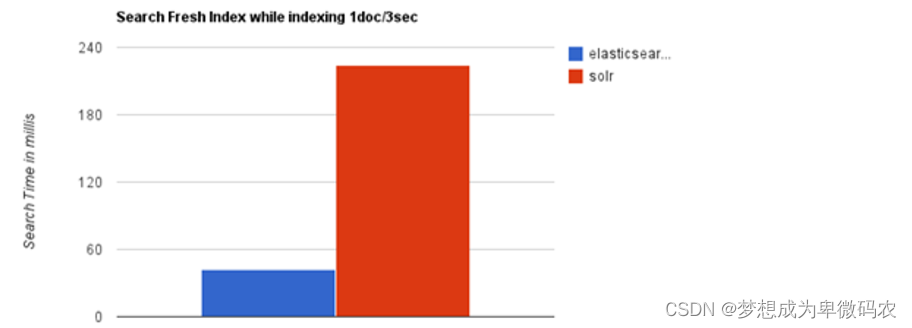
当单纯的对已有数据进⾏搜索时,
Solr
更快
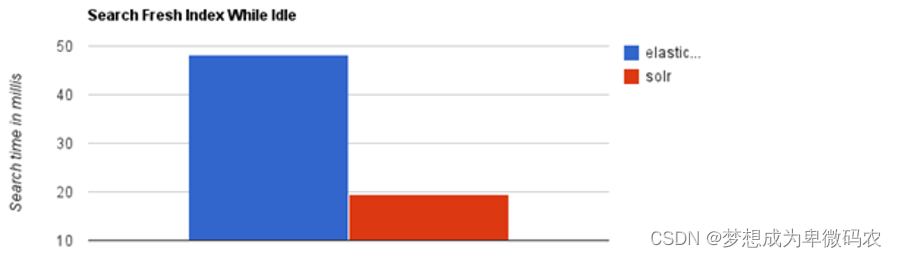
当实时建⽴索引时
, Solr
会产⽣
io
阻塞,查询性能较差
, Elasticsearch
具有明显的优势
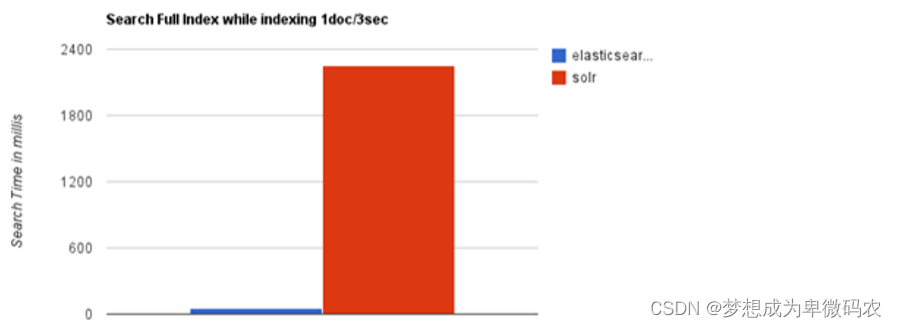
随着数据量的增加,
Solr
的搜索效率会变得更低,⽽
Elasticsearch
却没有明显的变化
3.3 Elasticsearch特性
3.3.1 安装管理⽅便
Elasticsearch
没有其他依赖,下载后安装⾮常⽅便;只⽤修改⼏个参数就可以搭建起来⼀个
集群。
3.3.2 ⼤规模分布式
Elasticsearch
允许你开始⼩规模使⽤,但是随着你使⽤数据的增⻓,它可以建⽴在横向扩展
的开箱即⽤。当你需要更多的容量,只需添加更多的节点,并让集群重组,只需要增加额外
的硬件,让集群⾃动利⽤额外的硬件。
可以在数以百计的服务器上处理
PB
级别的数据
。
节点对外表现对等(每个节点都可以⽤来做⼊⼝);加⼊节点⾃动均衡,可以扩展到上百台
服务器,处理
PB
级别的 结构化或⾮结构化数据。
Elasticsearch
致⼒于隐藏分布式系统的复杂性。以下这些操作都是在底层⾃动完成的:
- 将你的⽂档分区到不同的容器或者分⽚(shards)中,它们可以存在于⼀个或多个节点中;
- 将分⽚均匀的分配到各个节点,对索引和搜索做负载均衡;
- 冗余每⼀个分⽚,防⽌硬件故障造成的数据丢失;
- 将集群中任意⼀个节点上的请求路由到相应数据所在的节点;
- ⽆论是增加节点,还是移除节点,分⽚都可以做到⽆缝的扩展和迁移
3.3.3 多租户⽀持
ES
处理多租户不需要特殊配置,可根据不同的⽤途分索引;可以同时操作多个索引。
ES
的多租户简单的说就是通过多索引机制同时提供给多种业务使⽤,每种业务使⽤⼀个索
引。我们可以把索引理解 为关系型数据库⾥的库,那多索引可以理解为⼀个数据库系统建⽴
多个库给不同的业务使⽤。
在实际使⽤时,我们可以通过每个租户⼀个索引的⽅式将他们的数据进⾏隔离,并且每个索
引是可以单独配置参数的 (可对特定租户进⾏调优),这在典型的多租户场景下⾮常有⽤:
例如我们的⼀个多租户应⽤需要提供搜索⽀持,这 时可以通过
ES
根据租户建⽴索引,这样
每个租户就可以在⾃⼰的索引下搜索相关内容了
3.3.4 ⾼可⽤性
Elasticsearch
集群是有弹性的
-
他们会⾃动检测到新的或失败的节点,以及重组和重新平衡
数据,以确保数据安全。
3.3.5 操作持久化
Elasticsearch
把数据安全第⼀。⽂档改变被记录在群集上的多个节点上的事务⽇志
(transaction logs)
中记录,以减少 任何数据丢失的机会。
3.3.6 友好的RESTful API
Elasticsearch
是
API
驱动。⼏乎任何动作都可以⽤⼀个简单的
RESTful API
使⽤
JSON
基于
HTTP
请求。
ElasticSearch
提 供多种语⾔的客户端
API
。
3.4 典型使⽤案例
- 维基百科使⽤Elasticsearch来进⾏全⽂搜做并⾼亮显示关键词,以及提供search-as-youtype、did-you-mean 等搜索建议功能。
- 英国卫报使⽤Elasticsearch来处理访客⽇志,以便能将公众对不同⽂章的反应实时地反 馈给各位编辑。
- StackOverflflow将全⽂搜索与地理位置和相关信息进⾏结合,以提供more-like-this相关 问题的展现。
- GitHub使⽤Elasticsearch来检索超过1300亿⾏代码。
- Goldman Sachs使⽤它来处理5TB数据的索引,还有很多投⾏使⽤它来分析股票市场的 变动。
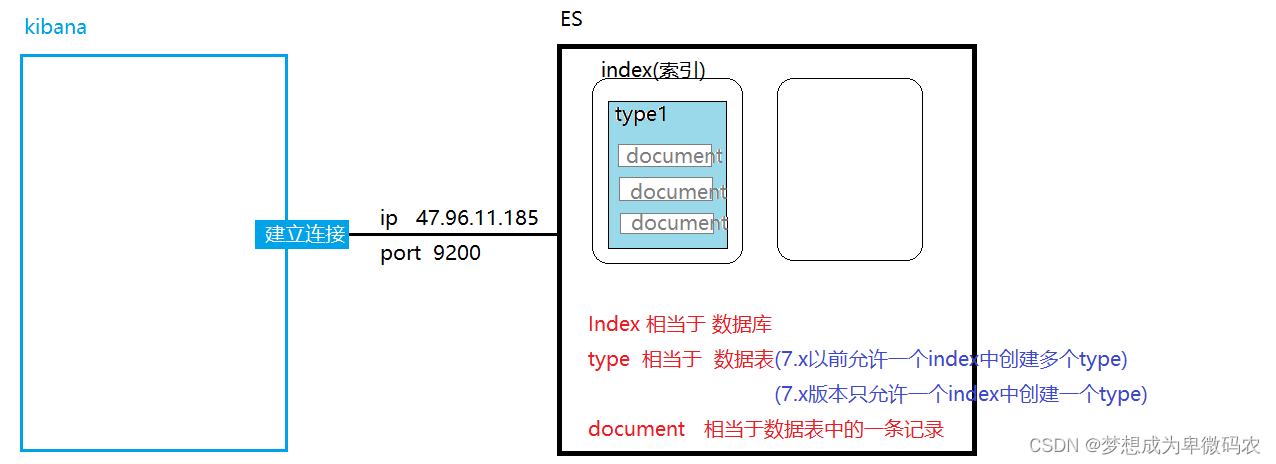
四、Elasticsearch逻辑结构
集群
-->index(
索引
)-->types(
类型
)-->document(
⽂档
)-->field(
字段
)
4.1 索引(index)
索引是
ElasticSearch
存放数据的地⽅,可以理解为关系型数据库中的⼀个数据库。
事实上,我们的数据被存储和索引 在分⽚
(shards)
中,索引只是⼀个把⼀个或多个分⽚分组
在⼀起的逻辑空间。然⽽,这只是⼀些内部细节
——
我们的 程序完全不⽤关⼼分⽚。对于我
们的程序⽽⾔,⽂档存储在索引
(index)
中。剩下的细节由
Elasticsearch
关⼼既可。
索引的名字必须是全部⼩写,不能以下划线开头,不能包含逗号
4.2 类型(type)
类型⽤于区分同⼀个索引下不同的数据类型
,
相当于关系型数据库中的表。在
Elasticsearch
中,我们使⽤相同类型
(type)
的⽂档表示相同的
“
事物
”
,因为他们的数据结构也是相同的。每
个类型
(type)
都有⾃⼰的映射
(mapping)
或者结 构定义,就像传统数据库表中的列⼀样。所有
类型下的⽂档被存储在同⼀个索引下,但是类型的映射
(mapping)
会告 诉
Elasticsearch
不同
的⽂档如何被索引。
es 6.0
开始不推荐⼀个
index
下多个
type
的模式,并且会在
7.0
中完全移除。在
7.0
的
index
下是
⽆法创建多个
type
4.3 ⽂档(documents)
⽂档是
ElasticSearch
中存储的实体,类⽐关系型数据库,每个⽂档相当于数据库表中的⼀⾏
数据。 在
Elasticsearch
中,⽂档
(document)
这个术语有着特殊含义。它特指最顶层结构或
者根对象
(root object)
序列化成的
JSON
数据(以 唯⼀
ID
标识并存储于
Elasticsearch
中)。
4.4 字段(fifields)
⽂档由字段组成,相当于关系数据库中列的属性,不同的是
ES
的不同⽂档可以具有不同的字
段集合。
4.5 节点与集群
⼀个集群是由⼀个或多个节点组成的集合,集群上的节点将会存储数据,并提供跨节点的索
引和搜索功能。
集群通过⼀个唯⼀的名称作为标识,节点通过设置集群名称就可以加⼊相应的集群,当然这
需要节点所在的⽹络能够发现集群。所以要注意在同⼀个⽹络中,不同环境、服务的集群的
名称不能重复。
⼀个节点就是⼀个
Elasticsearch
服务 (实例),可以实现存储数据,索引并且搜索的功能。
和集群⼀样,每个节点都有⼀个唯⼀的名称作为身份标识,如果没有设置名称,默认使⽤
UUID
作为名称。如果想更好的管理集群,最好给每个节点都定义上有意义的名称,在集群中
区分出各个节点。节点通过设置集群名称,在同⼀⽹络中发现具有相同集群名称的节点,组
成集群。默认的集群名称为
elasticsearch
。
如果在同⼀⽹络中只有⼀个节点,则这个节点成为⼀个单节点集群,换句话说就是每个节点
都是功能⻬全的服务。
五、Elasticsearch安装
5.1 Elastic 和 Elasticsearch
Elastic
官⽹:
https://www.elastic.co/cn/
Elastic
有⼀条完整的产品线及解决⽅案:
Elasticsearch
、
Logstash
、
Kibana
等,这三个就是
⼤家常说的
ELK
技术栈。

Elasticsearch
官⽹:
https://www.elastic.co/cn/products/elasticsearch
5.2 Linux下安装ES
出于安全考虑,
elasticsearch
默认不允许以
root
账号运⾏
- 创建⽤户设置密码
[root@localhost ~] # useradd es[root@localhost ~] # passwd esChanging password for user es.New password: 【 QFedu123 】Retype new password:[root@localhost ~] # chmod 777 /usr/local 【授予 es ⽤户 /usr/local ⽬录可读可写可执⾏权限】[root@localhost ~] # su - es[es@localhost ~] $
- 检查JDK版本(需要JDK1.8+)
[es@localhost ~] # java -versionopenjdk version "1.8.0_222-ea"OpenJDK Runtime Environment (build 1 .8.0_222-ea-b03)OpenJDK 64 -Bit Server VM (build 25 .222-b03, mixed mode)
- 将ES的压缩包上传⾄ /usr/local ⽬录并解压
[es@localhost local] $ tar -zxvf elasticsearch-7.6.1-linuxx86_64.tar.gz
- 查看配置⽂件
[es@localhost local] # cd elasticsearch-7.6.1/config/[es@localhost config] # lselasticsearch.yml jvm.options log4j2.properties role_mapping.ymlroles.yml users users_roles
- 修改 jvm.options
Elasticsearch基于Lucene的,⽽Lucene底层是java实现,因此我们需要配置jvm参数
[es@localhost config] # vim jvm.options# 默认配置如下# Xms represents the initial size of total heap space# Xmx represents the maximum size of total heap space-Xms1g-Xmx1g
- 修改 elasticsearch.yml
- 修改集群节点信息
# ---------------------------------- Cluster -----------------------------------17cluster.name : my-application# ------------------------------------ Node ------------------------------------23node.name : node-1# --------------------------------- Discovery ----------------------------------72cluster.initial_master_nodes : [ "node-1" ]
-
- 修改数据⽂件和⽇志⽂件存储⽬录路径(如果⽬录不存在则需创建)
[root@localhost config] # vim elasticsearch.yml# ---------------------------- Paths ------------------------------path.data: /usr/local/elasticsearch-7.6.1/datapath.logs: /usr/local/elasticsearch-7.6.1/logs
-
- 修改绑定的ip,默认只允许本机访问,修改为0.0.0.0后则可以远程访问
# ---------------------------- Network ------------------------------# 默认只允许本机访问,修改为 0.0.0.0 后则可以远程访问network.host: 0 .0.0.0
- 配置信息说明
⽬前我们是做的单机安装,如果要做集群,只需要在这个配置⽂件中添加其它节点信
息即可。

- 进⼊elasticsearch/bin⽬录运⾏
[es@localhost elasticsearch-7.6.1] # cd /usr/local/elasticsearch-7.6.1/bin[es@localhost elasticsearch-7.6.1] # ./elasticsearch
* soft nofile 666666666* hard nofile 131072* soft nproc 4096* hard nproc 4096
5.3 启动错误问题总结
错误
1
:内核过低
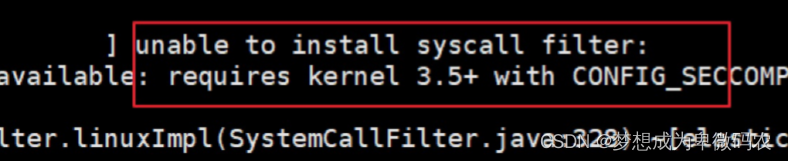
我们使⽤的是
centos6
,其
linux
内核版本为
2.6
。⽽
Elasticsearch
的插件要求⾄少
3.5
以上版
本。不过没关系,我们禁 ⽤这个插件即可。
修改
elasticsearch.yml
⽂件,在最下⾯添加如下配置:
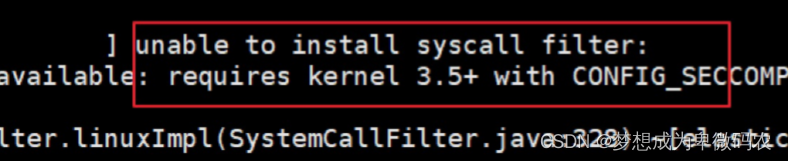
然后重启
错误
2
:⽂件权限不⾜
我们⽤的是
es
⽤户,⽽不是
root
,所以⽂件权限不⾜。
⾸先⽤
root
⽤户登录
,
然后修改配置⽂件
:
添加下⾯的内容:
* soft nofile 65536* hard nofile 131072* soft nproc 4096* hard nproc 4096
错误
3
:线程数不够
[1]: max number of threads [1024] for user [es] is too low, increase toat least [4096]
这是线程数不够
继续修改配置
[1]: max number of threads [1024] for user [es] is too low, increase toat least [4096]
修改下⾯的内容:
soft nproc 1024
改为
soft nproc 4096
错误
4
:进程虚拟内存
vm .max_map_count = 655360
vm.max_map_count
:限制⼀个进程可以拥有的
VMA(
虚拟内存区域
)
的数量
继续修改配置⽂件,
vim /etc/sysctl.conf
添加下⾯内容:
[3]: max virtual memory areas vm.max_map_count [65530] likely too low,increase to at least [262144]
修改完成之后在终端执⾏
## 然后执⾏命令sysctl -p
错误
5
:未设置节点
the default discovery settings are unsuitable for production use; atleast one of [discovery.seed_ho...]
修改
elasticsearch.yml
cluster.name : my-applicationnode.name : node-1cluster.initial_master_nodes : [ "node-1" ]
六、安装Kibana
Kibana
是⼀个基于
Node.js
的
Elasticsearch
索引库数据统计⼯具,可以利⽤
Elasticsearch
的聚
合功能,⽣成各种图 表,如柱形图,线状图,饼图等。
⽽且还提供了操作
Elasticsearch
索引数据的控制台,并且提供了⼀定的
API
提示,⾮常有利于
我们学习
Elasticsearch
的语法。
6.1 安装
kibana
版本与
elasticsearch
保持⼀致,也是
7.6.1
解压到特定⽬录即可
tar -zxvf kibana-7.6.1-linux-x86_64.tar.gz
6.2 配置
进⼊安装⽬录下的
con
fifi
g
⽬录,修改
kibana.yml
⽂件:
server.port : 5601server.host : "0.0.0.0"
6.3 运⾏
进⼊安装⽬录下的
bin
⽬录启动:
./kibana
发现
kibana
的监听端⼝是
5601
我们访问:
http://47.96.11.185:5601
6.4 控制台
七、安装IK分词器
7.1 安装ik分词器
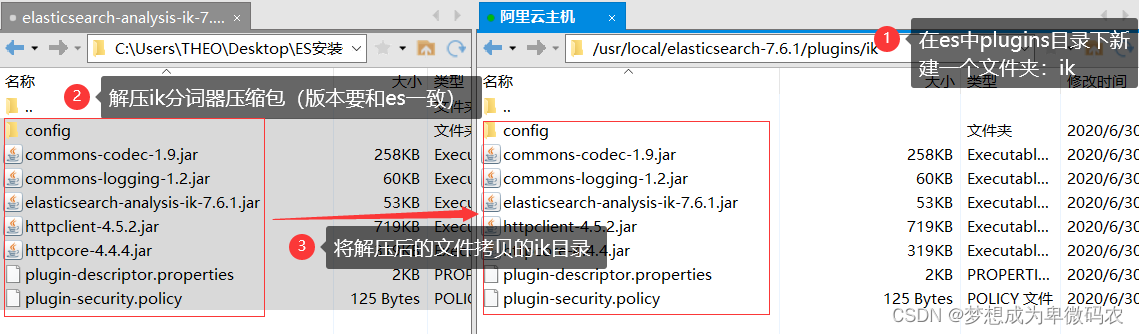
分词器配置完成以后,重启
es
7.2 测试分词器
7.3 配置⾃定义词库
- 在elasticsearch-analysis-ik-7.6.1/plugins/ik/config⽬录中定义词典⽂件(.dic)
- 在词典⽂件中定义⾃定义词汇
- elasticsearch-analysis-ik-7.6.1/plugins/ik/config/IKAnalyzer.cfg.xml加载⾃定义词典⽂件
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE properties SYSTEM"http://java.sun.com/dtd/properties.dtd"><properties><comment> IK Analyzer 扩展配置 </comment><!-- ⽤户可以在这⾥配置⾃⼰的扩展字典 --><entry key = "ext_dict" > mywords.dic </entry><!-- ⽤户可以在这⾥配置⾃⼰的扩展停⽌词字典 --><entry key = "ext_stopwords" ></entry><!-- ⽤户可以在这⾥配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!-- ⽤户可以在这⾥配置远程扩展停⽌词字典 --><!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>
⼋、ES基本操作
8.1 ES是基于RESTful实现访问
ES
是⽀持
web
访问的,但必须遵从
RESTful
访问规范
ES
逻辑结构
- 数据库:数据是存储在数据表中的,数据表是创建在数据库中的
- ES:document是存储在type中的,type是创建在index中
- index 索引 --- 相当于数据库 (索引的命名不能包含特殊字符,必须⼩写)
- type类型 --- 相当于数据表 (在es7以前,⼀个index中可以创建多个type )
- document⽂档 --- 相当于数据表中的⼀条记录
RESTful
- 不同操作需要使⽤不同的请求⽅式
- 基于REST的基本访问规范
|
请求⽅
式
|
REST
请求
|
功能描述
|
|
PUT
|
http://eshost:9200/index1
|
创建
index(
索引
)
|
|
POST
|
http://eshost:9200/
索引名
/
类型名
/
⽂档
ID
|
添加
document
|
|
POST
|
http://eshost:9200/
索引名
/
类型名
/
⽂档
ID/_update
|
修改
document
⽂档
|
|
DELETE
|
http://eshost:9200/
索引名
/
类型名
/
⽂档
ID
|
根据
ID
删除
document
|
|
GET
|
http://eshost:9200/
索引名
/
类型名
/
⽂档
ID
|
根据
ID
查询
document
|
|
POST
|
http://eshost:9200/
索引名
/
类型名
/_search
|
查询索引下所有数据
|
8.2 基本操作
- 创建索引
# 【基本操作】# 1. 创建索引 PUTPUT index1PUT index3{"mappings" : {"properties" : {"book_id" : {"type" : "long"},"book_name" : {"type" : "text"},"book_author" : {"type" : "keyword"},"book_price" : {"type" : "float"},"book_desc" : {"type" : "text"}}}}# 索引是⼀个逻辑单元, ES 中的数据实际上是存储在分⽚中的 , 我们可以在 settings 中设置索引的属性PUT index2{"settings" : {"number_of_shards" : 2}}
- 查询索引
# 查询索引信息GET index1# 查询索引的 mappings 信息GET index1/_mappings# 查询索引的属性设置GET index1/_settings
- 创建⽂档:新增⼀条记录到ES
POST index3/_doc/101{"book_id" : 101,"book_name" : "Java 程序设计 ","book_author" : " 千锋亮哥 ","book_price" : 22.22,"book_desc" : " 这是⼀本看了就会的 Java 秘籍 "}POST index3/_doc/102{"book_id" : 102,"book_name" : "C++ 程序设计 ","book_author" : " 谭浩强 ","book_price" : 22.22,"book_desc" : "C++ 程序设计中的名著 "}POST index3/_doc/103{"book_id" : 103,"book_name" : "Python 王者归来 ","book_author" : " 杰哥 ","book_price" : 33.22,"book_desc" : "Python 从⼊⻔到放弃 "}
注意: 在
ES 7.0
版本以后,⼀个
index
中只能存在⼀个
type(
默认名称为
_doc)
- 修改⽂档:修改记录
使⽤新增操作的请求覆盖原记录
POST index3/_doc/103{"book_id" : 103,"book_name" : "Python 王者归来 ","book_author" : " 杰哥 ","book_price" : 33.22,"book_desc" : "Python 从⼊⻔到放弃 "}
使⽤_update
修改
POST index3/_doc/103/_update{"book_id" : 103,"book_name" : "Python 王者归来 ","book_author" : " 杰哥 ","book_price" : 33.22,"book_desc" : "Python 从⼊⻔到放弃 "}
查询⽂档
根据⽂档 id 查询数据GET index3/_doc/101查询索引中的所有数据( type 使⽤⾃定名称)POST index3/_doc/_search
删除⽂档
DELETE index3/_doc/103
查看es
状态
_cat
GET _cat/indices?vGET _cat/health?v
8.3 数据类型
es
中⼀个
document
表示⼀条记录,记录中
field
值的存储是有类型的
https://www.elastic.co/guide/en/elasticsearch/reference/6.5/mapping-types.html
string
- text 可分词
- keyword 不能分词
Numeric datatypes
long ,
integer
,
short
,
byte
,
double
,
float
,
half_float
,
scaled_float
Date datatype
data --- ⽇期的存储时以
long
类型存储的毫秒数
Boolean datatype
boolean --- true | false | "true" | "false"
Binary datatype
binary 基于
base64
编码的字符串
Range datatypes
integer_range ,
float_range
,
long_range
,
double_range
,
date_range
创建
Index
并指定
field
类型
PUT index3{"mappings" : {"properties" : {"bookId" : {"type" : "long"},"bookName" : {"type" : "text"},"author" : {"type" : "keyword"},"time" : {"type" : "date"}}}}GET index3/_doc/_searchPOST index3/_doc/1{"bookId" : 10001,"bookName" : "Java 程序设计 ","author" : " 张三 ","time" : 234567890}
8.4 复杂查询-数据搜索
8.4.1 数据准备
PUT index4{"mappings": {"properties": {"bookId":{"type": "long"},"bookName":{"type": "text"},"author":{"type": "keyword"},"time":{"type": "date"}}}}POST index4/_doc/1{"bookId":10001,"bookName":"Java 程序设计 ","author":" 张三 ","time":234567890}POST index4/_doc/2{"bookId":10002,"bookName":"C 语⾔程序设计 ","author":"Java 谭浩强 ","time":2345678999}POST index4/_doc/3{"bookId":10003,"bookName":" 程序设计进阶 ","author":" 李三 ","time":2345678222}POST index4/_doc/4{"bookId":10004,"bookName":"Java 编程思想 ","author":" 三⽑ ","time":23456783452}
8.4.2 复杂查询语法

8.4.3 term和terms
⽤于对
keyword
字段进⾏精确匹配
- term 表示完全匹配,搜索之前不会对关键字进⾏分词
GET /index3/_search{"query" : {"term" : {"author" : " 涛哥 "}}}
- terms 也表示完全匹配,可以为⼀个field指定多个匹配关键词
GET /index3/_search{"query" : {"terms" : {"author" : [" 涛哥 "," 李三 "]}}}
8.4.4 match查询(重点)
match查询表示对text字段进⾏部分匹配(模糊查询)
- match 表示部分匹配,搜索之前会对关键词进⾏分词
GET /index4/_search{"query" : {"match" : {"bookName" : "Java 程序 "}}}
- match_all 表示查询全部内容,不指定任何条件
GET /index4/_search{"query" : {"match_all" : {}}}
- multi_match 在多个字段中匹配同⼀个关键字
GET /index4/_search{"query" : {"multi_match" : {"query" : "Java","fields" : ["bookName","author"]}}}
8.4.5 根据id查询
- 根据⼀个id查询⼀个document
GET /index4/_doc/1
- 根据多个id查询多个document ==> select * from ... where id in [1,2,3]
GET /index4/_search{"query" : {"ids" : {"values" : ["1","2","3"]}}}
8.4.5 其他查询
- prefix查询,根据指定字段的前缀值进⾏查询
GET /index4/_search{"query" : {"prefix" : {"author" : {"value" : " 张 "}}}}
- fuzzy查询,模糊查询,输⼊⼤概的内容es检索相关的数据
GET /index4/_search{"query" : {"fuzzy" : {"bookName" : {"value" : "jav"}}}}
- wildcard查询:正则匹配
GET /index4/_search{"query" : {"wildcard" : {"author" : {"value" : " 张 *"}}}}
- range查询,根据范围进⾏查询
GET /index4/_search{"query" : {"range" : {"bookId" : {"gt" : 10001,"lte" : 10003}}}}
- 分⻚查询
GET /index4/_search{"query" : {"match_all" : {}},"_source" : ["bookId","bookName"],"from" : 0,"size" : 20}
8.5 复合查询—bool
复合查询
——
多条件查询
- should ==> or
- must ==> and
- must_not ==> not
GET /index4/_search{"query" : {"bool" : {"must_not" : [{"match" : {"bookName" : "Java"}},{"match" : {"author" : " 张三 "}}]}}}
8.6 结果过滤—filter
filter——
根据条件进⾏查询,不计算分数,会对经常被过滤的数据进⾏缓存
GET /index3/_search{"query" : {"bool" : {"filter" : [{"match" : {"bookName" : "Java"}},{"match" : {"author" : " 张三 "}}]}}}
8.7 ⾼亮显示(重点)
对匹配的关键词进⾏特殊样式的标记
GET /index3/_search{"query" : {"match" : {"bookName" : "Java"}},"highlight" : {"fields" : {"bookName" : {}},"pre_tags" : "<label style = 'color : red'>","post_tags" : "</label>"}}
九、SpringBoot整合ES
官⽅参考地址
https://www.elastic.co/guide/en/elasticsearch/client/index.html
- RestLowerLevelClient
- RestHighLevelClient
9.1 创建SpringBoot应⽤
略
9.2 添加es的依赖
<dependency><groupId> org.springframework.boot </groupId><artifactId> spring-boot-starter-data-elasticsearch </artifactId></dependency>
9.3 配置Bean
在
springboot
应⽤中已经提供了
RestHighLevelClient
实例,⽆需进⾏实例配置,但是需
要进⾏
es
服务器地址配置
@Bean
public RestHighLevelClient getRestHighLevelClient(){
HttpHost httpHost = new HttpHost("47.96.11.185", 9200, "http");
RestClientBuilder restClientBuilder = RestClient.builder(httpHost);
RestHighLevelClient restHighLevelClient = new
RestHighLevelClient(restClientBuilder);
return restHighLevelClient; }
在
springboot
应⽤配置连接:
spring :elasticsearch :rest :uris : http : //47.96.11.185 : 9200
9.4 使⽤案例
@SpringBootTest
class Esdemo3ApplicationTests {
@Resource
private RestHighLevelClient restHighLevelClient;
/**
* 在es中创建索引
*/
@Test
public void testCreateIndex() throws IOException {
CreateIndexRequest createIndexRequest = new
CreateIndexRequest("index4");
CreateIndexResponse createIndexResponse =
restHighLevelClient.indices().create(createIndexRequest,
RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
/**
* 删除索引
*/
@Test
public void testDeleteIndex() throws IOException {
DeleteIndexRequest deleteIndexRequest = new
DeleteIndexRequest("index4");
AcknowledgedResponse deleteIndexRes =
restHighLevelClient.indices().delete(deleteIndexRequest,
RequestOptions.DEFAULT);
System.out.println(deleteIndexRes);
}
/**
* 添加⽂档:将数据存⼊es
*/
@Test
public void testCreateDocument() throws IOException {
Book book = new Book(10005,"平凡的世界","路遥",new
Date().getTime());
ObjectMapper objectMapper = new ObjectMapper();
String jsonStr = objectMapper.writeValueAsString(book);
IndexRequest request = new IndexRequest("index3");
request.id("10005");
request.source(jsonStr, XContentType.JSON);
IndexResponse indexResponse =
restHighLevelClient.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse);
}
/**
* 搜索
*/
@Test
public void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("index3");
SearchSourceBuilder searchSourceBuilder = new
SearchSourceBuilder();
searchSourceBuilder.from(0);
searchSourceBuilder.size(10);
// searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchSourceBuilder.query(QueryBuilders.matchQuery("bookName","Java"))
;
HighlightBuilder highlightBuilder = new HighlightBuilder();
HighlightBuilder.Field highlightTitle = new
HighlightBuilder.Field("bookName");
highlightTitle.highlighterType("unified");
highlightBuilder.field(highlightTitle);
highlightBuilder.preTags("<label style='color:red'>");
highlightBuilder.postTags("</label>");
searchSourceBuilder.highlighter(highlightBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResp =
restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = searchResp.getHits();
for (SearchHit hit : hits){
System.out.println(hit);
}
}
}
批量添加(参考代码)
/**
* 批量插⼊ES
* @param indexName 索引
* @param type 类型
* @param idName id名称
* @param list 数据集合
*/
public void bulkData(String indexName,String type ,String idName
,List<Map<String,Object>> list ){
try {
if(null == list || list.size()<=0){
return;
}
if(StringUtils.isBlank(indexName)||StringUtils.isBlank(idName)||StringU
tils.isBlank(type)) {
return;
}
BulkRequest request = new BulkRequest();
for(Map<String,Object> map : list){
if(map.get(idName)!=null){
request.add(new IndexRequest(indexName, type,
String.valueOf(map.get(idName)))
.source(map,XContentType.JSON));
}
}
// 2、可选的设置
/*
request.timeout("2m");
request.setRefreshPolicy("wait_for");
request.waitForActiveShards(2);
*/
//3、发送请求:同步请求
BulkResponse bulkResponse = client.bulk(request);
//4、处理响应
if(bulkResponse != null) {
for (BulkItemResponse bulkItemResponse : bulkResponse) {
DocWriteResponse itemResponse =
bulkItemResponse.getResponse();
if (bulkItemResponse.getOpType() ==
DocWriteRequest.OpType.INDEX
|| bulkItemResponse.getOpType() ==
DocWriteRequest.OpType.CREATE) {
IndexResponse indexResponse = (IndexResponse)
itemResponse;
//TODO 新增成功的处理
System.out.println("新增成功,{}"+
indexResponse.toString());
} else if (bulkItemResponse.getOpType() ==
DocWriteRequest.OpType.UPDATE) {
UpdateResponse updateResponse = (UpdateResponse)
itemResponse;
//TODO 修改成功的处理
System.out.println("修改成功,{}"+
updateResponse.toString());
} else if (bulkItemResponse.getOpType() ==
DocWriteRequest.OpType.DELETE) {
DeleteResponse deleteResponse = (DeleteResponse)
itemResponse;
//TODO 删除成功的处理
System.out.println("删除成功,{}"+
deleteResponse.toString());
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
查询数据封装
Iterator<SearchHit> iterator = hits.iterator();
List<Product> products = new ArrayList<>();
while(iterator.hasNext()){
SearchHit searchHit = iterator.next();
String str = searchHit.getSourceAsString();
Product product = objectMapper.readValue(str, Product.class);
HighlightField highlightField =
searchHit.getHighlightFields().get("productName");
if(highlightField != null){
String s = Arrays.toString(highlightField.fragments());
product.setProductName(s);
}
products.add(product);
}














 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









