







1. 什么是线性核
这是一种常见、常用的核函数。
线性核函数可以将非线性问题转换为线性问题。
线性核函数的数学表达式为:

假设我们有两个二维特征向量 𝑥1=[1,2]和 𝑥2=[3,4],它们的线性核计算如下:
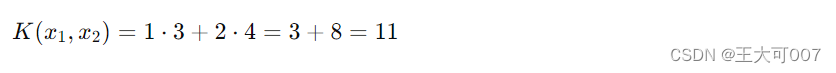
2. 什么是高斯核(也称为径向基函数RB)
这是一种将数据从原始空间映射到更高维空间的核函数。它衡量样本之间的“相似度”,使同类样本在新的空间中更好地聚在一起,从而更易于进行线性分类。

假设我们有两个二维特征向量 𝑥1=[1,2]x1=[1,2] 和 𝑥2=[3,4]x2=[3,4],且 𝜎=1σ=1。它们的高斯核计算如下:
首先,计算两个特征向量的欧氏距离的平方:
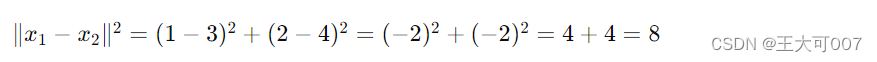
然后,计算高斯核:

举个例子
我们有一串颜色为红色和蓝色的珠子,它们排成一条直线。如果我们想只保留蓝色的珠子,使用一维的“一刀切”方法是无法实现的。然而,如果我们使用高斯核函数将这些珠子映射到二维平面,并在平面上找到一条直线来分隔红色和蓝色的珠子,那么问题就变得简单了。在二维平面上,我们可以轻松地找到这样一条直线,使得蓝色珠子在一边,红色珠子在另一边。
3. 什么是SVM(支持向量机)
SVM是一种经典的机器学习算法。
其基本模型是定义在特征空间上的间隔最大的线性分类器。对于非线性可分的数据,SVM使用核技巧将数据映射到高维空间,使其变得线性可分。
4. 数据集

5. Iris
5.1 读取Iris数据集
filename_iris = 'F:\\Matlab\\bin\\Iris\\Iris\\iris.data';
opts_iris = detectImportOptions(filename_iris, 'FileType', 'text');
opts_iris.Delimiter = ',';
opts_iris.VariableNames = {'SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Species'};
opts_iris.VariableTypes = {'double', 'double', 'double', 'double', 'string'};
irisData = readtable(filename_iris, opts_iris);这里使用的是detectImportOptions 函数,该函数可以制定导入的文件类型,这里指定的文件类型为“text(文本)”类型。
opts_iris.VariableNames 设置表格的列名
opts_iris.VariableTypes 设置表格的字段类型
5.2 提取特征
X_iris = irisData{:, 1:4};
Y_iris = irisData{:, 5};从irisData表格中提取前 4 列作为特征,存在X_iris。
从irisData表格中提取第 5 列作为标签,存在Y_iris。
5.3 五折交叉验证
% 定义折数
k = 5;
% 使用 k 折交叉验证 Iris 数据集
cv_iris = cvpartition(Y_iris, 'KFold', k);
accuracy_linear_iris = zeros(k, 1);
accuracy_gaussian_iris = zeros(k, 1);
accuracy_bp_iris = zeros(k, 1);使用 cvpartition 函数和k=5,来创建一个交叉验证分区的对象。这个对象将Y_iris(也就是标签)分为了k(也就是5)个部分。
初始化的三个数组。分别存储线性SVM、高斯SVM和BP神经网络在每次交叉验证迭代中的准确度。
上述的数组都是kx1的列向量,其中 k 是交叉验证的折数















 1650
1650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









