









目录
set, map, multiset, multimap, 基于平衡二叉树(红黑树),动态维护有序序列
unordered_set, unordered_map, unordered_multiset, unordered_multimap, 哈希表
unordered_set中find()和end()的运用:
插入删除操作汇总
vector:push_back()/pop_back()
往字符串后添加和删除操作:
s.push_back(char c);
s.pop_back();
pair:没有
queue:push()/pop()
stack:push()/pop()
set, map, multiset, multimap:insert()/erase()
转载:
这个适合简洁
史上最全的各种C++ STL容器全解析 - Seaway-Fu - 博客园
这个比较全
vector
vector, 变长数组,倍增的思想
头文件:#include<vector>
n-皇后中用到的string与vector的混合
vector<string> path;
path=vector<string>(n,string(n,'.'));
定义:
二维vector数组vector<vector<bool>>f(n,vector<bool>(m));定义n*m的二维数组
二维数组作为函数参数 double count1(vector< vector<double> > &v,int n)
二维数组的行数和列数
int r=v.size();//行数
int l=v[0].size();//列数vector<int>a;
vector<int> list2(list);
vector<int> list = {1,2,3.0,4,5,6,7};
vector<int> list3(list.begin() + 2, list.end() - 1);
vector<int>a(10);//定义长度为10的vector初始化为0
vector<int>a(10,1);//定义长度为10的vector,并都初始化为1
vector<string> a(10,"zhang");
vector<int>a[10];//定义vector数组,10个vector
函数:
size() 返回元素个数
empty() 返回是否为空
clear() 清空
front()/back()//返回第一个/最后一个数
push_back()/pop_back()//在最后插入/删除一个元素
begin()/end()//begin=>vector的第0个元素,end=>vector最后一个元素的后一个数
[]//支持随机选举//支持比较运算,按字典序
翻转vector<>数组:
Leetcode066 加一:力扣

class Solution {
public:
vector<int> plusOne(vector<int>& digits) {
reverse(digits.begin(),digits.end());
int t=1;
for(int i=0;i<digits.size();i++){
digits[i]=digits[i]+t;
if(digits[i]>=10) t=1;
else t=0;
digits[i]%=10;
}
//t=1,说明还有进位没处理
if(t==1) digits.push_back(1);
reverse(digits.begin(),digits.end());
return digits;
}
};遍历二维vector数组
//迭代器遍历
vector<vector<int >>::iterator iter;
for (iter = V.begin(); iter != V.end() ; ++iter) {
for (int i = 0; i < (*iter).size(); ++i) {
cout << (*iter)[i] << " " ;
}
cout << endl;
}
实例
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> v;
//初始化
for(int i = 0; i < 10; ++i )
{
v.push_back(i);
}
//第一种遍历方式:
for(int i=0;i<v.size();i++) cout<<v[i]<<" ";
cout<<endl;
//第二种:使用迭代器
//这里也可以直接简化vector<int>::iterator为auto自动判断
for(vector<int>::iterator it = v.begin(); it != v.end(); ++it)
{
cout << *it << " ";
}
cout << endl;
//没听清好像叫范围遍历?
for(auto x:v) cout<<x<<" ";
cout<<endl;
return 0;
}注意在函数参数体传入vector数组的地址时要添加&,例如二叉树的中序遍历
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void inorder(TreeNode *cur,vector<int> &res){
if(cur==NULL) return;
inorder(cur->left,res);
res.push_back(cur->val);
inorder(cur->right,res);
}
vector<int> inorderTraversal(TreeNode* root) {
vector<int> res;
inorder(root,res);
return res;
}
};pair
pair<int, int>
定义:
pair<int ,string>p;
初始化:
p=make_pair(10,"abc");
p={10,"abc"};
first, 第一个元素
second, 第二个元素
支持比较运算,以first为第一关键字,以second为第二关键字(字典序)
举例
#include <iostream>
#include <algorithm>
using namespace std;
int n;
const int N=50010;
typedef pair<int ,int > PII;
PII cow[N];
int main(){
cin>>n;
for(int i=0;i<n;i++){
int w,s;
cin>>w>>s;
cow[i]={w+s,s};
}
//将奶牛按照w+s升序排序,pair排序按照first为第一标准
sort(cow,cow+n);
//依次计算奶牛的危险系数取最大值
//res是奶牛危险系数的最大值,sum是奶牛上面的总质量
int res=-2e9,sum=0;
for(int i=0;i<n;i++){
int s=cow[i].second,w=cow[i].first-s;
res=max(res,sum-s);
sum+=w;
}
cout<<res;
return 0;
}string
C++string+=和+的区别:
C++ string类的+与+=运算符的区别_Myblog-CSDN博客
str=str+a;会先将等号右边的两个string对象内容相加,得到一个新的string对象,再把这个新的对象赋给等号左边的string对象。
str+=a;直接将等号右边的string对象内容追加到左边的string对象后面。
具体题目:Leetcode071简化路径:C++ string类的+与+=运算符巧妙运用 Leetcode 071简化路径(括号匹配的升级版)_Myblog-CSDN博客
例子
字符串初始化:
N皇后问题,怎么初始化一个全是'.'的棋盘呢?
vector<string> qi= vector<string>(n,string(n,'.'));
往字符串后添加和删除操作
s.push_back(char c);
s.pop_back();
将数据转换为string,不止能转换int
to_string (2);
翻转字符串
力扣二进制求和
描述:

代码:
class Solution {
public:
string addBinary(string a, string b) {
string c;
reverse(a.begin(),a.end());
reverse(b.begin(),b.end());
int t=0;
for(int i=0;i<a.size()||i<b.size()||t;i++){
if(i<a.size()) t+=a[i]-'0';
if(i<b.size()) t+=b[i]-'0';
c+=to_string(t%2);
t/=2;
}
reverse(c.begin(),c.end());
return c;
}
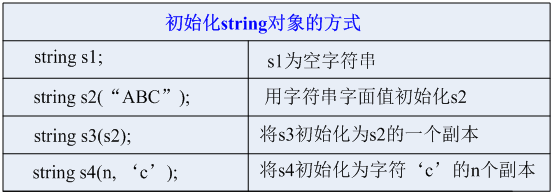
};string,字符串
string a="abc";
添加操作:a+="def";这时a=>"abcdef"
find()//找到返回第一次出现位置,找不到返回-1
size()/length() 返回字符串长度
empty()
clear()
substr(起始下标,(子串长度)) 返回子串
c_str() 返回字符串所在字符数组的起始地址
queue
size()
empty()
push() 向队尾插入一个元素
front() 返回队头元素
back() 返回队尾元素
pop() 弹出队头元素
priority_queue, 优先队列,默认是大根堆
priority_queue<int>q; size()
empty()
push() 插入一个元素
top() 返回堆顶元素
pop() 弹出堆顶元素
定义小根堆的方法
定义成小根堆的方式:
q.push(-x);//将-x从大到小排序=将x从小到大排序
priority_queue<int, vector<int>, greater<int>> q; (似乎只支持int?)
那有结构体怎么办?
构造比较函数,放入小根堆定义中作为第三个参数
代码:
#include<bits/stdc++.h>
#define Ll long long
using namespace std;
struct cs{
int x;
bool operator < (const cs &rhs) const {
return x > rhs.x;
}
}a;
priority_queue<cs>Q;
priority_queue<int,vector<int>,greater<int> >q;
int x,y;
int main()
{
while(1){
cin>>x;
if(x==1){
scanf("%d",&y);
a.x=y;
Q.push(a);
}
if(x==2){
cout<<Q.top().x<<endl;
Q.pop();
}
}
}碰到链表怎么办?
代码:
Leetcode023合并K个升序链表
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
struct Cmp {
bool operator() (ListNode* a, ListNode* b) {
return a->val > b->val;
}
};
ListNode* mergeKLists(vector<ListNode*>& lists) {
priority_queue<ListNode*, vector<ListNode*>, Cmp> heap;
auto dummy = new ListNode(-1), tail = dummy;
for (auto l : lists) if (l) heap.push(l);
while (heap.size()) {
auto t = heap.top();
heap.pop();
tail = tail->next = t;
if (t->next) heap.push(t->next);
}
return dummy->next;
}
};
将pair放入小根堆
可以将pair放入小根堆中,排序的原则是以pair的first作为第一关键字,实验:

使用实例:Dijkstra算法求最短路径(小根堆优化)
地址:Dijkstra算法求最短路问题_Myblog-CSDN博客
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
typedef pair<int ,int >PII;
const int N=150010;
int n,m;
//稀疏表用邻接表存储,w[N]存储的是权重
int h[N],e[N],ne[N],w[N],idx;
int dist[N];
bool stu[N];
void add(int a,int b,int c){
e[idx]=b,w[idx]=c,ne[idx]=h[a],h[a]=idx++;
}
int Dijkstra(){
//定义一个小根堆
priority_queue<PII,vector<PII>,greater<PII>> heap;
dist[1]=0;
heap.push({0,1});
while(!heap.empty()){
//这里不能写heap.front,没有这个函数
auto temp=heap.top();
heap.pop();
//distance是起点到temp的距离,ver是temp节点的编号
int distance=temp.first,ver=temp.second;
//如果已经出现过说明当前点是冗余备份
if(stu[ver]) continue;
//找到距离最近的节点加入小根堆
stu[ver]=true;
//通过temp节点更新距离
//i存储与temp节点相连通的节点的编号,所以w[i]存储的就是temp节点到j节点边的权重
for(int i=h[ver];i!=-1;i=ne[i]){
int j=e[i];
//distance 存储从1~temp的距离,w[i]存储从temp~j的距离
if(dist[j]>w[i]+distance){
dist[j]=w[i]+distance;
heap.push({dist[j],j});
}
}
}
if(dist[n]==0x3f3f3f3f) return -1;
else return dist[n];
}
int main(){
cin>>n>>m;
//初始化dist[N]为无穷大
memset(dist,0x3f,sizeof dist);
memset(h,-1,sizeof h);
for(int i=0;i<m;i++){
//m条边,但有重边,所以当节点间有重边时,取边长最小的一条边
int a,b,c;
cin>>a>>b>>c;
add(a,b,c);
}
cout<<Dijkstra();
return 0;
}stack, 栈
size()
empty()
push() 向栈顶插入一个元素
top() 返回栈顶元素
pop() 弹出栈顶元素
deque, 双端队列
size()
empty()
clear()
front()/back()
push_back()/pop_back()
push_front()/pop_front()
begin()/end()
[]
set, map, multiset, multimap, 基于平衡二叉树(红黑树),动态维护有序序列
小TIP如何快速利用vector初始化hash表:
复杂过程:
vector<int >nums1;
unordered_set<int> hash;
for(auto x:nums1) hash.insert(x);
可直接简化为:
unordered_set <int>hash(nums1.begin(),nums1.end());
size()
empty()
clear()
begin()/end()
++, -- 返回前驱和后继,时间复杂度 O(logn)
insert() 插入一个数
find() 查找一个数,存在返回集合中指向元素k的迭代器,否则就返回s.end()
count() 返回某一个数的个数
erase()//erase(key)的时候会删除multiset里面所有的key并且返回删除的个数。
(1) 输入是一个数x,删除所有x O(k(k为x的个数) + logn)
(2) 输入一个迭代器,删除这个迭代器
lower_bound()/upper_bound() //离散数学里的最小上界和最大下界lower_bound返回集合中第一个大于等于关键字的迭代器
upper_bound返回集合中第一个严格大于关键字的迭代器


find()函数:返回迭代器
#include<iostream>
#include<set>
using namespace std;
int main()
{
set<int> st;
for(int i=0;i<=3;i++)
{
st.insert(i);
}
set<int>::iterator it=st.find(2);
cout<<*it;
return 0;
}
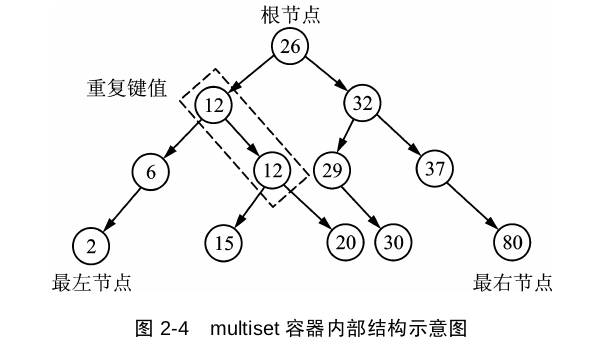
set/multiset
//set不能有重复元素,multiset可以有重复元素
set是用红黑树的平衡二叉索引树的数据结构来实现的,插入时,它会自动调节二叉树排列,把元素放到适合的位置,确保每个子树根节点的键值大于左子树所有的值、小于右子树所有的值,插入重复数据时会忽略。set迭代器采用中序遍历,检索效率高于vector、deque、list,并且会将元素按照升序的序列遍历。set容器中的数值,一经更改,set会根据新值旋转二叉树,以保证平衡,构建set就是为了快速检索.
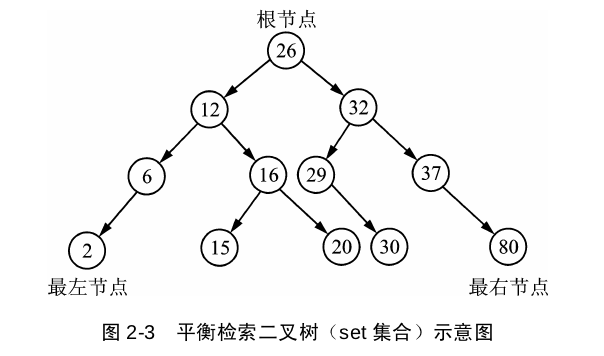
正反遍历,迭代器iterator、reverse_iterator
#include<iostream>
#include<set>
using namespace std;
int main()
{
set<int> v;
v.insert(1);
v.insert(3);
v.insert(5);
v.insert(2);
v.insert(4);
v.insert(3);
//中序遍历 升序遍历
for(set<int>::iterator it = v.begin(); it != v.end(); ++it)
{
cout << *it << " ";
}
cout << endl;
for(set<int>::reverse_iterator rit = v.rbegin(); rit != v.rend(); ++rit)
{
cout << *rit << " ";
}
cout << endl;
return 0;
}结果:

自定义比较函数
insert的时候,set会使用默认的比较函数(升序),很多情况下需要自己编写比较函数。
1、如果元素不是结构体,可以编写比较函数,下面这个例子是用降序排列的(和上例插入数据相同):
#include<iostream>
#include<set>
using namespace std;
struct Comp
{
//重载()
bool operator()(const int &a, const int &b)
{
return a > b;
}
};
int main()
{
set<int,Comp> v;
v.insert(1);
v.insert(3);
v.insert(5);
v.insert(2);
v.insert(4);
v.insert(3);
for(set<int,Comp>::iterator it = v.begin(); it != v.end(); ++it)
{
cout << *it << " ";
}
cout << endl;
for(set<int,Comp>::reverse_iterator rit = v.rbegin(); rit != v.rend(); ++rit)
{
cout << *rit << " ";
}
cout << endl;
return 0;
}
2、元素本身就是结构体,直接把比较函数写在结构体内部,下面的例子依然降序:
#include<iostream>
#include<set>
#include<string>
using namespace std;
struct Info
{
string name;
double score;
//重载 <
bool operator < (const Info &a) const
{
return a.score < score;
}
};
int main()
{
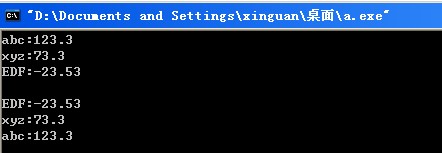
set<Info> s;
Info info;
info.name = "abc";
info.score = 123.3;
s.insert(info);
info.name = "EDF";
info.score = -23.53;
s.insert(info);
info.name = "xyz";
info.score = 73.3;
s.insert(info);
for(set<Info>::iterator it = s.begin(); it != s.end(); ++it)
{
cout << (*it).name << ":" << (*it).score << endl;
}
cout << endl;
for(set<Info>::reverse_iterator rit = s.rbegin(); rit != s.rend(); ++rit)
{
cout << (*rit).name << ":" << (*rit).score << endl;
}
cout << endl;
return 0;
}结果:
multiset:
map/multimap
map可以当数组一样用,multimap不清楚

insert() 插入的数是一个pair
erase() 输入的参数是pair或者迭代器
find()
[] 注意multimap不支持此操作。 时间复杂度是 O(logn)
lower_bound()/upper_bound()
unordered_set, unordered_map, unordered_multiset, unordered_multimap, 哈希表
unordered_set中find()和end()的运用:
题解:unordered_set中end()与find()的使用_bulangman277的博客-CSDN博客

判断某一元素在hash表中是否存在:
hash.find(num)!=hash.end()表示不存在:
例题:Leetcode 349两个数组的交集
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
vector<int> ans;
unordered_set<int> hash(nums1.begin(),nums1.end());
for(auto num:nums2){
if(hash.find(num)!=hash.end()){
ans.push_back(num);
hash.erase(num);
}
}
return ans;
}
};
unordered_map用法详解:
哈希表的妙用:
力扣(Leetcode049字母异位词分组)
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string >> res;
unordered_map<string ,vector<string >> ans;
for(int i=0;i<strs.size();i++){
string temp=strs[i];
//将字符串进行排序,这样由相同字符组成的不同字符就转换成了同一个字符串
sort(temp.begin(),temp.end());
ans[temp].push_back(strs[i]);
}
for(auto str:ans) {
res.push_back(str.second);
}
return res;
}
};运用unordered_map记录字符串每个字符出现次数,解决最长的不重复子串问题:
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int res=0;
//用于存储字符串中每个字符的出现次数
unordered_map<char,int> heap;
//枚举以i为尾端点的所有字串,i----[0,n-1],找到其中最长的不重复字串
for(int i=0,j=0;i<s.size();i++){
heap[s[i]]++;
while(heap[s[i]]>1) {
heap[s[j]]--;//j指针所指的字符出现次数--
j++;//j向右移动直到把重复出现的字符删除为止
}
res=max(res,i-j+1);
}
return res;
}
};C++中的unordered_map用法详解_zou_albert的博客-CSDN博客_c++ unordered_map用法
无序,和上面类似,增删改查的时间复杂度是 O(1)
不支持 lower_bound()/upper_bound(), 迭代器的++,--
注意点:
- unordered_map是一个将key和value关联起来的容器,它可以高效的根据单个key值查找对应的value。
- key值应该是唯一的,key和value的数据类型可以不相同。
- unordered_map存储元素时是没有顺序的,只是根据key的哈希值,将元素存在指定位置,所以根据key查找单个value时非常高效,平均可以在常数时间内完成。
- unordered_map查询单个key的时候效率比map高,但是要查询某一范围内的key值时比map效率低。
- 可以使用[]操作符来访问key值对应的value值。
使用:
std::unordered_map<std::string, std::int> umap; //定义
umap.insert(Map::value_type("test", 1));//增加
//根据key删除,如果没找到n=0
auto n = umap.erase("test") //删除
auto it = umap.find(key) //改
if(it != umap.end())
it->second = new_value;
//map中查找x是否存在
umap.find(x) != map.end()//查
//或者使用count()函数
//使用count(),返回的是被查找元素的个数。如果有,返回1;否则,返回0。
//注意,map中不存在相同元素,所以返回值只能是1或0。
umap.count(x) != 0
map和unordered_map的比较
#include<iostream> //map的基本操作如下
#include<map>
#include<string>
using namespace std;
int main()
{
// 构造函数
map<string, int> dict;
// 插入数据的三种方式
dict.insert(pair<string,int>("apple",2));
dict.insert(map<string, int>::value_type("orange",3));
dict["banana"] = 6;
// 判断是否有元素
if(dict.empty())
cout<<"该字典无元素"<<endl;
else
cout<<"该字典共有"<<dict.size()<<"个元素"<<endl;
// 遍历
map<string, int>::iterator iter;
for(iter=dict.begin();iter!=dict.end();iter++)
cout<<iter->first<<ends<<iter->second<<endl;
// 查找
if((iter=dict.find("banana"))!=dict.end()) // 返回一个迭代器指向键值为key的元素,如果没找到就返回end()
cout<<"已找到banana,其value为"<<iter->second<<"."<<endl;
else
cout<<"未找到banana."<<endl;
if(dict.count("watermelon")==0) // 返回键值等于key的元素的个数
cout<<"watermelon不存在"<<endl;
else
cout<<"watermelon存在"<<endl;
pair<map<string, int>::iterator, map<string, int>::iterator> ret;
ret = dict.equal_range("banana"); // 查找键值等于 key 的元素区间为[start,end),指示范围的两个迭代器以 pair 返回
cout<<ret.first->first<<ends<<ret.first->second<<endl;
cout<<ret.second->first<<ends<<ret.second->second<<endl;
iter = dict.lower_bound("boluo"); // 返回一个迭代器,指向键值>=key的第一个元素。
cout<<iter->first<<endl;
iter = dict.upper_bound("boluo"); // 返回一个迭代器,指向值键值>key的第一个元素。
cout<<iter->first<<endl;
return 0;
}
#include<string>
#include<iostream>
#include<unordered_map>
using namespace std;
int main()
{
unordered_map<string, int> dict; // 声明unordered_map对象
// 插入数据的三种方式
dict.insert(pair<string,int>("apple",2));
dict.insert(unordered_map<string, int>::value_type("orange",3));
dict["banana"] = 6;
// 判断是否有元素
if(dict.empty())
cout<<"该字典无元素"<<endl;
else
cout<<"该字典共有"<<dict.size()<<"个元素"<<endl;
// 遍历
unordered_map<string, int>::iterator iter;
for(iter=dict.begin();iter!=dict.end();iter++)
cout<<iter->first<<ends<<iter->second<<endl;
// 查找
if(dict.count("boluo")==0)
cout<<"can't find boluo!"<<endl;
else
cout<<"find boluo!"<<endl;
if((iter=dict.find("banana"))!=dict.end())
cout<<"banana="<<iter->second<<endl;
else
cout<<"can't find boluo!"<<endl;
return 0;
}
bitset, 压位(最主要省空间)
bitset<10000> s;
~, &, |, ^
>>, <<
==, !=
[]count() 返回有多少个1
any() 判断是否至少有一个1
none() 判断是否全为0set() 把所有位置成1
set(k, v) 将第k位变成v
reset() 把所有位变成0
flip() 等价于~
flip(k) 把第k位取反















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









