






网易云盘歌曲加歌词
网易云盘歌曲加歌词
一.现象
新版云音乐PC/移动客户端(我的PC端版本3.1.2)打开发现之前云盘里有歌词的歌曲现在没了。。。
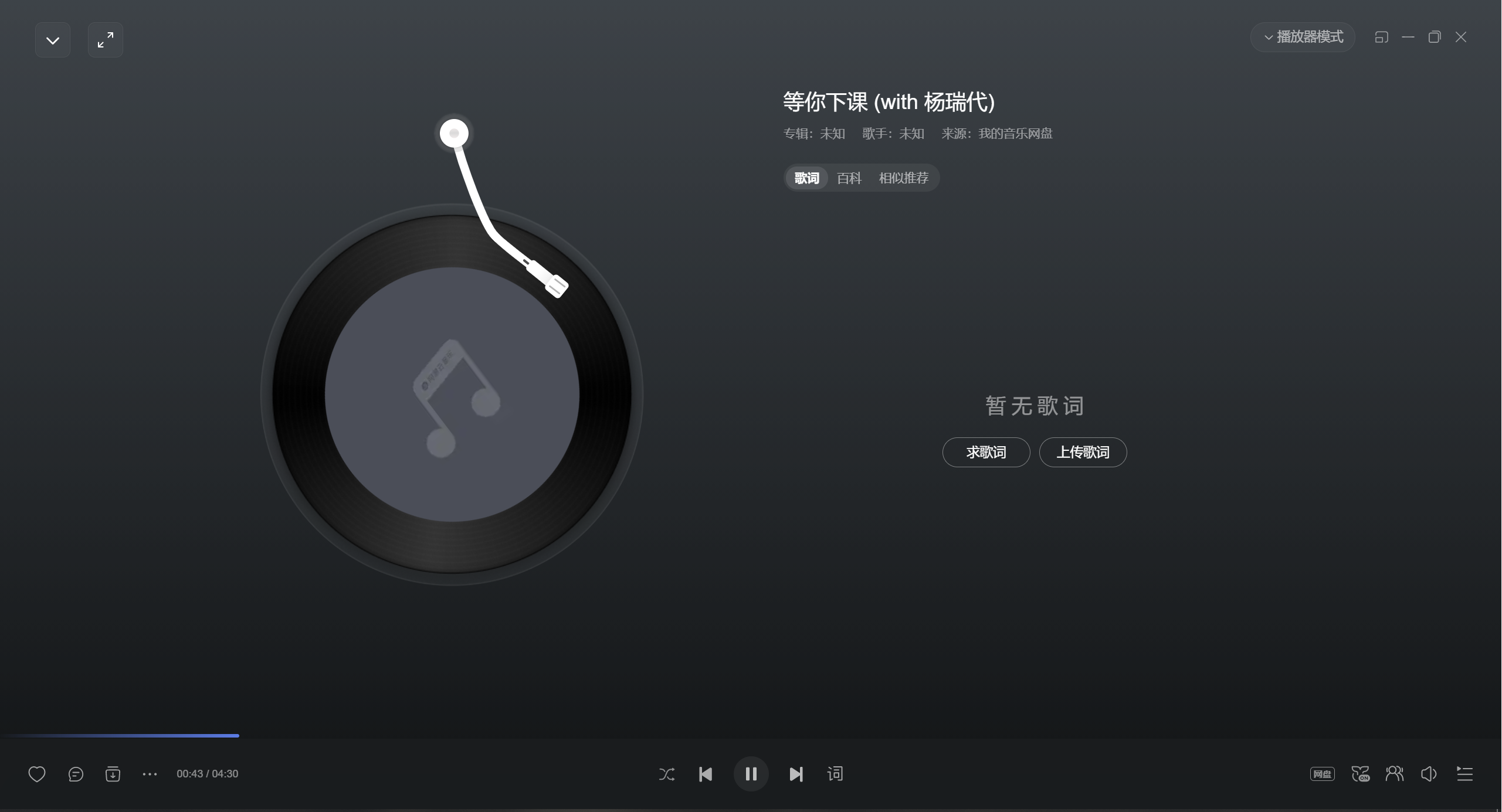
移动端

二.解决办法
1、音频、歌词文件下载
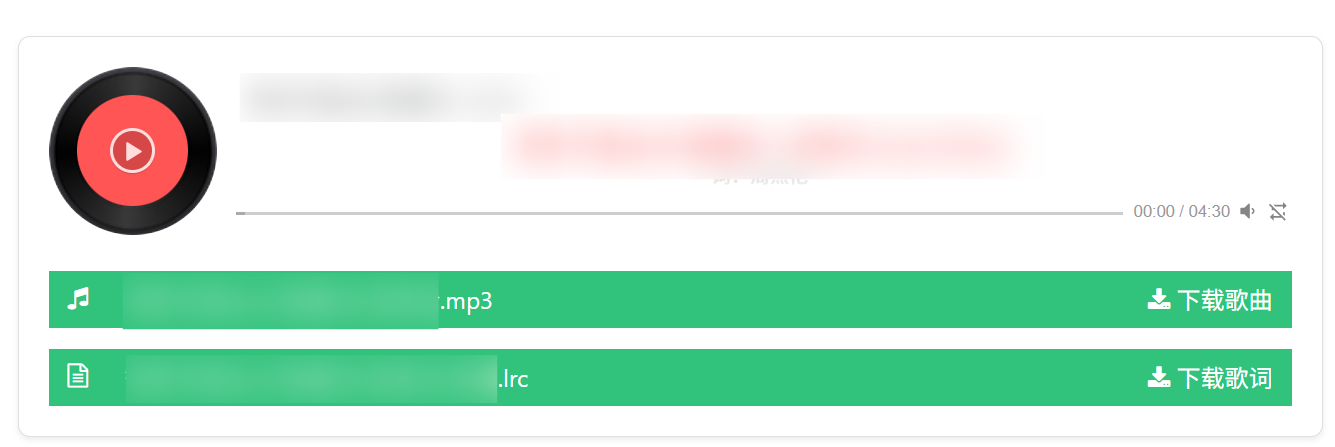
1.推荐一个音乐下载地址: 免费音乐下载。这里有音频(.mp3)文件,有歌词(.lrc)文件。搜索下载即用(推荐)~
2.也可自行编写歌词文件(推荐互联网上能找到的就不用自己折腾,见方法1)
①.首先要准备两个文件(1.歌曲音源文件 2.歌词文件[txt的文件就行,不需要带时间轴,因为我们利用下面那个工具手动调整歌词滑动])
②使用BesLyric: BesLyric下载。
如果都失效了可私信我拿~
下载解压完成后打开BesLyric.exe文件
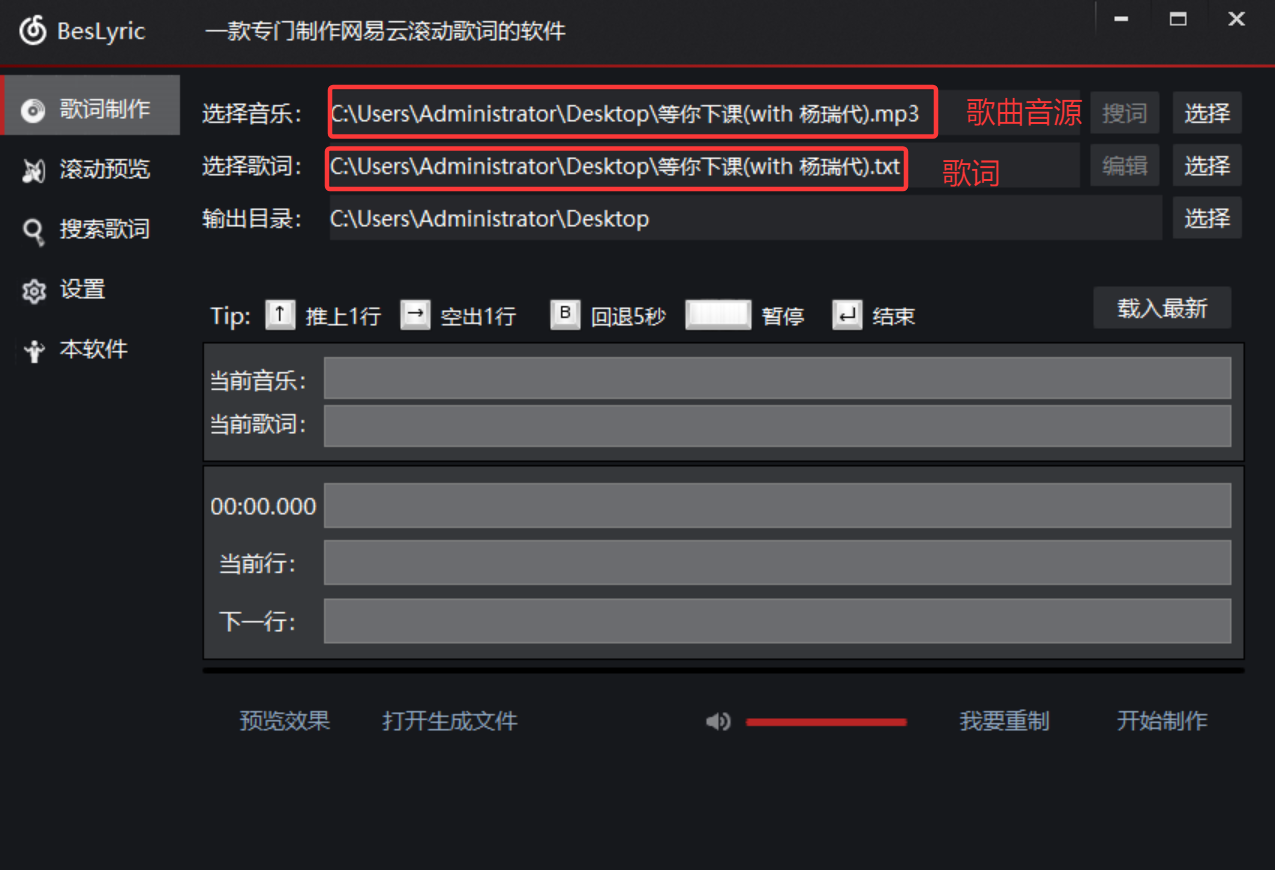
依次点击载入最新,开始制作
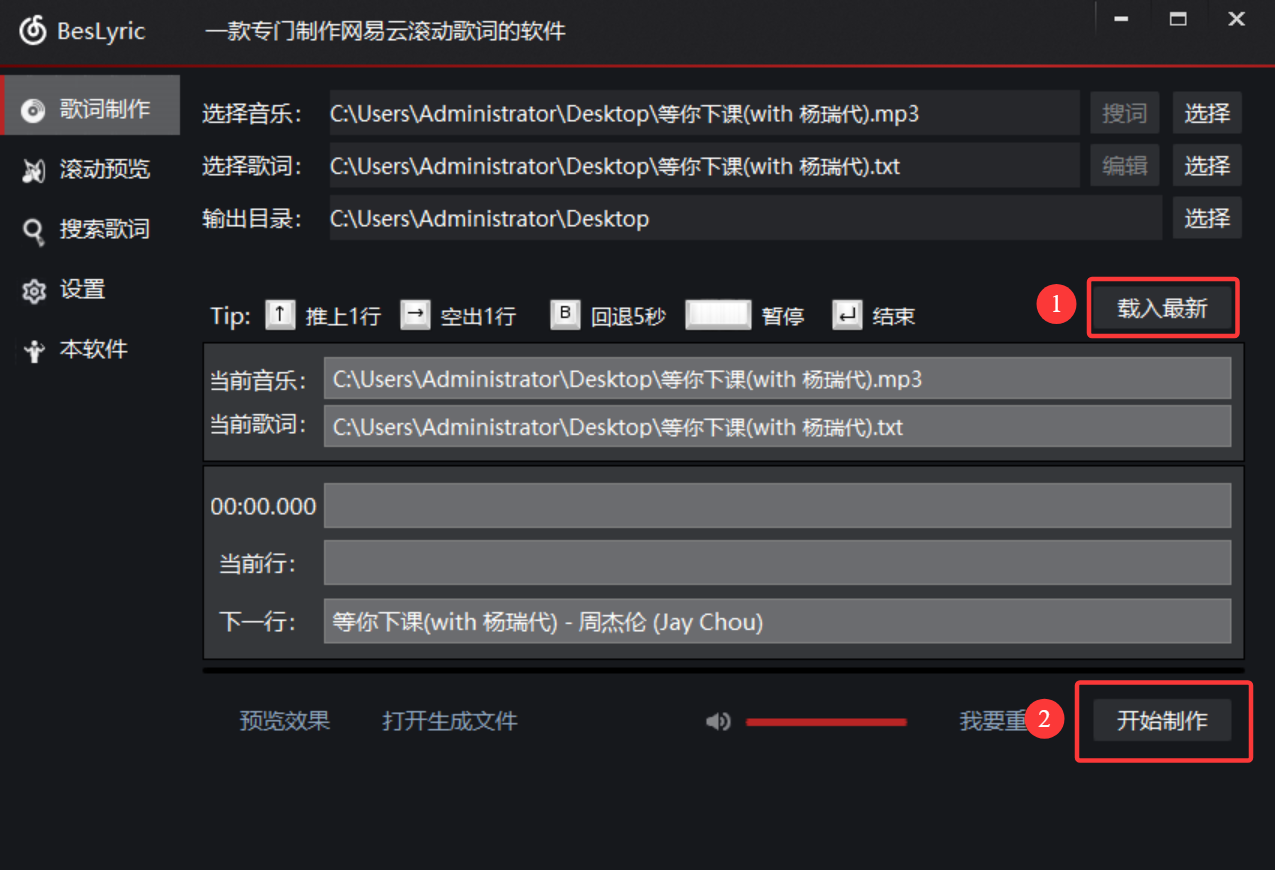
点击开始制作后,就开始播放歌曲,此时通过键盘↑(下一句)手动调整歌词滑动,听到这句歌词按下↑即可~
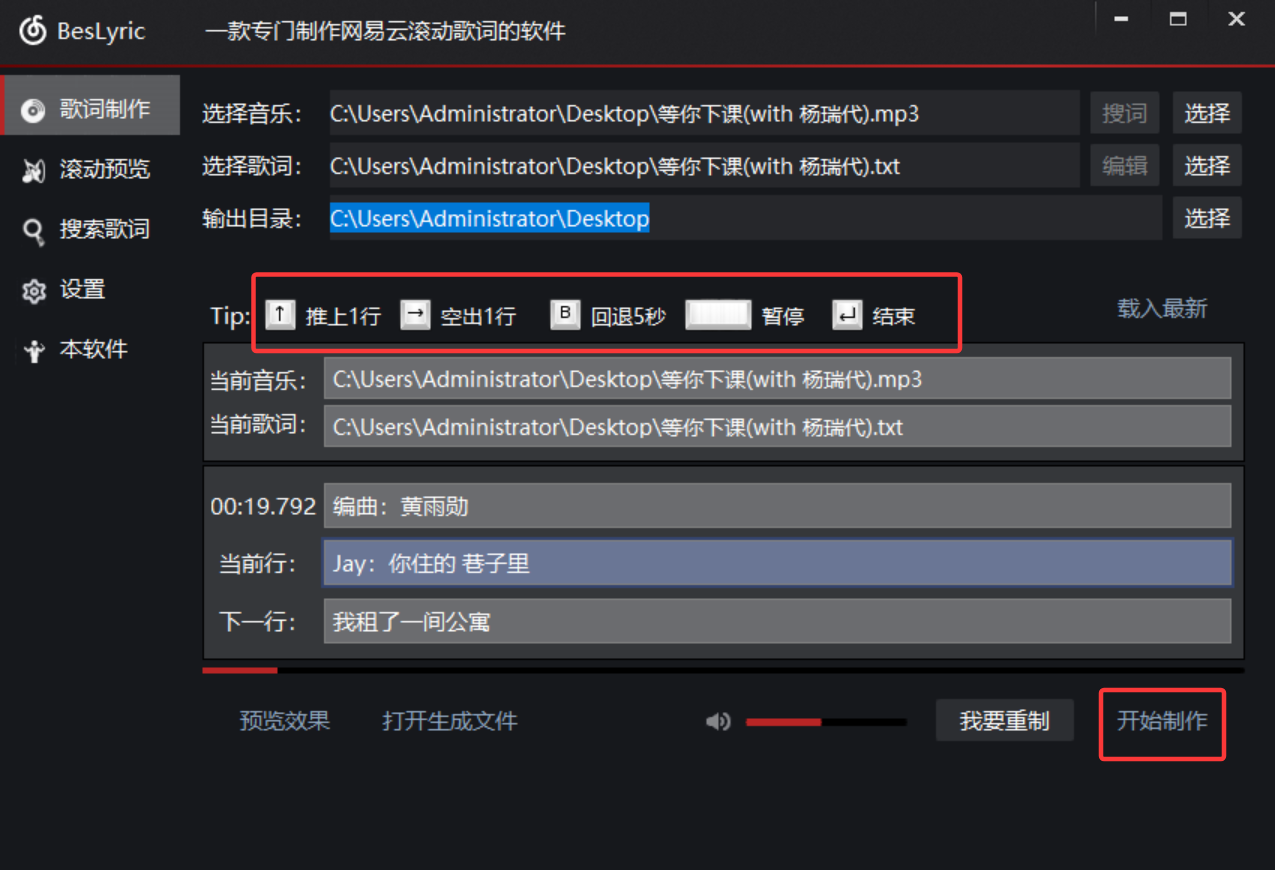
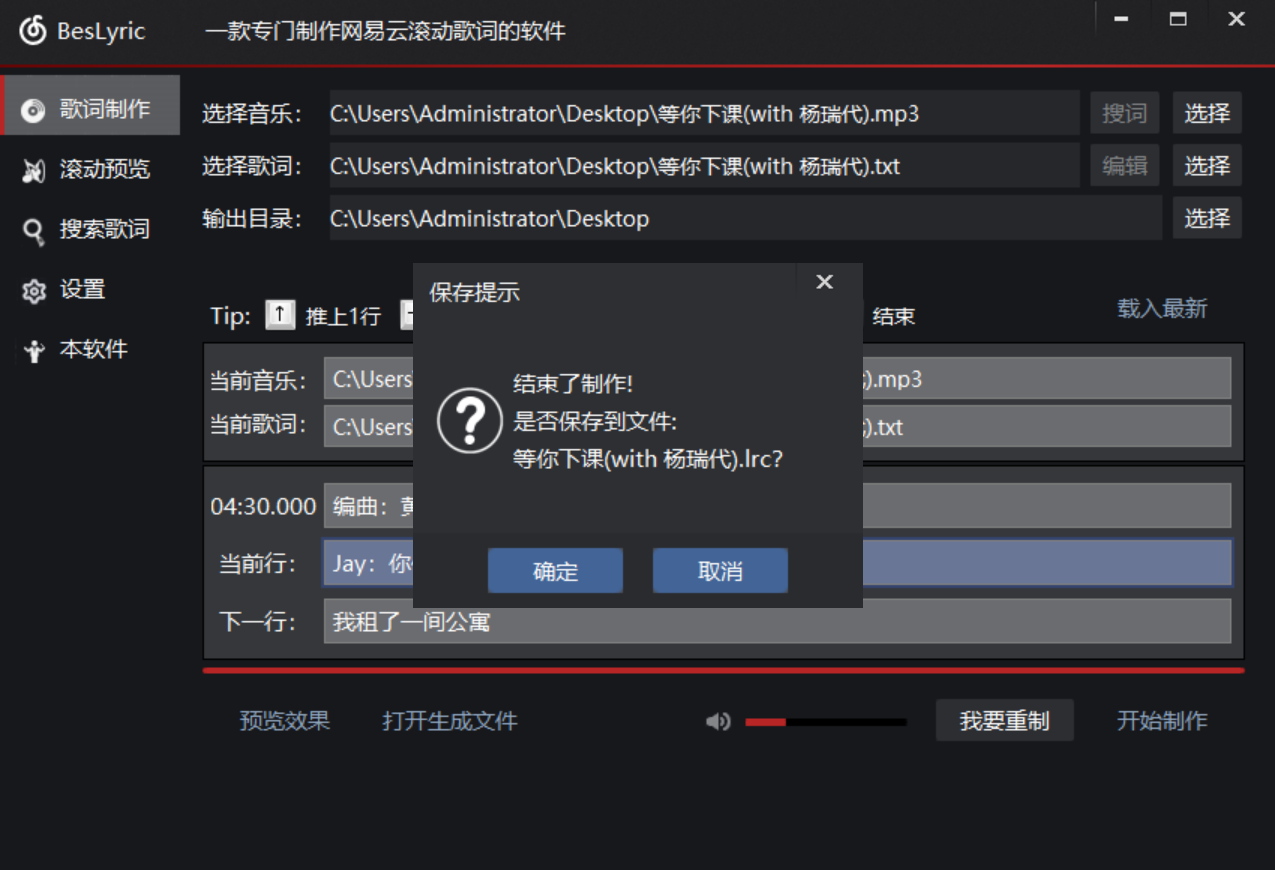
歌曲结束之后即可保存为.Irc文件
最后把生成的歌词歌曲放在同一个目录下,网易云的本地目录打开这个目录即可看到歌词~
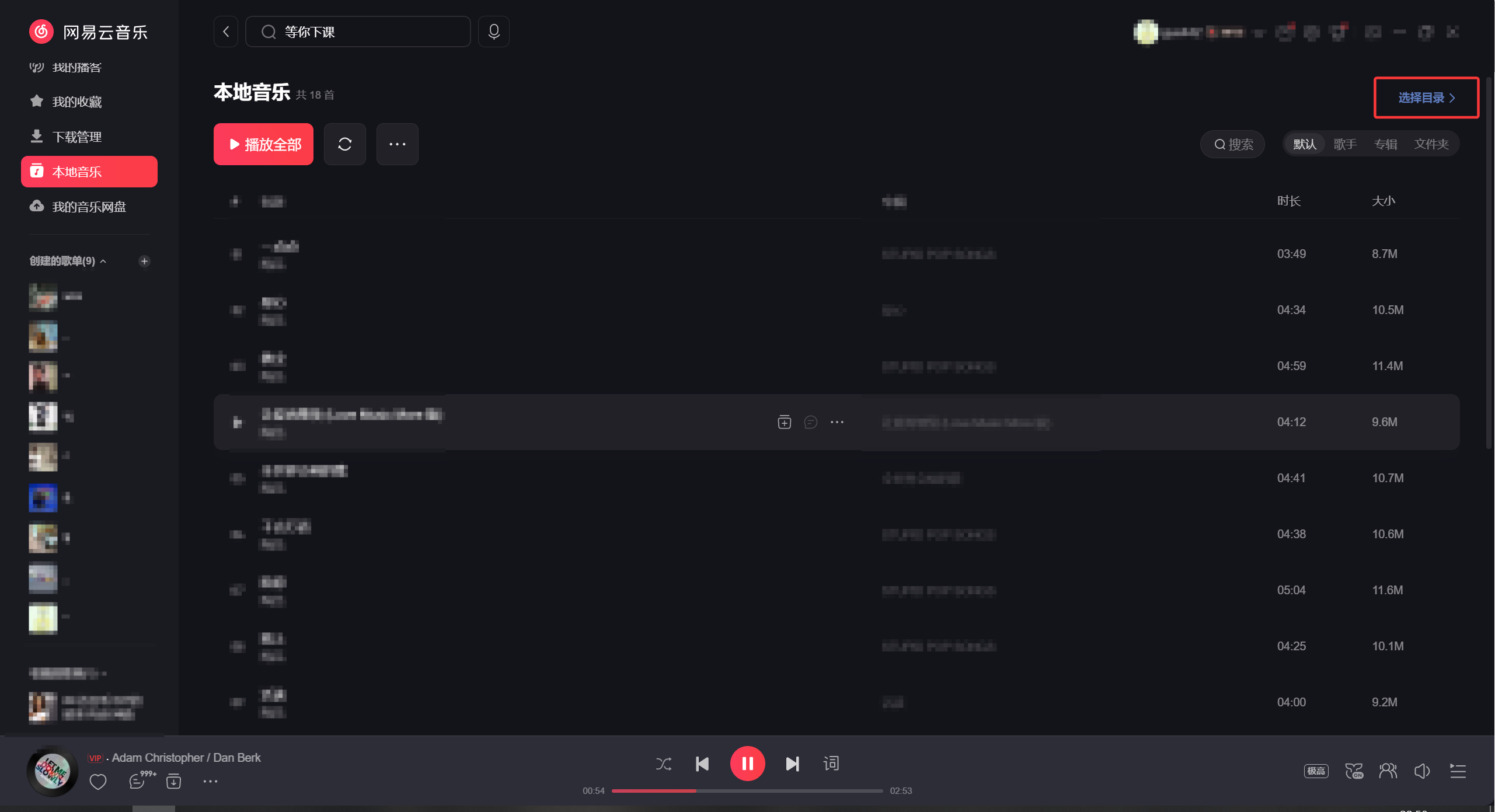
但是这边把歌曲传到云盘后,发现云盘播放还是没有歌词,说明两个只有本地才能读到本地目录下的Irc歌词文件,云盘不会来读本地。以上提供给音乐爱好的小伙伴制作歌曲的歌词文件的一种方法,接下来推荐使用方法二解决歌词失效问题。
2、更改歌曲云盘ID
软件下载:见文章底部~
下载解压之后打开NeteaseMusicCloudMatch.exe文件,使用移动端网易云APP扫描之后登录即可访问云盘。
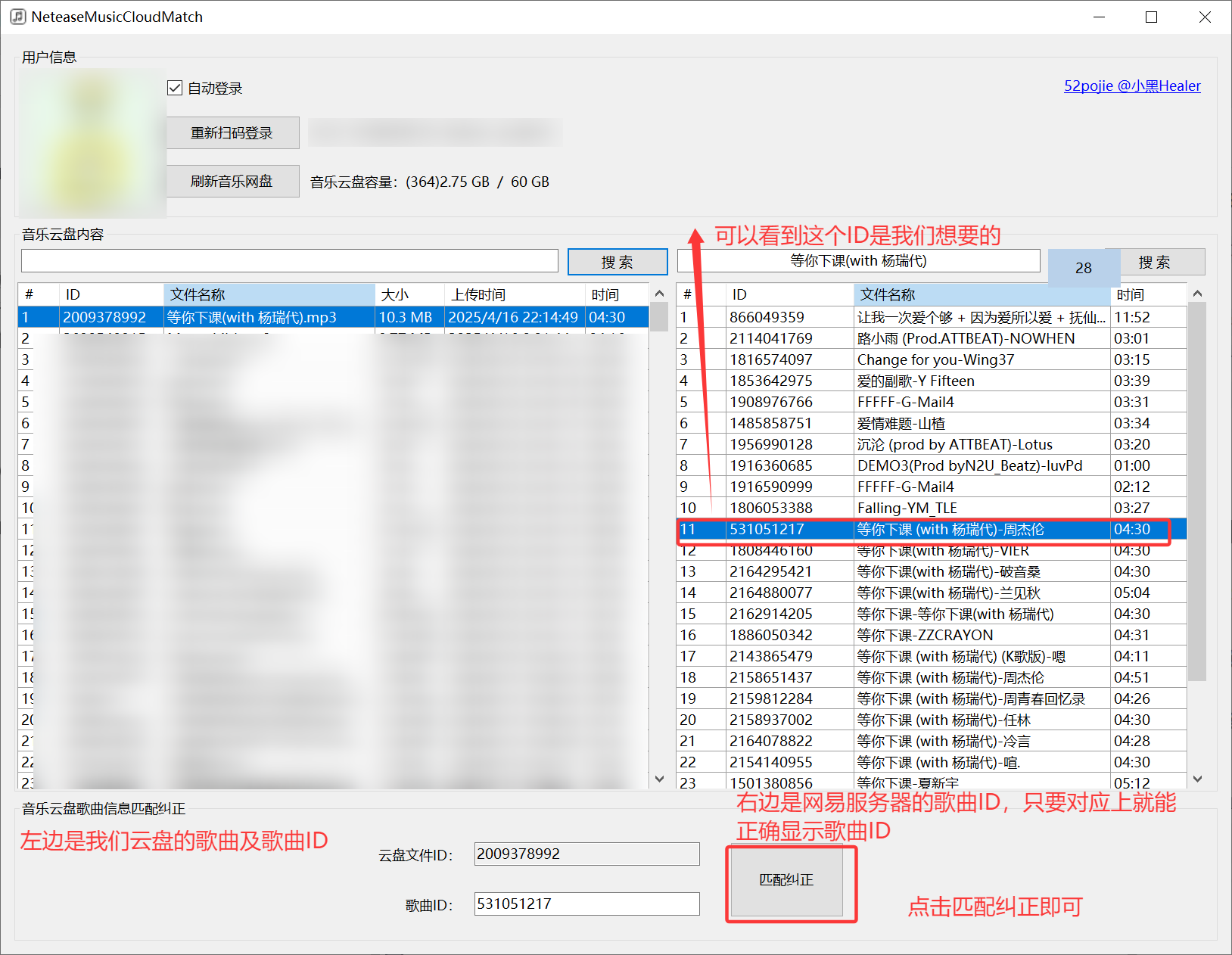
成功!
更改云盘歌曲ID 或 全网无损音乐下载的☞私信~

















 5100
5100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









