






本文讲的是如何站内获取仓库sku,并且添加到审单规则
在这里我们会用到两个模块,一个requests模块,另一个是xpath模块
requests模块安装命令
pip install requests
xpath模块安装命令
pip install lxml
下载速度慢的可以添加镜像下载
获取仓库清单sku
首先是获取仓库清单的sku,而里面的sku又分为单个sku和组合sku。
所以在获取sku的时候我们要分两步取,第一步就是取单个sku,接着在取组合sku,然后存储起来返回出去
-
获取请求文本

上面的代码就是利用requests模块发送请求获取到网页的文本,有了响应文本后我们可以获取相关的数据,这一步我们就需要用到xpath了。 -
处理请求文本
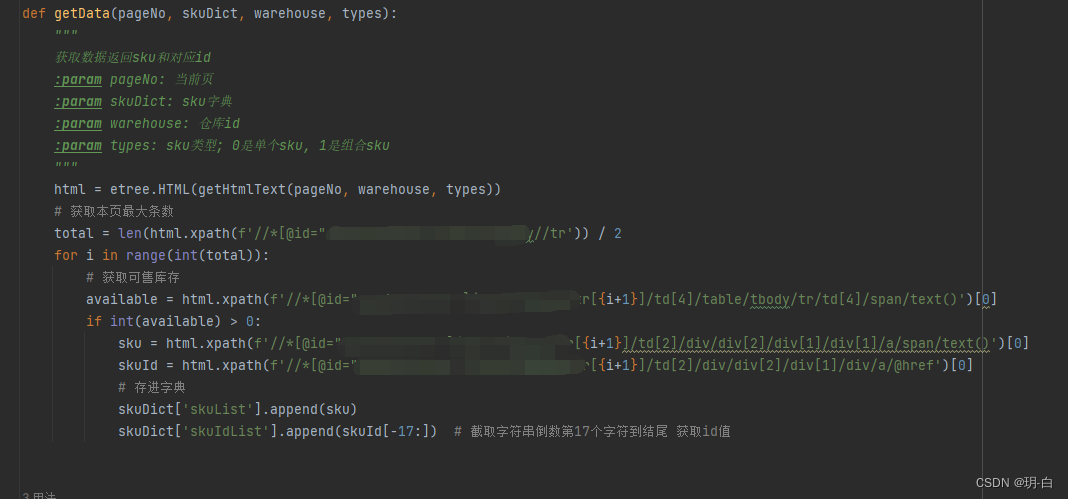
在这里我们对当前的响应文本进行数据提取,拿到我们想要的部分,但是但数据量大于一百,两百,乃至更多的时候,一般会采取分页处理,而我们获取的文本只有一页,为此我们需要写一个能换页的函数进行跳转! -
换页函数
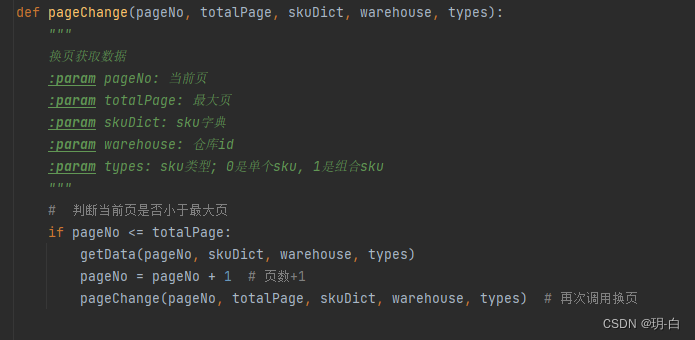
上面就是我们写的换页行数,如果当前页小于等于最大页,那么我们将继续获取本页文本,然后pageNo页数加一,继续调用换页函数。反之当前页大于最大页,那么将会结束该函数。 -
整合代码
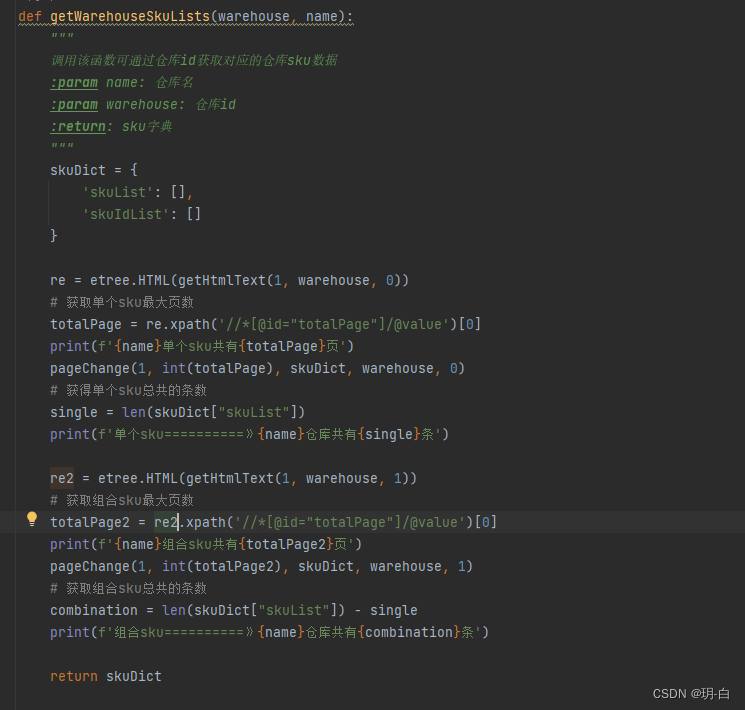
该函数有两个参数,一个是仓库名,一个仓库ID,仓库名是助于我们分辨获取的仓库,ID是获取数据必须要的值!
首先我们这里定义一个存储sku和对应id的字典,然后获取最大页数传到我们的换页函数里,而我们的换页函数我们给他默认第一页。特别要说明的是单个sku和组合sku是两个不一样的分类,所以我们必须要分别获取。
添加审单规则
添加审单规则我们默认已经获得sku和对应id的存储字典
-
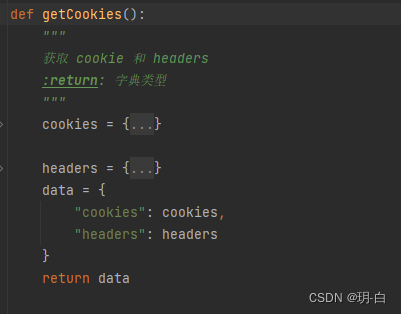
获取cookie和headers
第一步我们先封装cookie和headers,因为这在后面请求中会多次调用,为了减少代码冗余,我们为此把它进行了封装,方便我们调用,而我们采用字典的形式来存储cookie和headers
-
添加审单规则
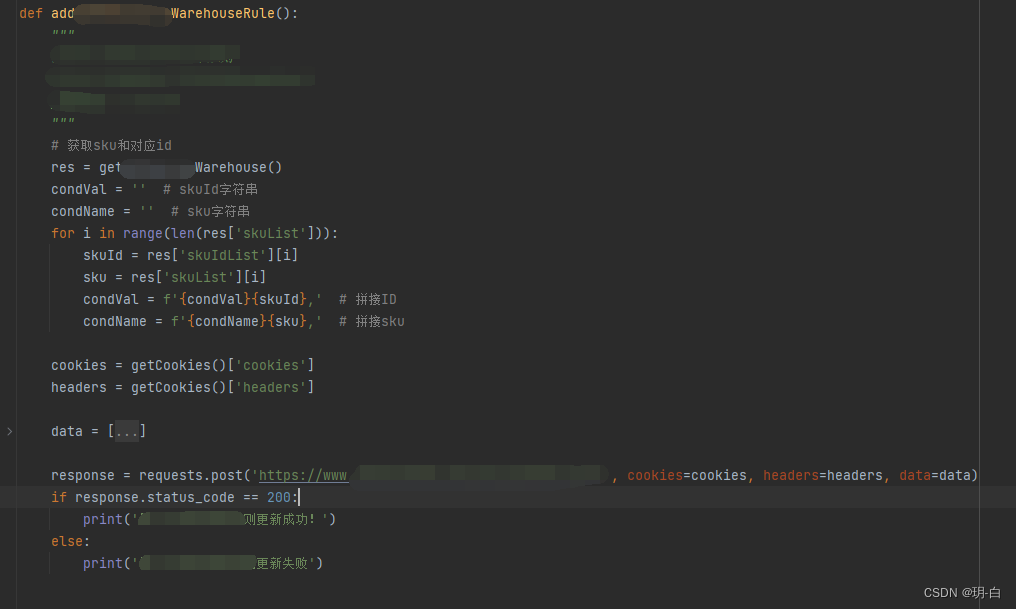
上面的res就是获取sku和对应id的字典,而字典内的每一个字段对应的值都是一个列表。拿到字典后我们把它循环遍历出来,接着拼接id,拼接sku,然后就带参数上传到对应的请求网址,最后判断请求代码,如果是200证明请求成功。
添加多个审单规则
在上面我们可以看到能添加审单规则了,但是如果需要同时添加多个审单规则怎么办呢?
在这里就需要用到多线程了,下面就简单的介绍一下:
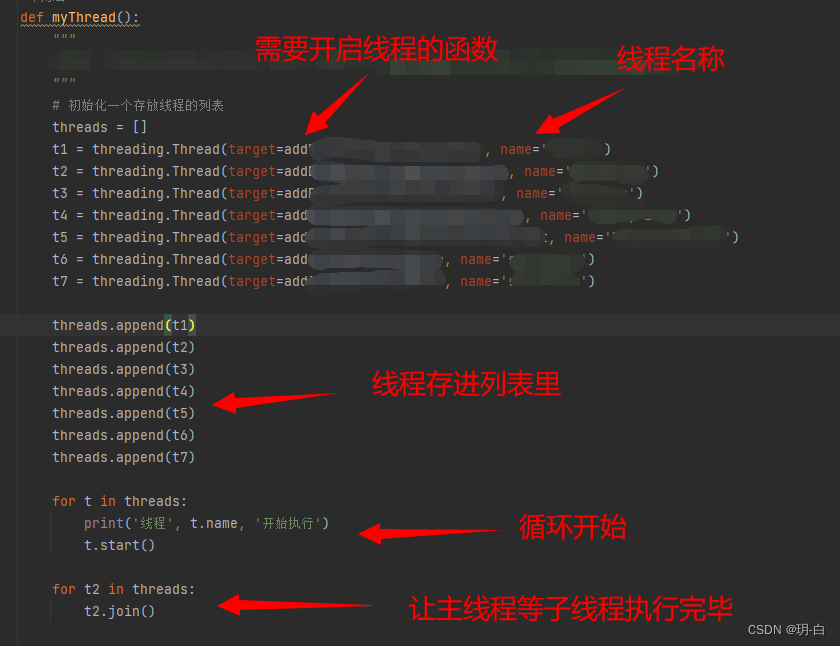
以上就是如何获取仓库清单sku和添加审单规则的代码和逻辑














 256
256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









